") 實體關(guān)系抽取模型CasRel
實體關(guān)系抽取模型CasRel
寫在前面
今天來跟大家分享一篇發(fā)表在2020ACL上的實體關(guān)系抽取論文CasRel。
論文名稱:《A Novel Cascade Binary Tagging Framework forRelational Triple Extraction》
論文鏈接:https://aclanthology.org/2020.acl-main.136.pdf
代碼地址:https://github.com/weizhepei/CasRel
1. 關(guān)系抽取任務(wù)定義
實體關(guān)系抽取(關(guān)系抽取)是構(gòu)建知識圖譜非常重要的一環(huán),其旨在識別實體之間的語義關(guān)系。換句話說,關(guān)系抽取就是從非結(jié)構(gòu)化文本即純文本中抽取實體關(guān)系三元組(SRO)。這里 代表頭實體, 代表關(guān)系, 代表尾實體。

上圖展示了3個例子:
第一句文本中,“劉翔”和“上海”兩個實體之間的語義關(guān)系是“出生地”。
第二句文本中,“張藝謀”與“菊豆”兩個實體之間的語義關(guān)系是“導演”。
第三句文本中,“史蒂夫.喬布斯”與“蘋果”之間的語義關(guān)系是“創(chuàng)始人”。
2. 關(guān)系抽取方法
關(guān)系抽取方法主要可分為兩類:
管道學習方法(pipeline):管道學習方法通常先抽取句子中的實體,然后再對實體對進行關(guān)系分類,從而找出SRO三元組。
聯(lián)合學習方法(Joint):聯(lián)合學習方法同時進行實體識別和實體對的關(guān)系分類兩個子任務(wù)。
許多實驗證明聯(lián)合學習方法由于考慮了兩個子任務(wù)之間的信息交互,大大提升了實體關(guān)系抽取的效果,所以目前針對實體關(guān)系抽取任務(wù)的研究大多采用聯(lián)合學習方法。
