") 利用對(duì)比前綴控制文本生成以及長(zhǎng)文本生成的動(dòng)態(tài)內(nèi)容規(guī)劃
利用對(duì)比前綴控制文本生成以及長(zhǎng)文本生成的動(dòng)態(tài)內(nèi)容規(guī)劃
引言
文本生成作為人工智能領(lǐng)域研究熱點(diǎn)之一,其研究進(jìn)展與成果也引發(fā)了眾多關(guān)注。本篇主要介紹了三篇ACL2022的三篇文章。主要包含了增強(qiáng)預(yù)訓(xùn)練語言模型理解少見詞語能力的可插拔模型、利用對(duì)比前綴控制文本生成以及長(zhǎng)文本生成的動(dòng)態(tài)內(nèi)容規(guī)劃。
文章概覽
1. A Simple but Effective Pluggable Entity Lookup Table for Pre-trained Language Models
一個(gè)簡(jiǎn)單但有效的預(yù)訓(xùn)練語言模型的可插拔實(shí)體查找表
論文地址:https://arxiv.org/pdf/2202.13392.pdf
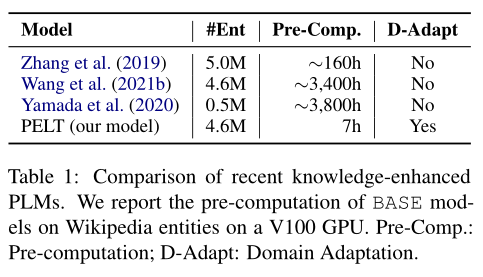
預(yù)訓(xùn)練語言模型(PLM)不能很好地回憶大規(guī)模語料庫中實(shí)體詞語的知識(shí),尤其是那些少見的實(shí)體。這篇文章通過將實(shí)體在語料庫中多次出現(xiàn)的輸出嵌入表示結(jié)合起來,構(gòu)建了一個(gè)簡(jiǎn)單但有效的可插拔實(shí)體查找表(PELT)。PELT可以兼容地插入PLM,向其補(bǔ)充實(shí)體詞語的知識(shí)。與以往的知識(shí)增強(qiáng)PLM相比,PELT僅需要0.2% ~ 5%預(yù)訓(xùn)練的計(jì)算量,并具有從不同領(lǐng)域語料庫獲取知識(shí)的能力。
2. Controllable Natural Language Generation with Contrastive Prefixes
帶有對(duì)比前綴的可控文本生成
論文地址:https://arxiv.org/pdf/2202.13257.pdf
為了引導(dǎo)預(yù)訓(xùn)練語言模型的生成具有某種屬性的文本,以前的工作主要集中在微調(diào)語言模型或利用屬性鑒別器。這篇文章在前綴微調(diào)的基礎(chǔ)上進(jìn)行改進(jìn),考慮了前綴之間的關(guān)系,同時(shí)訓(xùn)練多個(gè)前綴。本文提出了一種新的監(jiān)督學(xué)習(xí)和一種無監(jiān)督學(xué)習(xí)來訓(xùn)練單個(gè)屬性標(biāo)簽控制的前綴,而這兩種方法的結(jié)合可以實(shí)現(xiàn)多個(gè)屬性標(biāo)簽的控制。實(shí)驗(yàn)結(jié)果表明,該方法能夠在保持較高語言質(zhì)量的同時(shí),引導(dǎo)生成文本具有所需的屬性。
3. PLANET: Dynamic Content Planning in Autoregressive Transformers for Long-form Text Generation
PLANET:用于長(zhǎng)文本生成的自回歸Transformer中的動(dòng)態(tài)內(nèi)容規(guī)劃
論文地址:https://arxiv.org/pdf/2203.09100.pdf
現(xiàn)有的方法在長(zhǎng)文本生成任務(wù)中存在邏輯不連貫的問題,這篇文章提出了一個(gè)新的生成框架PLANET,利用自回歸的自注意力機(jī)制來動(dòng)態(tài)地進(jìn)行內(nèi)容規(guī)劃和表層實(shí)現(xiàn)。為了指導(dǎo)輸出句子的生成,該框架將句子的潛在表征補(bǔ)充到Transformer解碼器中,以維持基于詞袋的句子級(jí)語義規(guī)劃。此外,該模型引入了一個(gè)基于文本連貫性的對(duì)比學(xué)習(xí)目標(biāo),以進(jìn)一步提高輸出的內(nèi)容連貫性。在反駁論點(diǎn)生成和觀點(diǎn)文章生成這兩個(gè)任務(wù)中,該方法明顯優(yōu)于base line,能生成更連貫的文本和更豐富的內(nèi)容。
論文

動(dòng)機(jī)
一些最新的研究表明,預(yù)訓(xùn)練語言模型(PLM)可以通過自我監(jiān)督的預(yù)訓(xùn)練從大規(guī)模語料庫中自動(dòng)獲取知識(shí),然后將學(xué)到的知識(shí)編碼到模型參數(shù)中。然而,由于詞匯量有限,PLM難以從大規(guī)模語料庫中回憶知識(shí),尤其是少見的實(shí)體。
