 Meta開源NLLB翻譯模型,支持200種語言互譯
Meta開源NLLB翻譯模型,支持200種語言互譯
這個翻譯模型,不僅支持200+語言之間任意兩兩互譯,還是開源的。Meta AI在發布開源大型預訓練模型OPT之后,再次發布最新成果NLLB。
NLLB的全稱為No Language Left Behind,如果套用某著名電影,可以翻譯成“一個語言都不能少”。

這其中,中文分為簡體繁體和粵語三種,而除了中英法日語等常用語種外,還包括了許多小眾語言。
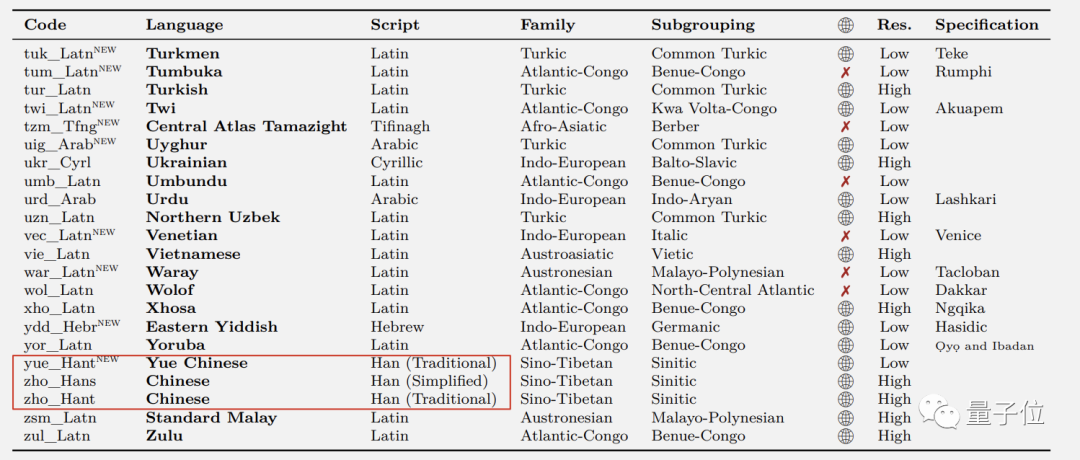
▲NLLB支持的部分語種截圖
由于這些語言之間都可以兩兩互譯,所以咱們能用NLLB把阿斯圖里亞語、盧甘達語、烏爾都語等地球上的小眾語言直接譯成中文了。
一位用粵語的靚仔看到這里直接喜大普奔。
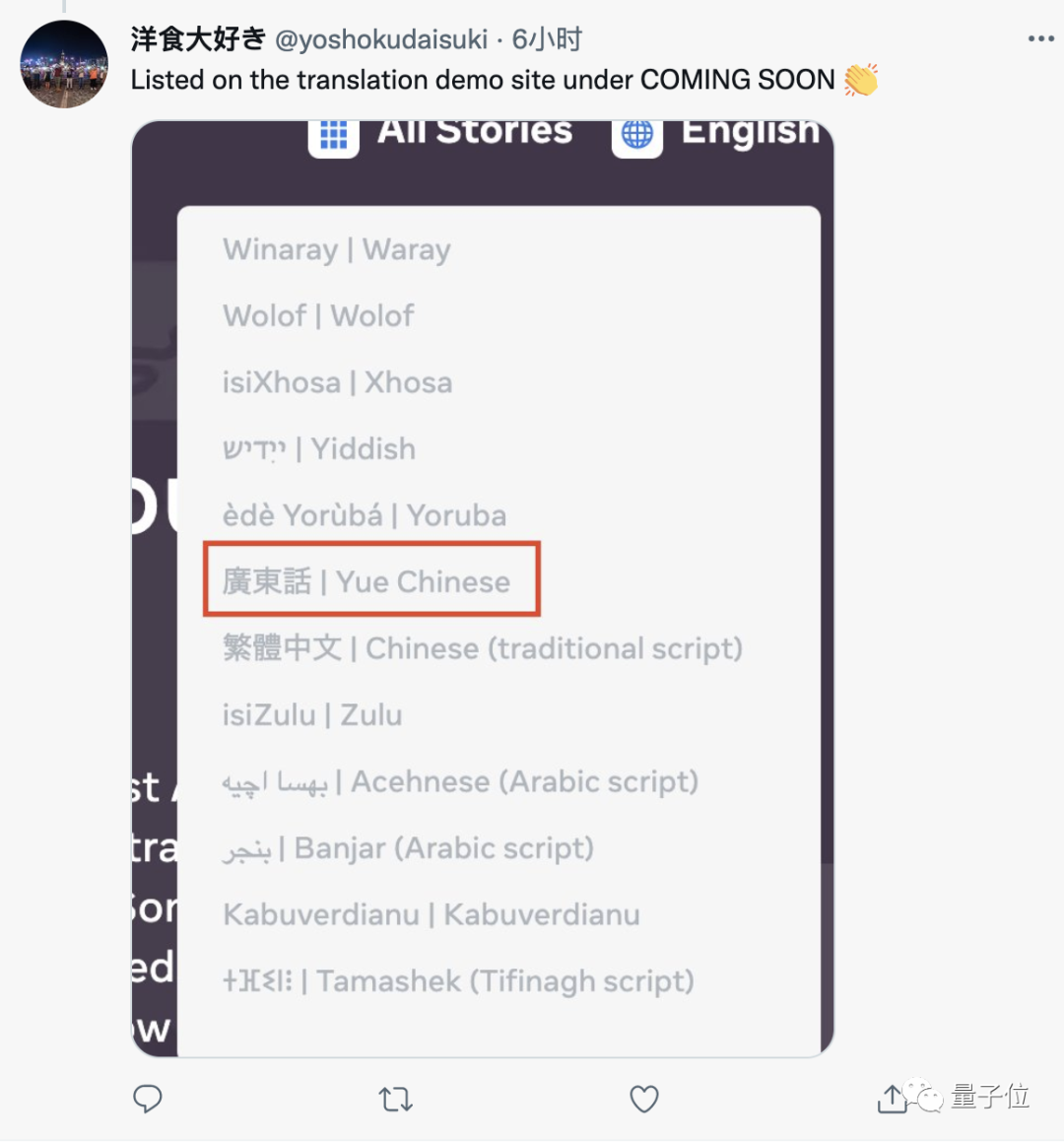
要知道,此前的眾多語言模型,要么不支持這么多種語言,要么不能直接完成小眾語言之間的兩兩翻譯。
有了NLLB,世界各地的人都有機會以自己的母語訪問和分享網絡內容;并且無論他們的語言偏好如何,都可以與他人在任意地方溝通。
