 大模型技術發展背景
大模型技術發展背景
本文根據瀾舟科技創始人兼 CEO 周明、瀾舟大模型技術負責人王宇龍在「瀾舟NLP分享會」演講整理,帶領大家回顧過去 12 個月以來,國內外大模型的發展趨勢,包括百花齊放的國產大模型、新秀不斷涌現的多模態模型、萌芽中的通用能力模型等等,并對大模型新應用、預訓練框架等方面的進展進行了總結。
大模型技術發展背景
此前十余年,人工智能在“感知智能”方面進展非常迅速,涌現了“CV 四小龍”等公司。在 2017 年,谷歌提出了 Transformer 架構,隨后 BERT 、GPT 等預訓練模型相繼提出,2019 年基于預訓練模型的算法在閱讀理解方面超過了人類的水平,此后 NLP 技術在各項任務中都有了大幅度的提升。
AI 從感知智能向認知智能邁進
我們今天看到了一個明顯的趨勢就是 AI 正從感知智能快速向認知智能邁進。AI 正從“能聽、會說、會看”的感知智能,走向“能思考、能回答問題、能總結、做翻譯、做創作”的認知智能,甚至走到“決策、推理”層面了。
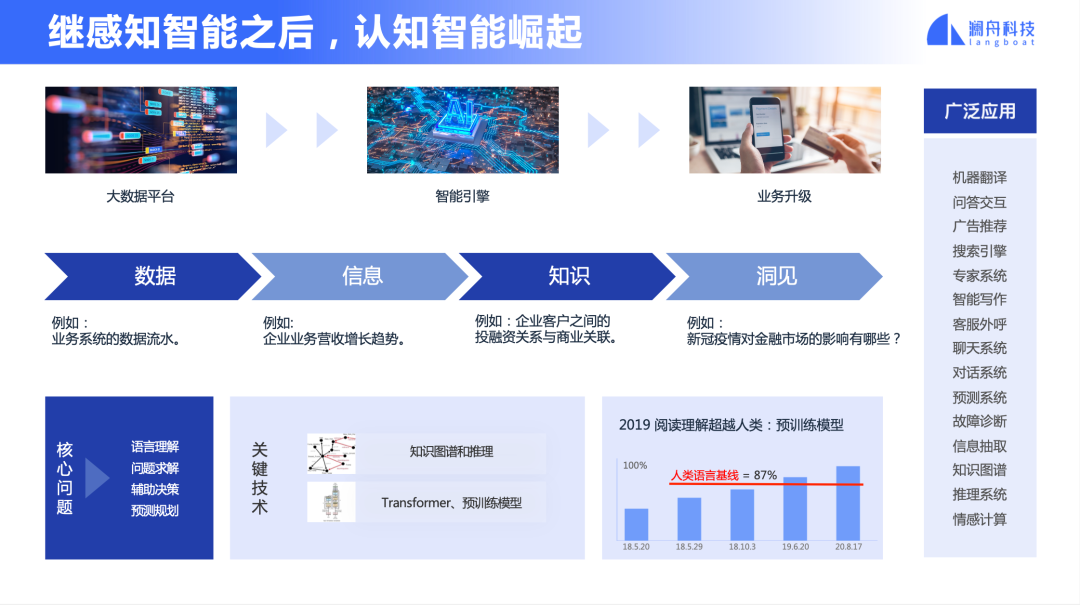
圖 1
如圖 1 右側所示,認知智能的例子比比皆是。比如,達到了接近人類水準的機器翻譯已經在手機和桌面普遍使用;聊天機器人幾乎可以通過圖靈測試;搜索引擎得益于閱讀理解以及預訓練模型,搜索相關度大幅度提升;自動客服系統已經普及;知識圖譜在金融等領域得到快速應用。這些認知智能的能力在加速推動產業發展,從大數據出發到建立信息檢索,再到建立知識圖譜并實現知識推理,再到發現趨勢形成觀點和洞見,認知智能在大數據支持下,推動著企業的業務數智化,正深刻地影響產業的發展。可以說 NLP 和認知智能代表了人工智能的未來發展。
預訓練成為了認知智能的核心技術
剛才說到 2017 年推出的 Transformer,催生了 BERT、GPT、T5 等預訓練模型。這些模型基于自監督學習,利用大規模文本學習一個語言模型。在此基礎上,針對每一個NLP 任務,用有限的標注數據進行微調。這種遷移學習技術推動了 NLP 發展,各項任務都上了一個大臺階。更為重要的是,產生的“預訓練+微調”技術,可用一套技術解決不同語言和不同的 NLP 任務,有效地提升了開發效率。這標志著 NLP 進入到工業化實施階段。
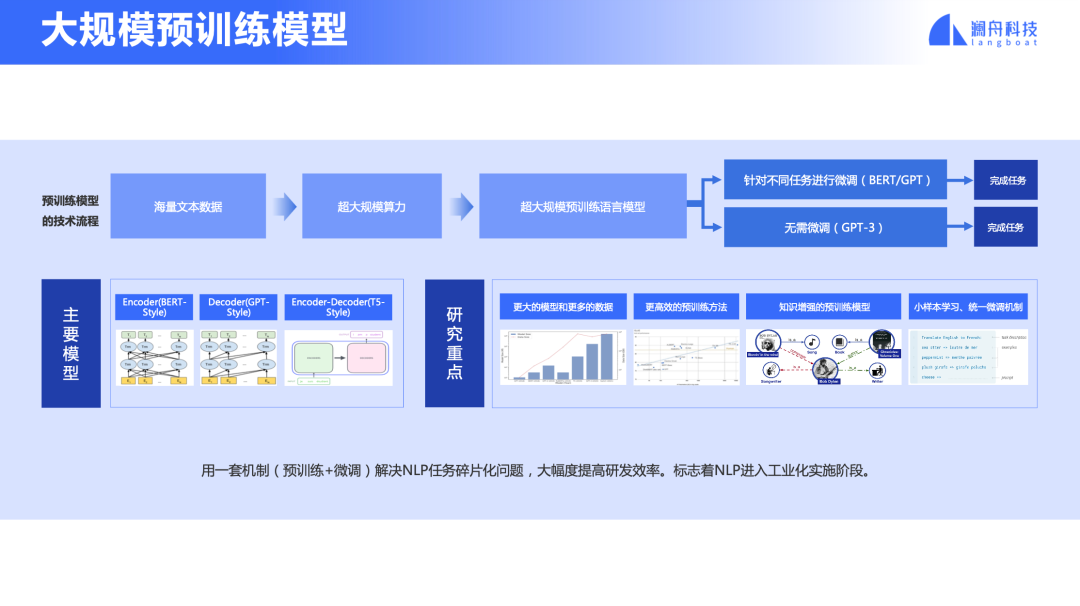
圖2
當前在預訓練模型領域較為關注的研究重點包括:如何訓練超大規模參數的模型、對已有模型架構的創新性研究、更加有效的訓練方法和訓練加速的方法。還有簡化微調的步驟,比如像 GPT-3 那樣用一套提示機制來統一所有下游任務的微調,推動零樣本學習和小樣本學習。除此之外,多模態預訓練模型和推理加速方法也是目前的研究焦點。
NLP領域需要挑戰產品創新和商業模式創新
人們常說創新有三個層次,一個是科研的創新,第二個是產品的創新,第三是商業模式的創新。
我個人認為預訓練模型是目前最具顛覆性的科技創新。可是再偉大的科技創新也要考慮如何推動產品的創新和商業模式的創新。如何從工業界觀點來看,把科技創新貫穿到產品創新,貫穿到商業模式的創新呢?也就是說如何實現認知智能的落地?
