 GoF設計模式之迭代器模式
GoF設計模式之迭代器模式
簡單的分布式應用系統(示例代碼工程):https://github.com/ruanrunxue/Practice-Design-Pattern--Go-Implementation
簡介
有時會遇到這樣的需求,開發一個模塊,用于保存對象;不能用簡單的數組、列表,得是紅黑樹、跳表等較為復雜的數據結構;有時為了提升存儲效率或持久化,還得將對象序列化;但必須給客戶端提供一個易用的 API,允許方便地、多種方式地遍歷對象,絲毫不察覺背后的數據結構有多復雜。
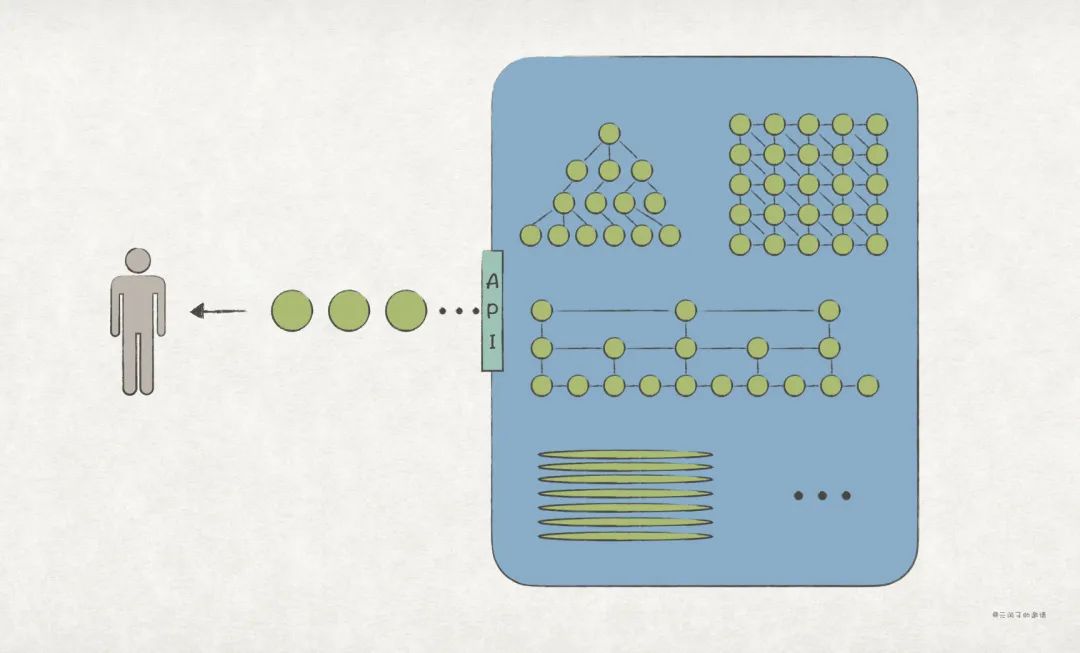
對這樣的 API,很適合使用迭代器模式(Iterator Pattern)實現。
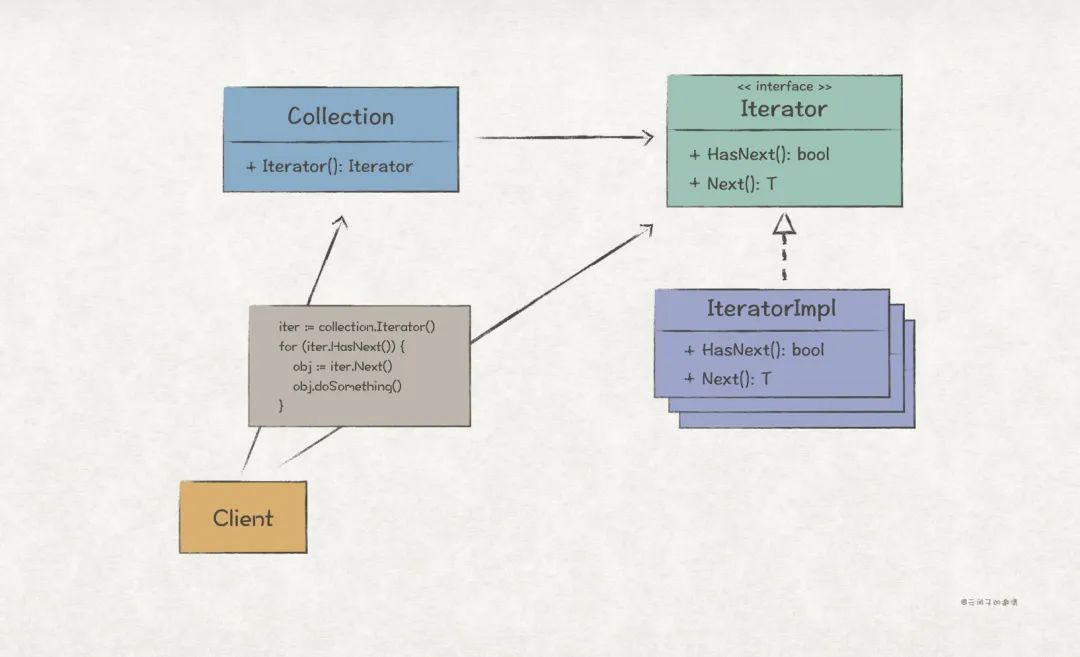
GoF 對 迭代器模式 的定義如下:
Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
從描述可知,迭代器模式主要用在訪問對象集合的場景,能夠向客戶端隱藏集合的實現細節。
Java 的 Collection 家族、C++ 的 STL 標準庫,都是使用迭代器模式的典范,它們為客戶端提供了簡單易用的 API,并且能夠根據業務需要實現自己的迭代器,具備很好的可擴展性。