為了提高PLM理解實(shí)體的能力,目前有兩種方法:
一是從知識(shí)圖譜、實(shí)體描述或語料庫中獲得外部實(shí)體詞嵌入。為了利用外部知識(shí),模型將原始詞嵌入與外部實(shí)體嵌入對(duì)齊。缺點(diǎn)是忽略了從PLM本身探索實(shí)體嵌入,使得所學(xué)到的嵌入沒有領(lǐng)域適應(yīng)性。
二是通過額外的預(yù)訓(xùn)練將知識(shí)注入PLM的參數(shù)中,例如從語料庫構(gòu)建額外的實(shí)體詞匯,或采用與實(shí)體相關(guān)的訓(xùn)練前任務(wù)來強(qiáng)化實(shí)體表示。缺點(diǎn)是額外預(yù)訓(xùn)練計(jì)算量過于龐大,增加了下游任務(wù)擴(kuò)展或更新定制詞匯表的成本。
本文為了解決前兩種方法的缺點(diǎn),引入了一個(gè)簡(jiǎn)單有效的可插拔實(shí)體查找表(PELT),將知識(shí)注入到PLM中。優(yōu)點(diǎn)是只消耗相當(dāng)于0.2% ~ 5%的預(yù)訓(xùn)練計(jì)算量,并且支持來自不同領(lǐng)域的詞匯。
模型
重新審視Masked Language Modeling
PLM進(jìn)行自我監(jiān)督的預(yù)訓(xùn)練任務(wù),如掩碼語言建模(Masked Language Modeling,MLM),從大規(guī)模未標(biāo)記語料庫中學(xué)習(xí)語義和句法知識(shí)。MLM可以看作是一種完形填空任務(wù),根據(jù)上下文表示來預(yù)測(cè)缺失的詞。
給定一個(gè)詞序列, MLM先將其中某個(gè)詞語替換為[MASK]標(biāo)記,再將替換之后的進(jìn)行詞嵌入和位置嵌入作為PLM的輸入,獲得上下文表示:
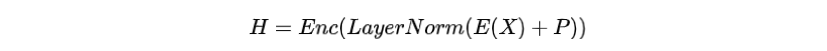
其中為Transformer的編碼器,為層歸一化,為詞嵌入,為位置嵌入。
然后PLM使用前饋神經(jīng)網(wǎng)絡(luò)(FFN)來輸出被掩蓋位置的預(yù)測(cè)詞嵌入
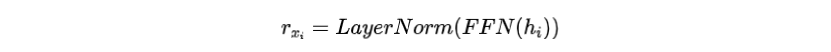
進(jìn)一步計(jì)算在所有單詞之間的交叉熵?fù)p失
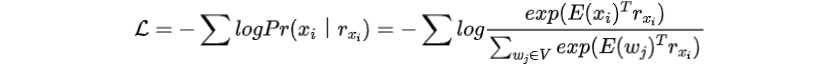
重新審視上式中的損失,可以直觀地觀察到詞嵌入和PLM的輸出位于同一個(gè)向量空間。因此,我們能夠從PLM的輸出補(bǔ)充實(shí)體詞的嵌入,將其上下文知識(shí)注入到模型中。
構(gòu)建可插拔的實(shí)體嵌入
具體地說,給定一個(gè)通用的或特定于領(lǐng)域的語料庫,本文的模型構(gòu)建了一個(gè)實(shí)體詞查找表。對(duì)于實(shí)體,例如Wikidata實(shí)體或?qū)S忻~實(shí)體,我們構(gòu)造其嵌入如下:
步驟1:收集所有包含實(shí)體e的句子,并用[MASK]掩蓋
為了在PLM詞匯表中加入實(shí)體,可以在其他參數(shù)被凍結(jié)的情況下優(yōu)化其嵌入。首先收集包含實(shí)體的句子,并用[MASK]替換。在中,對(duì)MLM損失的影響為
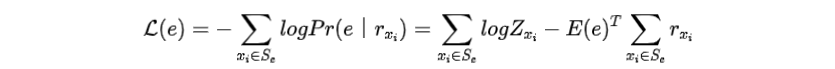
其中
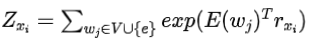
步驟2:求
與整個(gè)詞匯量對(duì)的影響相比,的影響要小得多。如果忽略這部分影響,
求對(duì)的最優(yōu)解,那么的結(jié)果與成正比,記為
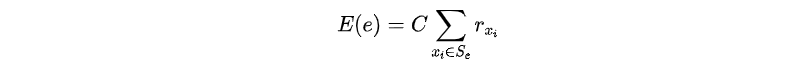
其中為比例因子。
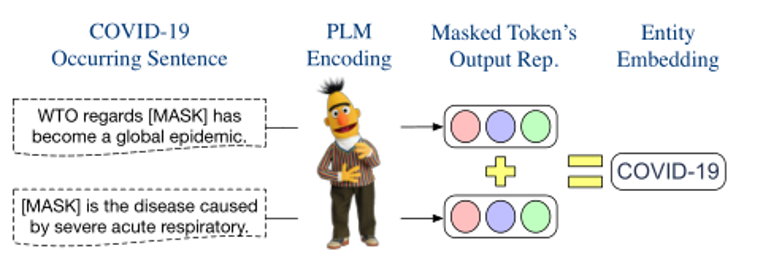
這里說明了將若干個(gè)相加即可得到實(shí)體的新嵌入表示,如下圖所示。
將實(shí)體知識(shí)注入PLM
由于上述得到的新的實(shí)體嵌入和原始詞嵌入都是從MLM中獲得的,因此新的實(shí)體嵌入可以看作是一個(gè)特殊的輸入表示。為了將實(shí)體知識(shí)注入到PLM中,本文使用一對(duì)括號(hào)將構(gòu)建的新嵌入包圍起來,然后將其插入到原始實(shí)體詞嵌入之后。例如,原始輸入為Most people with COVID-19 have a dry [MASK] they can feel in their chest.,在注入新嵌入之后變?yōu)?Most people with COVID-19(COVID-19)have a dry [MASK] they can feel in their chest.