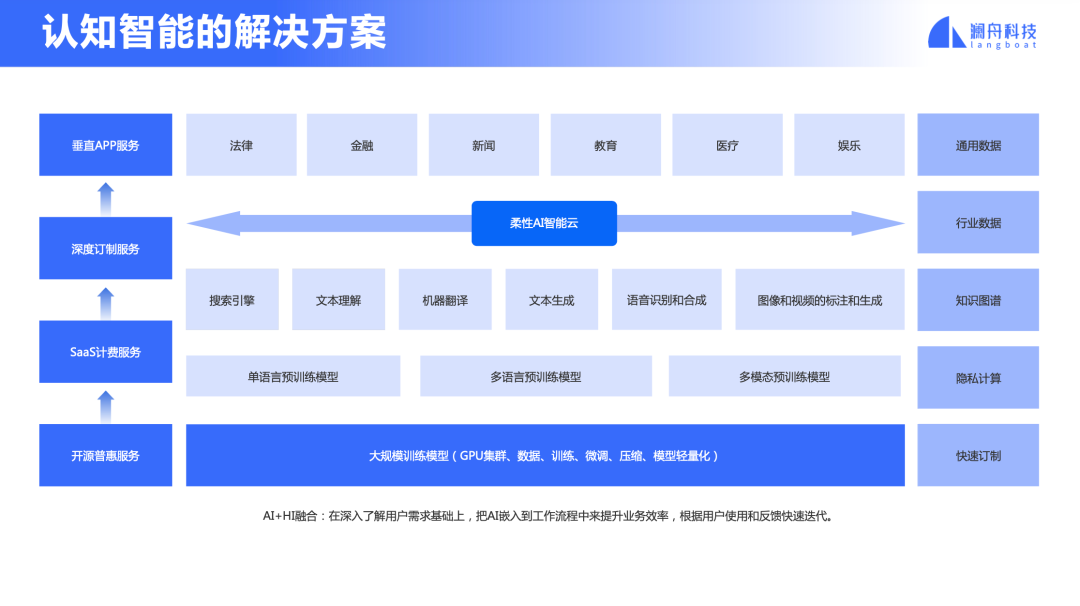
圖 3
這里我跟大家分享如下四個觀點。
模型訓練。首先需要積累各類互聯網數據、包括單語和雙語數據、行業數據。通過實體、關系和時間序列抽取建立知識圖譜。與此同時,建立大規模的預訓練模型支持單語、多語、多模態等各項任務,并進而支持搜索、文本理解、生成、翻譯、語音、圖像、視頻等各項應用。
模型快速適配。要有能力針對某一個行業需求,快速訓練所需的模型。鑒于大模型在落地的時候部署代價大,需要考慮模型壓縮和輕量化。為了解決 NLP 開發碎片化問題,建立一套基于預訓練和微調機制的技術平臺支撐所有語言、所有領域和任務的研發和維護。
柔性AI智能云服務。需要開發柔性AI智能云技術,使得用戶以傻瓜型“拖拉拽”操作方式,“所見即所得”地實現自己的功能,并提供隨著用戶用量靈活調度云資源的彈性服務。
多樣化的服務。通過開源方式提供普惠服務,并建立起品牌和口碑;通過SaaS提供付費服務;通過深度訂制對重要客戶提供優質服務。
這里特別提一下瀾舟科技在預訓練模型方面的研究。2021 年 7月,瀾舟自研的孟子預訓練模型以十億級的規模,榮獲了中文 NLP 比賽 CLUE 第一名。超過了許多大公司的大模型。它具備如下特色:
小:提供 100M 至 1B 參數量的多級別模型,實現低硬件需求和低研發成本。
精:模型結構上引入更多知識,同樣模型體積下可有更好的表現。
快:可用 8 張 3090 卡約 3 天完成一個領域遷移(base 級),8 張 3090 卡半天完成一個任務適應。
專:可對每個領域或者每個任務定制預訓練模型。由于是專用模型,其水平可超過通用的大模型。
目前,我們開源了四個模型(孟子Mengzi-BERT 模型、孟子Mengzi-T5 模型、孟子Mengzi-金融模型、孟子Mengzi-圖文模型),并跟同花順、華夏基金等公司展開緊密合作,此外還通過剛才所說的柔性智能云——“瀾舟認知智能平臺”來釋放我們的能力,并通過SaaS服務廣大客戶,以實現科技創新到產品創新到商業模式的創新全貫通。
國內外預訓練模型近一年的新進展
下面我就快速講一下過去 12 個月以來,預訓練模型國內外發展的一些新的狀況。
我試圖用一張圖按照時間順序來概括過去一年多大模型的進展。雖然我盡量概括全部,但是由于時間有限,或者水平和眼界所限,可能會漏掉某些重要的工作。
國內大模型百花齊放

圖 4
首先我想介紹國內的一些進展,國內有關公司和學校的預訓練模型研究非常令人關注(圖 4 高亮的部分)。
今年4月,華為云發布了盤古系列超大預訓練模型,包括中文語言(NLP)、視覺(CV)大模型,多模態大模型、科學計算大模型。華為云盤古大模型旨在建立一套通用、易用的人工智能開發工作流,以賦能更多的行業和開發者,實現人工智能工業化開發。
清華和騰訊推出的 CokeBert,雖然模型小,但是根據上下文動態選擇適配的知識圖譜的子圖,在利用知識增強預訓練方面(簡稱知識增強)有一定特色。
孟子是瀾舟自研的模型,走輕量化路線,覆蓋多語言和多模態,理解和生成,去年 7 月在 CLUE 登頂。
