") 怎么構(gòu)建命名實體識別(NER)任務(wù)的標注數(shù)據(jù)
怎么構(gòu)建命名實體識別(NER)任務(wù)的標注數(shù)據(jù)
最近一段時間在做商品理解的工作,主要內(nèi)容是從商品標題里識別出商品的一些屬性標簽,包括不限于品牌、顏色、領(lǐng)型、適用人群、尺碼等等。這類任務(wù)可以抽象成命名實體識別(Named Entity Recognition, NER)工作,一般用序列標注(Sequence Tagging)的方式來做,是比較成熟的方向。
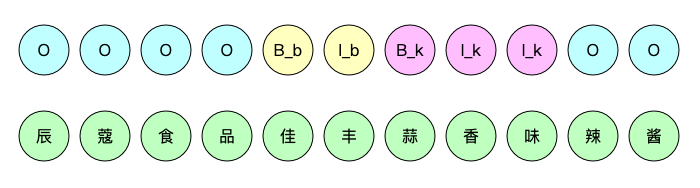
▲ 商品理解示例,品牌:佳豐;口味:蒜香味
本文主要記錄下做這個任務(wù)上遇到的問題,踩的坑,模型的效果等。
主要內(nèi)容:
- 怎么構(gòu)建命名實體識別(NER)任務(wù)的標注數(shù)據(jù)
-
BertCRF 訓練單標簽識別過程及踩坑
- BertCRF 訓練超多標簽識別過程及踩坑
- CascadeBertCRF 訓練超多標簽識別過程及踩坑
NER任務(wù)標注數(shù)據(jù)方法
其實對 NER 任務(wù)來說,怎么獲取標注數(shù)據(jù)是比較重要、比較耗時費力的工作。針對商品理解任務(wù)來說,想要獲取大量的標注數(shù)據(jù)一般可以分為 3 種途徑:
-
花錢外包,靠外包人肉打標,羨慕有錢的公司。
-
抓取其他平臺的數(shù)據(jù),這塊也可以分成兩種情況,第一種是既抓標題又抓標簽-標簽值,比如 標題:珍味來(zhenweilai)小黃魚(燒烤味),品牌:珍味來(zhenweilai),口味:燒烤味,得到的數(shù)據(jù)直接可以訓練模型了;第二種是只抓 標簽-標簽值,把所有類目下所有常見的標簽抓下來,不抓標題,然通過一些手段把標簽掛到自己平臺的標題上,構(gòu)造訓練數(shù)據(jù);第一種抓取得數(shù)據(jù)準,但很難找到資源給抓,即使找到了也非常容易被風控;第二種因為請求量小,好抓一點,但掛標簽這一步的準確度會影響后面模型的效果。
- 用自己平臺的商品標題去請求一些開放 NER 的 api,比如阿里云、騰訊云、百度 ai 等,有些平臺的 api 是免費的,有些 api 每天可以調(diào)用一定次數(shù),可以白嫖,對于電商領(lǐng)域,阿里云的 NER 效果比其他家好一些。
BertCRF單標簽NER模型
這部分主要記錄 BertCRF 在做單一標簽(品牌)識別任務(wù)時踩的一些坑。
先把踩的坑列一下:
-
怎么輕量化構(gòu)建 NER 標注數(shù)據(jù)集。
-
bert tokenizer 標題轉(zhuǎn) id 時,品牌值的 start idx、end idx 和原始的對不上,巨坑。
- 單一標簽很容易過擬合,會把不帶品牌的標題里識別出一些品牌,識別出來的品牌也不對。
2.1 輕量化構(gòu)建標注數(shù)據(jù)集
上面講到構(gòu)建 NER 標注數(shù)據(jù)的常見 3 種方法,先把第一種就排除,因為沒錢打標;對于第三種,我嘗試了福報廠的 NER api,分基礎(chǔ)版 和 高級版,但評估下來發(fā)現(xiàn)不是那么準確,召回率沒有達到要求,也排除了;
那就剩第二種方案了,首先嘗試了第二種里的第一種情況,既抓標題又抓標簽,很快發(fā)現(xiàn)就被風控了,不管用自己寫的腳本還是公司的采集平臺,都繞不過風控,便放棄了;所以就只抓標簽-標簽值,后面再用規(guī)則的方法掛到商品標題上。