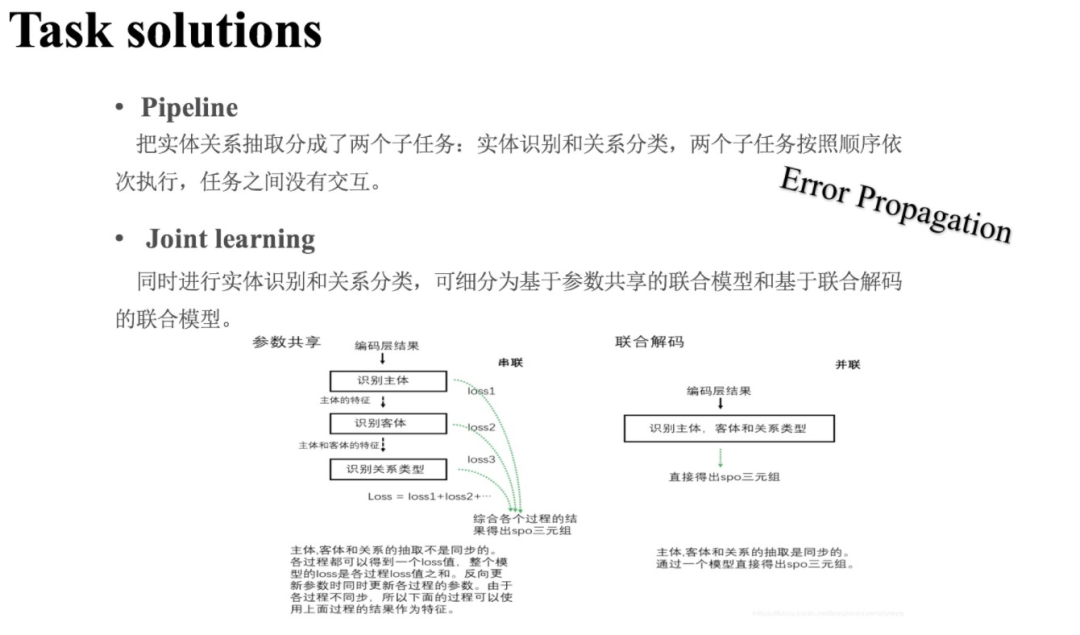
進一步地,聯(lián)合學習方法又可以細分為以下兩種:基于參數(shù)共享的聯(lián)合模型;基于聯(lián)合解碼的聯(lián)合模型。另一方面,解碼方式對實體關(guān)系抽取性能的影響也很大,主要的解碼方式有三種:基于序列標注;基于指針網(wǎng)絡(luò);基于片段分類。
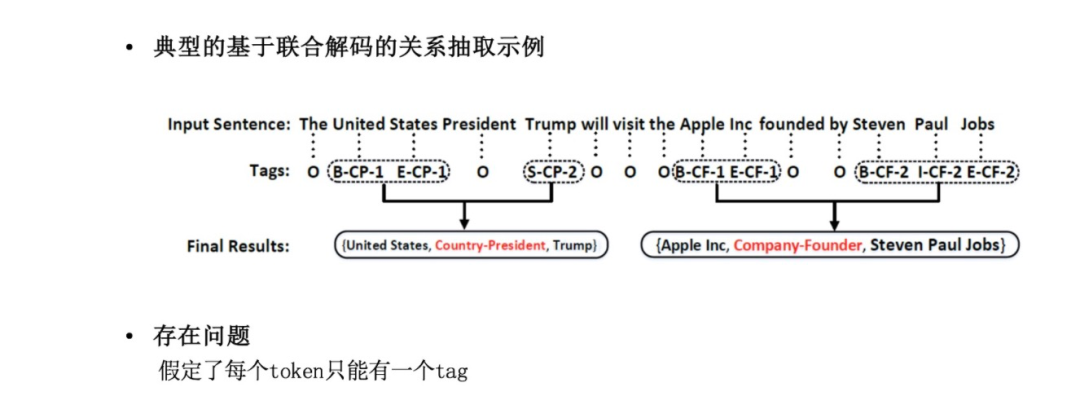
《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》[1]是采用序列標注的聯(lián)合解碼的典型方法。簡單地說,它將實體關(guān)系抽取當作了序列標注問題,設(shè)計了比較特別的標注標簽可以實現(xiàn)實體、關(guān)系的聯(lián)合抽取(如上圖所示)。
3. 關(guān)系抽取難點

如上圖所示,和大多數(shù)的自然語言處理任務(wù)一樣,關(guān)系抽取同樣有許多難點。我們今天所分享的CasRel關(guān)注的難點主要是三元組的重疊問題(實體關(guān)系重疊),即:輸入文本中有多個實體關(guān)系三元組,彼此之間可能共享了某些實體。
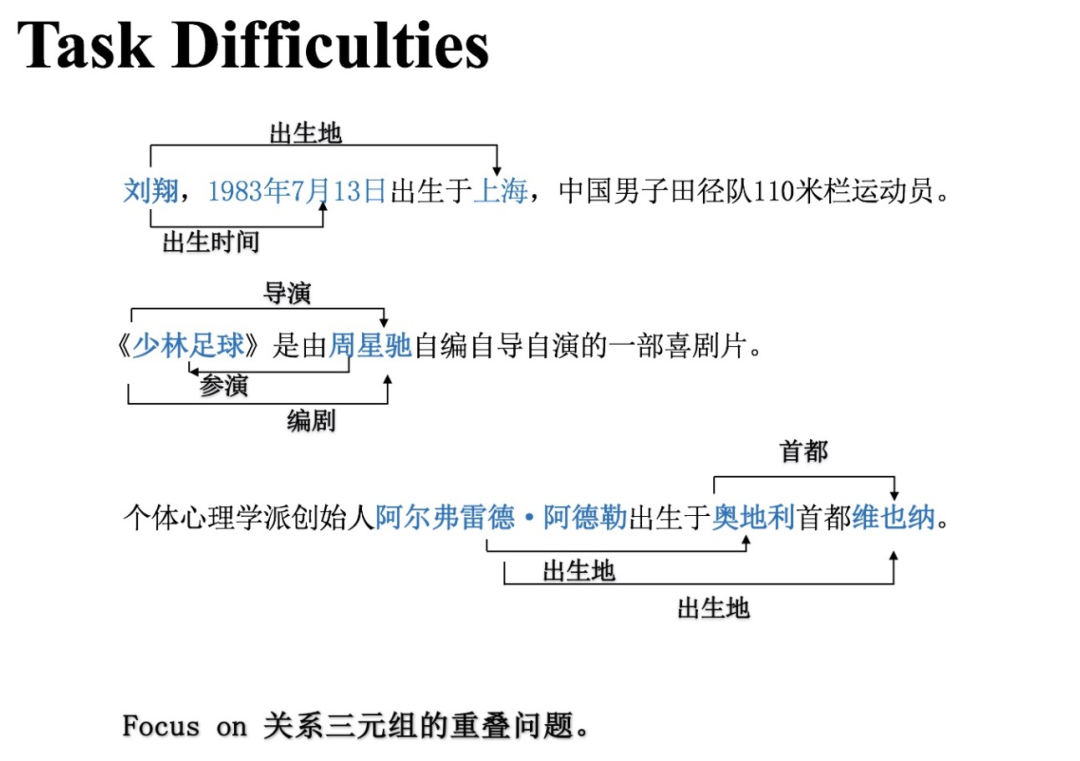
上圖給出了部分示例:
(劉翔, 出生地, 上海)與(劉翔, 出生時間, 1983年7月13日)都有“劉翔”;
(《少林足球》, 導演, 周星馳)、(《少林足球》, 編劇, 周星馳)、(周星馳, 參演, 《少林足球》)都有“《少林足球》”和“周星馳”;
(阿爾弗雷德.阿德勒, 出生地, 奧地利)與(阿爾弗雷德.阿德勒, 出生地, 維也納)都有“阿爾弗雷德.阿德勒”..