括號(hào)中的即為實(shí)體COVID-19新嵌入,而其他詞使用了原來的嵌入。本文只是將修改后的輸入傳遞給PLM進(jìn)行編碼,而不需要任何額外的結(jié)構(gòu)或參數(shù),以幫助模型預(yù)測(cè)[MASK]處的單詞為"cough"。
實(shí)驗(yàn)
論文比較了關(guān)系分類、知識(shí)獲取的準(zhǔn)確率:
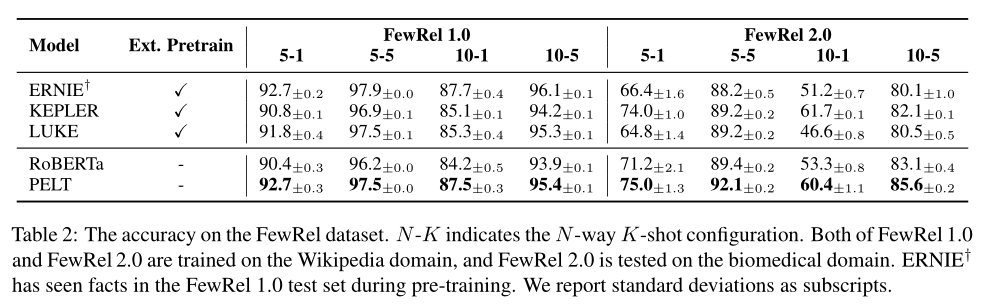
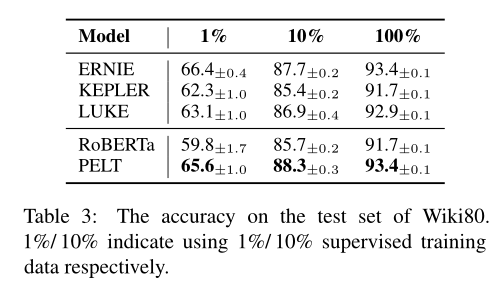
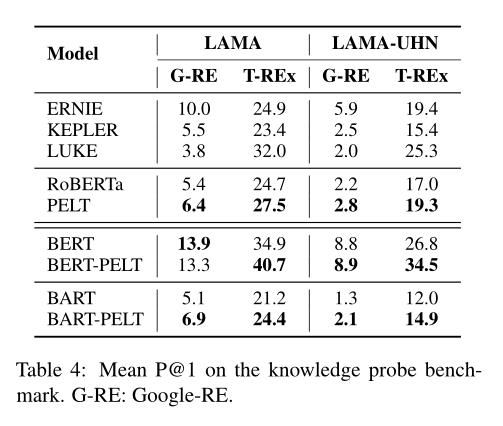
以及對(duì)低頻率實(shí)體性能的提升:
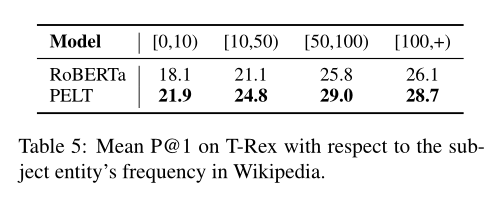
論文

動(dòng)機(jī)
可控文本生成的任務(wù)是引導(dǎo)文本向著期望屬性生成。屬性之間往往存在相互關(guān)系,例如,對(duì)情感這個(gè)主題可以設(shè)定兩個(gè)對(duì)立的屬性:積極和消極,作者認(rèn)為這種相反的關(guān)系有助于提高前綴的可控性,訓(xùn)練時(shí)將某個(gè)主題的所有屬性一起訓(xùn)練,但每個(gè)屬性都各自訓(xùn)練一個(gè)前綴,且前綴互相獨(dú)立。
模型
本文的方法是使用前綴來引導(dǎo)GPT-2的文本生成,其中前綴是一個(gè)屬性特定的連續(xù)向量,位于GPT-2激活層之前。某個(gè)主題的前綴集合記為。與Li和Liang(2021)的每個(gè)屬性前綴都獨(dú)立訓(xùn)練不同,作者考慮了屬性之間的關(guān)系,同時(shí)訓(xùn)練多個(gè)前綴。
的維數(shù)為,其中為前綴數(shù)量,在單主題控制中,等于屬性的數(shù)量。為前綴向量的長(zhǎng)度。,為GPT-2中激活層維度,其中為Transformer層數(shù),為隱藏層大小,代表一個(gè)key向量和一個(gè)value向量。仿照Li和Liang(2021)的做法,作者通過一個(gè)大矩陣和有較小參數(shù)的對(duì)進(jìn)行訓(xùn)練,式子為。訓(xùn)練結(jié)束后,只需要保留,和可以丟棄。由于GPT-2參數(shù)在訓(xùn)練時(shí)被固定,因此也不需要保存。
