 使用移動傳感器產生的原始數據來識別人類活動
使用移動傳感器產生的原始數據來識別人類活動
本文帶你使用移動傳感器產生的原始數據來識別人類活動。 人體活動識別(HAR)是一種使用人工智能(AI)從智能手表等活動記錄設備產生的原始數據中識別人類活動的方法。當人們執行某種動作時,人們佩戴的傳感器(智能手表、手環、專用設備等)就會產生信號。這些收集信息的傳感器包括加速度計、陀螺儀和磁力計。人類活動識別有各種各樣的應用,從為病人和殘疾人提供幫助到像游戲這樣嚴重依賴于分析運動技能的領域。我們可以將這些人類活動識別技術大致分為兩類:固定傳感器和移動傳感器。在本文中,我們使用移動傳感器產生的原始數據來識別人類活動。
在本文中,我將使用LSTM (Long - term Memory)和CNN (Convolutional Neural Network)來識別下面的人類活動:
- 下樓
- 上樓
- 跑步
- 坐著
- 站立
- 步行
概述
你可能會考慮為什么我們要使用LSTM-CNN模型而不是基本的機器學習方法? 機器學習方法在很大程度上依賴于啟發式手動特征提取人類活動識別任務,而我們這里需要做的是端到端的學習,簡化了啟發式手動提取特征的操作。 ?我將要使用的模型是一個深神經網絡,該網絡是LSTM和CNN的組合形成的,并且具有提取活動特征和僅使用模型參數進行分類的能力。 這里我們使用WISDM數據集,總計1.098.209樣本。通過我們的訓練,模型的F1得分為0.96,在測試集上,F1得分為0.89。
?我將要使用的模型是一個深神經網絡,該網絡是LSTM和CNN的組合形成的,并且具有提取活動特征和僅使用模型參數進行分類的能力。 這里我們使用WISDM數據集,總計1.098.209樣本。通過我們的訓練,模型的F1得分為0.96,在測試集上,F1得分為0.89。
導入庫
首先,我們將導入我們將需要的所有必要庫。
我們將使用Sklearn,Tensorflow,Keras,Scipy和Numpy來構建模型和進行數據預處理。使用PANDAS 進行數據加載,使用matplotlib進行數據可視化。from pandas import read_csv, uniqueimport numpy as npfrom scipy.interpolate import interp1dfrom scipy.stats import modefrom sklearn.preprocessing import LabelEncoderfrom sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplayfrom tensorflow import stackfrom tensorflow.keras.utils import to_categoricalfrom keras.models import Sequentialfrom keras.layers import Dense, GlobalAveragePooling1D, BatchNormalization, MaxPool1D, Reshape, Activationfrom keras.layers import Conv1D, LSTMfrom keras.callbacks import ModelCheckpoint, EarlyStoppingimport matplotlib.pyplot as plt%matplotlib inlineimport warningswarnings.filterwarnings("ignore")
數據集加載和可視化
WISDM是由個人腰間攜帶的移動設備上的加速計記錄下來。該數據收集是由個人監督的可以確保數據的質量。我們將使用的文件是WISDM_AR_V1.1_RAW.TXT。使用PANDAS,可以將數據集加載到DataAframe中,如下面代碼:
def read_data(filepath):df = read_csv(filepath, header=None, names=['user-id','activity','timestamp','X','Y','Z'])## removing ';' from last column and converting it to floatdf['Z'].replace(regex=True, inplace=True, to_replace=r';', value=r'')df['Z'] = df['Z'].apply(convert_to_float)return dfdef convert_to_float(x):try:return np.float64(x)except:return np.nandf = read_data('Dataset/WISDM_ar_v1.1/WISDM_ar_v1.1_raw.txt')df
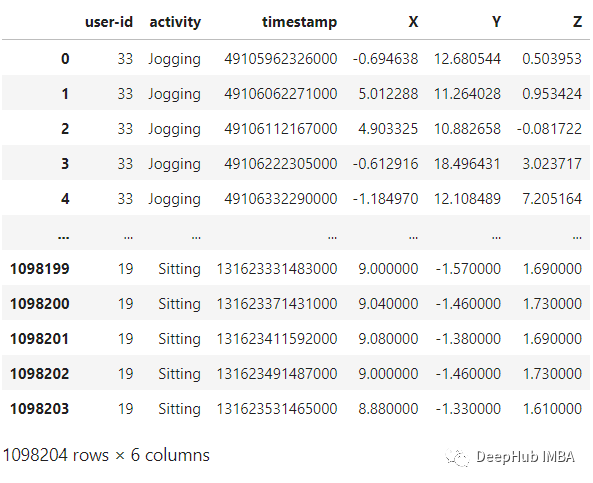
plt.figure(figsize=(15, 5))plt.xlabel('Activity Type')plt.ylabel('Training examples')df['activity'].value_counts().plot(kind='bar',title='Training examples by Activity Types')plt.show()plt.figure(figsize=(15, 5))plt.xlabel('User')plt.ylabel('Training examples')df['user-id'].value_counts().plot(kind='bar',title='Training examples by user')plt.show()
 ?