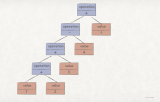
UML 結構
場景上下文
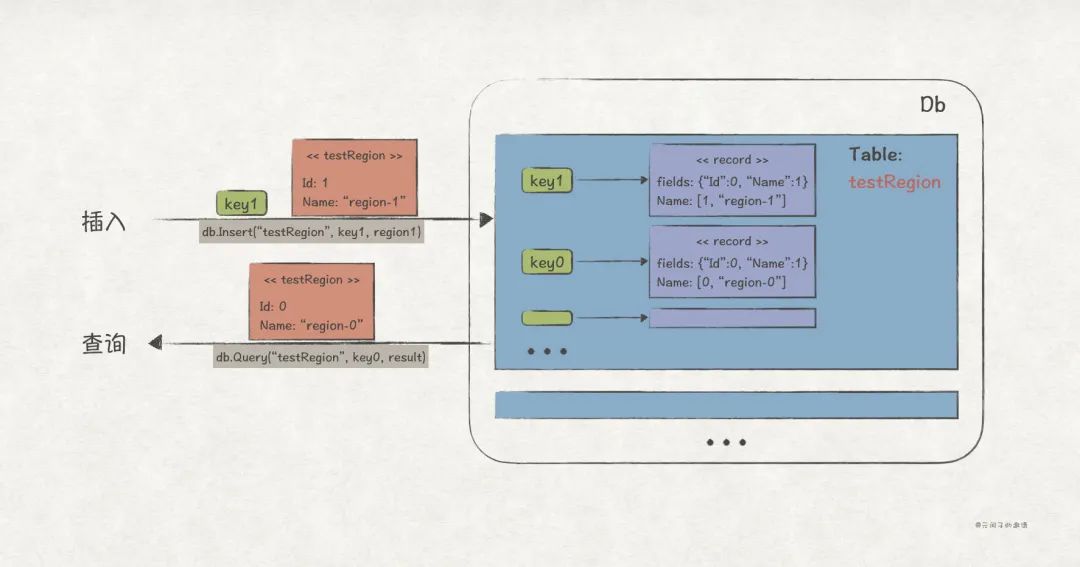
在簡單的分布式應用系統(示例代碼工程)中,db 模塊用來存儲服務注冊和監控信息,它的主要接口如下:
//demo/db/db.go
packagedb
//Db數據庫抽象接口
typeDbinterface{
CreateTable(t*Table)error
CreateTableIfNotExist(t*Table)error
DeleteTable(tableNamestring)error
Query(tableNamestring,primaryKeyinterface{},resultinterface{})error
Insert(tableNamestring,primaryKeyinterface{},recordinterface{})error
Update(tableNamestring,primaryKeyinterface{},recordinterface{})error
Delete(tableNamestring,primaryKeyinterface{})error
...