中科院自動化所推出紫東太初,它是融圖、文、音三模態于一體(視覺-文本-語音)的三模態預訓練模型,具備跨模態理解與跨模態生成能力。
智源研究院也在不斷推出新模型,覆蓋文本和多模態。
沈向洋博士領導的大灣區 IDEA 研究院推出了二郎神模型,其中“二郎神-1.3B”模型在 FewCLUE 和 ZeroCLUE 上都取得榜一成績。
當然,其他大公司也都推出了他們自己的新模型,比如阿里的 M6 采用相對低碳方式突破 10萬億,有多模態、多任務;百度的 ERNIE 3.0 是融合了大量知識的預訓練模型,既用了自回歸,也用了自編碼,使得一個模型兼具理解和生成。這里不再贅述細節。
多模態模型新秀涌現

圖5
圖 5 highlight 了一些新的多模態模型,比如微軟亞洲研究院提出的一個可以同時覆蓋語言、圖像和視頻的統一多模態預訓練模型——NüWA(女媧),直接包攬 8 項 SOTA,還有其文檔理解的 LayoutLM 也有了新的進展。當然谷歌的 ImageN 和 OpenAI 的 DALL-E 2,實現了更強大的“文一圖”生成能力,也引起廣泛關注。
通用能力模型萌芽
我也注意到,把大模型拓展可以構建某種意義上的通用能力模型。比如,OpenAI 的 VPT 模型:在人類 Minecraft 游戲的大規模未標記視頻數據集訓練一個視頻預訓練模型,來玩 Minecraft。
而 Deepmind 用預訓練構建了一個 AGI 智能體 Gato,它具有多模態、多任務、多具身(embodiment)特點,可以玩雅達利游戲、給圖片輸出字幕、和別人聊天、用機械臂堆疊積木等等。Gato 使用相同的訓練模型就能玩許多游戲,而不用為每個游戲單獨訓練。DeepMind 這項最新工作將強化學習、計算機視覺和自然語言處理這三個領域合到一起。
它們都試圖把大模型的概念推廣到一個相對通用的人工智能領域。像 Gato,它具備多模態、多任務、多具身的特點,可以玩多種游戲,用一個模型來覆蓋多個游戲,而不是說為每個游戲單獨訓練一個模型。實際上把強化學習、計算機視覺和自然語言處理這三個領域試圖合在一起。
小結
總的來講,小樣本,零樣本取得了新的進展,SOTA模型的尺寸在降低,檢索增強的預訓練模型逐漸成為主流技術。多模態模型能力提高很快,從圖、視頻、聲音、code、甚至擴展到AGI。我們也看到了很多新的應用。
以上只是非常 high level 地概括最近預訓練的發展,下面我們會更詳細地說明。
預訓練之“不可能的三角”
下面具體介紹近期有亮眼進展的預訓練模型。
大家可能都知道在分布式系統里有 CAP 定理,該定理指出,對于一個分布式計算系統來說,不可能同時滿足“一致性”、“可用性”、“分區容錯性”。類似的,去年有一篇論文提出了預訓練模型“不可能三角”理論(圖6) ,三角形頂端分別是“合理的模型尺寸”、“先進的小樣本能力”以及“先進的微調能力”,一個模型很難兼顧這三點,大多數模型只能做到其中一點或者兼顧兩點。
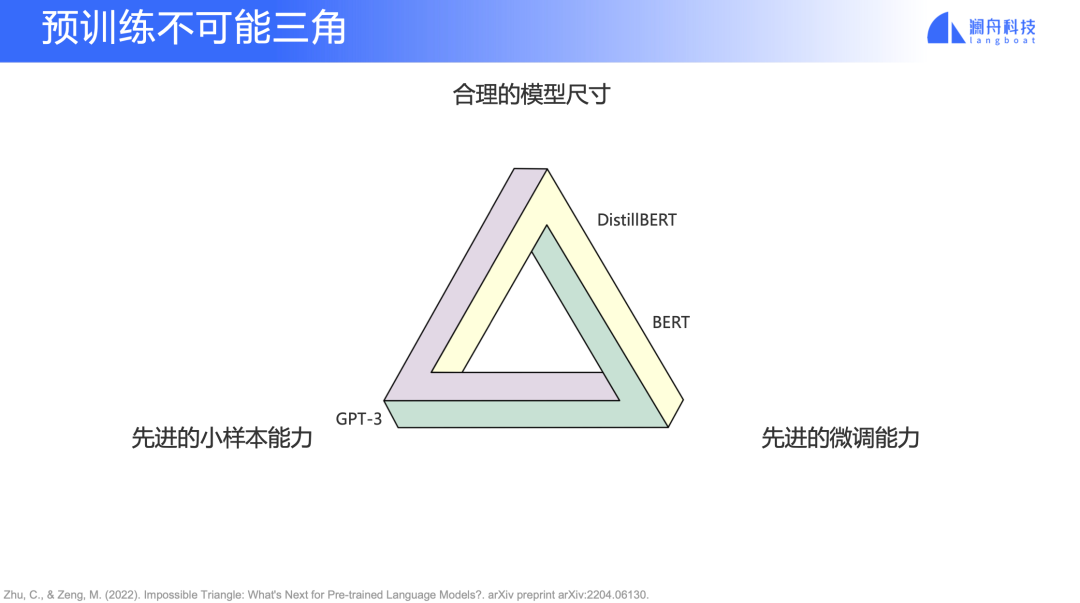
圖6
