 Edge AI 挑戰內存技術
Edge AI 挑戰內存技術
隨著邊緣人工智能的興起,對存儲系統提出了一系列新要求。當今的內存技術能否滿足這一具有挑戰性的新應用的嚴格要求,新興內存技術對邊緣 AI 的長期承諾是什么?
首先要意識到的是,沒有標準的“邊緣人工智能”應用;最廣泛解釋的邊緣涵蓋了云外所有支持人工智能的電子系統。這可能包括“近邊緣”,通常涵蓋企業數據中心和本地服務器。
更進一步的是用于自動駕駛的計算機視覺等應用。用于制造的網關設備執行 AI 推理以檢查生產線上產品的缺陷。電線桿上的 5G“邊緣盒”分析智能城市應用(如交通管理)的視頻流。5G 基礎設施在邊緣使用人工智能來實現復雜但高效的波束形成算法。
在“遠端”,人工智能在手機等設備中得到支持——想想 Snapchat 過濾器——在將結果發送到另一個網關設備之前,工廠中執行傳感器融合的設備和物聯網傳感器節點的語音控制。
內存在邊緣 AI 系統中的作用——存儲神經網絡權重、模型代碼、輸入數據和中間激活——對于大多數 AI 應用程序來說都是相同的。必須加速工作負載以最大化 AI 計算能力以保持高效,因此對容量和帶寬的要求通常很高。然而,特定應用的需求是多種多樣的,可能包括尺寸、功耗、低電壓操作、可靠性、熱/冷卻考慮和成本。
邊緣數據中心
邊緣數據中心是一個關鍵的邊緣市場。用例范圍從醫學成像、研究和復雜的金融算法,其中隱私阻止上傳到云。另一個是自動駕駛汽車,延遲會阻止它。
這些系統使用與其他應用程序中的服務器相同的內存。
“在開發和訓練 AI 算法的應用中,將低延遲 DRAM 用于快速、字節級的主內存非常重要,”內存產品設計師和開發商 Smart Modular Technologies 的解決方案架構師 Pekon Gupta 說。“大型數據集需要高容量 RDIMM 或 LRDIMM。系統加速需要 NVDIMM——我們將它們用于寫入緩存和檢查點,而不是速度較慢的 SSD。”

佩孔古普塔
將計算節點定位在靠近最終用戶的位置是電信運營商采用的方法。
“我們看到了使這些[電信] 邊緣服務器更有能力運行復雜算法的趨勢,”Gupta 說。因此,“服務提供商正在使用 RDIMM、LRDIMM 和 NVDIMM 等高可用性持久內存等設備為這些邊緣服務器增加更多內存和處理能力。”
Gupta 認為英特爾 Optane 是該公司的 3D-Xpoint 非易失性內存,其特性介于 DRAM 和閃存之間,是服務器 AI 應用程序的良好解決方案。
“Optane DIMM 和 NVDIMM 都被用作 AI 加速器,”他說。“NVDIMM 為 AI 應用程序加速提供了非常低延遲的分層、緩存、寫入緩沖和元數據存儲功能。Optane 數據中心 DIMM 用于內存數據庫加速,其中數百 GB 到 TB 的持久內存與 DRAM 結合使用。盡管這些都是用于 AI/ML 加速應用程序的持久內存解決方案,但它們有不同且獨立的用例。”
英特爾 Optane 產品營銷總監 Kristie Mann 告訴EE Times , Optane正在服務器 AI 領域獲得應用。