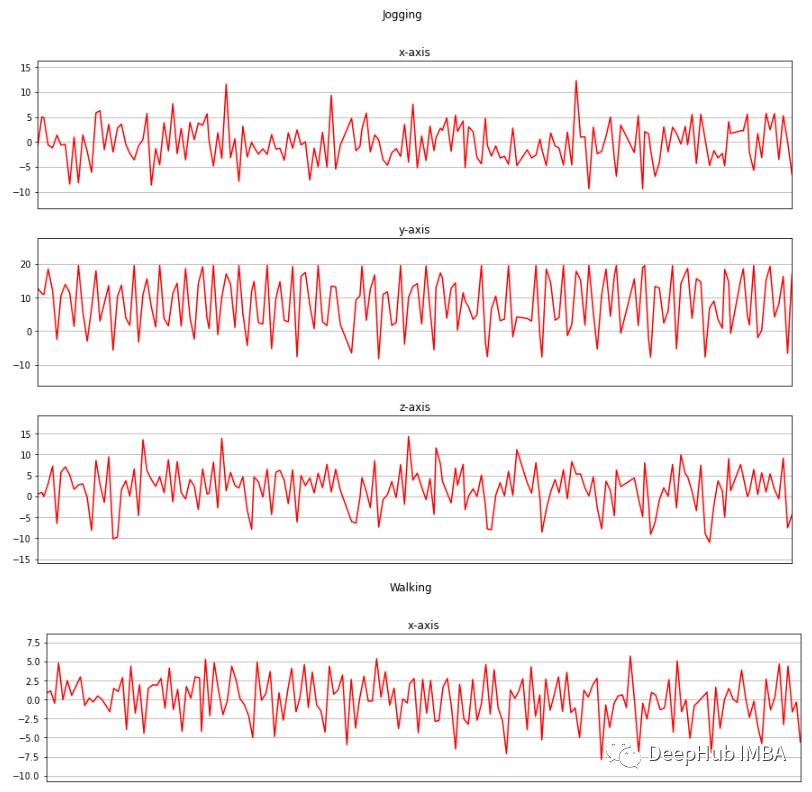
?現在我將收集的三個軸上的加速度計數據進行可視化。
def axis_plot(ax, x, y, title):ax.plot(x, y, 'r')ax.set_title(title)ax.xaxis.set_visible(False)ax.set_ylim([min(y) - np.std(y), max(y) + np.std(y)])ax.set_xlim([min(x), max(x)])ax.grid(True)for activity in df['activity'].unique():limit = df[df['activity'] == activity][:180]fig, (ax0, ax1, ax2) = plt.subplots(nrows=3, sharex=True, figsize=(15, 10))axis_plot(ax0, limit['timestamp'], limit['X'], 'x-axis')axis_plot(ax1, limit['timestamp'], limit['Y'], 'y-axis')axis_plot(ax2, limit['timestamp'], limit['Z'], 'z-axis')plt.subplots_adjust(hspace=0.2)fig.suptitle(activity)plt.subplots_adjust(top=0.9)plt.show()
數據預處理
數據預處理是一項非常重要的任務,它使我們的模型能夠更好地利用我們的原始數據。這里將使用的數據預處理方法有:
- 標簽編碼
- 線性插值
- 數據分割
- 歸一化
- 時間序列分割
- 獨熱編碼
- Downstairs [0]
- Jogging [1]
- Sitting [2]
- Standing [3]
- Upstairs [4]
- Walking [5]
label_encode = LabelEncoder()df['activityEncode'] = label_encode.fit_transform(df['activity'].values.ravel())df
 ?