比如 GPT-3 小樣本表現較好,但是模型較大,finetune 效果表現并不是那么好;BERT 和 DistillBERT 就是另外一個典型,那它們的模型尺寸可能沒有那么大,然后微調能力也很好。但是它們在小樣本和零樣本上的表現就是會比較差。
但是最近半年我們也看到一些改進:在保證和 GPT-3 效果相當的前提下,去減小模型參數量。下面我們分開來講。
FLAN (Google)
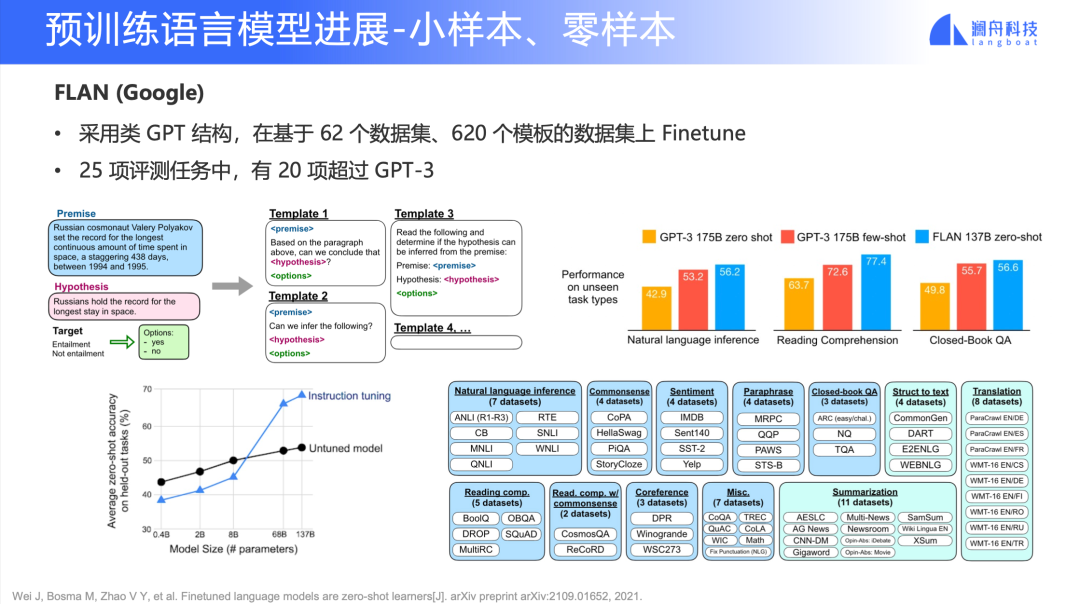
圖 7
Google 去年提出了 FLAN,一個基于 finetune 的 GPT 模型。它的模型結構和 GPT 相似。但是不同于 GPT-3 的是,它基于 62 個數據集,每個數據集構造了 10 個 Prompt 模板,也就是總共拿到 620 個模板的數據之后再進行 finetune。
我們可以看到圖 7 右側,FLAN 的這個模型參數只有 137B,相比于 GPT-3 的 175B 有大幅降低,但是 FLAN 在一些下游任務 few-shot 和 zero-shot 上表現卻變得更好。這給我們帶來一個啟示:我們不是必須去用像 GPT-3 級別超大規模的語言模型,而是通過更多的監督數據(而不是純粹做無監督的訓練),去降低模型規模,同時拿到更好的模型效果。
當然 FLAN 也會有些約束條件。如圖 7 左下角所示,finetune 所帶來的效果在 8B 以上的參數量才能夠實現。
T0 (BigScience)
下圖是 Huggingface 發起的“BigScience” workshop 中的一項工作,該模型取名為 T0。T0 選擇的是 T5 的架構,但是它的數據量更多。T0 總共構造了 171 個數據集,最終構造了 2000 個多樣的 Prompt 模板,最終用 11B 參數量(GPT-3 的 1/16)達到了和 GPT-3 相似的效果。
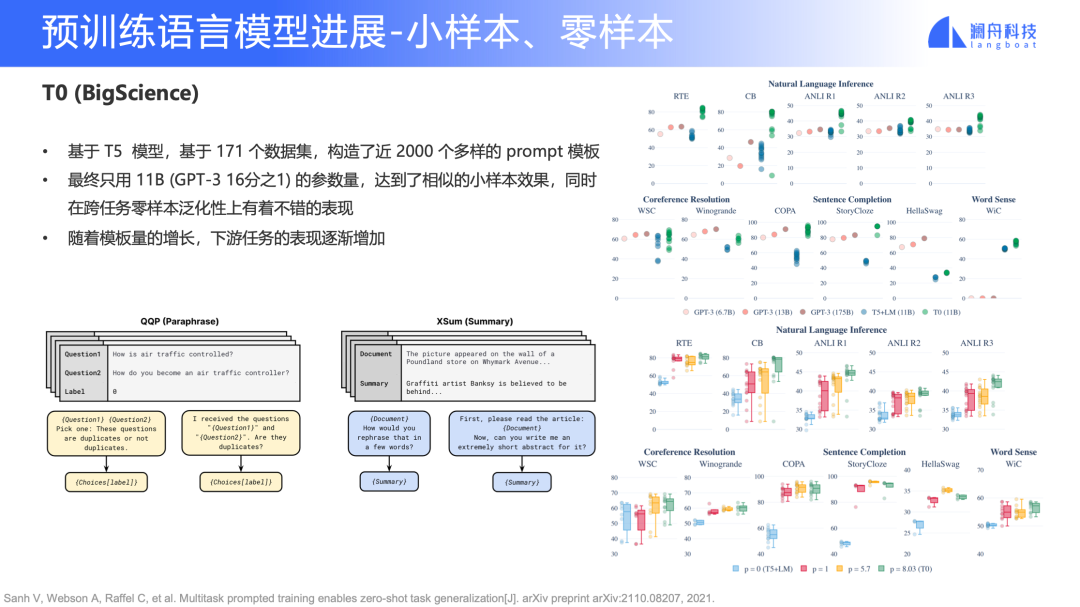
圖 8
如圖 8 右下角所示,我們可以看到隨著 Prompt 的數量增加,下游任務表現也會逐漸地變好。這也啟發我們,是不是可以通過不斷增加任務數量以及構造更多樣化的 Prompt 模板,不停地把這個超大規模語言模型的參數量壓縮得更小?比如,上面 FLAN 是 137B,T0 現在是 11B,那如果我們再去增加數據量,或者再增加 Prompt 數量,參數是不是還有更高的壓縮空間?這個也是值得探索。
CoT
這個是最近挺有話題性的一篇文章。邏輯比較簡單,主要在探索“在 GPT-3 上,我們選擇不同的 Prompt 是不是還有更好的表現”。

圖 9
如圖 9 左下角的表格所示,在一個任務上,它的 zero-shot 大概是 17.7 分,但是選擇“Let's think step by step” 這個 Prompt,分數直接漲到 78 分。
這說明一些問題,一方面是超大規模的預訓練語言模型其實還有很多挖掘的空間,另一方面,Prompt 魯棒是一個很大的問題。如果我們要落地這樣的模型會增加工程難度。就像我們之前做語言或者視覺方向上的特征工程一樣,不同的特征工程對下游任務的最終表現影響是特別大的。
