 全球首款一站式處理因果學習完整流程的開源算法工具包
全球首款一站式處理因果學習完整流程的開源算法工具包
根據福布斯的統計數據,全球范圍只有 13% 左右的機器學習項目能夠真正上線運行,項目失敗的一個重要原因是模型的泛化能力不足,在真實數據上的表現和完全達不到訓練數據上的效果。 隨著機器學習建模越來越多的應用,企業對人工智能的要求也在進一步提高。近幾年提及的「數智化」核心是智能決策,以數據驅動的方式實現自動化決策來提高整體運營效率。用戶的需求的重心從預測性分析向指導性分析升級轉移,預測性分析是告訴企業未來可能會發生什么,指導性分析也叫處方性分析,是告訴企業我們如果想要實現一個目標需要如何做,這是典型的智能決策問題。 機器學習主要用在預測性分析上,基本上沒有能力解決指導性分析這樣的決策問題,因此,因果學習正被學界和業界逐漸重視起來,其可以補充機器學習的一些短板,也滿足了智能決策這類問題的需求。因果推斷的重要性逐漸顯示,被認為是人工智能領域的一次范式革命。 7 月 12 日,九章云極 DataCanvas 發布了 YLearn 因果學習開源項目,是全球首款一站式處理因果學習完整流程的開源算法工具包。 一個典型的完整因果推斷流程主要由三個部分組成。圖靈獎得主 Judea Pearl 曾表示,現有的機器學習模型不過是對數據的精確曲線擬合,只是在上?代的基礎上提升了性能,在基本的思想方面沒有任何進步。
-
第一,數據中的因果結構應當首先被學習和發現,用作這一任務的手段通常被稱為因果發現(causal discovery)。這些被發現的因果關系會被表示為因果結構公式(structural causal models, SCM)或因果圖(一種有向無環圖,directed acyclic graphs, DAG)。
-