英特爾的克里斯蒂曼
“我們的客戶現在已經在使用 Optane 持久內存來支持他們的 AI 應用程序,”她說。“他們正在成功地為電子商務、視頻推薦引擎和實時財務分析應用提供支持。由于可用容量的增加,我們看到了向內存應用程序的轉變。”
DRAM 的高價格使 Optane 越來越成為有吸引力的替代品。配備兩個 Intel Xeon Scalable 處理器和 Optane 持久內存的服務器可以為需要大量數據的應用程序容納多達 6 TB 的內存。
“DRAM 仍然是最受歡迎的,但從成本和容量的角度來看,它有其局限性,”Mann 說。“由于其成本、容量和性能優勢,Optane 持久內存和 Optane SSD 等新的內存和存儲技術正在 [新興] 作為 DRAM 的替代品。Optane SSD 是特別強大的緩存 HDD 和 NAND SSD 數據,可以持續為 AI 應用程序提供數據。”
她補充說,Optane 還優于目前尚未完全成熟或可擴展的其他新興存儲器。

英特爾傲騰 200 系列模塊。英特爾表示,Optane 目前
已用于為 AI 應用程序提供動力。(來源:英特爾)
GPU 加速
對于高端邊緣數據中心和邊緣服務器應用程序,GPU 等 AI 計算加速器正在獲得關注。除 DRAM 外,這里的內存選擇還包括GDDR,一種用于為高帶寬 GPU 供電的特殊 DDR SDRAM,以及HBM,一種相對較新的芯片堆疊技術,它將多個內存芯片與 GPU 本身放在同一個封裝中。
兩者都是為 AI 應用程序所需的極高內存帶寬而設計的。
對于最苛刻的 AI 模型訓練,HBM2E 提供 3.6 Gbps 并提供 460 GB/s 的內存帶寬(兩個 HBM2E 堆棧提供接近 1 TB/s)。這是可用的性能最高的內存之一,在最小的區域內具有最低的功耗。GPU 領導者Nvidia 在其所有數據中心產品中都使用 HBM 。
Rambus IP 內核產品營銷高級總監 Frank Ferro 表示,GDDR6 還用于邊緣的 AI 推理應用程序。Ferro 表示,GDDR6 可以滿足邊緣 AI 推理系統的速度、成本和功耗要求。例如,GDDR6 可以提供 18 Gbps 并提供 72 GB/s。擁有四個 GDDR6 DRAM 可提供接近 300 GB/s 的內存帶寬。
“GDDR6 用于 AI 推理和 ADAS 應用,”Ferro 補充道。
在將 GDDR6 與 LPDDR(從 Jetson AGX Xavier 到 Jetson Nano 的大多數非數據中心邊緣解決方案的 Nvidia 方法)進行比較時,Ferro 承認 LPDDR 適用于邊緣或端點的低成本 AI 推理。
“LPDDR 的帶寬限制為 LPDDR4 的 4.2 Gbps 和 LPDDR5 的 6.4 Gbps,”他說。“隨著內存帶寬需求的增加,我們將看到越來越多的設計使用 GDDR6。這種內存帶寬差距有助于推動對 GDDR6 的需求。”