RETRO (DeepMind)
除了多任務之外,還有一個新趨勢是檢索增強。早一些在做檢索生成的時候,我們用到 REALM 和 RAG 等模型。而 RETRO 模型是 DeepMind 去年 12 月份左右提出的,它的主要思路是,除了使用這一個大規模預訓練語言模型掌握語料知識之外,還可以把知識從這個模型中解耦,獨立成一個單獨的檢索模塊,把這些知識放到一個數據庫里面。
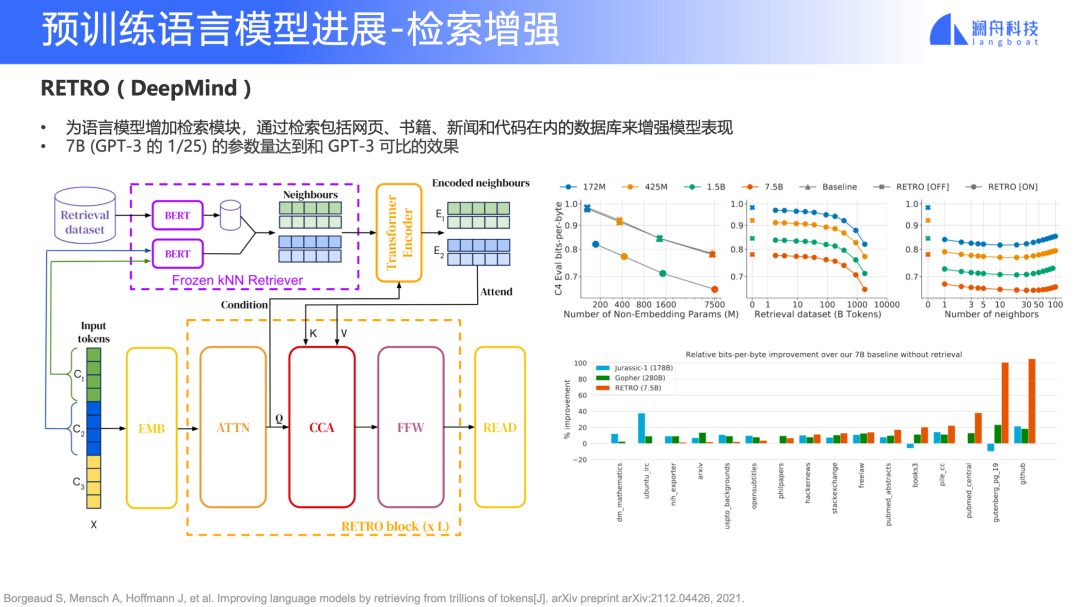
圖 10
RETRO 只用了 7B 參數(相當于 GPT-3 的 1/25),就可以達到和 GPT-3 可比的效果。這也證明了提高模型效果并不只有增加參數量一條路。同時還能通過數據庫更新的方式實時加入新的知識(OpenAI 的 GPT-3 API 只有 2020 年 8 月前的知識)。
當然 RETRO 也會有一些要求限制。如圖 10 左上角所示,它對檢索庫的數據量有很高要求,在 1T Tokens 左右才能達到相似效果,這也是后續要解決的問題。
WebGPT (OpenAI)
WebGPT 其實跟 RETRO 很相似,我們可以從兩個角度來看:
1. WebGPT 引入了外部知識,讓 GPT-3 學會像人類一樣去學會使用瀏覽器獲取知識;
2. WebGPT 不僅僅是像 RETRO 一樣直接引入一個外部的檢索模塊,它還會利用強化學習的方法,通過 6k 條人類的搜索行為數據讓 GPT-3 模仿人類的搜索方式

圖11
小結一下,從上面 FLAN、T0、CoT、RETRO、WebGPT 的工作來看,在 GPT-3 模型的基礎上,我們可以通過增加多任務、Prompt 和增加檢索模塊,在更小的參數量級上達到 GPT-3 175B 相同水平的效果。之前只能在 GPT-3 中看到的小樣本、零樣本能力,未來通過更小參數量的模型在工業界中落地的可能性會越來越大,大量場景中的標注成本將會繼續降低。未來,這一能力這將為我們帶來全新的商業場景,讓沒有 NLP 算法團隊的公司也能更容易、低成本的獲得定制化的 NLP 能力。
多模態模型
DALL·E 2(Open AI)和 Imagen(Google)
多模態方面近期有很多進展,今年,OpenAI 發布了 DALL·E 2,Google 發布了 Imagen。雖然兩個模型權重都未公開,但從釋放出的大量示例來看,圖片的真實度、分辨率都有較為明顯的進步。我們已經到了需要討論這項技術商業化落地的時間點了。當然,目前模型還存在的各種?險和限制也是我們要考慮的問題,比如暴恐、低俗的文字輸入、版權?險、來自數據的偏?等。
以往關于文本生成圖像的研究,除了最早出現的 GAN,大體可以分成兩種思路:
一種是基于自回歸模型,將文本特征和圖像特征映射到同一空間,再使用類似于 Transformer 的模型架構,來學習語言輸入和圖像輸出之間的關系。比如 DALL-E 和 CogView,就采用了這一思路。
另一種則是基于擴散模型的方式,DALL·E 2 和 Imagen 就屬于這一類。可以看到的是,這些模型產生的圖像分辨率更高,效果更好。