前面我們所提的聯(lián)合解碼模型由于其標簽設(shè)計或CRF層限定了每個token只能有一個tag,所以無法適用于實體關(guān)系重疊情況。此外,基于參數(shù)共享的關(guān)系抽取方法最后通常是一個多分類層,也就是一對實體只能有一個標簽。簡單地將其改成多標簽分類就能一定程度上解決實體關(guān)系重疊問題,但是這種改進并不具備什么創(chuàng)新性。
那接下來我們就來看看CasRel是如何另辟蹊徑來解決實體關(guān)系重疊問題的。
4. CasRel核心思想
CasRel本質(zhì)上也是基于參數(shù)共享的聯(lián)合實體關(guān)系抽取方法,它通常被大家稱作層疊指針網(wǎng)絡(luò)。實際上,CasRel的核心思想或者說作者改進現(xiàn)有模型的重點在于子層的設(shè)計。
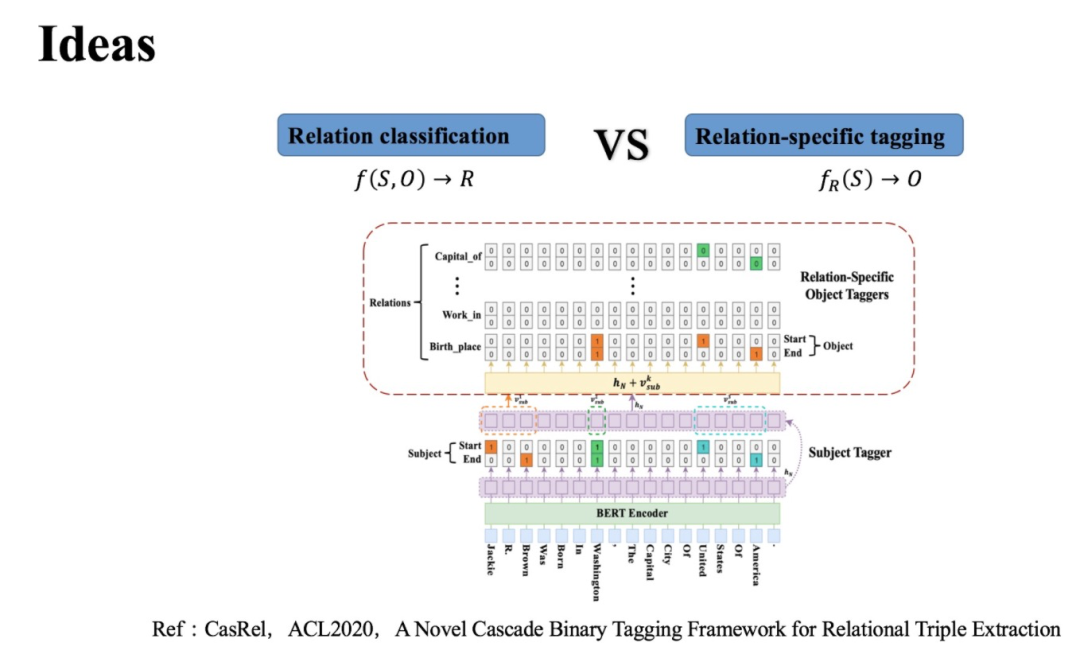
因為CasRel對于關(guān)系抽取這個任務(wù)的拆分不同,所以子任務(wù)及子任務(wù)求解順序也不同。具體地:首先CasRel 會識別所有可能的主語(頭實體);然后在給定類別關(guān)系 下,再去識別與主語相關(guān)的賓語(尾實體)。
更形式化的表達:如果說以前關(guān)系抽取/關(guān)系分類是這樣一個映射函數(shù) ,;那么現(xiàn)在在CasRel中關(guān)系抽取對應(yīng)的映射函數(shù)則是 。
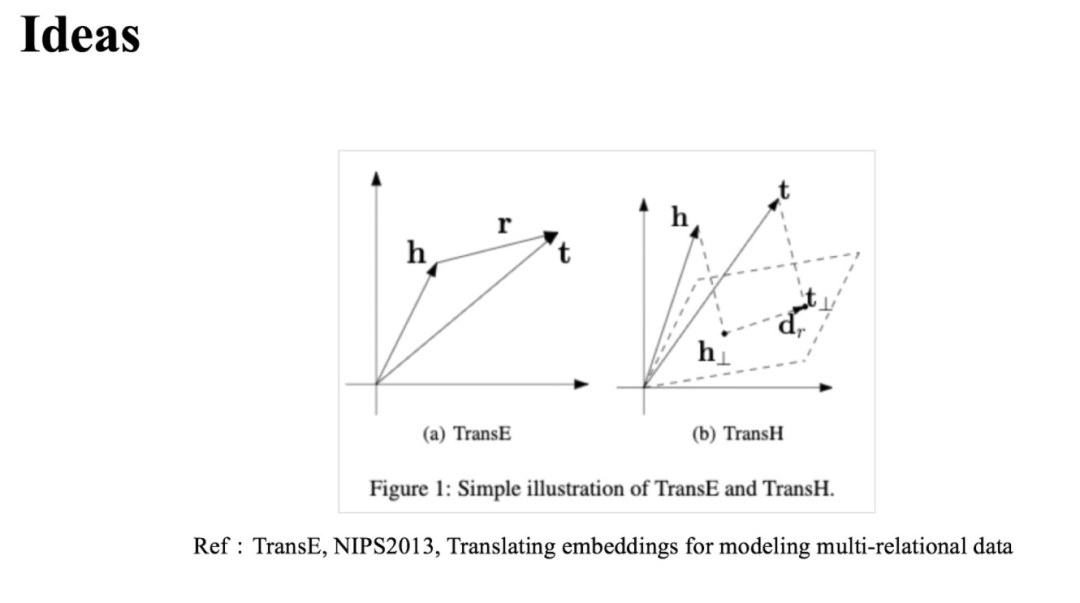
與之相似的思想很早之前就有出現(xiàn)在知識圖譜表示學習方法當中,比如在下圖的 TransE[2]模型中就有 (這里 為頭實體, 為尾實體)。
5. 模型細節(jié)

