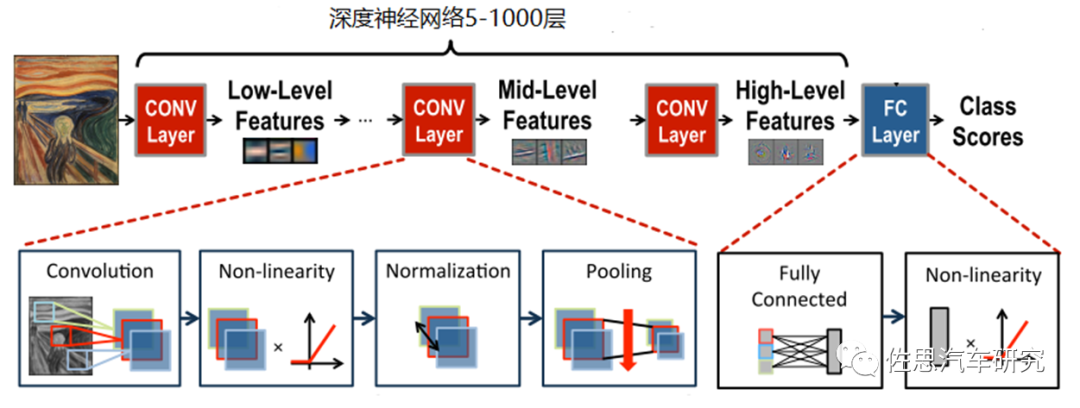
 如何提升NPU的能效比?
如何提升NPU的能效比?
現如今,深度神經網絡正在以越來越大的規模部署,橫跨了從云端,自動駕駛到IoT等平臺。比如用于圖像識別,語音識別及翻譯,癌癥檢測以及自動駕駛中對感知層海量數據的處理等。在很多領域,深度神經網絡的精度已經超越人類,它的優越性來源于它對原始數據的特征提取,并通過對大量數據的學習來獲取輸入空間的有效表征,但是它的高精度是以超高計算復雜度為代價。因此很多廠商都在追逐NPU的算力來解決這些復雜問題,但是隨著算力的提高,NPU設計也越來越復雜,將伴隨著面積和功耗的增加,這對于那些面積和功耗有很大限制的設備帶來了挑戰,因此如何提升NPU的能效比就成了亟待解決的問題。
NPU通過數據分區和有效調度,利用數據的重用以及執行分段來提高能效比和硬件利用率,而實現高利用率,數據重用將直接依賴于如何調度深度神經網絡的計算和如何將這些計算有效的映射到NPU的硬件單元上。以CNN為例,數據流無非包含三個方面filter(Weight),ifmap和ofmap,如下圖。
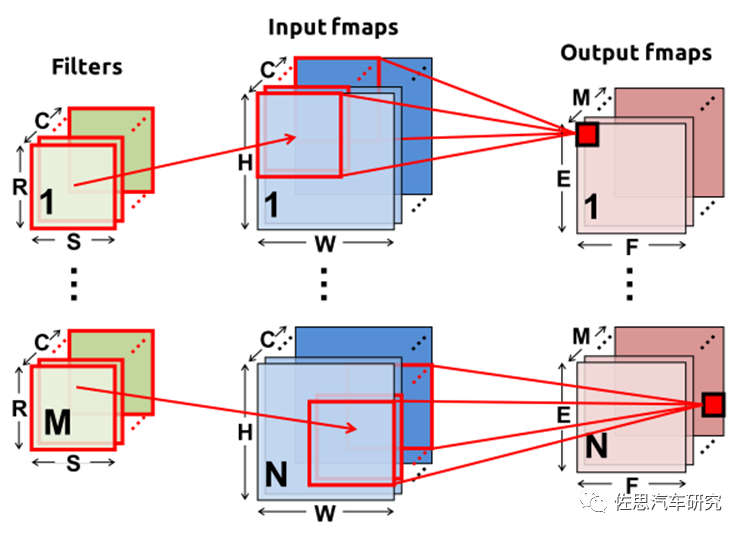
因此在設計NPU時需要考慮如利用內存的層次結構,決定哪些數據要讀到那一層的內存中以及什么時候被處理,如何可以重用filter,ifmap和ofmap,將他們存放在本地內存中,從而大大減少DRAM的訪問次數,這將在很大程度上提高NPU的硬件利用率及性能,并減少由于DRAM訪問帶了的額外功耗。根據數據處理特征可以將數據流分為以下幾類:
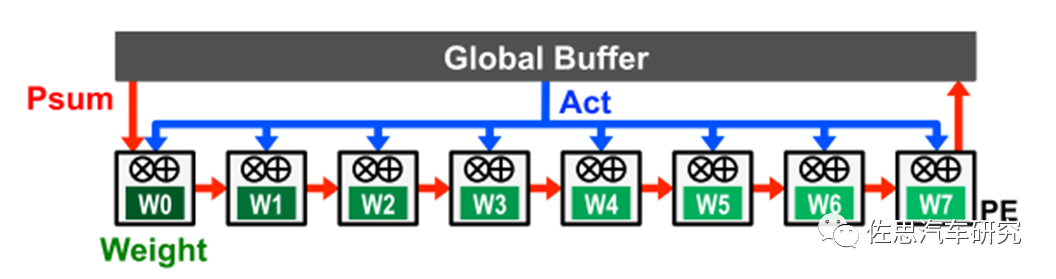
1)、靜態weight
weight靜態數據流的設計是通過在PE的RF(Register File)中存取weight,來減少讀取weight產生的功耗。weight從DRAM讀取到RF并保持靜態以供進一步訪問,NPU在計算時盡可能多的利用RF中的weight以達到最大程度的重用。通常的實現是將ifmap廣播給所有的PE,部分和(Psum)將穿過所有的PE來完成空間上的累加。