只抓標簽和標簽值相當于構(gòu)建類目下標簽知識庫了,有了類目限定之后,通過規(guī)則掛靠在商品標題上時,會提高掛靠的準確率。比如“夏季清涼短款連衣裙”,其中包含標簽“裙長”:“短款”,如果不做類目限定,就會用規(guī)則掛出多個標簽“衣長”:“短款”,“褲長”:“短款”,“裙長”:“短款”等等,類目限制就可以把一些非此類目的標簽排除掉。
通過規(guī)則掛靠出的數(shù)據(jù)也會存在一些 bad case,盡管做了類目限制,但也有一定的標錯樣本;組內(nèi)其他同學在做大規(guī)模對比學習模型,于是用規(guī)則掛靠出的結(jié)果標題——標簽:標簽值走一遍對比學習模型,把標題向量和標簽值向量相似得分高的樣本留下當做優(yōu)質(zhì)標注數(shù)據(jù)。
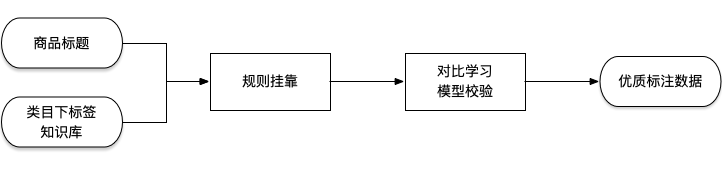
▲ 輕量化構(gòu)建NER標注數(shù)據(jù)
通過以上步驟,不需要花費很多人力,自己一人就可以完成整個流程,減少了很多人工標注、驗證的工作;得到的數(shù)據(jù)也足夠優(yōu)質(zhì)。
2.2 正確打標label index
NER 任務(wù)和文本分類任務(wù)很像,文本分類任務(wù)是句子或整篇粒度,NER 是 token 或者 word 粒度的文本分類。
所以 NER 任務(wù)的訓練數(shù)據(jù)和文本分類任務(wù)相似,但有一點點不同。對于文本分類任務(wù),一整個標題有 1 個 label。

▲ 文本分類任務(wù)token和label對應(yīng)關(guān)系
對于 NER 任務(wù),一整個標題有一串 label,每個 tokend 都有一個 label。在做品牌識別時,設(shè)定 label 有 3 種取值。
"UNK":0," B_brand":1,"I_brand":2,其中 B_brand 代表品牌的起始位置,I_brand 代表品牌的中間位置。
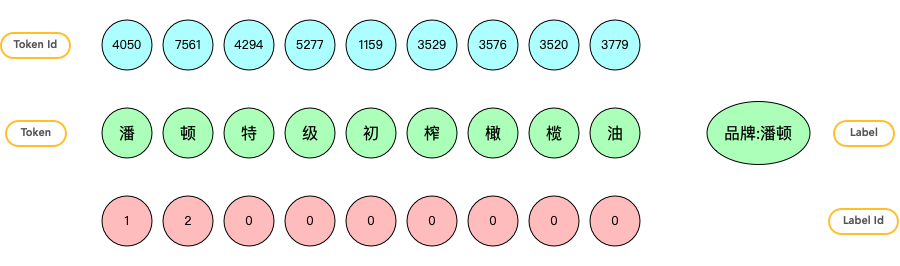
搞清了 NER 任務(wù)的 label 形式之后,接下來就是怎么正確的給每個樣本打上 label,一般先聲明個和 title 長度一樣的全 0 列表,遍歷,把相應(yīng)位置置 1 或者 2 就可以得到樣本 label,下面是一個基礎(chǔ)的例子
a={
"title":"潘頓特級初榨橄欖油",
"att_name":"品牌",
"att_value":"潘頓",
"start_idx":0,
"end_idx":2
}
defset_label(text):
title=text['title']
label=[0]*len(title)
foridxinrange(text['start_idx'],text['end_idx']):
ifidx==text['start_idx']:
label[idx]=1
else:
label[idx]=2
returnlabel
text_label=set_label(a)
print(text_label)
但這里需要把 title 進行 tokenizer id 化,bert tokenizer 之后的 id 長度可能會和原來的標題長度不一致,包含有些英文會拆成詞綴,空格也會被丟棄,導致原始的 start_idx 和 end_idx 發(fā)生偏移,label 就不對了。
這里先說結(jié)論:強烈建議使用 list(title)全拆分標題,再使用 tokenizer.convert_tokens_to_ids 的方式 id 化!!!