?線性插值 利用線性插值可以避免采集過程中出現NaN的數據丟失的問題。它將通過插值法填充缺失的值。雖然在這個數據集中只有一個NaN值,但為了我們的展示,還是需要實現它。
數據分割 根據用戶id進行數據分割,避免數據分割錯誤。我們在訓練集中使用id小于或等于27的用戶,其余的在測試集中使用。interpolation_fn = interp1d(df['activityEncode'] ,df['Z'], kind='linear')null_list = df[df['Z'].isnull()].index.tolist()for i in null_list:y = df['activityEncode'][i]value = interpolation_fn(y)df['Z']=df['Z'].fillna(value)print(value)
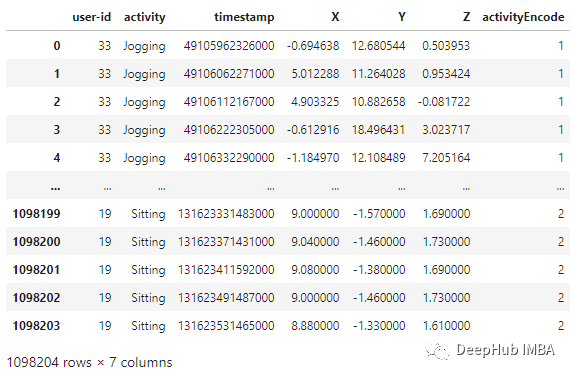
歸一化 在訓練之前,需要將數據特征歸一化到0到1的范圍內。我們用的方法是:df_test = df[df['user-id'] > 27]df_train = df[df['user-id'] <= 27]
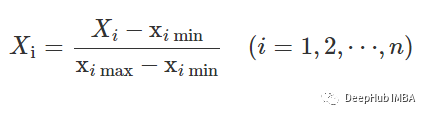 ?
?
df_train['X'] = (df_train['X']-df_train['X'].min())/(df_train['X'].max()-df_train['X'].min())df_train['Y'] = (df_train['Y']-df_train['Y'].min())/(df_train['Y'].max()-df_train['Y'].min())df_train['Z'] = (df_train['Z']-df_train['Z'].min())/(df_train['Z'].max()-df_train['Z'].min())df_train
 ?
?時間序列分割 因為我們處理的是時間序列數據, 所以需要創建一個分割的函數,標簽名稱和每個記錄的范圍進行分段。此函數在x_train和y_train中執行特征的分離,將每80個時間段分成一組數據。
這樣,x_train和y_train形狀變為:def segments(df, time_steps, step, label_name):N_FEATURES = 3segments = []labels = []for i in range(0, len(df) - time_steps, step):xs = df['X'].values[i:i+time_steps]ys = df['Y'].values[i:i+time_steps]zs = df['Z'].values[i:i+time_steps]label = mode(df[label_name][i:i+time_steps])[0][0]segments.append([xs, ys, zs])labels.append(label)reshaped_segments = np.asarray(segments, dtype=np.float32).reshape(-1, time_steps, N_FEATURES)labels = np.asarray(labels)return reshaped_segments, labelsTIME_PERIOD = 80STEP_DISTANCE = 40LABEL = 'activityEncode'x_train, y_train = segments(df_train, TIME_PERIOD, STEP_DISTANCE, LABEL)
這里還存儲了一些后面用到的數據:時間段(time_period),傳感器數(sensors)和類(num_classes)的數量。print('x_train shape:', x_train.shape)print('Training samples:', x_train.shape[0])print('y_train shape:', y_train.shape)x_train shape: (20334, 80, 3)Training samples: 20334y_train shape: (20334,)