Rambus 的弗蘭克·費羅
盡管設計為與 GPU 一起使用,但其他處理加速器可以利用 GDDR 的帶寬。Ferro 重點介紹了 Achronix Speedster7t,這是一款基于 FPGA 的 AI 加速器,用于推理和一些低端訓練。
“在邊緣 AI 應用中,HBM 和 GDDR 內存都有空間,”Ferro 說。HBM“將繼續用于邊緣應用。對于 HBM 的所有優點,由于 3D 技術和 2.5D 制造,成本仍然很高。鑒于此,GDDR6 是成本和性能之間的良好權衡,尤其是對于網絡中的 AI 推理。”
HBM 用于高性能數據中心 AI ASIC,例如Graphcore IPU。雖然它提供了出色的性能,但對于某些應用來說,它的價格可能很高。
高通公司就是使用這種方法的公司之一。其 Cloud AI 100 針對邊緣數據中心、5G“邊緣盒”、ADAS/自動駕駛和 5G 基礎設施中的 AI 推理加速。
“與 HBM 相比,使用標準 DRAM 對我們來說很重要,因為我們希望降低材料成本,”高通計算和邊緣云部門總經理 Keith Kressin 說。“我們希望使用可以從多個供應商處購買的標準組件。我們有客戶想要在芯片上做所有事情,我們也有客戶想要跨卡。但他們都希望保持合理的成本,而不是選擇 HBM 甚至更奇特的內存。
“在訓練中,”他繼續說,“你有可以跨越[多個芯片]的非常大的模型,但對于推理[Cloud AI 100的市場],很多模型都更加本地化。”
遙遠的邊緣
在數據中心之外,邊緣人工智能系統通常專注于推理,但有一些明顯的例外,例如聯邦學習和其他增量訓練技術。
一些用于功耗敏感應用的 AI 加速器使用內存進行 AI 處理。基于多維矩陣乘法的推理適用于具有用于執行計算的存儲單元陣列的模擬計算技術。使用這種技術,Syntiant 的設備專為消費電子產品的語音控制而設計,而Gyrfalcon 的設備已被設計成智能手機,用于處理相機效果的推理。
在另一個例子中,智能處理單元專家Mythic使用閃存單元的模擬操作在單個閃存晶體管上存儲一個 8 位整數值(一個權重參數),使其比其他內存計算技術更密集。編程的閃存晶體管用作可變電阻器;輸入作為電壓提供,輸出作為電流收集。結合 ADC 和 DAC,結果是一個高效的矩陣乘法引擎。
Mythic 的 IP 在于補償和校準技術,可消除噪聲并實現可靠的 8 位計算。
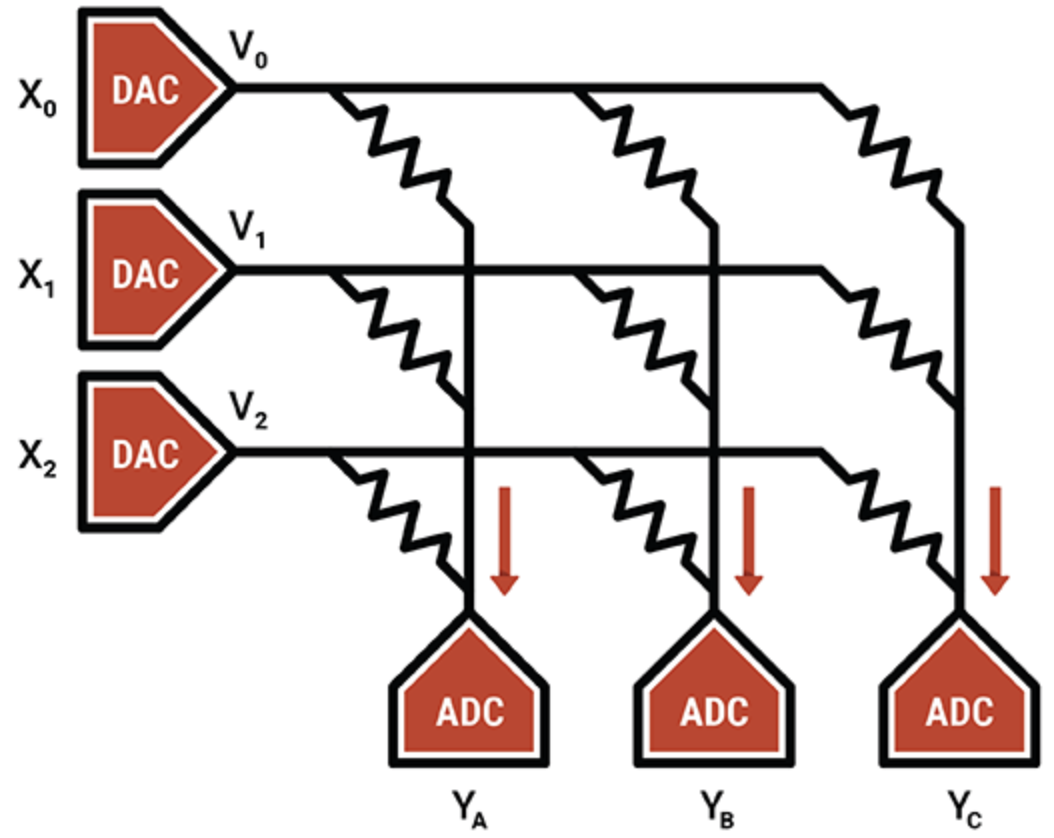
Mythic 使用閃存晶體管陣列來制造密集的乘法累加引擎(來源:Mythic)
除了內存計算設備外,ASIC 在特定的邊緣領域也很受歡迎,特別是低功耗和超低功耗系統。ASIC 的內存系統使用多種內存類型的組合。分布式本地 SRAM 是最快、最節能的,但不是很節省面積。在芯片上擁有一個大容量 SRAM 的面積效率更高,但會帶來性能瓶頸。片外 DRAM 更便宜,但耗電量更大。