剛開始沒有使用上面那種方式,用的是 tokenizer(title)進行 id 化再計算偏移量,重新對齊 label,踩了 2 個坑
-
tokenizer 拆分英文變成詞綴,start index 和 end index 會發(fā)生偏移,盡管有offset_mapping 可以記錄偏移的對應(yīng)關(guān)系,但真正回退偏移時還會遇到問題;
- 使用 tokenizer(title)的方式,預測的時候會遇到?jīng)]法把 id 變成 token;比如下面這個例子,
fromtransformersimportAutoTokenizer
tokenizer=AutoTokenizer.from_pretrained('../bert_pretrain_model')
input_id=tokenizer('呫頓')['input_ids']
token=[tokenizer.convert_ids_to_tokens(w)forwininput_id[1:-1]]
#['[UNK]','頓']
因為“呫”是生僻字,使用 convert_ids_to_tokens 是沒法知道原始文字是啥的,有人可能會說,預測出 index 之后,直接去標題里拿字不就行了,不用 convert_ids_to_tokens;上面說過,預測出來的 index 和原始標題的文字存在 offset,這樣流程就變成
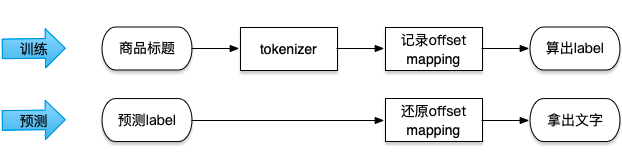
▲ 使用tokenizer id化label對應(yīng)關(guān)系
所以,還是強烈建議使用 list(title)全拆分標題,再使用 tokenizer.convert_tokens_to_ids 的方式 id 化!!!
這樣就不存在偏移的問題,start idx 和 end idx 不會變化,預測的時候不需要使用 convert_ids_to_tokens,直接用 index 去列表里 token list 取字
正確打標 label 非常重要,不然訓練的模型就會很詭異。建議在代碼里加上校驗語句,不管使用哪種方法,有考慮不全的地方,就會報錯
assertattribute_value==title[text['start_idx']:text['end_idx']]
2.3 BertCRF模型結(jié)構(gòu)
Pytorch 寫 BertCRF 很簡單,可能會遇到 CRF 包安裝問題,可以不安裝,直接把 crf.py 文件拷貝到項目里引用。
classBertCRF(nn.Module):
def__init__(self,num_labels):
super(BertCRF,self).__init__()
self.config=BertConfig.from_pretrained('../xxx/config.json')
self.bert=BertModel.from_pretrained('../xxx')
self.dropout=nn.Dropout(self.config.hidden_dropout_prob)
self.classifier=nn.Linear(self.config.hidden_size,num_labels)
self.crf=CRF(num_tags=num_labels,batch_first=True)
defforward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
labels=None,
):
outputs=self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
sequence_output=outputs[0]
sequence_output=self.dropout(sequence_output)
logits=self.classifier(sequence_output)
outputs=(logits,)
iflabelsisnotNone:
loss=self.crf(emissions=logits,tags=labels,mask=attention_mask)
outputs=(-1*loss,logits)
returnoutputs
2.4 緩解過擬合問題
只做一個標簽(品牌)識別時,訓練集是 標題-品牌值 pair 對,每個樣本都有品牌值。由于品牌長尾現(xiàn)象嚴重,這里對熱門品牌的數(shù)據(jù)進行了采樣,1 個品牌最少包含 100 個標題,最多包含 300 個標題,數(shù)據(jù)分布如下

模型關(guān)鍵參數(shù)
max_seq_length=50
train_batch_size=256
epochs=3
learning_rate=1e-5
crf_learning_rate=5e-5
第一版模型訓練之后,驗證集 F1 0.98,通過分析驗證數(shù)據(jù)的 bad case,發(fā)現(xiàn)模型對包含品牌的標題預測效果還不錯,但是對不包含品牌的標題,幾乎全軍覆沒,都會抽出 1、2 個字出來,模型過擬合了。而且抽出的字一般都是標題前 1、2 個字,這與商品品牌一般都在標題前面有關(guān)。
針對過擬合問題及表現(xiàn)的現(xiàn)象,嘗試了 2 種方法:
-
既然對沒有品牌的標題一般都抽出前 1、2 個字,那在訓練的時候把品牌從前面隨機插入到標題中間、尾部等位置,是不是可以緩解。
- 構(gòu)建訓練集的時候加入一些負樣本,負樣本里 label 都是 0,不包含品牌,正負樣本比 1:1。
法 1 訓練之后,沒有解決問題,而且過擬合問題更加嚴重了
法 2 訓練之后,過擬合問題解決了,增加了近 1 倍樣本,訓練時間翻倍。
BertCRF 模型訓練完之后,通過分析 bad case,會發(fā)現(xiàn)有的數(shù)據(jù)模型預測是對的,標注時標錯了,模型有一定的糾錯能力,transformer 強啊!