第二,我們需要將我們感興趣的因果問題中的量用因果變量(causal estimand)表示,其中一個例子是平均治療效應(average treatment effect, ATE)。這些因果變量接下來會通過因果效應識別轉化為統計變量(statistical estimand),這是因為因果變量無法從數據中直接估計,只有識別后的因果變量才可以從數據中被估計出來。
-
最后,我們需要選擇合適的因果估計模型從數據中去學些這些被識別后的因果變量。完成這些事情之后,諸如策略估計問題和反事實問題等因果問題也可以被解決了。
GitHub 開源地址:https://github.com/DataCanvasIO/YLearn YLearn 的應用目前主要集中在兩個方向: 用于彌補機器學習理論上的缺陷。在機器學習模型中加入因果機制,利用因果關系的穩定性和可解釋性,優化模型、提升效率; 幫助實現用戶需求從預測到決策的遷移,例如使用基于因果推斷的推薦算法幫助企業進行客戶增長和智能營銷等。 它具有一站式、新而全、用途廣等特點:
-
一站式:通常的因果學習流程包括從數據中發現因果結構,對因果結構建立因果模型,使用因果模型進行因果效應識別和對從數據中對因果效應進行估計。YLearn 一站式地支持這些功能,使用戶以最低的學習成本使用與部署因果學習。
-
新而全:YLearn 實現了多個近年來在因果學習領域中發展出的各類算法,例如 Meta-Learner、Double Machine Learning 等。也將一直致力于緊跟前沿進展,保持因果識別與估計模型的先進和全面。
-
用途廣:YLearn 支持對估計得到的因果效應進行解釋、根據因果效應在各種方案中選取收益最大的方案并可視化決策過程等功能。除此之外,YLearn 也支持將因果結構中識別出的因果效應的概率分布表達式以 LaTex 的形式輸出等小功能,幫助用戶將因果學習與其他方向交叉。