下圖顯示了一個(gè)在訓(xùn)練后的前綴控制下生成文本的示例。這些前綴可以以監(jiān)督、半監(jiān)督或無監(jiān)督的方式進(jìn)行訓(xùn)練。由于半監(jiān)督方法是監(jiān)督方法和無監(jiān)督方法的結(jié)合,所以文章將介紹監(jiān)督方法和無監(jiān)督方法。為了清晰起見,文章在單主題控制設(shè)置下介紹這些方法。
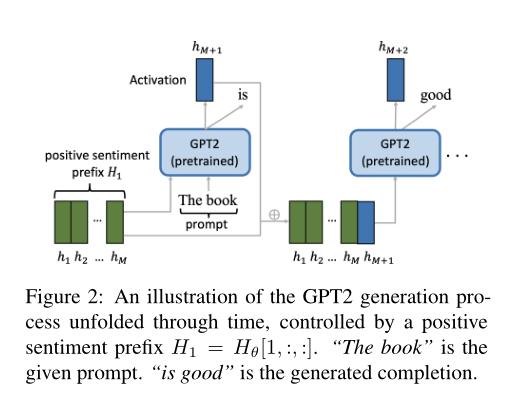
監(jiān)督學(xué)習(xí)
假設(shè)相關(guān)主題有屬性集,每個(gè)訓(xùn)練樣本都是一對(duì),其中是輸入文本,,為的屬性。注意屬性同時(shí)表示中前綴的索引,因此在下面的描述中也表示前綴索引。
給定一個(gè)訓(xùn)練樣本,對(duì)前綴進(jìn)行優(yōu)化以生成,而不鼓勵(lì)其他前綴生成。為了實(shí)現(xiàn)這一目標(biāo),中的所有前綴都應(yīng)該同時(shí)進(jìn)行訓(xùn)練,且需要引入額外的損失函數(shù)。因此,總訓(xùn)練損失是語言模型損失與對(duì)比損失的加權(quán)和:
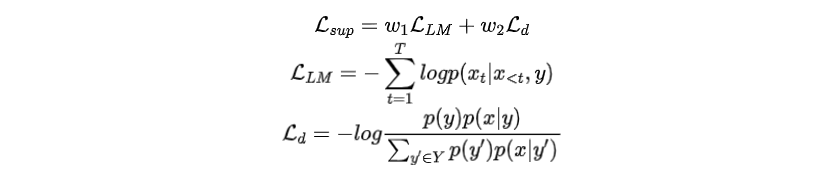
損失能夠讓生成的文本包含鼓勵(lì)生成的信息,損失能夠讓生成的文本去除不鼓勵(lì)產(chǎn)生的信息,代表著不同屬性之間的“距離”。整個(gè)訓(xùn)練過程如下圖所示。

無監(jiān)督學(xué)習(xí)
在無監(jiān)督學(xué)習(xí)中,假設(shè)相關(guān)主題的屬性集是已知的。訓(xùn)練樣本只包含輸入文本。屬性不再可用,因此與x關(guān)聯(lián)的前綴的索引是未知的。因此,對(duì)應(yīng)的前綴的索引是一個(gè)潛變量,其后驗(yàn)分布遵循分類分布。
文章采用上述監(jiān)督學(xué)習(xí)中的主要模型作為解碼器,并引入一個(gè)編碼器來參數(shù)化分類分布,根據(jù)選擇前綴索引,然后將前綴輸入解碼器。由于前綴的選擇過程不可微,作者使用Gumbel-Softmax松弛,計(jì)算如下:
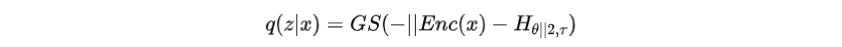
其中是Gumbel-Softmax的溫度,是編碼器函數(shù)。
為了訓(xùn)練前綴,總損失函數(shù)是三個(gè)損失項(xiàng)的加權(quán)和:
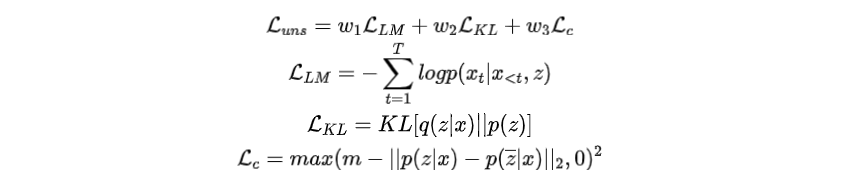
其中為語言模型損失。是KL散度,這里作者假設(shè)先驗(yàn)是均勻分布。注意,這兩項(xiàng)構(gòu)成了VAE的損失函數(shù),優(yōu)化這兩個(gè)損失項(xiàng)可以改善的證據(jù)下界。
