 基于配準的少樣本異常檢測的框架
基于配準的少樣本異常檢測的框架
近年來,異常檢測在工業缺陷檢測、醫療診斷,自動駕駛等領域有著廣泛的應用。“異常”通常定義為 “正常” 的對立面,即所有不符合正常規范的樣本。通常來說,相比于正常,異常事件的種類是不可窮盡的,且十分稀有,難以收集,因此不可能收集詳盡的異常樣本進行訓練。因此,近期關于異常檢測的研究主要致力于無監督學習,即僅使用正常樣本,通過使用單類別(one-class)分類,圖像重建(reconstruction),或其他自監督學習任務對正常樣本進行建模,之后,通過識別不同于模型分布的樣本來檢測異常。
大多數現有的異常檢測方法都專注于為每個異常檢測任務訓練一個專用模型。然而,在諸如缺陷檢測之類的真實場景中,考慮到要處理數百種工業產品,為每種產品均收集大量訓練集是不劃算的。對此,上海交通大學 MediaBrain 團隊和上海人工智能實驗室智慧醫療團隊等提出了一個基于配準的少樣本異常檢測框架,通過學習多個異常檢測任務之間共享的通用模型,無需進行模型參數調整,便可將其推廣到新的異常檢測任務。目前,這項研究已被 ECCV2022 接收為 Oral 論文,完整訓練代碼及模型已經開源。

方法簡介
在這項工作中,少樣本異常檢測通用模型的訓練受到了人類如何檢測異常的啟發。事實上,當嘗試檢測圖像中的異常時,人們通常會將該檢測樣本與某個已經被確定為正常的樣本進行比較,從而找出差異,有差異的部分就可以被認為是異常。為了實現這種類似于人類的比較的過程,本文作者采用了配準技術。本文作者認為,對于配準網絡而言,只要知道如何比較兩個極度相似的圖像,圖像的實際語義就不再重要,因此模型就更能夠適用于從未見過的異常檢測新任務。配準特別適用于少樣本異常檢測,因為配準可以非常方便地進行跨類別推廣,模型無需參數微調就能夠快速應用于新的異常檢測任務。
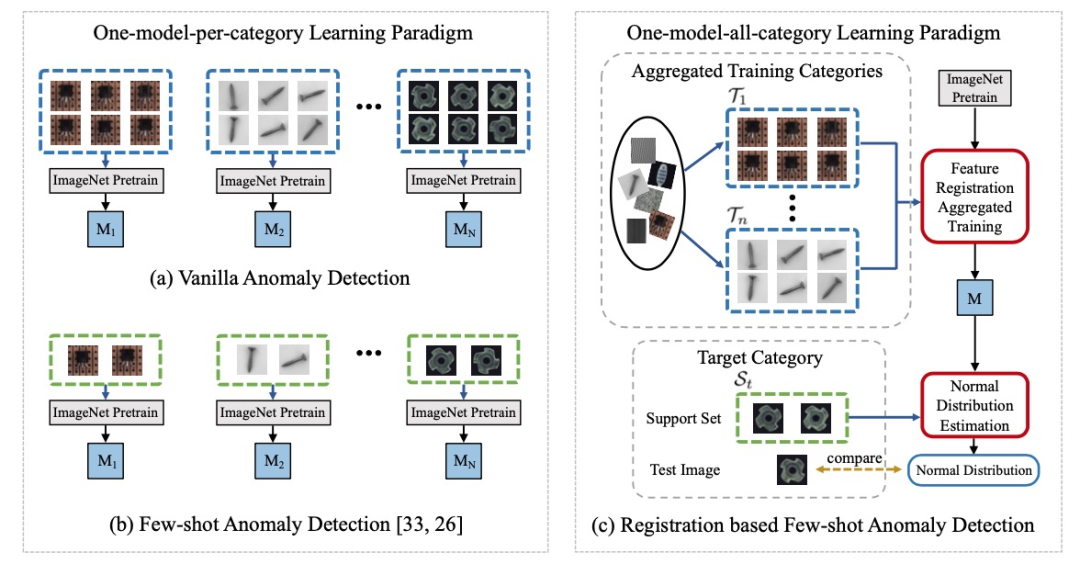