Meta稱,他們計劃先將這個技術應用于Facebook和Instagram,以提升這些平臺上小眾語言的計算機翻譯水平。
同時,這也是他們元宇宙計劃的一部分。而這項成果正式開源的消息,也受到廣受好評。
除了AI業內關心他們如何支持語料稀缺的冷門語言,以及如何在BLEU基準測試上提高7個點以外。也有來自西非的網友認為,語言障礙正是全球互聯網用戶數量進一步增長的關鍵。
在Hacker News論壇上,大家也對這個AI議論紛紛。一個前端開發者說,自己的母語就是非常小眾的那種,僅有約一百萬人使用。
這位開發者此前從未見過對這種語言好用的AI翻譯軟件,而NLLB給他帶來了希望。
不過他認為,連著名的谷歌AI在處理“德-英-德”這樣語料豐富的語言翻譯時,都常常會出問題,所以他暫且對這個聲稱能翻譯好小眾語言的新模型持保留態度。

有網友給這位開發者支招兒,告訴他Meta開放了有支持翻譯的兒童書籍,可以去看看翻譯效果。

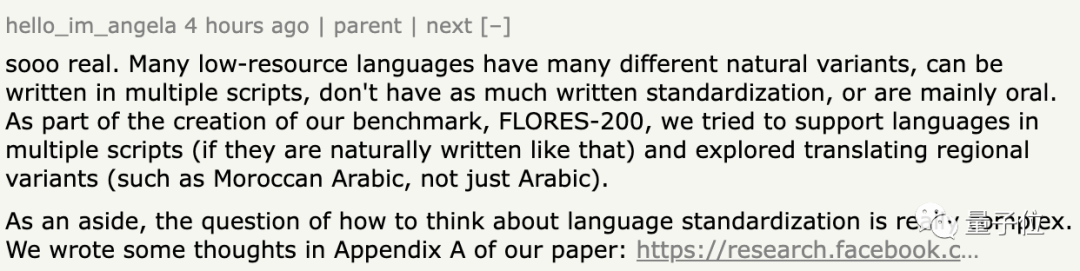
還有人補充道,許多小眾語言有許多不同的自然變體,更偏于口語化,而沒有特定書面化標準,可以用多種文字書寫。所以,如何對小眾語言進行標準化是個棘手的問題。
怎么支持語料少的語言
這個掌握了200多種語言的AI模型是怎么訓練的?