}
從增刪查改接口可以看出,它是一個 key-value 數據庫,另外,為了提供類似關系型數據庫的按列查詢能力,我們又抽象出Table對象:
//demo/db/table.go
packagedb
//Table數據表定義
typeTablestruct{
namestring
recordTypereflect.Type
recordsmap[interface{}]record
}
其中,Table底層用map存儲對象數據,但并沒有存儲對象本身,而是從對象轉換而成的record。record的實現原理是利用反射機制,將對象的屬性名 field 和屬性值 value 分開存儲,以此支持按列查詢能力(一類對象可以類比為一張表):
//demo/db/record.go
packagedb
typerecordstruct{
primaryKeyinterface{}
fieldsmap[string]int//key為屬性名,value屬性值的索引
values[]interface{}//存儲屬性值
}
//從對象轉換成record
funcrecordFrom(keyinterface{},valueinterface{})(rrecord,eerror){
...//異常處理
vType:=reflect.TypeOf(value)
vVal:=reflect.ValueOf(value)
ifvVal.Type().Kind()==reflect.Pointer{
vType=vType.Elem()
vVal=vVal.Elem()
}
record:=record{
primaryKey:key,
fields:make(map[string]int,vVal.NumField()),
values:make([]interface{},vVal.NumField()),
}
fori:=0;ireturnrecord,nil
}
當然,客戶端并不會察覺 db 模塊背后的復雜機制,它們直接使用的仍是對象:
typetestRegionstruct{
Idint
Namestring
}
funcclient(){
mdb:=db.MemoryDbInstance()
tableName:="testRegion"
table:=NewTable(tableName).WithType(reflect.TypeOf(new(testRegion)))
mdb.CreateTable(table)
mdb.Insert(tableName,"region1",&testRegion{Id:0,Name:"region-1"})
result:=new(testRegion)
mdb.Query(tableName,"region1",result)
}
另外,除了上述按 Key 查詢接口,我們還想提供全表查詢接口,有隨機和有序 2 種表記錄遍歷方式,并且支持客戶端自己擴展遍歷方式。下面使用迭代器模式來實現該需求。
代碼實現
這里并沒有按照標準的 UML 結構去實現,而是結合工廠方法模式來解決公共代碼的復用問題:
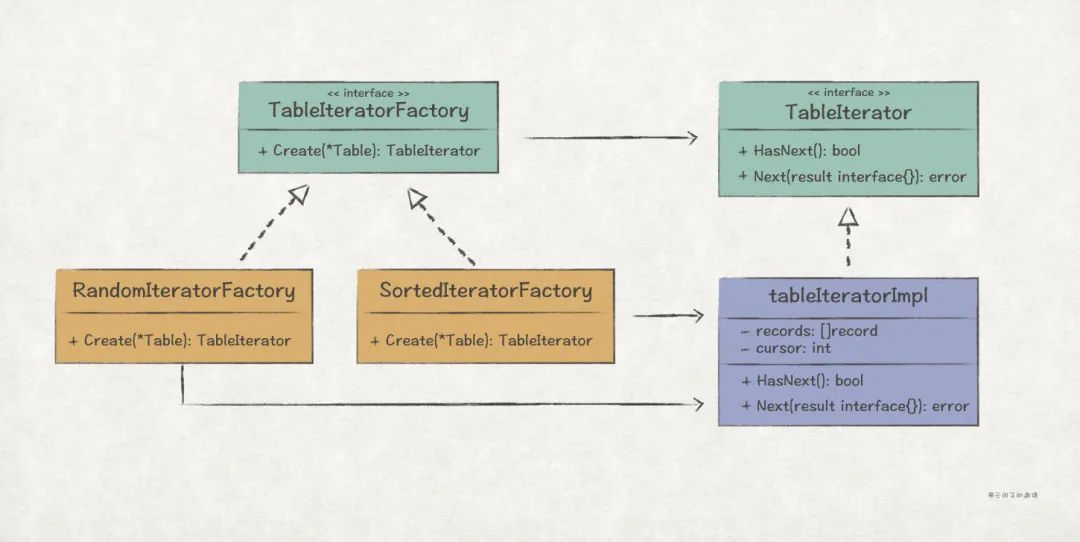
//demo/db/table_iterator.go
packagedb
//關鍵點1:定義迭代器抽象接口,允許后續客戶端擴展遍歷方式
//TableIterator表迭代器接口
typeTableIteratorinterface{
HasNext()bool
Next(nextinterface{})error
}
//關鍵點2:定義迭代器接口的實現
//tableIteratorImpl迭代器接口公共實現類
typetableIteratorImplstruct{
//關鍵點3:定義一個集合存儲待遍歷的記錄,這里的記錄已經排序好或者隨機打散
records[]record
//關鍵點4:定義一個cursor游標記錄當前遍歷的位置
cursorint
}
//關鍵點5:在HasNext函數中的判斷是否已經遍歷完所有記錄
func(r*tableIteratorImpl)HasNext()bool{
returnr.cursorlen(r.records)
}