上圖概述了基于配準的少樣本異常檢測的框架。與常規的異常檢測方法(one-model-per-category)不同,這項工作(one-model-all-category)首先使用多類別數據聯合訓練一個基于配準的異常檢測通用模型。來自不同類別的正常圖像一起用于聯合訓練模型,隨機選擇來自同一類別的兩個圖像作為訓練對。在測試時,為目標類別以及每個測試樣本提供了由幾個正常樣本組成的支撐集。給定支撐集,使用基于統計的分布估計器估計目標類別注冊特征的正態分布。超出統計正態分布的測試樣本被視為異常。
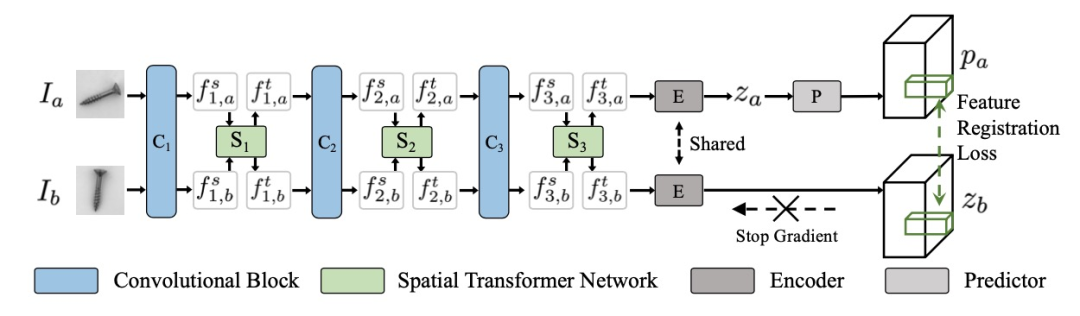
這項工作采用了一個簡單的配準網絡,同時參考了 Siamese [1], STN [2] 和 FYD [3]。具體地說,以孿生神經網絡(Siamese Network)為框架,插入空間變換網絡(STN)實現特征配準。為了更好的魯棒性,本文作者利用特征級的配準損失,而不是像典型的配準方法那樣逐像素配準,這可以被視為像素級配準的松弛版本。
實驗結果
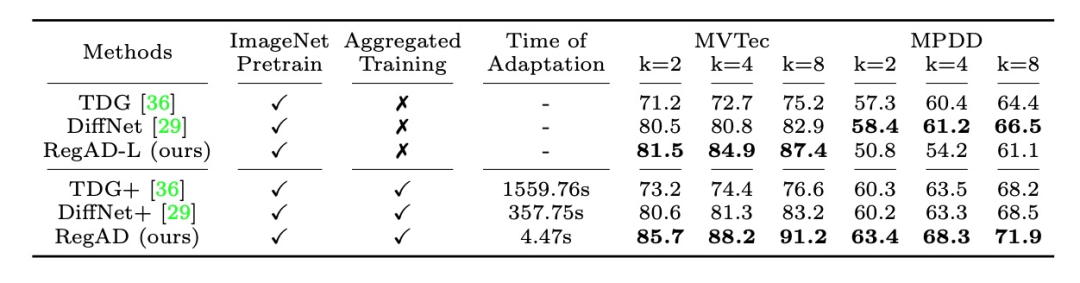
在與其他少樣本異常檢測方法的比較上,RegAD 無論在檢測性能、適用到新類別數據的自適應時間上,相比于基準方法 TDG [4] 和 DiffNet [5] 都有顯著的優勢。這是由于其他的方法都需要針對新的類別數據進行模型的多輪迭代更新。另外,RegAD 相比于沒有進行多類別特征配準聯合訓練的版本(RegAD-L),性能也得到了顯著的提升,體現出基于配準的通用異常檢測模型的訓練是十分有效的。本文在異常檢測數據集 MVTec [6] 和 MPDD [7] 上進行實驗。更多的實驗結果和消融實驗可參考原論文。
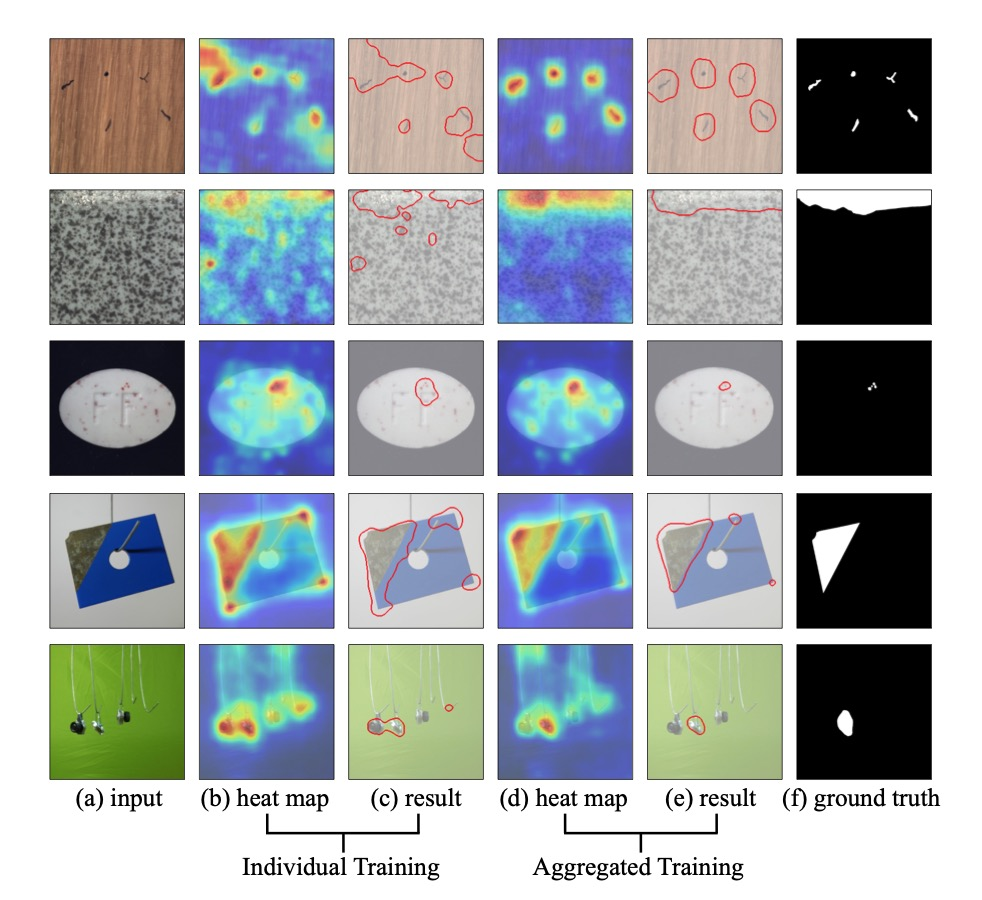
此外,作者還展示了異常定位可視化的結果。可以看到,聯合訓練可以使得模型的異常定位變得更加準確。
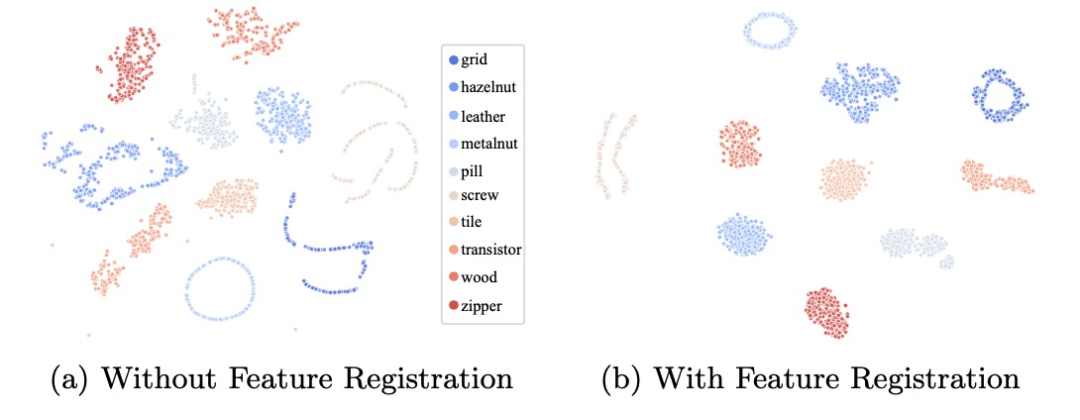