據Meta AI介紹,他們的AI研究人員主要通過3個方面來解決一些語言語料少的問題。
其一是為語料少的語言自動構建高質量的數據集。研究者建立了一個多對多的多語言數據集Flores-200。專業的真人翻譯員和審稿人采用統一的標準,來保質保量地建立這個數據集。
首先,譯員們翻譯Flores-200的全部句子,并檢查;然后,獨立審查員小組開始審查翻譯質量,根據他們的評估將一些譯文送去進行后期編輯。
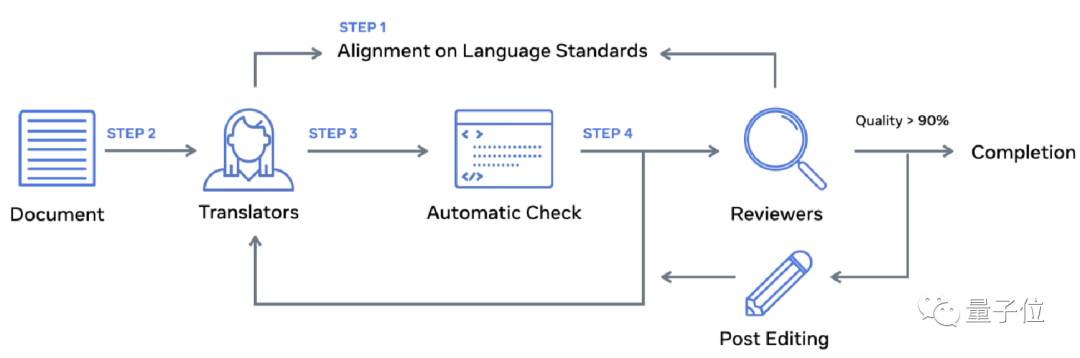
如果質量評估表明,質量在90%以上,則認為該語言可以被納入Flores-200中。
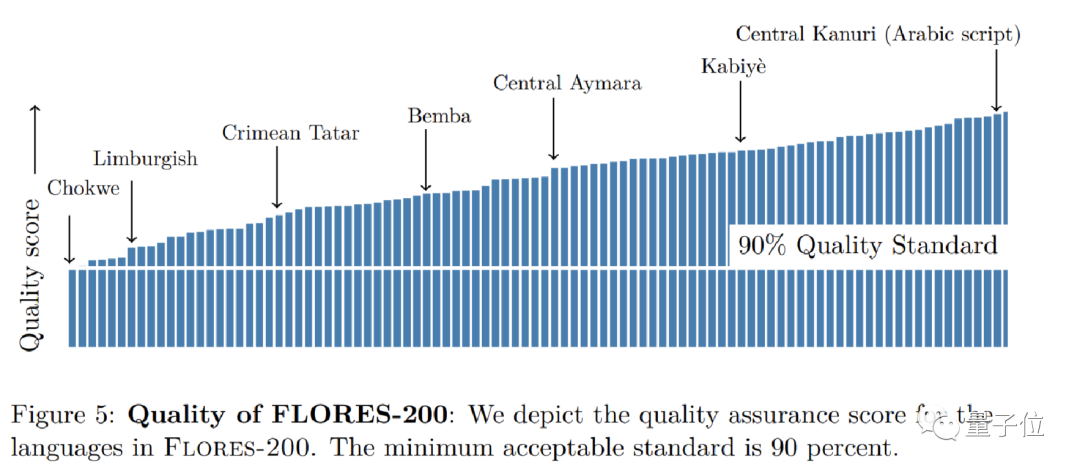
最終,Flores-200中包含了842篇不同文章的翻譯,共3001個句子。
其二,是對200種語言建模:研究者開發了一個語言識別系統LID(language identification systems),標記出某段文字是用哪種語言寫的。
用監督方式訓練的LID模型在看似流暢的句子上,可能難以識別處不正確語法和不完整的字符串。
此外,LID很容易學習到沒有意義的相關性。所以,在這個LID開發的不同階段,工程師們都和語言學家們保持著緊密合作來盡量規避這些問題。
為了對小眾語言進行較好的建模,研究者開發了一種“學生-教師挖掘法”(Student-Teacher Mining)該方法的內容是:讓一個大規模的多語言句子編碼器的教師模型,與幾個語料少的學生模型相互學習整合。
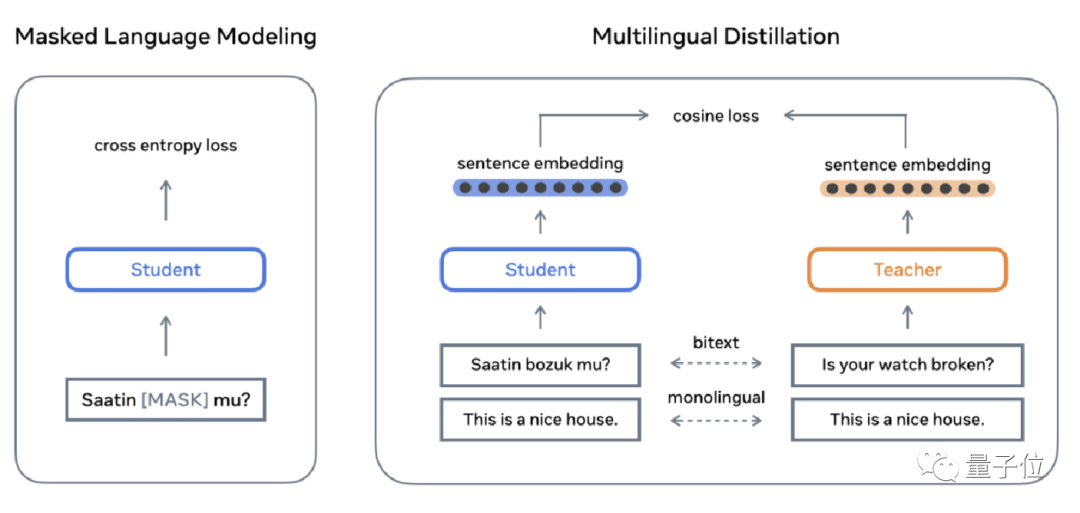