最后需要使用Reshape將其轉換為列表,作為keras的輸入:time_period, sensors = x_train.shape[1], x_train.shape[2]num_classes = label_encode.classes_.sizeprint(list(label_encode.classes_))['Downstairs', 'Jogging', 'Sitting', 'Standing', 'Upstairs', 'Walking']
最后需要將所有數據轉換為float32。input_shape = time_period * sensorsx_train = x_train.reshape(x_train.shape[0], input_shape)print("Input Shape: ", input_shape)print("Input Data Shape: ", x_train.shape)Input Shape: 240Input Data Shape: (20334, 240)
獨熱編碼 這是數據預處理的最后一步,我們將通過編碼標簽并將其存儲到y_train_hot中來執行。x_train = x_train.astype('float32')y_train = y_train.astype('float32')
y_train_hot = to_categorical(y_train, num_classes)print("y_train shape: ", y_train_hot.shape)y_train shape: (20334, 6)
模型
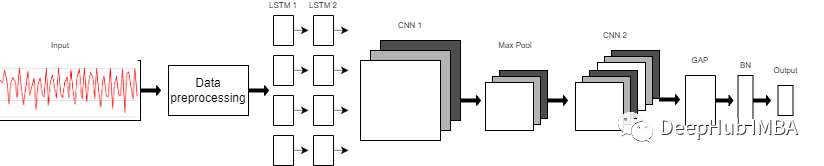 ?
?我們使用的模型是一個由8層組成的序列模型。模型前兩層由LSTM組成,每個LSTM具有32個神經元,使用的激活函數為Relu。然后是用于提取空間特征的卷積層。 在兩層的連接處需要改變LSTM輸出維度,因為輸出具有3個維度(樣本數,時間步長,輸入維度),而CNN則需要4維輸入(樣本數,1,時間步長,輸入)。 第一個CNN層具有64個神經元,另一個神經元有128個神經元。在第一和第二CNN層之間,我們有一個最大池層來執行下采樣操作。然后是全局平均池(GAP)層將多D特征映射轉換為1-D特征向量,因為在此層中不需要參數,所以會減少全局模型參數。然后是BN層,該層有助于模型的收斂性。 最后一層是模型的輸出層,該輸出層只是具有SoftMax分類器層的6個神經元的完全連接的層,該層表示當前類的概率。
model = Sequential()model.add(LSTM(32, return_sequences=True, input_shape=(input_shape,1), activation='relu'))model.add(LSTM(32,return_sequences=True, activation='relu'))model.add(Reshape((1, 240, 32)))model.add(Conv1D(filters=64,kernel_size=2, activation='relu', strides=2))model.add(Reshape((120, 64)))model.add(MaxPool1D(pool_size=4, padding='same'))model.add(Conv1D(filters=192, kernel_size=2, activation='relu', strides=1))model.add(Reshape((29, 192)))model.add(GlobalAveragePooling1D())model.add(BatchNormalization(epsilon=1e-06))model.add(Dense(6))model.add(Activation('softmax'))print(model.summary())

訓練和結果
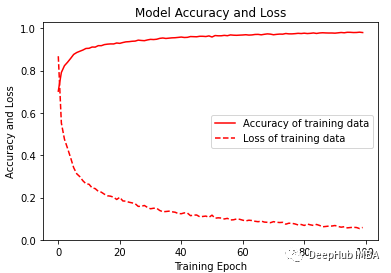
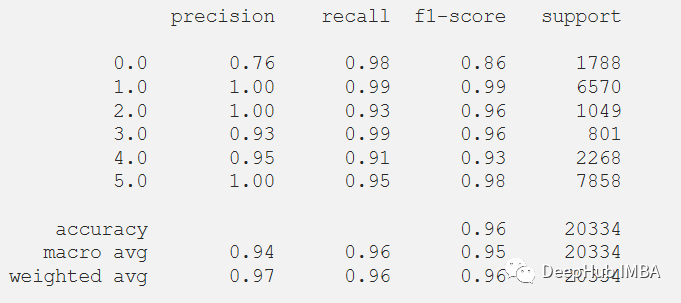
經過訓練,模型給出了98.02%的準確率和0.0058的損失。訓練F1得分為0.96。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])history = model.fit(x_train,y_train_hot,batch_size= 192,epochs=100)
 ?