//關鍵點6:在Next函數中取出下一個記錄,并轉換成客戶端期望的對象類型,記得增加cursor
func(r*tableIteratorImpl)Next(nextinterface{})error{
record:=r.records[r.cursor]
r.cursor++
iferr:=record.convertByValue(next);err!=nil{
returnerr
}
returnnil
}
//關鍵點7:通過工廠方法模式,完成不同類型的迭代器對象創建
//TableIteratorFactory表迭代器工廠
typeTableIteratorFactoryinterface{
Create(table*Table)TableIterator
}
//隨機迭代器
typerandomTableIteratorFactorystruct{}
func(r*randomTableIteratorFactory)Create(table*Table)TableIterator{
varrecords[]record
for_,r:=rangetable.records{
records=append(records,r)
}
rand.Seed(time.Now().UnixNano())
rand.Shuffle(len(records),func(i,jint){
records[i],records[j]=records[j],records[i]
})
return&tableIteratorImpl{
records:records,
cursor:0,
}
}
//有序迭代器
//Comparator如果i
typeComparatorfunc(i,jinterface{})bool
//sortedTableIteratorFactory根據主鍵進行排序,排序邏輯由Comparator定義
typesortedTableIteratorFactorystruct{
comparatorComparator
}
func(s*sortedTableIteratorFactory)Create(table*Table)TableIterator{
varrecords[]record
for_,r:=rangetable.records{
records=append(records,r)
}
sort.Sort(newRecords(records,s.comparator))
return&tableIteratorImpl{
records:records,
cursor:0,
}
}
最后,為Table對象引入TableIterator:
//demo/db/table.go
//Table數據表定義
typeTablestruct{
namestring
recordTypereflect.Type
recordsmap[interface{}]record
//關鍵點8:持有迭代器工廠方法接口
iteratorFactoryTableIteratorFactory//默認使用隨機迭代器
}
//關鍵點9:定義Setter方法,提供迭代器工廠的依賴注入
func(t*Table)WithTableIteratorFactory(iteratorFactoryTableIteratorFactory)*Table{
t.iteratorFactory=iteratorFactory
returnt
}
//關鍵點10:定義創建迭代器的接口,其中調用迭代器工廠完成實例化
func(t*Table)Iterator()TableIterator{
returnt.iteratorFactory.Create(t)
}
客戶端這樣使用:
funcclient(){
table:=NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))).
WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdComparator))
iter:=table.Iterator()
foriter.HashNext(){
next:=new(testRegion)
err:=iter.Next(next)
...