為無監(jiān)督對(duì)比損失,類似于監(jiān)督學(xué)習(xí)中,但計(jì)算方式不同,因?yàn)檎鎸?shí)屬性不可用。其中為預(yù)先設(shè)置的距離,是另一個(gè)表示相對(duì)前綴索引的潛在變量,計(jì)算方法如下
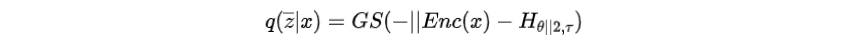
的目的是通過將從推開一段距離。的計(jì)算如下:
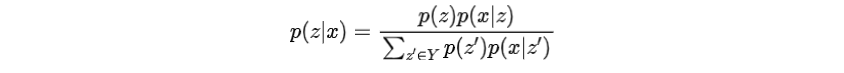
實(shí)驗(yàn)
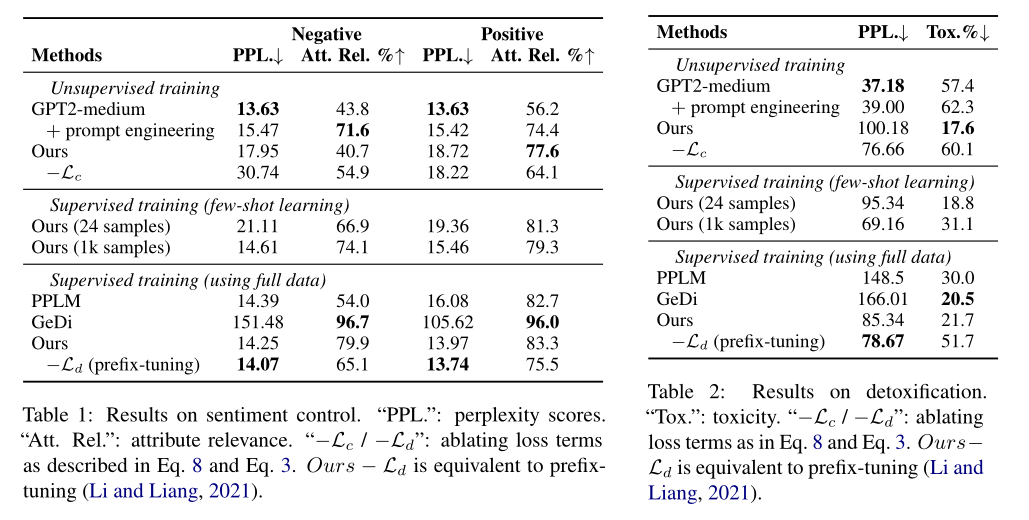
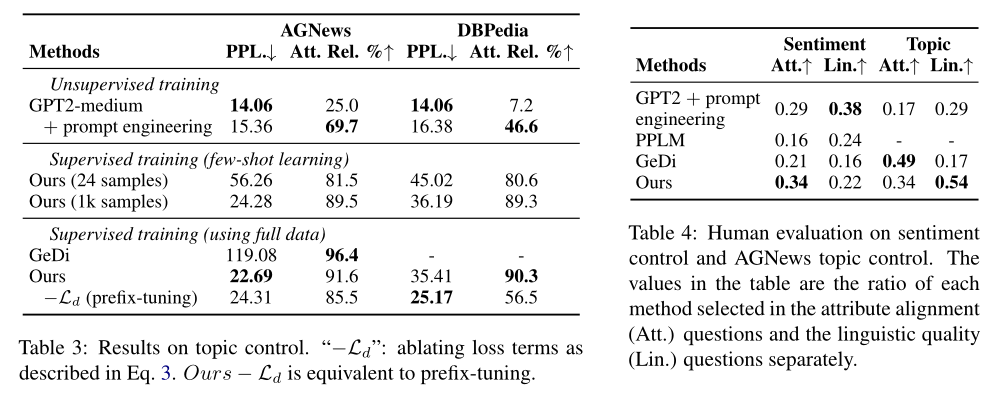
作者做了三個(gè)實(shí)驗(yàn),分別是情感控制、去除有害文本、主題控制。結(jié)果說明了模型在引導(dǎo)生成文本具有某種屬性的能力上有提升
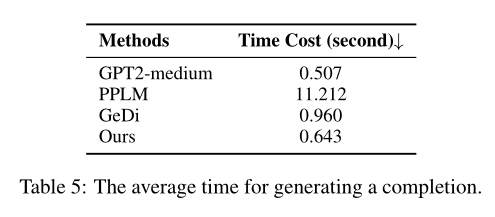
論文

動(dòng)機(jī)
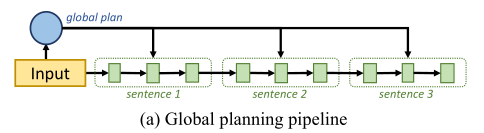
盡管預(yù)訓(xùn)練語言模型在生成流暢文本方面取得了進(jìn)展,但現(xiàn)有的方法在長(zhǎng)文本生成任務(wù)中仍然存在邏輯不連貫的問題,這些任務(wù)需要適當(dāng)?shù)膬?nèi)容規(guī)劃,以形成連貫的高級(jí)邏輯流。現(xiàn)有的方法大致分為兩類,一類是全局規(guī)劃,利用潛在變量作為全局規(guī)劃來指導(dǎo)生成過程,但是沒有考慮細(xì)粒度的句子級(jí)規(guī)劃。
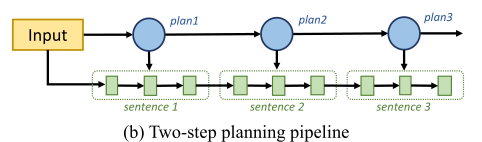
另一類是兩階段規(guī)劃,首先生成句子級(jí)的內(nèi)容規(guī)劃,然后將內(nèi)容規(guī)劃傳遞給表層實(shí)現(xiàn)模塊生成文本,但是內(nèi)容規(guī)劃和表層實(shí)現(xiàn)模塊是脫節(jié)的,無法反向傳播,會(huì)導(dǎo)致錯(cuò)誤累積。
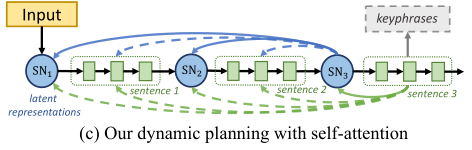
因此文章提出了一個(gè)新的生成框架PLANET,利用自回歸的自我注意力機(jī)制來動(dòng)態(tài)地進(jìn)行內(nèi)容規(guī)劃和表層實(shí)現(xiàn)。