現(xiàn)在我們再來看CasRel的模型細節(jié)。CasRel是一個基于聯(lián)合解碼的實體關(guān)系抽取模型,其思想和模型都很簡單,主要包括三層:
編碼端:基于BERT的編碼層用于獲取上下文語義信息對字/詞進行表征;
解碼端:解碼端主要包括了頭實體識別層、關(guān)系與尾實體聯(lián)合識別層。
在這里,基于BERT的編碼層我們就不做過多的介紹了,感興趣的讀者可以下載論文《Pre-trained Models for Natural Language Processing》進行閱讀學習。接下來,我們將著重介紹CasRel的解碼端。
5.1 頭實體識別層
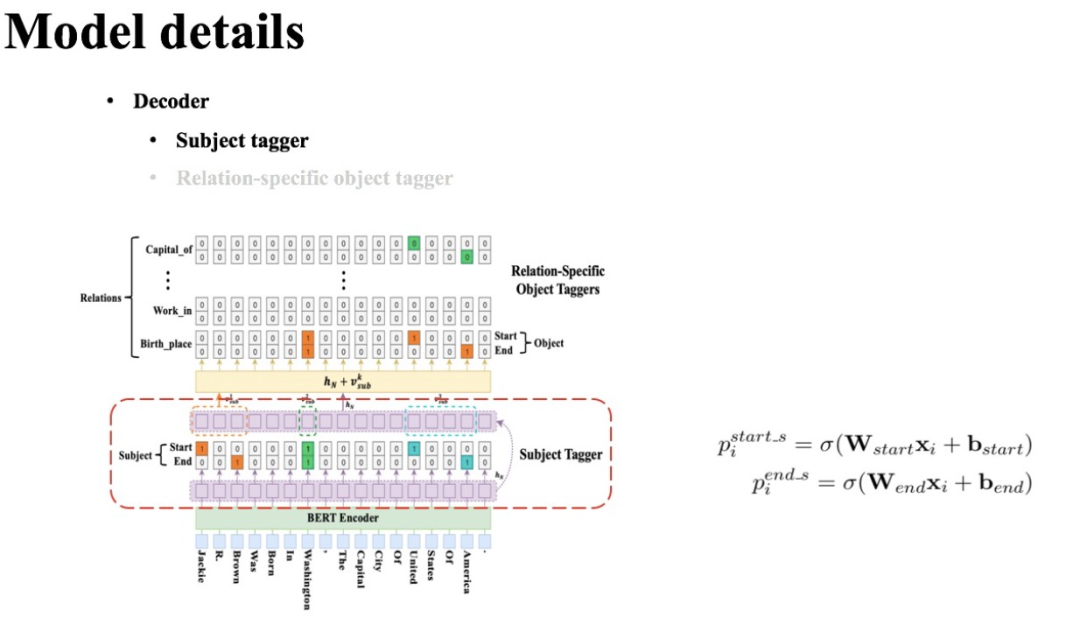
CasRel的頭實體識別層直接對編碼層的結(jié)果進行解碼,去識別所有可能的頭實體。這里CasRel是識別頭實體span,也就是start和end位置,所以它采用的是二分類。這點和我們在實體識別BERT-MRC論文閱讀筆記、實體識別LEAR論文閱讀筆記中類似。
因此,模型本身很簡單:
首先,利用一個線性層一個sigmoid激活函數(shù)判斷每個token是不是頭實體的開始token或結(jié)束token;
然后,利用最近匹配原則將識別到的start和end配對獲得候選頭實體集合。
5.2 關(guān)系、尾實體聯(lián)合識別層
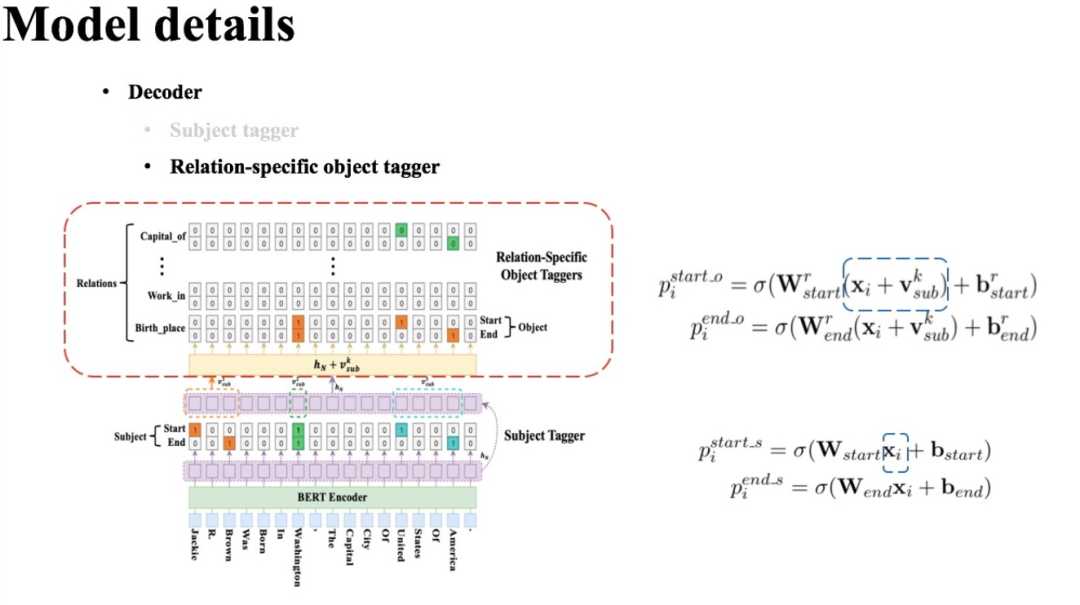
識別頭實體后就要進行關(guān)系和尾實體的聯(lián)合識別了。這里,CasRel是通過一組關(guān)系相關(guān)的尾實體識別層來實現(xiàn)的。每一層尾實體識別層的結(jié)構(gòu)其實與頭實體識別層是一樣的,不同主要在于輸入:
頭實體識別層的輸入直接就是編碼層的輸出;
而尾實體識別層的輸入還考慮了頭實體的特征:
這里 是第 個候選頭實體所包含的所有token的向量的平均。
5.3 概率解釋
最后,我們從概率角度來看CasRel模型。
既然實體關(guān)系抽取任務(wù)就是識別文本中潛在的實體關(guān)系三元組,那么模型的優(yōu)化目標可以直接建立在三元組這個層面上。
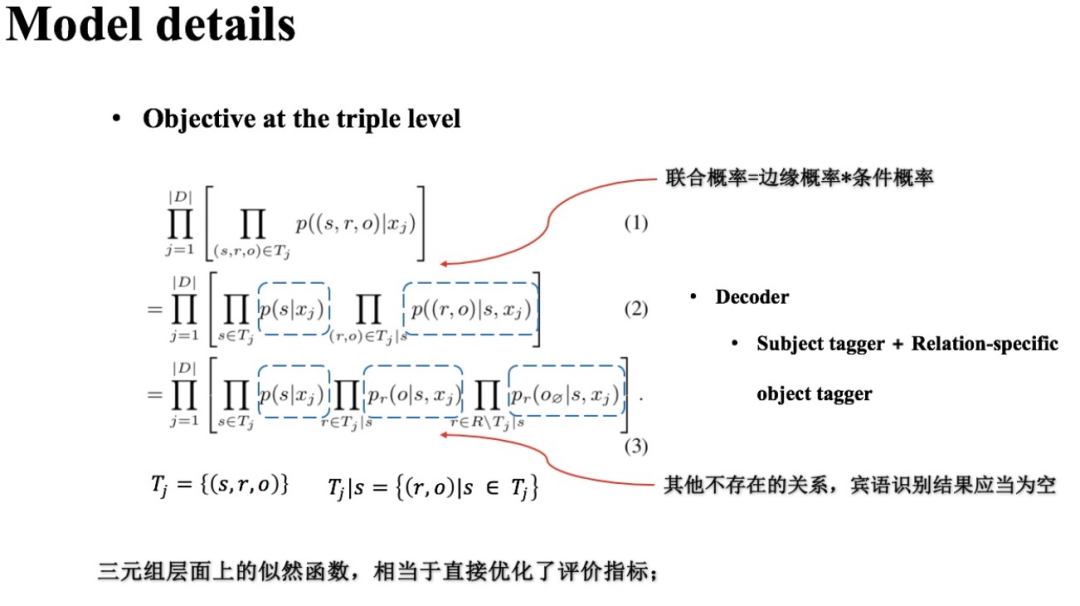
(1) 優(yōu)化目標
假設(shè) 為訓練集, 是第 個輸入樣本, 是文本 中含有的所有三元組,CasRel的訓練目標自然是如下似然函數(shù)值最大:
(2) 概率公式變換
根據(jù)聯(lián)合概率=邊緣概率*條件概率,我們有:
這里 表示出現(xiàn)在 中的一個頭實體, 表示出現(xiàn)在 中且其頭實體為 的一組關(guān)系-尾實體對。 為先驗概率, 為條件概率。
(3) 關(guān)系作為先驗知識
然后,把關(guān)系作為先驗知識,我們可以進一步把上式右端第二項拆成兩部分,即出現(xiàn)在 中且頭實體為 的關(guān)系、其他關(guān)系:
這里, 是所有關(guān)系的集合, 表示出現(xiàn)在 中且頭實體為 的一組關(guān)系, 是 與 的差集,也就是沒有出現(xiàn)在 中的其他關(guān)系。
表示對于文本 與頭實體 以及沒有出現(xiàn)在 中的關(guān)系 來說,尾實體識別結(jié)果應(yīng)當為空。所以最終我們有:
(4) 結(jié)論
可以發(fā)現(xiàn)最終這個式子與CasRel抽取實體關(guān)系三元組的子任務(wù)順序一致:
首先識別文本中所有可能的頭實體;
然后在每個關(guān)系類別下,去抽取與識別到的頭實體存在該關(guān)系的所有可能的尾實體。
另一方面,這個任務(wù)拆解方式也很自然解決了重疊實體關(guān)系三元組的提取問題。