}
}
總結實現迭代器模式的幾個關鍵點:
-
定義迭代器抽象接口,目的是提供客戶端自擴展能力,通常包含
HashNext()和Next()兩個方法,上述例子為TableIterator。 -
定義迭代器接口的實現類,上述例子為
tableIteratorImpl,這里主要起到了 Java/C++ 等帶繼承特性語言中,基類的作用,目的是復用代碼。 -
在實現類中持有待遍歷的記錄集合,通常是已經排序好或隨機打散后的,上述例子為
tableIteratorImpl.records。 -
在實現類中持有游標值,記錄當前遍歷的位置,上述例子為
tableIteratorImpl.cursor。 -
在
HashNext()方法中判斷是否已經遍歷完所有記錄。 -
在
Next()方法中取出下一個記錄,并轉換成客戶端期望的對象類型,取完后增加游標值。 -
通過工廠方法模式,完成不同類型的迭代器對象創建,上述例子為
TableIteratorFactory接口,以及它的實現,randomTableIteratorFactory和sortedTableIteratorFactory。 -
在待遍歷的對象中,持有迭代器工廠方法接口,上述例子為
Table.iteratorFactory。 -
為對象定義 Setter 方法,提供迭代器工廠的依賴注入,上述例子為
Table.WithTableIteratorFactory()方法。 -
為對象定義創建迭代器的接口,上述例子為
Table.Iterator()方法。
其中,7~9 步是結合工廠方法模式實現時的特有步驟,如果你的迭代器實現中沒有用到工廠方法模式,可以省略這幾步。
擴展
Go 風格的實現
前面的實現,是典型的面向對象風格,下面以隨機迭代器為例,給出一個 Go 風格的實現:
//demo/db/table_iterator_closure.go
packagedb
//關鍵點1:定義HasNext和Next函數類型
typeHasNextfunc()bool
typeNextfunc(interface{})error
//關鍵點2:定義創建迭代器的方法,返回HashNext和Next函數
func(t*Table)ClosureIterator()(HasNext,Next){
varrecords[]record
for_,r:=ranget.records{
records=append(records,r)
}
rand.Seed(time.Now().UnixNano())
rand.Shuffle(len(records),func(i,jint){
records[i],records[j]=records[j],records[i]
})
size:=len(records)
cursor:=0
//關鍵點3:在迭代器創建方法定義HasNext和Next的實現邏輯
hasNext:=func()bool{
returncursorfunc(nextinterface{})error{
record:=records[cursor]
cursor++
iferr:=record.convertByValue(next);err!=nil{
returnerr
}
returnnil
}
returnhasNext,next
}
客戶端這樣用:
funcclient(){
table:=NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))).
WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdComparator))
hasNext,next:=table.ClosureIterator()
forhasNext(){
result:=new(testRegion)
err:=next(result)
...
}
}
Go 風格的實現,利用了函數閉包的特點,把原本在迭代器實現的邏輯,放到了迭代器創建方法上。相比面向對象風格,省掉了迭代器抽象接口和實現對象的定義,看起來更加的簡潔。
總結幾個實現關鍵點:
-
聲明
HashNext和Next的函數類型,等同于迭代器抽象接口的作用。 -
定義迭代器創建方法,返回類型為
HashNext和Next,上述例子為ClosureIterator()方法。 -
在迭代器創建方法內,定義
HasNext和Next的具體實現,利用函數閉包來傳遞狀態(records和cursor)。
基于 channel 的實現
我們還能基于 Go 語言中的 channel 來實現迭代器模式,因為前文的 db 模塊應用場景并不適用,所以另舉一個簡單的例子:
typeRecordint
func(r*Record)doSomething(){
//...