美國新安怡(fsoothielp)安撫奶嘴。標注品牌:”soothie“;預測品牌:“新安怡(fsoothielp)”
美羚富奶羊羊羊粉 2 段。標注品牌:“羊羊羊”,預測品牌:“美羚”
針對 BertCRF 在 Finetune 時有 2 種方式,一種是 linear probe,只訓練 CRF 和線性層,凍結(jié) Bert 預訓練參數(shù),這種方式訓練飛快;另一種是不凍結(jié) Bert 參數(shù),模型所有參數(shù)都更新,訓練很慢。
一般在 Bert 接下游任務(wù)時,我都會選擇第二種全部訓練的方式,不凍結(jié)參數(shù),雖然訓練慢,但擬合能力強;尤其是用 bert-base 這類預訓練模型時,這些模型在電商領(lǐng)域直接適配并不會很好,更新 bert 預訓練參數(shù),能讓模型向電商標題領(lǐng)域進行遷移。
BertCRF多標簽NER模型
這部分主要記錄 BertCRF 訓練超多標簽識別時,遇到的問題,模型的效果等。
先把踩的坑列一下:
-
爆內(nèi)存問題,因為要訓練多標簽,所以訓練數(shù)據(jù)很多,千萬級別,dataloader 過程中內(nèi)存不夠。
-
爆顯存問題,CRF 的坑,下面會細說。
- 訓練完的模型,預測時召回能力不強,準確率夠用。
多標簽和單標簽時,模型的結(jié)構(gòu)不變,和上面的代碼一模一樣。
3.1 爆內(nèi)存問題
和單標簽一樣,也對每個標簽值進行了采樣,減少標簽值的長尾分布現(xiàn)象。1 個標簽值最少包含 100 個標題,最多包含 300 個標題。數(shù)據(jù)分布如下

一個標簽有多個標簽值,比如“顏色”:“紅”,“黃”,“綠”,...等。一個標簽有 2 個 label 值,B 代表起始位置,I 代表終止位置,所以整體有 1212 + 1 個類別,1 代表 UNK。
單類別負采樣后訓練數(shù)據(jù)總共 200w 左右,多類別時沒負采樣訓練數(shù)據(jù) 900 多 w,數(shù)據(jù)量多了 4 倍,原有的 dataset 沒有優(yōu)化內(nèi)存,到多標簽這里就爆內(nèi)存了。
把特征處理的模塊從__init__里轉(zhuǎn)移到__getitem__函數(shù)里,這樣就可以減少很多內(nèi)存使用了
舊版本的 dataset 函數(shù)
classMyDataset(Dataset):
def__init__(self,text_list,tokenizer,max_seq_len):
self.input_ids=[]
self.token_type_ids=[]
self.attention_mask=[]
self.labels=[]
self.input_lens=[]
self.len=len(text_list)
fortextintqdm(text_list):
input_ids,input_mask,token_type_ids,input_len,label_ids=feature_process(text,tokenizer,max_seq_len)
self.input_ids.append(input_ids)
self.token_type_ids.append(token_type_ids)
self.attention_mask.append(input_mask)
self.labels.append(label_ids)
self.input_lens.append(input_len)
def__getitem__(self,index):
tmp_input_ids=torch.tensor(self.input_ids[index]).to(device)
tmp_token_type_ids=torch.tensor(self.token_type_ids[index]).to(device)
tmp_attention_mask=torch.tensor(self.attention_mask[index]).to(device)
tmp_labels=torch.tensor(self.labels[index]).to(device)
tmp_input_lens=torch.tensor(self.input_lens[index]).to(device)