模型
任務(wù)描述
輸入:
(1)一個(gè)語句,該語句可以是論點(diǎn)生成的主題,也可以是文章生成的標(biāo)題,
(2)與該語句相關(guān)的一組無序的關(guān)鍵短語,作為話題的引導(dǎo)信號(hào),對(duì)長(zhǎng)文本生成任務(wù)進(jìn)行建模。
輸出:
一個(gè)由多個(gè)句子組成的文本,以連貫的邏輯恰當(dāng)?shù)胤从沉酥黝}和關(guān)鍵短語。
訓(xùn)練目標(biāo):
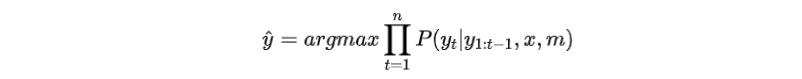
整體框架如圖
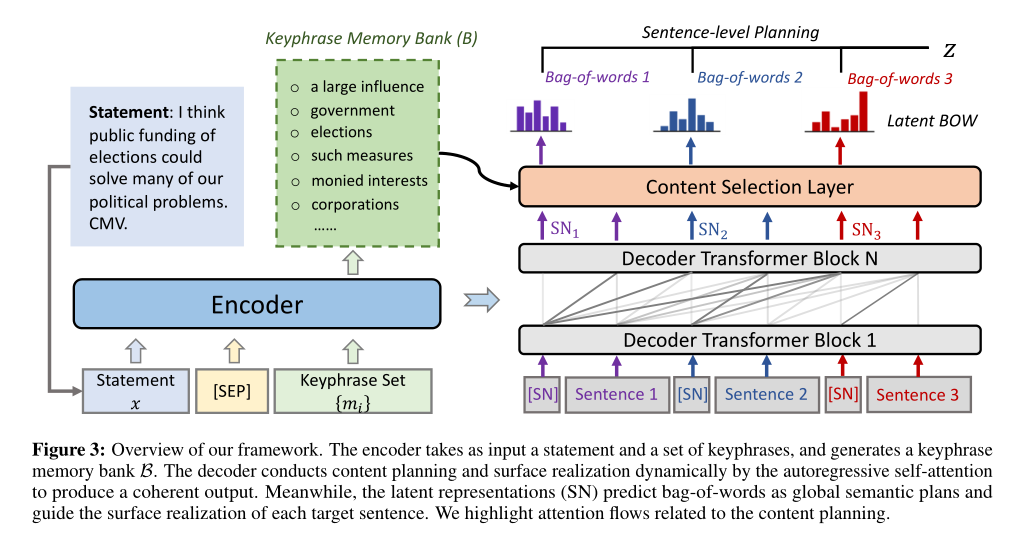
潛在表征學(xué)習(xí)
為每個(gè)目標(biāo)句子引入一個(gè)潛在表征,來表示整個(gè)語義信息,并指導(dǎo)詞的生成。
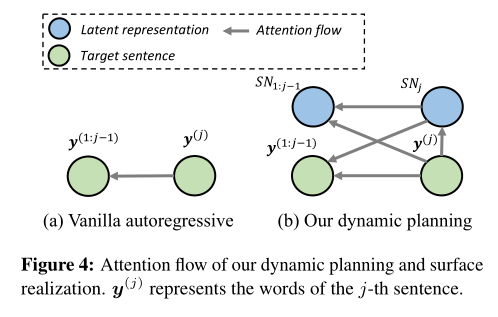
步驟一:在每個(gè)目標(biāo)句子前插入一個(gè)標(biāo)記,并將解碼器在對(duì)應(yīng)位置的隱藏層作為目標(biāo)句子的潛在表征。
步驟二:當(dāng)產(chǎn)生第j個(gè)輸出句子時(shí),潛在表征首先通過前面的潛在表征和前面句子計(jì)算得到。
步驟三:在句子表層實(shí)現(xiàn)時(shí),之前生成的句子和潛在表征都參與到當(dāng)前句子的計(jì)算中,且以當(dāng)前潛在表征為指導(dǎo)。
內(nèi)容選擇
關(guān)鍵詞潛在表征
先將關(guān)鍵詞用分隔符拼接,輸入編碼器以獲得潛在表征,再收集這些潛在表征,構(gòu)建關(guān)鍵詞存儲(chǔ)庫
內(nèi)容選擇層
內(nèi)容選擇層從關(guān)鍵詞存儲(chǔ)庫B中檢索關(guān)鍵詞信息,并將所選信息集成到解碼過程中。
步驟一:在解碼時(shí)間步,Transformer解碼器的頂層表示通過多頭注意力連接到關(guān)鍵詞存儲(chǔ)庫,獲得加入所選關(guān)鍵詞信息的上下文向量
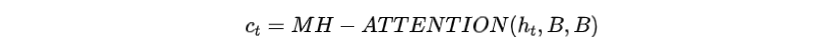
步驟二:通過前饋層和殘差連接(RC)將關(guān)鍵詞上下文向量合并到解碼器的隱藏層中
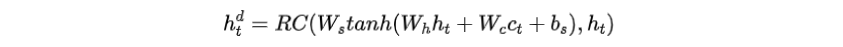
步驟三:通過softmax將增強(qiáng)后的隱藏層傳遞到另一個(gè)前饋層,估計(jì)每個(gè)輸出詞的概率