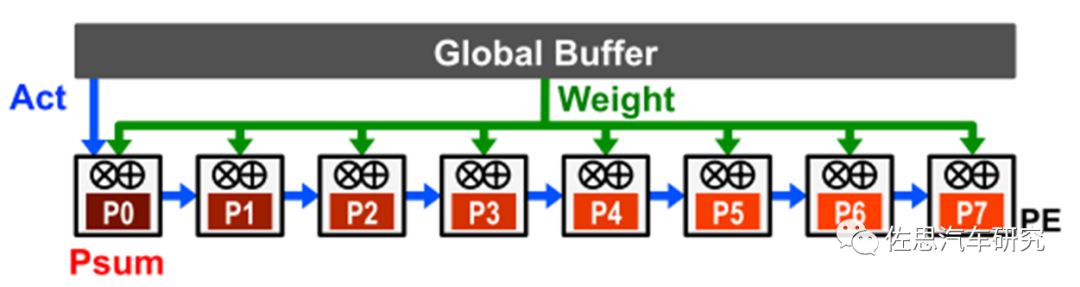
2)、靜態輸出
輸出靜態數據流的設計是通過將accumulator產生的Psum存放到本地的RF中,以避免將Psum剛寫入DRAM再讀回,從而減少因Psum讀寫產生的功耗。通常的實現是流式輸入Activation,并將weight廣播給所有的PE。
3)、無本地重用
如果考慮到RF會增大面積,可以將所有的數據都存放到Global Buffer中,這樣沒有任何數據會留在PE的RF,也不會增設RF單元來減小面積,但是增加了PE和Global Buffer的數據交互。具體來說是通過多廣播Activation,單廣播Weight以及Psum穿過所有的PE進行累加來實現的。
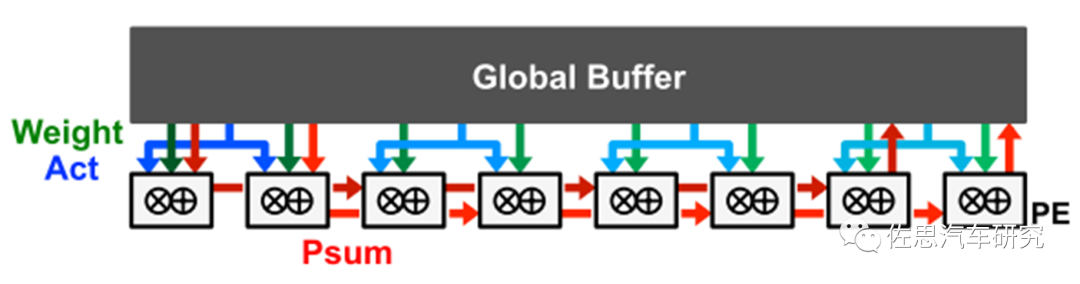
4)、靜態行
靜態行數據流的目標是將所有的數據類型(Activation,weight, psum)的重用和計算都在RF中完成,來提升總體的能效。它區別于上面的靜態weight和靜態輸出,只是分別對weight和psum進行優化。
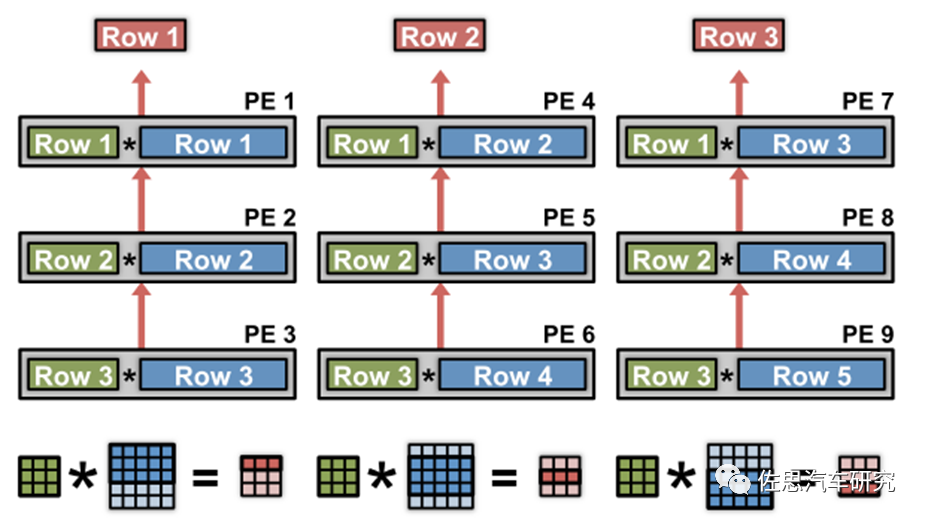
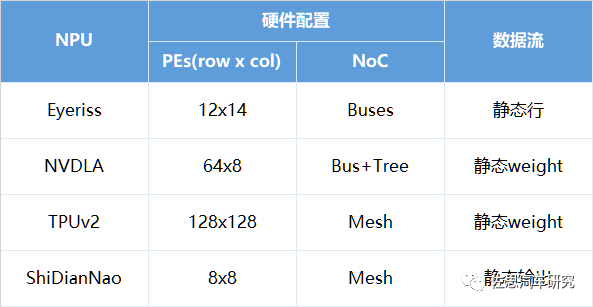
具體選用哪種數據流方式要結合NPU微架構的設計。下面總結了來自于幾個廠家的NPU,它們分別利用了不同數據流類型來提高能效比。
參考文獻:
【1】Vivienne S. Yu-Hsin C.and etc., “Ef?cient Processing of Deep Neural Networks: A Tutorial and Survey”
關于復睿微電子:
復睿微電子是世界500強企業復星集團出資設立的先進科技型企業。復睿微電子植根于創新驅動的文化,通過技術創新改變人們的生活、工作、學習和娛樂方式。公司成立于2022年1月,目標成為世界領先的智能出行時代的大算力方案提供商,致力于為汽車電子、人工智能、通用計算等領域提供以高性能芯片為基礎的解決方案。
目前主要從事汽車智能座艙、ADS/ADAS芯片研發,以領先的芯片設計能力和人工智能算法,通過底層技術賦能,推動汽車產業的創新發展,提升人們的出行體驗。在智能出行的時代,芯片是汽車的大腦。復星智能出行集團已經構建了完善的智能出行生態,復睿微是整個生態的通用大算力和人工智能大算力的基礎平臺。復睿微以提升客戶體驗為使命,在后摩爾定律時代持續通過先進封裝、先進制程和解決方案提升算力,與合作伙伴共同面對汽車智能化的新時代。
審核編輯 :李倩
-
芯片
+關注
關注
456文章
50892瀏覽量
424305 -
神經網絡
+關注
關注
42文章
4772瀏覽量
100851 -
NPU
+關注
關注
2文章
286瀏覽量
18647
原文標題:ADS算力芯片NPU數據流的重用性
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
IO模塊助力PLC,全面提升中水處理設備能效

Erp指令能效
NPU與機器學習算法的關系
NPU的工作原理解析
NPU在邊緣計算中的優勢
NPU技術如何提升AI性能
什么是NPU芯片及其功能
AcrelEMS企業微電網能效管理平臺如何輔助企業進行能源平衡優化?
智慧水務綜合能效管理系統-提高污水廠能效
利用AI和加速計算提升天氣預報效率和能效
重磅!英特爾發布intel3制程至強6能效核處理器,賦能數據中心能效升級

AMD披露高效數據中心策略,預計至2027年能效提升超百倍
天璣9300旗艦芯:全大核CPU架構,性能與能效的提升
智慧水務能效管理平臺-為污水處理的能效管理提供科學、精細的解決方案





 工商網監
工商網監
評論