returntmp_input_ids,tmp_attention_mask,tmp_token_type_ids,tmp_input_lens,tmp_labels
def__len__(self):
returnself.len
新版本的 dataset 函數(shù)
classMyDataset(Dataset):
def__init__(self,text_list,tokenizer,max_seq_len):
self.text_list=text_list
self.len=len(text_list)
self.tokenizer=tokenizer
self.max_seq_len=max_seq_len
def__getitem__(self,index):
raw_text=self.text_list[index]
input_ids,input_mask,token_type_ids,input_len,label_ids=feature_process(raw_text,
self.tokenizer,
self.max_seq_len)
tmp_input_ids=torch.tensor(input_ids).to(device)
tmp_token_type_ids=torch.tensor(token_type_ids).to(device)
tmp_attention_mask=torch.tensor(input_mask).to(device)
tmp_labels=torch.tensor(label_ids).to(device)
tmp_input_lens=torch.tensor(input_len).to(device)
returntmp_input_ids,tmp_attention_mask,tmp_token_type_ids,tmp_input_lens,tmp_labels
def__len__(self):
returnself.len
可以看到新版本比舊版本減少了 5 個超大的 list,爆內(nèi)存的問題就解決了,雖然這塊會有一定的速度損失。
3.2 爆顯存問題
當標簽個數(shù)少時,BertCRF 模型最大 tensor 是 bert 的 input,包含 input_ids,attention_mask,token_type_ids三個tensor,維度是(batch size,sequence length,hidden_size=768),對于商品標題數(shù)據(jù) sequence length=50,顯存占用大小取決于 batch size,僅做品牌識別,16G 顯存 batch size=300,32G 顯存 batch size=700。
但當標簽個數(shù)多時,BertCRF 模型最大 tensor 來自 CRF 這貨了,這貨具體原理不展開,后面會單獨寫一期,只講下這貨代碼里的超大 tensor。
CRF 在做 forward 時,函數(shù)_compute_normalizer 里的 next_score shape 是(batch_size, num_tags, num_tags),當做多標簽時,num_tags=1212,(batch_size, 1212, 1212)>>(batch_size, 50, 768),這個 tensor 遠遠大于 bert 的輸入了,多標簽時,16G 顯存 batch size=32,32G 顯存 batch size=80
#shape:(batch_size,num_tags,num_tags)
next_score=broadcast_score+self.transitions+broadcast_emissions
排查到爆顯存的原因之后,也沒找到好的優(yōu)化辦法,CRF 這貨在多標簽時太慢了,又占顯存。
3.3 模型效果
經(jīng)過近 4 天的顯卡火力全開之后,1k+ 類別的模型訓練完成了。使用測試數(shù)據(jù)對模型進行驗證,得到 3 個結(jié)論
-
模型沒有過擬合,盡管訓練數(shù)據(jù)沒有負樣本
-
模型預測準確率高,但召回能力不強
- 模型對單標簽樣本預測效果好,多標簽樣本預測不全,僅能預測 1~2 個,和 2 類似
先說一下模型為什么沒有出現(xiàn)單標簽時的過擬合問題,因為在近 1k 個標簽模型訓練時,學習難度直接上去了,模型不會很快的收斂,單標簽時任務(wù)過于簡單,容易出現(xiàn)過擬合。