5.4 實驗
實驗主要在兩個公開的數(shù)據(jù)集NYT和WebNLG上進行。此外,需要注意的是CasRel模型本身還有兩個變體:
:表示編碼端的BERT參數(shù)是隨機初始化的;
:表示編碼端使用的是LSTM而不是BERT。
當然CasRel則表示采用預(yù)訓練好的BERT作為編碼端。
(1) 整體實驗效果對比
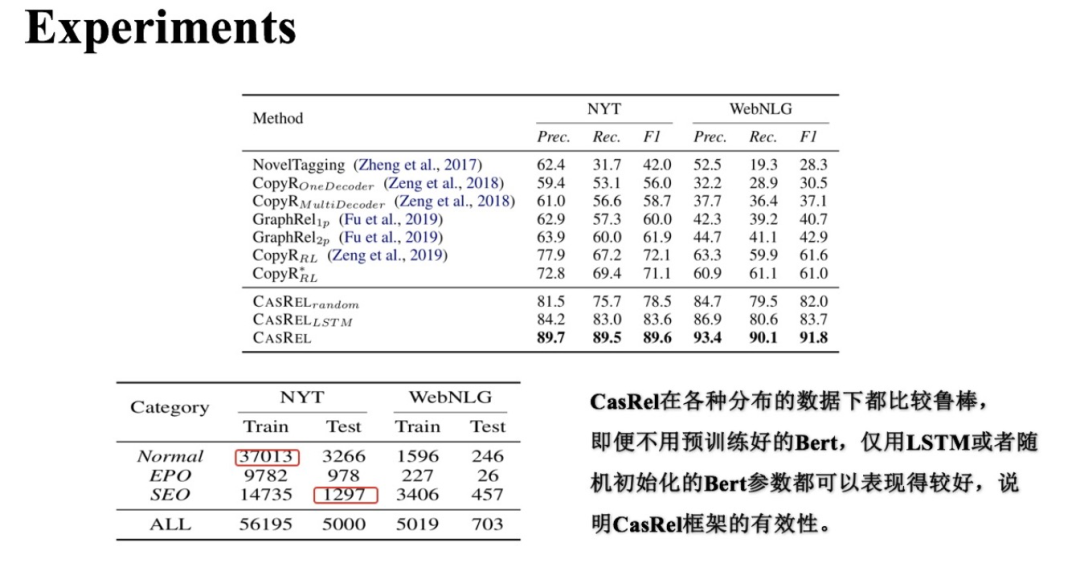
上圖中展示了CasRel及其變體模型與其他基準方法在兩個數(shù)據(jù)集上的效果。可以看到CasRel及其變體的效果都高于其他方法;尤其在WebNLG數(shù)據(jù)上,相對提升得更多。仔細看NYT、WebNLG兩個數(shù)據(jù)分布差異還是蠻大的:
NYT、WebNLG兩個數(shù)據(jù)中都有Normal類型的三元組、SEO類型的三元組、EPO類型的三元組,且三者在兩個數(shù)據(jù)集中占比不同;
Normal、SEO、EPO分別代表常規(guī)實體關(guān)系三元組、單個實體重疊的實體關(guān)系三元組、實體對重疊的實體關(guān)系三元組;
NYT中的實體關(guān)系三元組類型多為Normal類型,即數(shù)據(jù)中常規(guī)實體關(guān)系三元組居多。
WebNLG中的實體關(guān)系三元組多為SEO類型,即單個實體重疊的實體關(guān)系三元組居多。
CasRel在兩個數(shù)據(jù)集上相對穩(wěn)定的表現(xiàn)說明了在實體關(guān)系重疊這種復(fù)雜場景下,其框架的有效性。
(2) 不同三元組重疊類型實驗對比
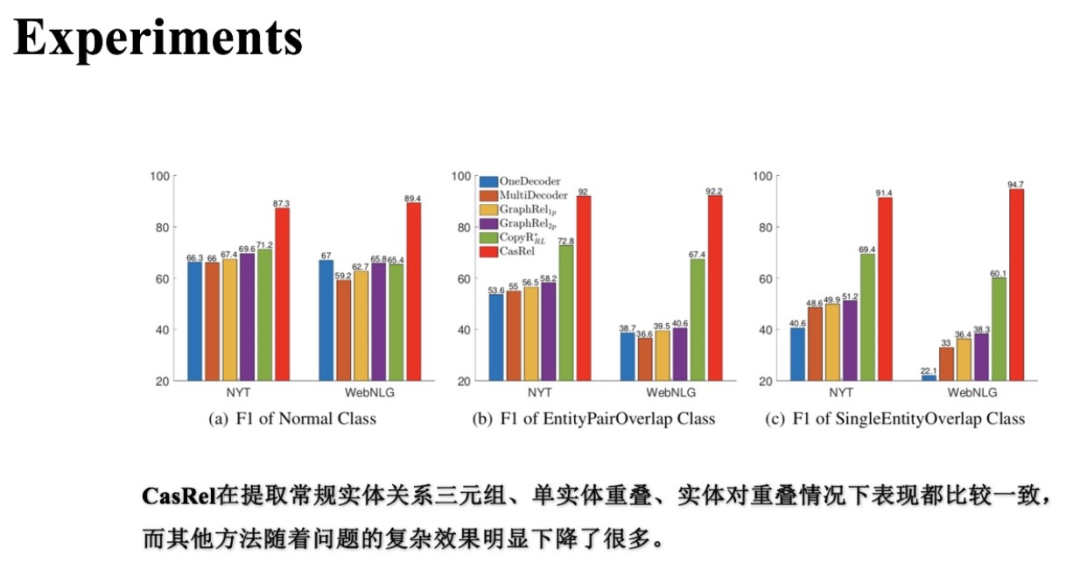