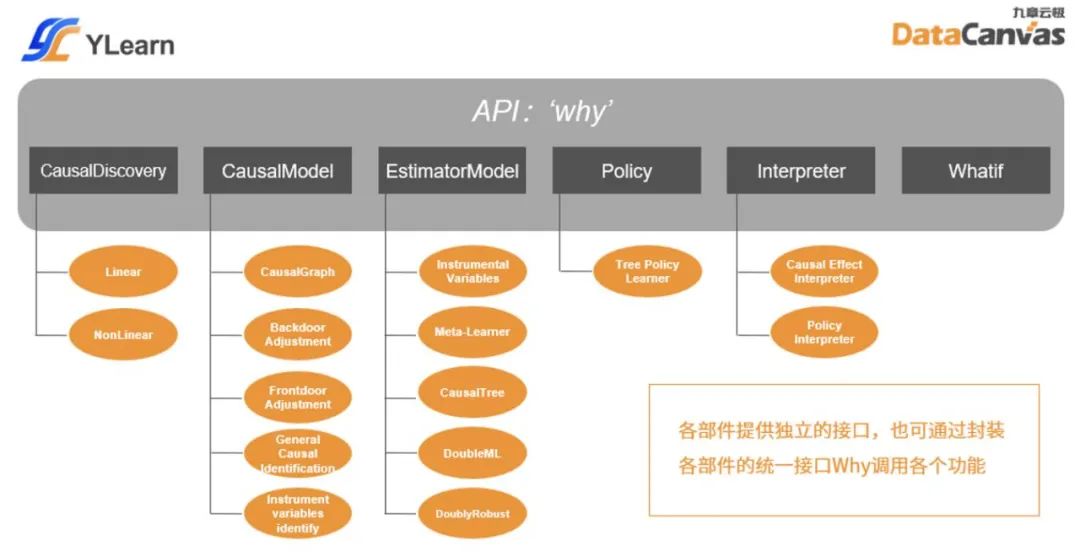
- CausalDiscovery. 發現數據集中線性和非線性的因果關系并用因果圖表示。
- CausalModel. 確定感興趣的因果量之后,識別因果圖中的工具變量,操作因果圖,識別因果效應(Causal Effect)的估計表達式,也可判斷給定集合是否可以作為后門調整集合,前門調整集合等。
- EstimatorModel. 給定因過量的估計表達式與訓練數據集,從訓練數據集中訓練多種估計模型,使用訓練好的估計模型在新的測試數據集上估計因果效應。
- Policy. 給定感興趣的因果效應和數據集,尋找一種最佳方案以提升因果效應,獲取理想收益。
- Interpreter. 解釋估計模型(EstimatorModel)所預測的因果效應,解釋策略模型(Policy)所給出的最佳方案。
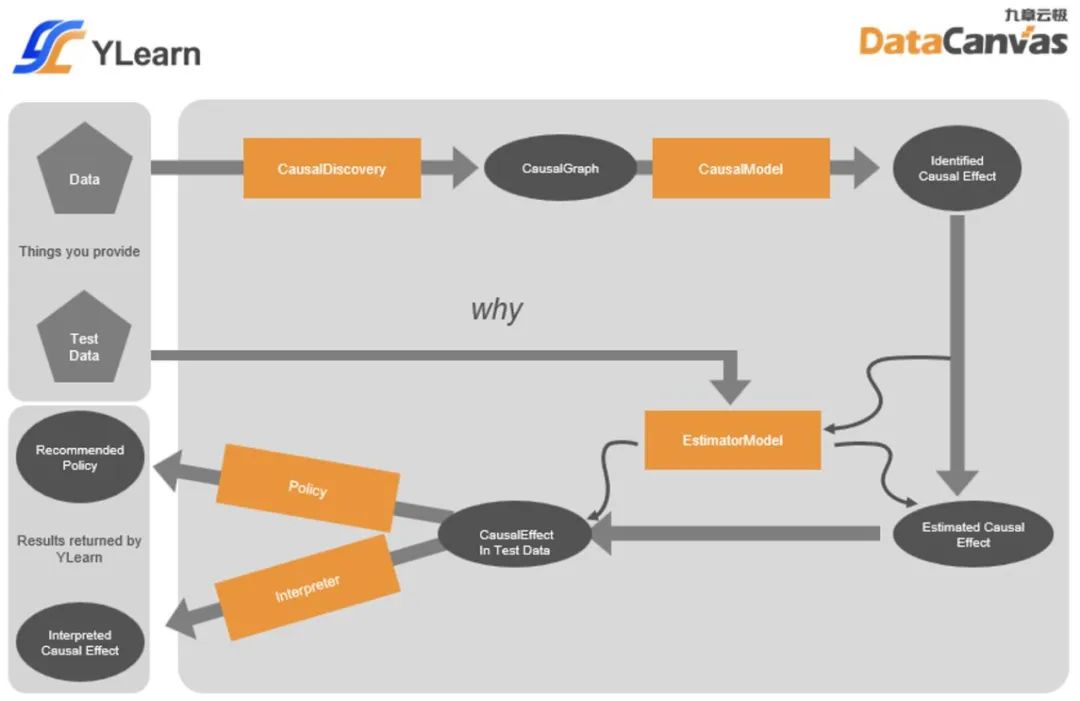
- 使用 CausalDiscovery 去發現數據中的因果關系和因果結構,它們會以 CausalGraph 的形式表示和存在。
- 這些因果圖接下來會被輸入進 CausalModel, 在這里用戶感興趣的因果變量會通過因果效應識別轉化為相應的可被估計的統計變量(也叫識別后的因果變量)。
- 一個特定的 EstimatorModel 此時會在訓練集中訓練,得到訓練好的估計模型,用來從數據中估計識別后的因果變量。
- 這個(些)訓練好的 EstimatorModel 就可以被用來在測試數據集上估計各類不同的因果效應,同時也可以被用來作因果效應解釋或策略方案的制定。
causation={'X':['W'],'W':[],'Y':['W']}
cg=CausalGraph(causation=causation)