圖 12
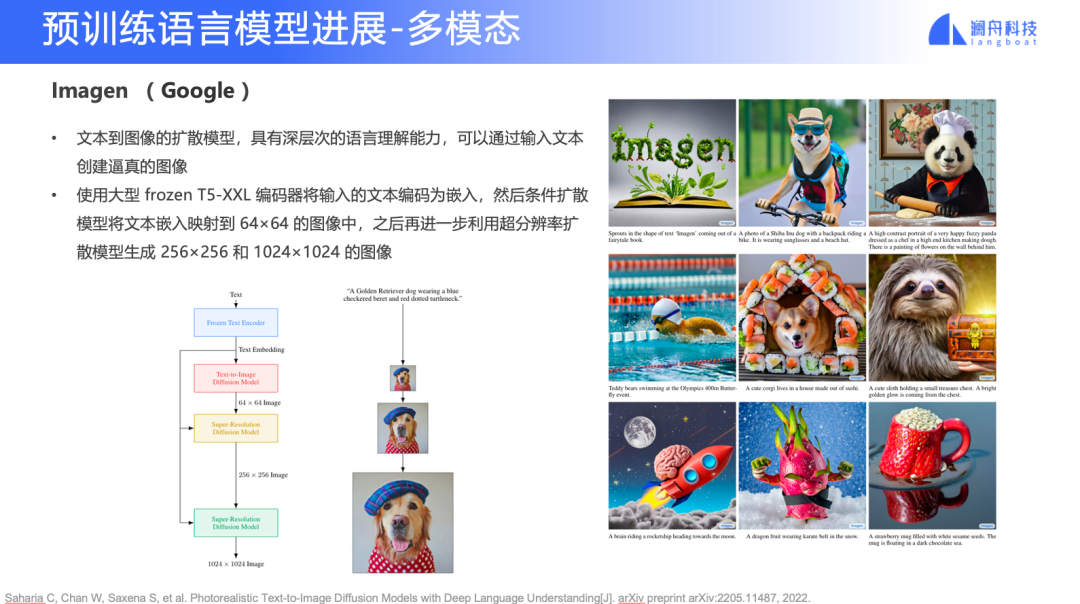
圖13
LayoutLM v3
LayoutLM 在文檔理解和智能文檔領域有非常重要作用,這方面的工作已經推出了第三代。相比前一代,它用 patch embedding 來代替之前 CNN 的 backbone,使用統一的文本和圖像的 mask 任務。
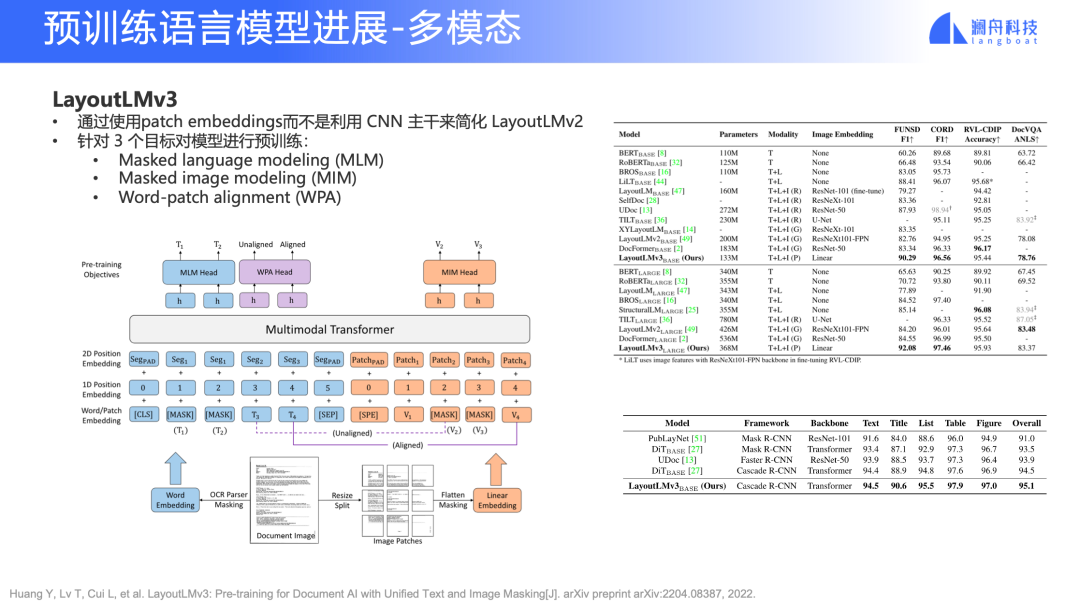
圖 14
在 NLP 領域,我們不僅僅要面對文字,還有更多復雜的、未經處理的 PDF、Word 文檔等,所以 LayoutLM 是一個非常值得關注的工作。
VPT
視頻領域的預訓練模型 VPT 應該算得上是一個里程碑式的工作。
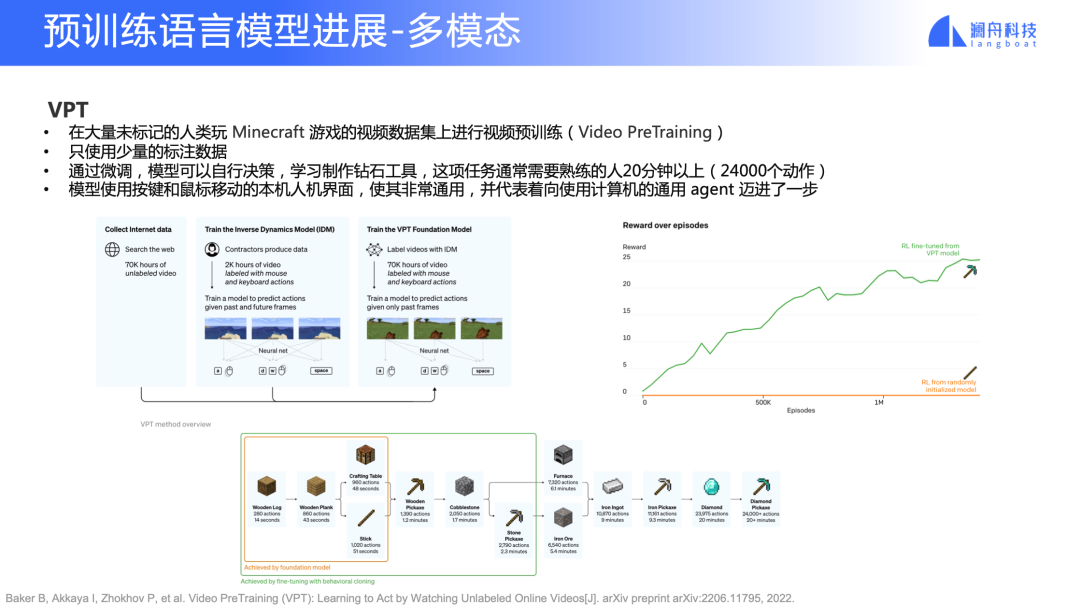
圖 15
這里要先簡單介紹一下 Minecraft,它是一個開放式的游戲,玩家可以在一個三維世界里采集資源,然后按照一個技能樹去創造不同的工具和物品。一般人類玩家會先采集木頭(如圖 15 下半部分所示),然后制造一些工具,再采集石頭、鐵,最后采集鉆石。整個游戲流程中需要進行不同類型的決策,除了要在三維世界里采集這些東西,玩家還要決定怎么制造道具。普通人類玩家——以我個人經驗——差不多半個小時才能完成整個流程。這是首次有 AI 算法能使用和人類一樣的交互(視頻+鍵鼠)完成這個任務。
VPT 里大量使用了預訓練。除了用大量無標注的視頻數據做了預訓練,還加入了少量的人工標記去學習人類行為。如圖 15 右側所示,我們可以看到,沒有使用預訓練的方法是很難完成這個工作的。所以,這給我們帶來一些想象空間——預訓練和強化練習,或者和機器人進行結合,能夠像人類一樣解決一些很通用的任務,可能會產生新的落地場景。
Gato (DeepMind)
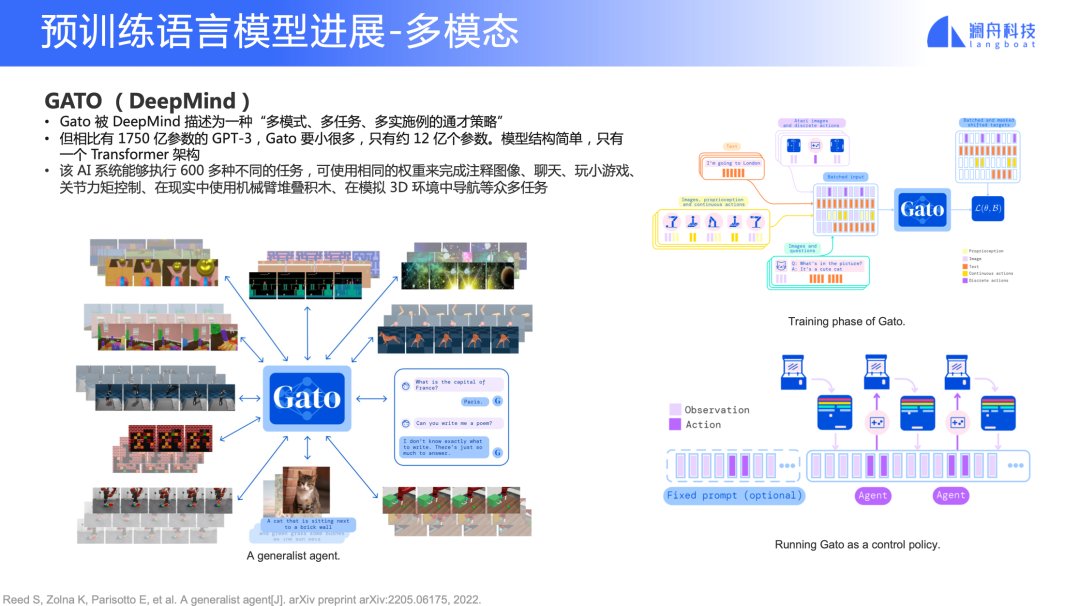
圖 16
DeepMind 提出的 Gato 是用一個單一的預訓練模型完成很多不同的任務。模型結構簡單,只有一個 Transformer 架構,只有約 12億參數。Gato 能夠執行 600 多種不同的任務,可以使用相同的權重來完成注釋圖像、聊天、玩小游戲、bu關節力矩控制、在現實中使用機械臂對疊積木、在模擬 3D 環境中導航等等任務。
這啟發我們,Transformer 架構實際上是有一定通用性的。不僅是能夠完成文字類理解工作,甚至打游戲、視頻相關的任務,它都能做。這意味著我們將來也許可以用一套更統一的框架來做更多事情。在工業界來說,就是用更低的成本來做預訓練微調、解決不同場景的問題。
新應用 —— Copilot
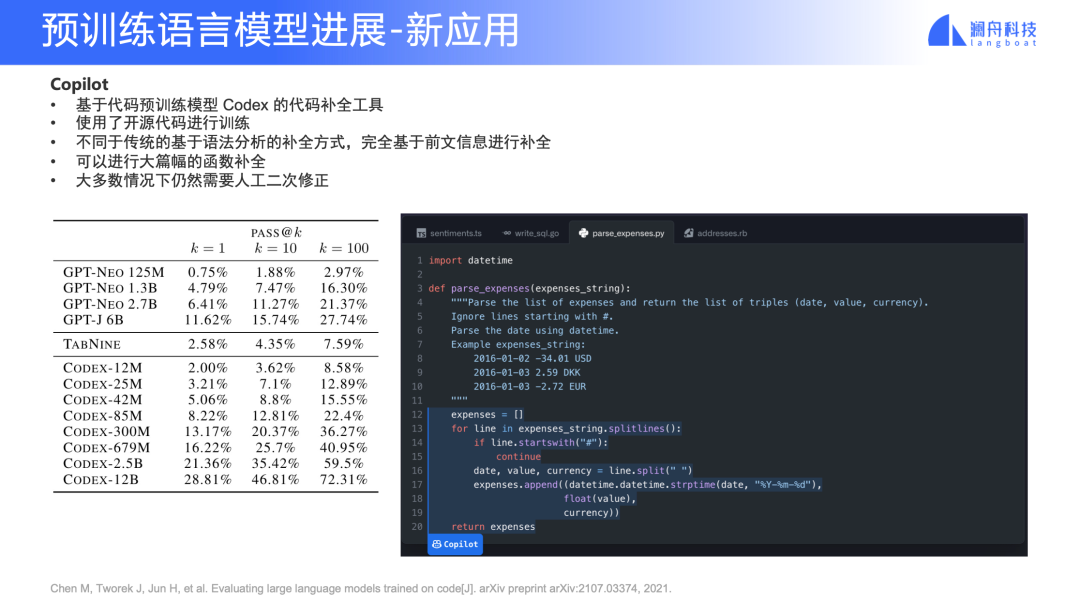
圖 17
Copilot 已經是非常落地的一個應用了,很多開發者的體驗反饋都是“非常驚艷”。傳統的代碼補全,通常用語法樹解析去做預測。由于這個原因,對于解釋性的語言的補全做得并不是很好,比如大家常用的 Python。當然,我們也知道有一些廠商做得可能稍微好一點,但相比于 Copilot 這種基于預訓練的工具,屬于不同“代次”。