驗證模型效果時,先定義怎么算正確:假設(shè)一個標題包含 3 個標簽,預測時要把這 3 個標簽都識別出來,并且標簽值也要對的上,才算正確;怎么算錯誤:識別的標簽個數(shù)少于真實的標簽個數(shù),識別的標簽值和真實的對不上都算錯誤。
使用 105w 驗證數(shù)據(jù),整體準確率 803388/1049268=76.5%,如果把預測不全,但預測對的樣本也算進來的話,準確率(803388+76589)/1049268=83.9%。
對 bad case 進行分析,模型對于 1 個標題中含有多個標簽時,識別效果不好,表現(xiàn)現(xiàn)象是識別不全,一般只識別出 1 個標簽,統(tǒng)計驗證數(shù)據(jù)里標簽個數(shù)和樣本個數(shù)的關(guān)系,這個指標算是標簽個數(shù)維度的召回率
多標簽樣本是指一個標題中包含多個標簽,比如下面這個商品包含 5 個標簽。
標題:“吊帶潮流優(yōu)雅純色氣質(zhì)收腰高腰五分袖喇叭袖連體褲 2018 年夏季”。
標簽:袖長:五分袖;上市時間:2018年夏季;風格:優(yōu)雅;圖案:純色;腰型:高腰。
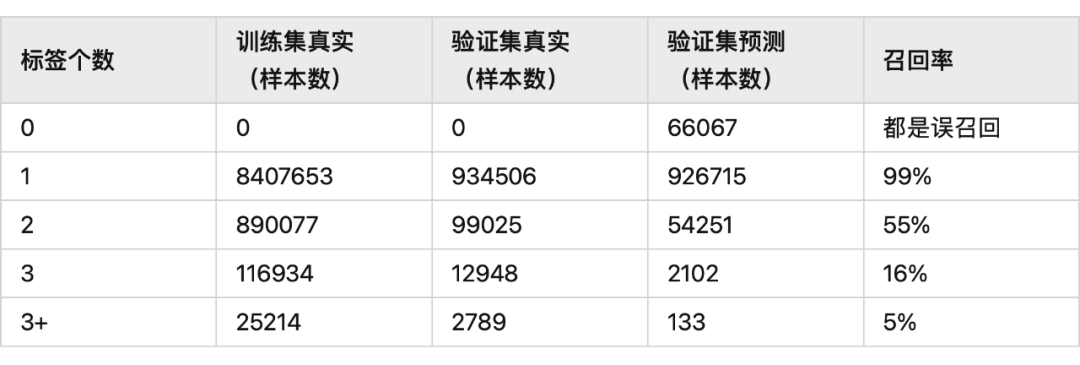
可以看到對于標簽數(shù)越多的標題,模型的識別效果越不好,然后我分析了訓練數(shù)據(jù)的標簽個數(shù)個樣本數(shù)的關(guān)系,可以看到在訓練數(shù)據(jù)里,近 90% 的樣本僅只有一個標簽,模型對多標簽識別效果不好主要和這個有關(guān)系。
所以在構(gòu)建數(shù)據(jù)集時,可以平衡一下樣本數(shù),多加一些多標簽的樣本到訓練集,這樣對多標簽樣本的適配能力也會增強。
但多標簽樣本本身收集起來會遇到困難,于是我又發(fā)現(xiàn)了一個新的騷操作
沒法獲得更多的多標簽樣本提升模型的召回能力咋辦呢?模型不是對單標簽樣本很牛 b 嘛,那在預測的時候,每次如果有標簽提取出來,就從標題里把已經(jīng)預測出的標簽值刪掉,繼續(xù)預測,循環(huán)預測,直到預測是空終止。
第一次預測
input title:吊帶潮流優(yōu)雅純色氣質(zhì)收腰高腰五分袖喇叭袖連體褲2018年夏季
predict label:袖長:五分袖
把五分袖從標題里刪除,進行第二次預測
input title:吊帶潮流優(yōu)雅純色氣質(zhì)收腰高腰喇叭袖連體褲2018年夏季
predict label:上市時間:2018年夏季
把2018年夏季從標題里刪除,進行第三次預測
input title:吊帶潮流優(yōu)雅純色氣質(zhì)收腰高腰喇叭袖連體褲
predict label:風格:優(yōu)雅
把優(yōu)雅從標題里刪除,進行第四次預測
input title:吊帶潮流純色氣質(zhì)收腰高腰喇叭袖連體褲
predict label:圖案:純色
把純色從標題里刪除,進行第五次預測
吊帶潮流氣質(zhì)收腰高腰喇叭袖連體褲
predict label:腰型:高腰
把高腰從標題里刪除,進行第六次預測
input title:吊帶潮流氣質(zhì)收腰喇叭袖連體褲
predict label:預測為空
可以看到,標簽被一個接一個的準確預測出,這種循環(huán)預測是比較耗時的,離線可以,在線吃不消;能找到更多 多標簽數(shù)據(jù)補充到訓練集里是正確的方向。
多標簽 CRF 爆顯存,只能設(shè)定小 batch size 慢慢跑的問題不能解決嘛?當然可以,卷友們提出了一種多任務(wù)學習的方法,CRF 只學習 token 是不是標簽實體,通過另一個任務(wù)區(qū)分 token 屬于哪個標簽類別。
CascadeBertCRF多標簽模型
4.1 模型結(jié)構(gòu)
在標簽數(shù)目過多時,BertCRF 由于 CRF 這貨的問題,導致模型很耗顯存,訓練也很慢,這種方式不太科學,也會影響效果。
從標簽過多這個角度出發(fā),卷友們提出把 NER 任務(wù)拆分成多任務(wù)學習,一個任務(wù)負責識別 token 是不是實體,另一個任務(wù)判斷實體屬于哪個類別。
這樣 NER 任務(wù)的 lable 字典就只有"B"、"I"、"UNK"三個值了,速度嗖嗖的;而判斷實體屬于哪個類別用線性層就可,速度也很快,模型顯存占用很少。
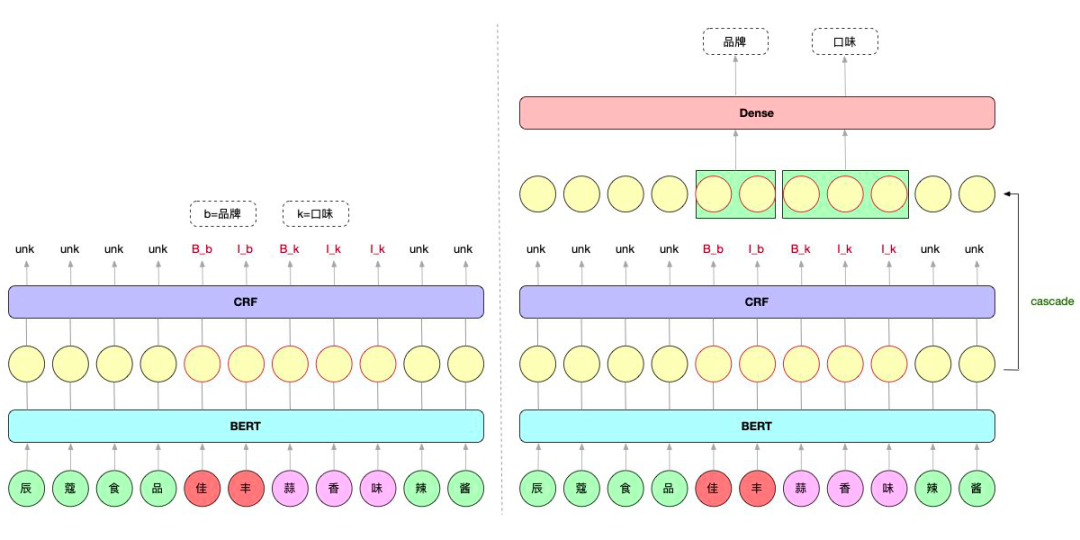
▲ 左單任務(wù)NER模型;右多任務(wù)NER模型