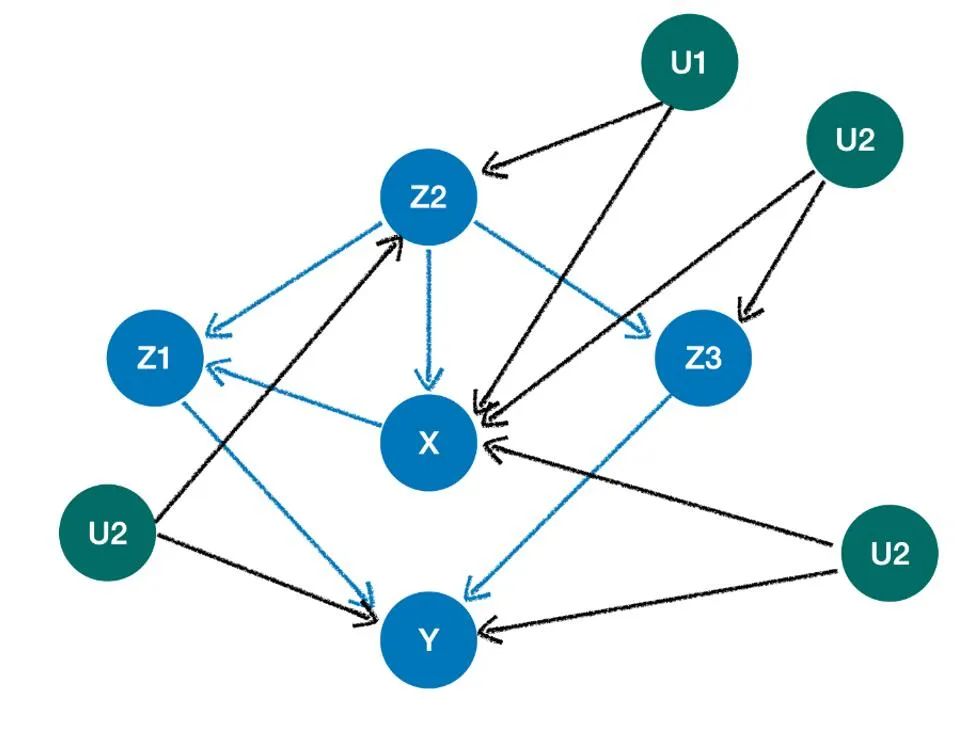
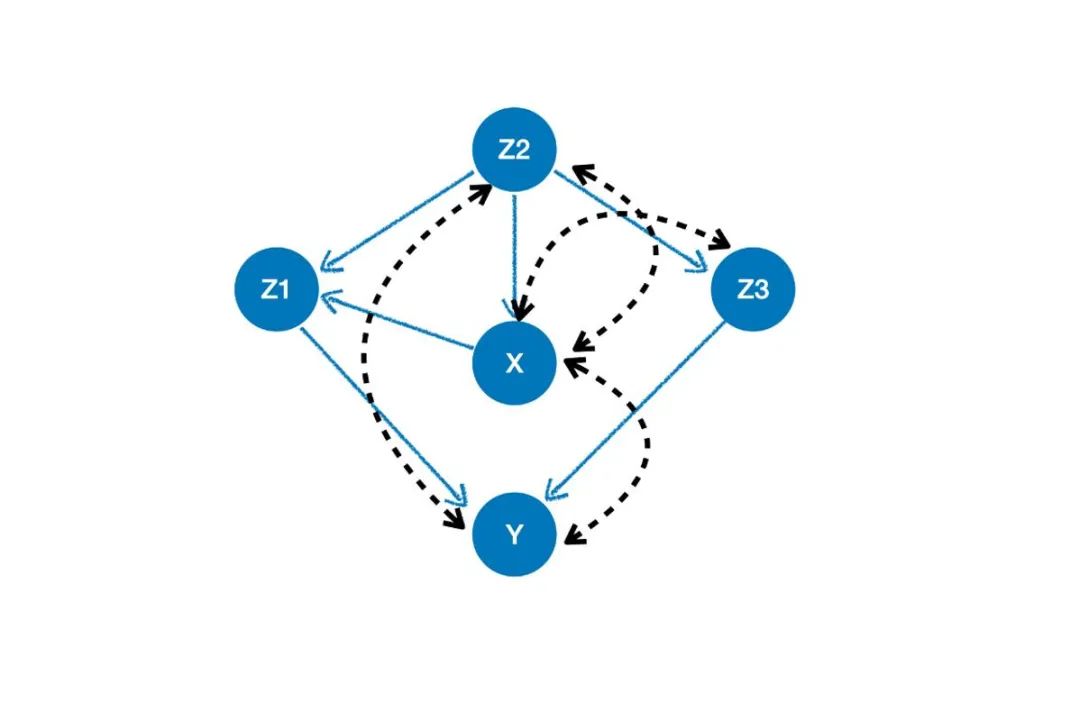
fromylearn.causal_model.graphimportCausalGraph
causation_unob={
'X':['Z2'],
'Z1':['X','Z2'],
'Y':['Z1','Z3'],
'Z3':['Z2'],
'Z2':[],
}
arcs=[('X','Z2'),('X','Z3'),('X','Y'),('Z2','Y')]
cg_unob=CausalGraph(causation=causation_unob,latent_confounding_arcs=arcs)
cm=CausalModel(causal_graph=cg)
cm.identify(treatment={'X'},outcome={'Y'},identify_method=('backdoor','simple'))
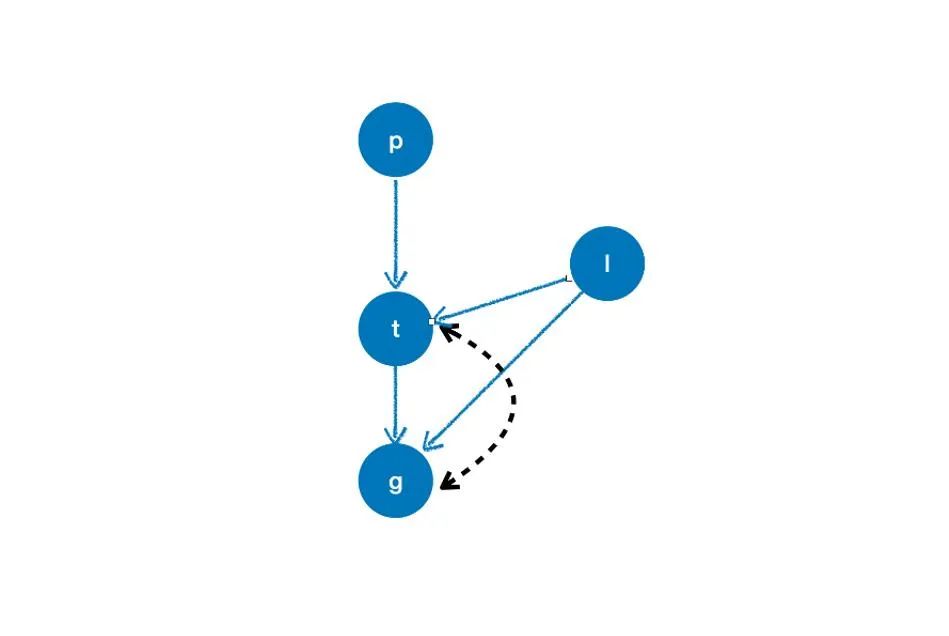
causation={
'p':[],
't':['p','l'],
'l':[],
'g':['t','l']
}
arc=[('t','g')]
cg=CausalGraph(causation=causation,latent_confounding_arcs=arc)
cm=CausalModel(causal_graph=cg)
cm.get_iv('t','g')
- 給定 pandas.DataFrame 形式的數據,確定 treatment, outcome, adjustment, covariate 的變量名。
- 調用 EstimatorModel 的 fit() 方法訓練模型。