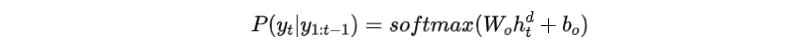
句子級(jí)詞袋規(guī)劃
該部分的目的是監(jiān)督潛在表征SN的學(xué)習(xí)過程。目的是通過目標(biāo)句子的詞袋來反映全局語義規(guī)劃,從而為潛在表征的意義奠定基礎(chǔ)。
將第j個(gè)目標(biāo)句子的詞袋定義為整個(gè)詞匯上的分類分布。其中,為多層前饋網(wǎng)絡(luò)。我們期望該分布能夠捕捉到對(duì)應(yīng)句子的整體語義規(guī)劃。
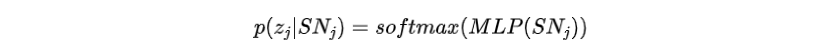
損失函數(shù):最大化預(yù)測(cè)每個(gè)目標(biāo)句子詞袋的可能性。
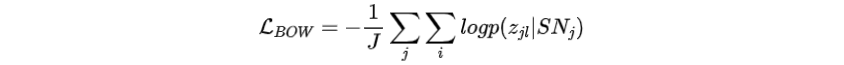
基于一致性的對(duì)比學(xué)習(xí)
該部分的目的是加強(qiáng)內(nèi)容規(guī)劃,并驅(qū)動(dòng)模型學(xué)習(xí)更加連貫的輸出。于是進(jìn)一步設(shè)計(jì)了一個(gè)對(duì)比學(xué)習(xí)(CL)的訓(xùn)練任務(wù)。
負(fù)樣本構(gòu)造
將原始目標(biāo)句子視為代表邏輯連貫輸出的正樣本,并構(gòu)造不連貫的負(fù)樣本。
對(duì)于一個(gè)正樣本,根據(jù)以下策略創(chuàng)建4個(gè)負(fù)樣本:
?SHUFFLE:隨機(jī)打亂目標(biāo)句子
?REPLACE:將50%的原始目標(biāo)句子隨機(jī)替換為語料庫中的隨機(jī)句子
?DIFFERENT:將所有原始目標(biāo)句子全部替換為語料庫中的隨機(jī)句子
?MASK:從關(guān)鍵詞集合中隨機(jī)掩蓋與關(guān)鍵詞相關(guān)的20%的非停詞,并采用BART填充掩蓋的位置
損失函數(shù)
模型將內(nèi)容選擇層的輸出表征映射到0到1之間的一致性得分,并且強(qiáng)制原始目標(biāo)句子的得分比所有對(duì)應(yīng)的負(fù)樣本都大,即設(shè)定一個(gè)固定的邊界
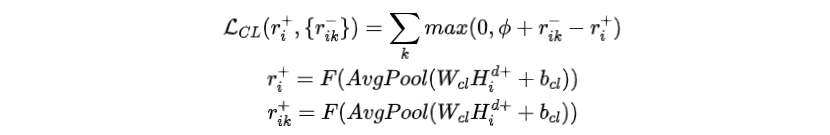
其中,是sigmoid變換,和是正樣本和負(fù)樣本在內(nèi)容選擇層的輸出表征,是平均池化層
訓(xùn)練目標(biāo)函數(shù)
損失函數(shù)聯(lián)合優(yōu)化了內(nèi)容規(guī)劃和表層實(shí)現(xiàn)模型,結(jié)合了以下目標(biāo)函數(shù):