Cascade 的意思是級聯(lián)。就是把 BERT 的 token 向量過一遍 CRF 之后,再過一遍 Dense 層分類。但這里面有一些細節(jié)。
訓練時,BERT 的 tokenx 向量過一遍 Dense 層分類,但不是所有 token 都計算 loss,是把 CRF 預測是實體的 token 拿出來算 loss,CRF 預測不是實體的不計算 loss,一個實體有多個 token,每個 token 都計算 loss;預測時,把實體的每個 token 分類結(jié)果拿出來,設(shè)計了三種類別獲取方式。
比如“蒜香味”在模型的 CRF 分支預測出是實體,標簽對應(yīng) "B"、"I"、"I";接下要解析這個實體屬于哪個類別,在 Dense 分支預測的結(jié)果可能會有四種
-
“蒜香味”對應(yīng)的 Dense 結(jié)果是 “unk”、“unk”、“unk”,沒識別出實體類別
-
“蒜香味”對應(yīng)的 Dense 結(jié)果是 “口味”、“口味”、“口味”,每個 token 都對
-
“蒜香味”對應(yīng)的 Dense 結(jié)果是 “unk”、"口味"、"口味",有的 token 對,有的token 沒識別出
- “蒜香味”對應(yīng)的 Dense 結(jié)果是 “unk”、“品牌”、“口味”,有的 token 對了,有的 token 沒識別出,有的 token 錯了
針對上面 4 中結(jié)果,可以看到 4、3、2 越來越嚴謹。在評估模型效果時,采用 2 是最嚴的,就是預測的 CRF 結(jié)果要對,Dense 結(jié)果中每個 token 都要對,才算完全正確;3 和 4 越來越寬松。
4.2 模型代碼
importtorch
fromcrfimportCRF
fromtorchimportnn
fromtorch.nnimportCrossEntropyLoss
fromtransformersimportBertModel,BertConfig
classCascadeBertCRF(nn.Module):
def__init__(self,bio_num_labels,att_num_labels):
super(CascadeBertCRF,self).__init__()
self.config=BertConfig.from_pretrained('../bert_pretrain_model/config.json')
self.bert=BertModel.from_pretrained('../bert_pretrain_model')
self.dropout=nn.Dropout(self.config.hidden_dropout_prob)
self.bio_classifier=nn.Linear(self.config.hidden_size,bio_num_labels)#crf預測字是不是標簽
self.att_classifier=nn.Linear(self.config.hidden_size,att_num_labels)#預測標簽屬于哪個類別
self.crf=CRF(num_tags=bio_num_labels,batch_first=True)
defforward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
bio_labels=None,
att_labels=None,
):
outputs=self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
sequence_output=outputs[0]
sequence_output=self.dropout(sequence_output)
bio_logits=self.bio_classifier(sequence_output)#(batchsize,sequencelength,bio_num_labels)
num_bio=bio_logits.shape[-1]
reshape_bio_logits=bio_logits.view(-1,num_bio)#(batchsize*sequencelength,bio_num_labels)
pred_bio=torch.argmax(reshape_bio_logits,dim=1)#ner預測的bio結(jié)果