Flex Logix 的首席執行官 Geoff Tate 表示,要為其 InferX X1 在分布式 SRAM、大容量 SRAM 和片外 DRAM 之間找到適當的平衡,需要進行一系列性能模擬。目標是最大化每美元的推理吞吐量——這是芯片尺寸、封裝成本和使用的 DRAM 數量的函數。
“最佳點是單個 x32 LPDDR4 DRAM;4K MAC(933MHz 時為 7.5 TOPS);和大約 10MB 的 SRAM,”他說。“SRAM 速度很快,但與 DRAM 相比價格昂貴。使用臺積電的16納米制程技術,1MB的SRAM大約需要1.1mm 2。“我們的 InferX X1 只有 54mm 2,由于我們的架構,DRAM 訪問很大程度上與計算重疊,因此沒有性能影響。對于具有單個 DRAM 的大型模型來說,這是正確的權衡,至少對于我們的架構而言,”Tate 說。
Flex Logix 芯片將用于需要實時操作的邊緣 AI 推理應用,包括以低延遲分析流視頻。這包括 ADAS 系統、安全鏡頭分析、醫學成像和質量保證/檢查應用程序。
在這些應用中,什么樣的 DRAM 將與 InferX X1 一起使用?
“我們認為 LPDDR 將是最受歡迎的:單個 DRAM 提供超過 10GB/秒的帶寬……但有足夠的位來存儲權重/中間激活,”Tate 說。“任何其他 DRAM 都需要更多的芯片和接口,并且需要購買更多未使用的位。”
這里有任何新興內存技術的空間嗎?
“當使用任何新興存儲器時,晶圓成本會急劇上升,而 SRAM 是‘免費的’,除了硅片面積,”他補充道。“隨著經濟的變化,臨界點也可能發生變化,但它會更進一步。”
涌現的記憶
盡管具有規模經濟性,但其他內存類型為人工智能應用提供了未來的可能性。
MRAM(磁阻式 RAM)通過由施加電壓控制的磁體方向存儲每一位數據。如果電壓低于翻轉位所需的電壓,則只有位翻轉的可能性。這種隨機性是不受歡迎的,因此用更高的電壓驅動 MRAM 以防止它發生。盡管如此,一些人工智能應用程序可以利用這種固有的隨機性(可以被認為是隨機選擇或生成數據的過程)。
實驗已將其 MRAM 的隨機性功能應用于Gyrfalcon 的設備,這是一種將所有權重和激活的精度降低到 1 位的技術。這用于顯著降低遠端應用程序的計算和功率要求。取決于重新訓練網絡的方式,可能會在準確性上進行權衡。一般來說,盡管精度降低,神經網絡仍可以可靠地運行。
“二值化神經網絡的獨特之處在于,即使數字為 -1 或 +1 的確定性降低,它們也能可靠地運行,”Spin Memory 產品副總裁 Andy Walker 說。“我們發現,這種 BNN 仍然可以以高準確度運行,因為 [通過] 引入錯誤寫入的內存位的所謂‘誤碼率’降低了這種確定性。”