?句子級(jí)詞袋規(guī)劃損失函數(shù)()
?交叉熵?fù)p失函數(shù)()
?對(duì)比學(xué)習(xí)損失函數(shù)()
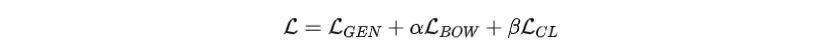
其中α和β被為超參數(shù)。
實(shí)驗(yàn)
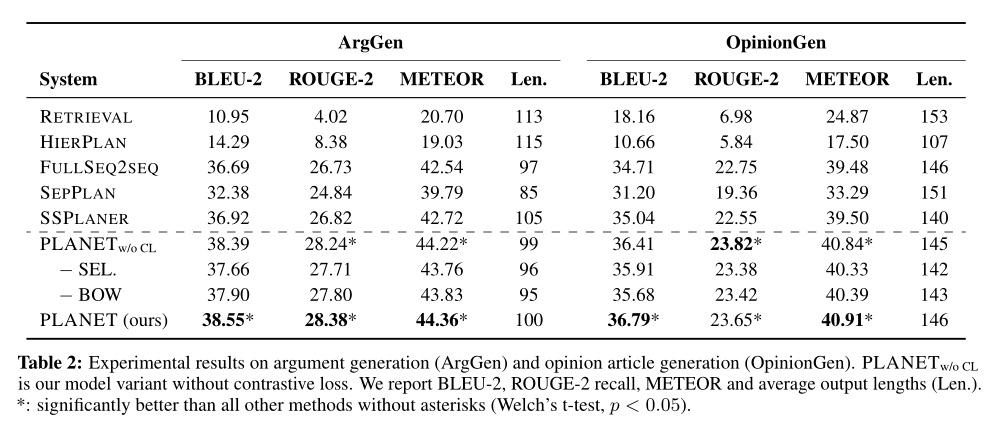
在論點(diǎn)生成和觀點(diǎn)文章生成任務(wù)上進(jìn)行了實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果證明了方法在兩種任務(wù)上都有提升。
審核編輯 :李倩
-
人工智能
+關(guān)注
關(guān)注
1792文章
47497瀏覽量
239211 -
PLM
+關(guān)注
關(guān)注
2文章
124瀏覽量
20884 -
文本
+關(guān)注
關(guān)注
0文章
118瀏覽量
17098
原文標(biāo)題:ACL2022 | 文本生成的相關(guān)前沿進(jìn)展
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
#新年新氣象,大家新年快樂!#AIGC入門及鴻蒙入門
AIGC入門及鴻蒙入門
AIGC與傳統(tǒng)內(nèi)容生成的區(qū)別 AIGC的優(yōu)勢(shì)和挑戰(zhàn)
如何使用 Llama 3 進(jìn)行文本生成
AIGC生成內(nèi)容的優(yōu)勢(shì)與挑戰(zhàn)
AIGC與傳統(tǒng)內(nèi)容生成的區(qū)別
AIGC技術(shù)在內(nèi)容創(chuàng)作中的應(yīng)用
RNN神經(jīng)網(wǎng)絡(luò)適用于什么
生成式AI的基本原理和應(yīng)用領(lǐng)域
什么是LLM?LLM的工作原理和結(jié)構(gòu)
谷歌發(fā)布Imagen 3,提升圖像文本生成技術(shù)
訊飛星火長(zhǎng)文本功能全新升級(jí)
訊飛星火大模型V3.5春季升級(jí),多領(lǐng)域知識(shí)問答超越GPT-4 Turbo?
Adobe Substance 3D整合AI功能:基于文本生成紋理、背景
快速全面了解大模型長(zhǎng)文本能力





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論