no_zero_pred_bio_index=torch.nonzero(pred_bio)#取出ner結(jié)果非0的token
att_logits=self.att_classifier(sequence_output)#(batchsize,sequencelength,att_num_labels)
num_att=att_logits.shape[-1]#att_num_labels
att_logits=att_logits.view(-1,num_att)#(batchsize*sequencelength,att_num_labels)
outputs=(bio_logits,att_logits)
ifbio_labelsisnotNoneandatt_labelsisnotNone:
select_att_logits=torch.index_select(att_logits,0,no_zero_pred_bio_index.view(-1))
select_att_labels=torch.index_select(att_labels.contiguous().view(-1),0,no_zero_pred_bio_index.view(-1))
loss_fct=CrossEntropyLoss()
select_att_loss=loss_fct(select_att_logits,select_att_labels)
bio_loss=self.crf(emissions=bio_logits,tags=bio_labels,mask=attention_mask)
loss=-1*bio_loss+select_att_loss
outputs=(loss,-1*bio_loss,bio_logits,select_att_loss,att_logits)
returnoutputs
4.3 模型效果
上面提到評估 Dense 的結(jié)果會遇到 4 種情況,使用第 4 種方式進行指標評估;NER 的識別效果和上面一致。
使用 105w 驗證數(shù)據(jù),整體準確率 792386/1049268=75.5%,比 BertCRF 低 1 個點;把預測不全,但預測對的樣本也算進來的話,準確率(147297+792386)/1049268=89.6%,比 BertCRF 高 5 個點;
標簽個數(shù)和預測標簽個數(shù)的對照關(guān)系:
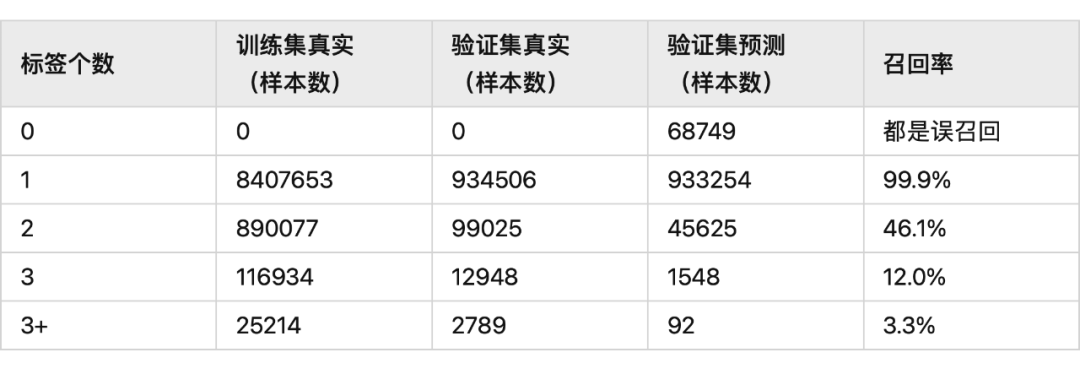
CascadeBertCRF 模型的召回率比 BertCRF 要低,但模型的準確率會高一些。CascadeBertCRF 相比 BertCRF,主要是提供了一種超多實體識別的訓練思路,且模型的效果沒有損失,訓練速度和推理速度有大幅提高。
把實體從標題里刪掉訓練預測的方法也同樣適用 CascadeBertCRF。
審核編輯 :李倩
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24772 -
標簽
+關(guān)注
關(guān)注
0文章
137瀏覽量
17897
原文標題:NER | 商品標題屬性識別探索與實踐
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
數(shù)據(jù)采集標注在智能導航系統(tǒng)中的應(yīng)用案例
AI自動圖像標注工具SpeedDP將是數(shù)據(jù)標注行業(yè)發(fā)展的重要引擎

標貝數(shù)據(jù)標注在智能駕駛訓練中的落地案例

標貝數(shù)據(jù)標注案例分享:車載語音系統(tǒng)數(shù)據(jù)標注
軟通動力入選《人工智能數(shù)據(jù)標注產(chǎn)業(yè)圖譜》
標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

nlp自然語言處理的主要任務(wù)及技術(shù)方法
llm模型有哪些格式
自然語言列舉法描述法各自的特點
如何使用freeRTOS在兩個任務(wù)之間傳輸任務(wù)數(shù)據(jù)?
車載語音識別系統(tǒng)語音數(shù)據(jù)采集標注案例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論