上圖展示了在不同三元組重疊類型的樣本上各個基準方法與CasRel的實驗結(jié)果。可以發(fā)現(xiàn)隨著場景逐漸復(fù)雜(Normal->EPO、SEO),基準方法的效果都逐漸下降,但CasRel則取得了相對穩(wěn)定且優(yōu)異的表現(xiàn)。這個對比實驗進一步說明了CasRel在重疊三元組場景下的有效性。
(3) 不同三元組個數(shù)實驗對比
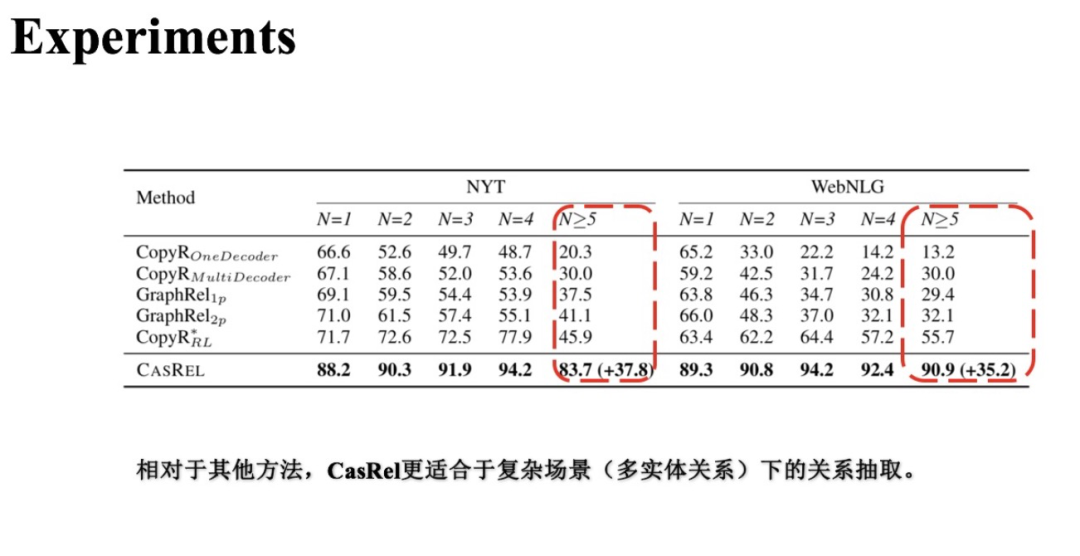
隨著樣本中三元組個數(shù)的增多,每個方法的效果都或多多少地受到了影響。尤其在 即多于五個三元組的樣本上,基準方法效果基本都大幅度下降,而CasRel相對要好一些。同時,在 的樣本上CasRel的效果相對于基準方法提升的最多。
這個對比實驗反映了CasRel相比其他基準方法在處理多實體關(guān)系三元組下的能力更強。
6. 延伸思考
CasRel的思想可以很自然地遷移到上去信息抽取中的另一大任務(wù)事件抽取上,因為在事件抽取同樣存在一些類似的挑戰(zhàn):
輸入文本里面存在多個事件;
事件論元可能重疊,同一個論元可能扮演不同的角色、同一個角色下也可能有多個論元:同一個事件論元可能重疊;不同事件之間論元可能重疊。
6.1 事件抽取任務(wù)描述
事件抽取任務(wù)可拆為兩個子任務(wù):
事件檢測(event detection):即觸發(fā)詞的抽取和事件類型判斷;
事件論元識別(argument extraction):即識別事件論元并判斷論元所扮演的角色。
6.2 CasRel范式遷移到事件抽取
阿墨最初看到CasRel時就想到它的層疊指針范式可以遷移到事件抽取中:
建模思路和子任務(wù)順序:CasRel建模思路(TransE 中也是類似的)是“頭實體+關(guān)系=尾實體”,即CasRel先抽頭實體,再抽關(guān)系和尾實體;遷移到事件抽取中,可以是“觸發(fā)詞+角色=論元”即先抽觸發(fā)詞,再抽角色和論元。