這樣能夠在不和多語料語言爭奪容量的情況下,豐富小眾語言的訓練數據,保持了多語言嵌入空間的兼容性,避免從頭開始重新訓練整個模型。
其三,是將一個人工翻譯的評估基準:FLORES的覆蓋范圍擴大2倍,來評估每一種語言的翻譯質量。雖然自動評分是推動該研究的重要工具,但人工評價對于翻譯質量的評估也是必不可少的。
通過整合AI自動評分和人工評估,能夠廣泛量化翻譯水平,便于提升整理的翻譯質量。
為了讓更多程序員和工程師們能夠使用或完善NLLB,Meta開放了所有的評估基準(FLORES-200、NLLB-MD、Toxicity-200)、LID模型和訓練代碼,以及最終的NLLB-200模型和其小型提煉版本等。
Meta AI已將這些內容開源,就在fariseq倉庫里面,感興趣的小伙伴們可以去看看。
論文地址:
https://research.facebook.com/publications/no-language-left-behind/
開源地址:
https://github.com/facebookresearch/fairseq/tree/nllb
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
536瀏覽量
10311 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14922 -
數據集
+關注
關注
4文章
1209瀏覽量
24781
原文標題:機器翻譯做到頭了?Meta開源NLLB翻譯模型,支持200種語言互譯
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論