?可視化訓練的準確性和損失變化圖。
plt.figure(figsize=(6, 4))plt.plot(history.history['accuracy'], 'r', label='Accuracy of training data')plt.plot(history.history['loss'], 'r--', label='Loss of training data')plt.title('Model Accuracy and Loss')plt.ylabel('Accuracy and Loss')plt.xlabel('Training Epoch')plt.ylim(0)plt.legend()plt.show()y_pred_train = model.predict(x_train)max_y_pred_train = np.argmax(y_pred_train, axis=1)print(classification_report(y_train, max_y_pred_train))
 ?
?在測試數據集上測試它,但在通過測試集之前,需要對測試集進行相同的預處理。
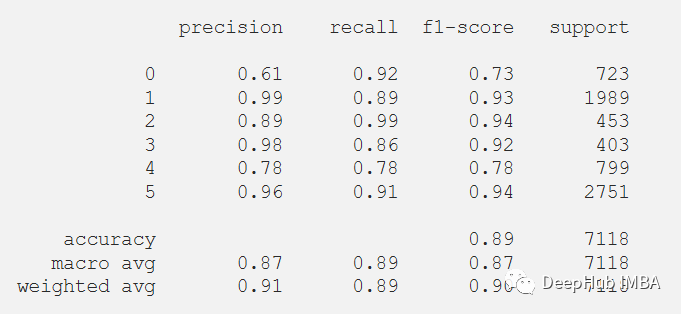
在評估我們的測試數據集后,得到了89.14%的準確率和0.4647的損失。F1測試得分為0.89。df_test['X'] = (df_test['X']-df_test['X'].min())/(df_test['X'].max()-df_test['X'].min())df_test['Y'] = (df_test['Y']-df_test['Y'].min())/(df_test['Y'].max()-df_test['Y'].min())df_test['Z'] = (df_test['Z']-df_test['Z'].min())/(df_test['Z'].max()-df_test['Z'].min())x_test, y_test = segments(df_test,TIME_PERIOD,STEP_DISTANCE,LABEL)x_test = x_test.reshape(x_test.shape[0], input_shape)x_test = x_test.astype('float32')y_test = y_test.astype('float32')y_test = to_categorical(y_test, num_classes)
score = model.evaluate(x_test, y_test)print("Accuracy:", score[1])print("Loss:", score[0])
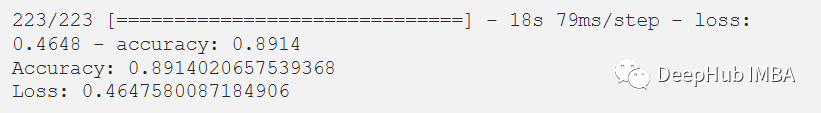 ?
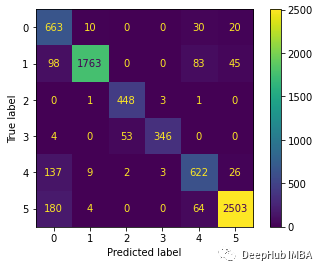
?下面繪制混淆矩陣更好地理解對測試數據集的預測。
predictions = model.predict(x_test)predictions = np.argmax(predictions, axis=1)y_test_pred = np.argmax(y_test, axis=1)cm = confusion_matrix(y_test_pred, predictions)cm_disp = ConfusionMatrixDisplay(confusion_matrix= cm)cm_disp.plot()plt.show()
 ?還可以在測試數據集上評估的模型的分類報告。
?還可以在測試數據集上評估的模型的分類報告。
print(classification_report(y_test_pred, predictions))
總結
LSTM-CNN模型的性能比任何其他機器學習模型要好得多。本文的代碼可以在GitHub上找到。 https://github.com/Tanny1810/Human-Activity-Recognition-LSTM-CNN 您可以嘗試自己實現它,通過優化模型來提高F1分數。 另:這個模型是來自于Xia Kun, Huang Jianguang, and Hanyu Wang在IEEE期刊上發表的論文LSTM-CNN Architecture for Human Activity Recognition。 https://ieeexplore.ieee.org/abstract/document/9043535 審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
傳感器
+關注
關注
2552文章
51288瀏覽量
755155 -
神經網絡
+關注
關注
42文章
4776瀏覽量
100951 -
機器學習
+關注
關注
66文章
8428瀏覽量
132837 -
移動傳感器
+關注
關注
0文章
8瀏覽量
8585
原文標題:基于LSTM-CNN的人體活動識別
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
用ads1292輸出的原始數據繪制心電波形可行嗎?