- 調用 EstimatorModel 的 estimate() 方法得到估計好的因果效應。
fromsklearn.datasetsimportfetch_california_housing
fromylearnimportWhy
housing=fetch_california_housing(as_frame=True)
data=housing.frame
outcome=housing.target_names[0]
data[outcome]=housing.target
why=Why()
why.fit(data,outcome,treatment=['AveBedrms','AveRooms'])
print(why.causal_effect())
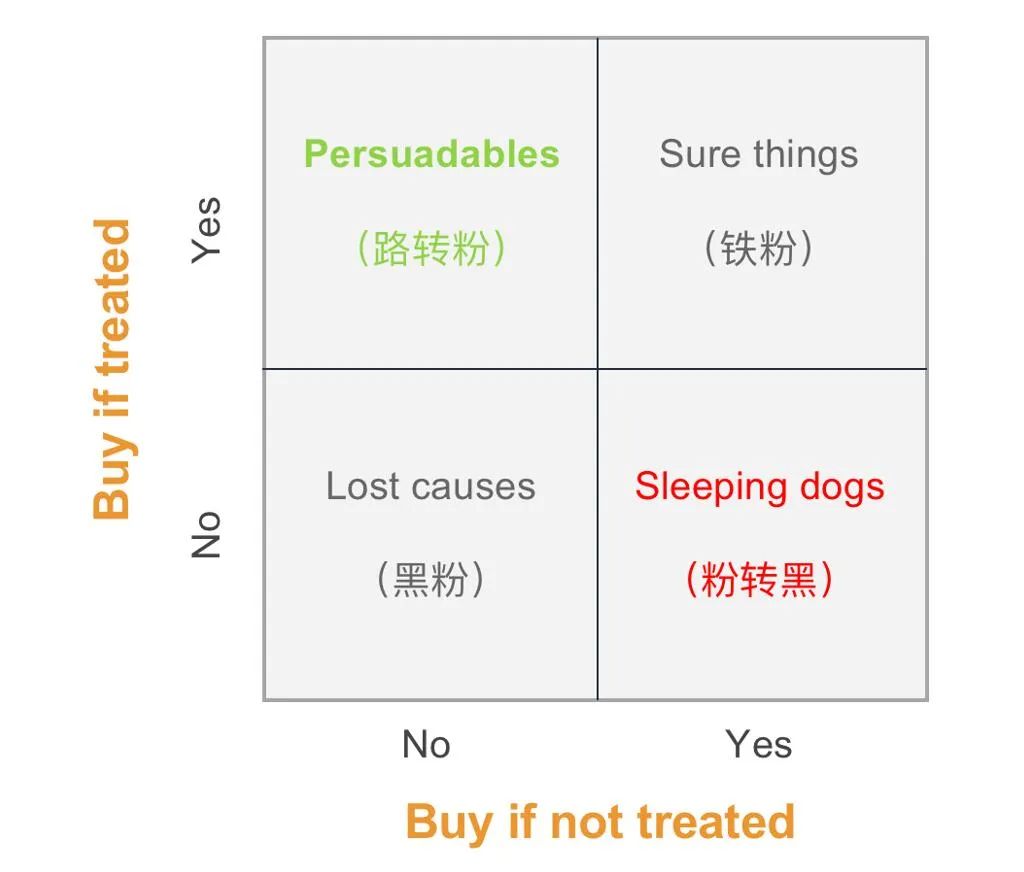
- 確定會購買的用戶,不管我是否推薦這類用戶都會購買(鐵粉)
- 不管我是否推薦他都不會購買(黑粉),
- 我的推薦會提高用戶購買轉化的,如果不推薦他不會購買(路轉粉)
- 是一些靜默用戶本來已經訂閱了我們的服務,一旦收到我們的推薦提醒反而取消了訂閱(粉轉黑)。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4625瀏覽量
93143 -
人工智能
+關注
關注
1793文章
47539瀏覽量
239392 -
機器學習
+關注
關注
66文章
8434瀏覽量
132866
原文標題:九章云極DataCanvas YLearn因果學習開源項目:從預測到決策
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦











 工商網監
工商網監
評論