自旋記憶的安迪沃克
MRAM 可以在低電壓水平下以受控方式自然地引入誤碼率,在保持精度的同時進一步降低功耗要求。關鍵是在最低電壓和最短時間下確定最佳精度。沃克說,這轉化為最高的能源效率。
雖然這項技術也適用于更高精度的神經網絡,但它特別適用于 BNN,因為 MRAM 單元有兩種狀態,與 BNN 中的二進制狀態相匹配。
Walker 表示,在邊緣使用 MRAM 是另一個潛在應用。
“對于邊緣人工智能,MRAM 能夠在不需要高性能精度的應用中以較低的電壓運行,但提高能效和內存耐用性非常重要,”他說。“此外,MRAM 固有的非易失性允許在沒有電源的情況下保存數據。
一種應用是作為所謂的統一存儲器,“這種新興存儲器可以作為嵌入式閃存和 SRAM 的替代品,節省芯片面積并避免 SRAM 固有的靜態功耗。”
雖然 Spin Memory 的 MRAM 正處于商業應用的邊緣,但 BNN 的具體實施最好在基本 MRAM 單元的變體上工作。因此,它仍處于研究階段。
神經形態 ReRAM
用于邊緣 AI 應用的另一種新興內存是 ReRAM。Politecnico Milan 最近使用 Weebit Nano 的氧化硅 (SiOx) ReRAM 技術進行的研究顯示了神經形態計算的前景。ReRAM 為神經網絡硬件增加了一個可塑性維度;也就是說,它可以隨著條件的變化而發展——神經形態計算中的一個有用品質。
當前的神經網絡無法在不忘記他們接受過訓練的任務的情況下學習,而大腦可以很容易地做到這一點。在 AI 術語中,這是“無監督學習”,算法在沒有標簽的數據集上執行推理,在數據中尋找自己的模式。最終的結果可能是支持 ReRAM 的邊緣 AI 系統,它可以就地學習新任務并適應周圍的環境。
總體而言,內存制造商正在引入提供人工智能應用所需的速度和帶寬的技術。各種內存,無論是與 AI 計算在同一芯片上、在同一封裝中還是在單獨的模塊上,都可用于適應許多邊緣 AI 應用。
雖然邊緣 AI 的內存系統的確切性質取決于應用程序,但 GDDR、HBM 和 Optane 被證明在數據中心中很受歡迎,而 LPDDR 與片上 SRAM 競爭端點應用程序。
新興記憶正在將其新穎的特性用于研究,旨在推動神經網絡超越當今硬件的能力,以實現未來的節能、受大腦啟發的系統。
、審核編輯 黃昊宇
-
內存
+關注
關注
8文章
3030瀏覽量
74109 -
AI
+關注
關注
87文章
30998瀏覽量
269329 -
EDGE
+關注
關注
0文章
181瀏覽量
42676
發布評論請先 登錄
相關推薦
貿澤開售適用于AI和機器學習應用的 AMD Versal AI Edge VEK280評估套件
在設備上利用AI Edge Torch生成式API部署自定義大語言模型

Google AI Edge Torch的特性詳解

AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
使用TI Edge AI Studio和AM62A進行基于視覺AI的缺陷檢測

Edge AI工控機的定義、挑選考量與常見應用
凌華智能推出全新AI 邊緣服務器MEC-AI7400 (AI Edge Server)系列
美光內存助力未來AI技術更強大、更智能
SiMa.ai推出針對Edge AI調整的SoC
微軟Edge瀏覽器擬推出內存限制器
NanoEdge AI的技術原理、應用場景及優勢
【ALINX 技術分享】AMD Versal AI Edge 自適應計算加速平臺之 Versal 介紹(2)
【ALINX 技術分享】AMD Versal AI Edge 自適應計算加速平臺之準備工作(1)





 工商網監
工商網監
評論