Copilot 可能會對傳統的 IDE 行業產生非常大沖擊。
舉一些具體的例子,我們一般寫代碼可能會輸入一個符號,然后按一下鍵盤上的 “.” 來進行補全出 class 、function、symbol 等等。但是 Copilot 用法往往是這樣:先寫一個函數名稱,再寫幾行注釋,它就能夠把函數的 5 到 10 行代碼直接補全出來,當然也不是非常完美,有時候需要我們手動做二次修改,但相對于傳統 IDE 是完全不同的體驗。
除了可以把 Copilot 當做代碼補全工具之外,也能把它當做替代 stackoverflow 的檢索工具。以往寫一些簡單、重復性的代碼片段,我們可能要去搜 stackoverflow,看看其他人分享的代碼。但是有了 Copilot 之后,stackoverflow 的使用率會變得很低。因為基本只要寫注釋就能讓 Copilot 幫你完成一些簡單的工作。
預訓練框架進展
JAX
除了模型之外,底層的預訓練框架也是非常重要的。最近一年,我們可以看到預訓練框架領域有了新的進展。
JAX 不是一個新的框架,它在 2018 年就已經問世了。2020 年 DeepMind 表示他們在用 JAX 去做他們的研究工作。相比 PyTorch,JAX 引入了 XLA 帶來了速度提升、顯存消耗下降,同時 API 形式是非常像NumPy,大家用起來會非常輕松。

圖 18
我們更關注的是基于這套框架之上的預訓練領域框架,如 T5X,最近 Google的工作很多用 T5X 實現。T5X 跟 Pathway 的思路會很接近,即通過一套框架讓研究員很輕松地去調整設置,用不同架構完成預訓練。目前在 Huggingface 上大多數模型也都已經有對應的 JAX 版本了。但是這個框架也有一些問題,由于它設計的思路,要求大家用函數式編程的思路寫純函數,那么對大多數沒有接觸過函數式編程語言(如 Lisp,Haskell 等)的人來說會有一定的上手門檻。
Megatron-DeepSpeed
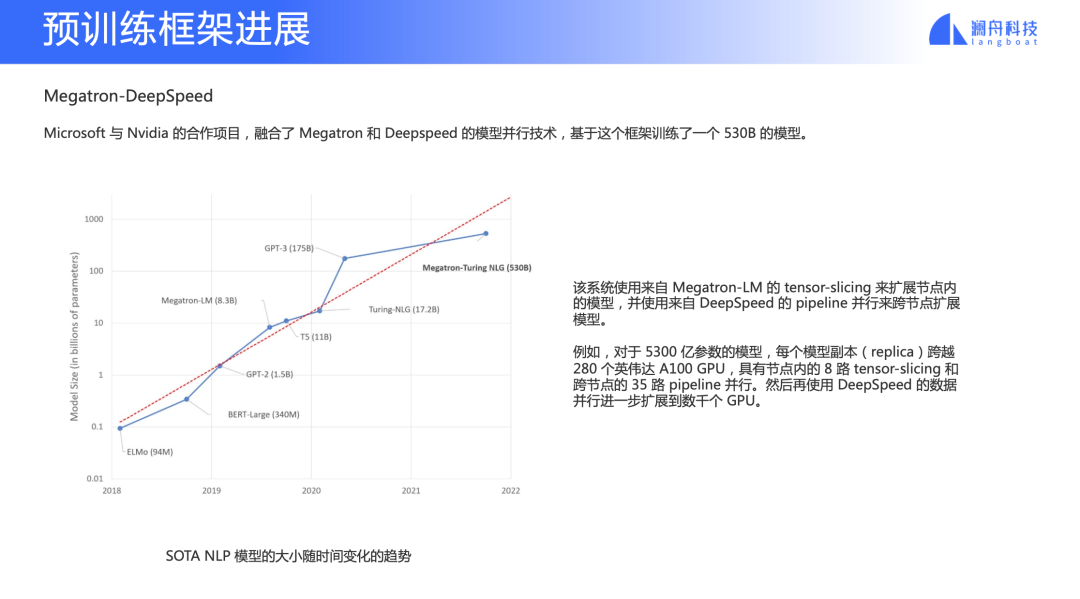
圖 19
Megatron 和 DeepSpeed 是兩個很重要的預訓練框架。Megatron 是英偉達做的超大規模預訓練模型框架,主要是利用 tensor parallel 做性能優化以及 mode parallel。DeepSpeed 是微軟團隊做的深度學習加速框架。這兩個團隊去年合作構造出 Megatron-DeepSpeed 框架,相當于是把兩個框架的特點結合在一起,并用它訓練一個 530B 的模型。后面會講到的 BLOOM 模型也是基于這個框架的一個 fork 去做的。
ColossalAI

圖 20
ColossalAI 是潞晨科技的開源項目,是 Megatron-DeepSpeed 有力的競品,社區也非常活躍。它給大家帶來一個非常直觀的結果就是預訓練成本降低了,在消費級的顯卡上也可以做一些訓練,相比 MegatronLM 更省力。