}
typeComplexCollectionstruct{
records[]Record
}
//關鍵點1:定義迭代器創建方法,返回只能接收的channel類型
func(c*ComplexCollection)Iterator()<-chanRecord{
//關鍵點2:創建一個無緩沖的channel
ch:=make(chanRecord)
//關鍵點3:另起一個goroutine往channel寫入記錄,如果接收端還沒開始接收,會阻塞住
gofunc(){
for_,record:=rangec.records{
ch<-?record
????????}
????//關鍵點4:寫完后,關閉channel
close(ch)
}()
returnch
}
客戶端這樣使用:
funcclient(){
collection:=NewComplexCollection()
//關鍵點5:使用時,直接通過for-range來遍歷channel讀取記錄
forrecord:=rangecollection.Iterator(){
record.doSomething()
}
}
總結實現基于 channel 的迭代器模式的幾個關鍵點:
- 定義迭代器創建方法,返回一個只能接收的 channel。
- 在迭代器創建方法中,定義一個無緩沖的 channel。
- 另起一個 goroutine 往 channel 中寫入記錄。如果接收端沒有接收,會阻塞住。
- 寫完后,關閉 channel。
- 客戶端使用時,直接通過 for-range 遍歷 channel 讀取記錄即可。
帶有 callback 函數的實現
還可以在創建迭代器時,傳入一個 callback 函數,在迭代器返回記錄前,先調用 callback 函數對記錄進行一些操作。
比如,在基于 channel 的實現例子中,可以增加一個 callback 函數,將每個記錄打印出來:
//關鍵點1:聲明callback函數類型,以Record作為入參
typeCallbackfunc(record*Record)
//關鍵點2:定義具體的callback函數
funcPrintRecord(record*Record){
fmt.Printf("%+v
",record)
}
//關鍵點3:定義以callback函數作為入參的迭代器創建方法
func(c*ComplexCollection)Iterator(callbackCallback)<-chanRecord{
ch:=make(chanRecord)
gofunc(){
for_,record:=rangec.records{
//關鍵點4:遍歷記錄時,調用callback函數作用在每條記錄上
callback(&record)
ch<-?record
????????}
????????close(ch)
}()
returnch
}
funcclient(){
collection:=NewComplexCollection()
//關鍵點5:創建迭代器時,傳入具體的callback函數
forrecord:=rangecollection.Iterator(PrintRecord){
record.doSomething()
}
}
總結實現帶有 callback 的迭代器模式的幾個關鍵點:
- 聲明 callback 函數類型,以 Record 作為入參。
-
定義具體的 callback 函數,比如上述例子中打印記錄的
PrintRecord函數。 - 定義迭代器創建方法,以 callback 函數作為入參。
- 迭代器內,遍歷記錄時,調用 callback 函數作用在每條記錄上。
- 客戶端創建迭代器時,傳入具體的 callback 函數。
典型應用場景
-
對象集合/存儲類模塊,并希望向客戶端隱藏模塊背后的復雜數據結構。
-
希望支持客戶端自擴展多種遍歷方式。
優缺點
優點
缺點
- 容易濫用,比如給簡單的集合類型實現迭代器接口,反而使代碼更復雜。
- 相比于直接遍歷集合,迭代器效率要更低一些,因為涉及到更多對象的創建,以及可能的對象拷貝。
-
需要時刻注意在迭代器遍歷過程中,由原始集合發生變更引發的并發問題。一種解決方法是,在創建迭代器時,拷貝一份原始數據(
TableIterator就這么實現),但存在效率低、內存占用大的問題。
與其他模式的關聯
迭代器模式通常會與工廠方法模式一起使用,如前文實現。
文章配圖
可以在用Keynote畫出手繪風格的配圖中找到文章的繪圖方法。
審核編輯:湯梓紅
-
設計模式
+關注
關注
0文章
53瀏覽量
8645 -
迭代器
+關注
關注
0文章
44瀏覽量
4329
原文標題:【Go實現】實踐GoF的23種設計模式:迭代器模式
文章出處:【微信號:yuanrunzi,微信公眾號:元閏子的邀請】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
談談Python 中的迭代器模式
關于國產MCU GOF32F103C8T6 軟硬件通用
Command模式與動態語言


GoF設計模式之代理模式
實踐GoF的23種設計模式:備忘錄模式
實踐GoF的23種設計模式:解釋器模式





 工商網監
工商網監
評論