在芯片處于RDATAC模式下,請教問題如下:
1. 用ads1292輸出的原始數據繪制心電波形可行嗎?我們這邊用原始數據繪制的波形很毛躁,看不出心電波形。
2. 若使用ad lead-off,如何在IC輸出數據中提取心電信號?
發表于 12-23 08:26
使用ADS1298出來的8通道原始數據是多少?
大家使用ADS1298出來的8通道原始數據是多少,我使用的心電模擬儀送信號,出來的原始數據的基線怎么這么高,下位機需要做哪些處理才能把基線拉倒一個固定的位置,希望TI老師或者做過的師傅指導指導。
發表于 12-04 08:38
tlv320adc3101評估板如何獲得采樣的原始數據?
目前使用tlv320adc3101評估板,想要獲得采樣的原始數據,但16bits,32bits,28bits三種情況下所采到的數據位數都不對
發表于 10-31 07:34

CY8CKIT-149 PSoC 4100S Plus如何在橋接控制面板上跟蹤CSD原始數據?
目前,我正在使用 CY8CKIT-149 PSoC 4100S Plus。
使用 CE220891_CapSense_with_Breathing_LED01 設計。 我想跟蹤 brdige 控制面板上每個傳感器的 RawData。
哪個 CapSense API 可以獲取每個傳
發表于 06-21 09:49
請問對雷達獲取的原始數據進行歸一化處理的具體方法是什么?
你好,我想知道原始數據 [-1,1] 歸一化的詳細方法。 從 mcu 寄存器接收到的原始數據和從雷達融合軟件獲取的原始數據都是 4 位小數,如圖 1 所示。
圖 1. 通過圖形界面
發表于 05-31 06:05
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
巨大的進展;自動駕駛開始摒棄手動編碼規則和機器學習模型的方法,轉向全面采用端到端的神經網絡AI系統,它能模仿學習人類司機的駕駛,遇到場景直接輸入傳感器數據,再直接輸出轉向、制動和加速信號。模仿學習
發表于 04-11 10:26
stm32F401 FFT模值是原始數據的一半是怎么回事?
是0.2588和0.5258,剛好只有原始數據的1/2。這是為什么?
看了一下ADC的采集數據和波形,和初始信號差不多。
困擾一整天還是沒想通,求助各路大神。
發表于 03-11 07:24
指紋傳感器的定義 指紋傳感器的應用
指紋傳感器的定義 指紋傳感器的應用? 指紋傳感器是一種生物識別技術,通過檢測和分析人體指紋特征來驗證用戶身份。它基于指紋獨特性和穩定性的基本
康謀產品 | 用于ADAS和AD傳感器的獨立數據采集設備
在 ADAS/AD 環境中,如果想要將原始數據與攝像頭、雷達或激光雷達等傳感器分離,總是會使用測量數據轉換器。借助MDILink,您可以獲得一個SerDes測量
求助,如何在Micrium uc探針中導出REF_BGT60LTR11AIP_M0雷達原始數據?
數據表是我自己添加的,我想用excel實時導出256點的原始數據,但是使用excel的數據傳輸速度很慢,導出的效果也不好,所以我想問一下有沒有建議實時導出Micrium中的原始數據。
發表于 01-26 06:11
如何使用Position2Go Board在MATLAB上提取原始數據來繪制距離多普勒圖?
有人可以分步解釋如何使用 Position2Go Board 在 MATLAB 上提取原始數據來繪制距離多普勒圖嗎?
發表于 01-25 06:18





 工商網監
工商網監
評論