大教堂到集市:大模型研究的平民化
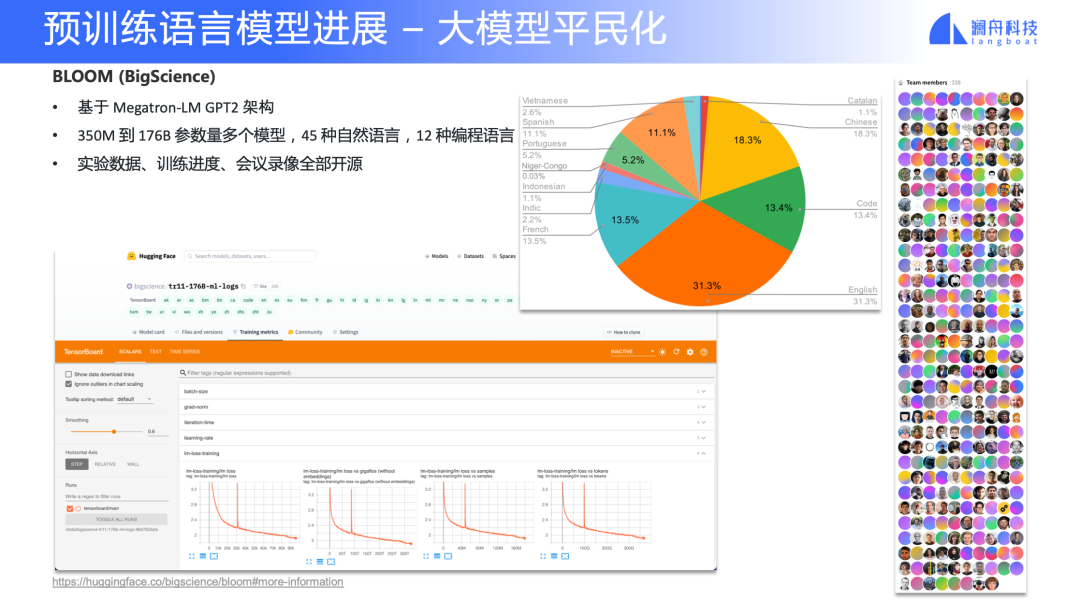
圖 21
最近大家可能關注到 BLOOM 模型,這是來自 BigScience 的一項工作。這其實是近半年以來的一個新趨勢——大模型平民化。BLOOM 模型在 7月中旬剛完成了最大規模 176B 的模型訓練,Benchmark 過兩天應該會出來,大家感興趣可以去 Slack 圍觀進度。除了 BLOOM,最近 Meta 也開源了 OPT, EleutherAI 也開源了 GPT-Neo。
除了關注 BLOOM 模型本身,我們還要關注到它的項目組織形式。與 GPT-3 純閉源的、頂級大廠內部研究不同,這個項目從立項開始就是開放的。其開源內容不僅是模型本身,還包含了數據治理、模型結構探索、實驗數據、訓練日志、線上會議錄像等資料。大家可以去看一下他們中間經過了幾次波折、訓練中止這些問題怎么解決的。這是一個非常寶貴的資源,預計在后續半年內,BLOOM 模型還有很多迭代工作。
總結
最后總結一下本次演講的內容。
繼感知智能之后,認知智能已經崛起,最重要一個因素是“預訓練+微調”技術的發展,相比于之前的特征工程,“預訓練+微調”可以大大提升開發效率,也意味著我們可能用更統一的方式,讓 NLP 能力在工業界落地。
最近一年,小樣本和零樣本技術也取得不錯進展,通過這種多任務或多 Prompt 的形式,訓練出的模型規模越來越小,讓大家可以開始關注零樣本商業化落地的可能性。
通過檢索增強,能夠把模型和知識解耦,讓模型變得更加輕量化。
近期在多模態領域涌現出非常多的新工作,模型能力提升非常迅速,也到了考慮商業化可能性的時間節點;多模態預訓練和強化學習的結合也是一個新的趨勢。
多個預訓練框架齊頭并進,這些框架的改進將幫助研究員和工業界更輕松地去解決預訓練的諸多問題。
開源訓練框架的出現,未來或許會使得超大規模預訓練模型技術壁壘逐漸消失。
審核編輯 :李倩
-
人工智能
+關注
關注
1793文章
47604瀏覽量
239547 -
nlp
+關注
關注
1文章
489瀏覽量
22066 -
大模型
+關注
關注
2文章
2524瀏覽量
2998
原文標題:一文看懂預訓練模型最新進展
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
探討大模型時代背景下數據存儲的變革之道
納微半導體亮相2024亞洲電源技術發展論壇
直流高壓電源技術發展淺析
開關電源的最新技術發展趨勢
揭示大模型剪枝技術的原理與發展
智能駕駛技術發展趨勢
簡述中軟國際模型工場服務場景
SDV的發展背景背景與功能
無線充電技術發展趨勢
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
揭秘氣候技術發展的關鍵平臺Earth-2的核心—CorrDiff
張宏江深度解析:大模型技術發展的八大觀察點

巖土工程中的振弦采集儀技術發展與前景展望






 工商網監
工商網監
評論