T-SNE 的可視化也顯示出,基于配準的訓練可以使得同類別的正常圖像特征變得更加緊湊,從而有利于異常數據的檢出。
總結
這項工作主要探索了異常檢測的一個具有挑戰性但實用的設置:1)訓練適用于所有異常檢測任務的單一模型(無需微調即可推廣);2)僅提供少量新類別圖像(少樣本);3)只有正常樣本用于訓練(無監督)。嘗試探索這種設置是異常檢測走向實際大規模工業應用的重要一步。為了學習類別無關的模型,本文提出了一種基于比較的解決方案,這與流行的基于重建或基于單分類的方法有很大不同。具體采用的配準模型建立在已有的配準方案基礎上,充分參考了現有的杰出工作 [1,2,3],在不需要參數調整的前提下,在新的異常檢測數據上取得了令人印象深刻的檢測效果。
-
代碼
+關注
關注
30文章
4791瀏覽量
68699 -
檢測圖像
+關注
關注
0文章
3瀏覽量
5537 -
自動駕駛
+關注
關注
784文章
13838瀏覽量
166546
原文標題:ECCV 2022 Oral | 無需微調即可推廣,上交大、上海人工智能實驗室等提出基于配準的少樣本異常檢測框架
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
華為發布駕駛員行為異常檢測新專利
基于AI的異常檢測解決方案
使用單個INA200去做高邊短路電流檢測,檢測電流會出現雙向振蕩,運放Vout輸出異常怎么解決?
BLE Mesh節點配網后如何不清除配網信息,進入待配網狀態?
天準科技發布國內首臺40nm明場納米圖形晶圓缺陷檢測設備
準直器的位置及作用
準直器的工作距離和什么有關
何謂準直器,準直器有什么作用
使用rt-thread的ADC框架,增加了DMA采集部分,采集到的兩通道數據中,有一個通道數據異常,為什么?
COD檢測儀響應水質異常的速度?
專家解讀 | NIST網絡安全框架(1):框架概覽
工業異常檢測超越特定閾值限制的解決方案

基于大模型的遙感圖像變化檢測新網絡
基于DiAD擴散模型的多類異常檢測工作






 工商網監
工商網監
評論