模型適配:CasRel 模型中的頭實體識別子結(jié)構(gòu)適配到事件抽取中觸發(fā)詞檢測,CasRel模型中的關(guān)系尾實體識別子結(jié)構(gòu)適配到事件論元識別。這樣就完成了事件檢測任務(wù)中的觸發(fā)詞抽取、事件論元識別任務(wù),那么事件類型判定呢?
事件類型判定:事件類型判定既可在觸發(fā)詞檢測完后做,即僅對觸發(fā)詞分類,也可以在最后結(jié)合觸發(fā)詞/論元/角色信息進行事件分類。
小改動完成完全適配:如果考慮“原文+事件類型=觸發(fā)詞”,那么實際上事件類型判定和觸發(fā)詞抽取可一并完成。只需要把用于抽取觸發(fā)詞子結(jié)構(gòu)換成和用于事件論元識別子結(jié)構(gòu)類似或者說一致即可。
實際上,在2020年阿墨進行事件抽取相關(guān)實驗過程中,陸陸續(xù)續(xù)就有這個系列的工作出來如:JMCEE[3]、PLMEE[4] 及CasEE[5]。CasEE代碼也開源了,阿墨去年也在上面進行了一些實驗。文末附上了相關(guān)論文鏈接,感興趣的讀者可下載閱讀。
總結(jié)
今天我們分享了實體關(guān)系抽取模型CasRel,并在最后聯(lián)系事件抽取做了一些延伸思考。
審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3259瀏覽量
48907 -
知識圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7714
原文標題:一文詳解關(guān)系抽取模型 CasRel
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論