") 分享一種更加隱秘且更難排查的"內(nèi)存泄漏"案例
分享一種更加隱秘且更難排查的"內(nèi)存泄漏"案例
一、 問題現(xiàn)象
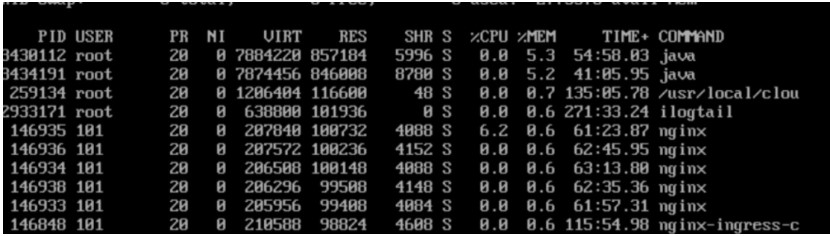
客戶收到系統(tǒng)告警,K8S 集群某些節(jié)點(diǎn) used 內(nèi)存持續(xù)升高,top 查看進(jìn)程使用的內(nèi)存并不多,剩余內(nèi)存不足卻找不到內(nèi)存的使用者,內(nèi)存神秘消失,需要排查內(nèi)存去哪兒了。

執(zhí)行 top 指令并按內(nèi)存排序輸出,內(nèi)存使用最多的進(jìn)程才 800M 左右,加起來遠(yuǎn)達(dá)不到 used 9G 的使用量。
二、問題分析
2.1 內(nèi)存去哪兒了?
在分析具體問題前,我們先把系統(tǒng)內(nèi)存分類,便于找到內(nèi)存使用異常的地方,從內(nèi)存使用性質(zhì)上,可以簡單把內(nèi)存分為應(yīng)用內(nèi)存和內(nèi)核內(nèi)存,兩種內(nèi)存使用量加上空閑內(nèi)存,應(yīng)該接近于 memory total,這樣區(qū)分能夠快速定位問題的邊界。
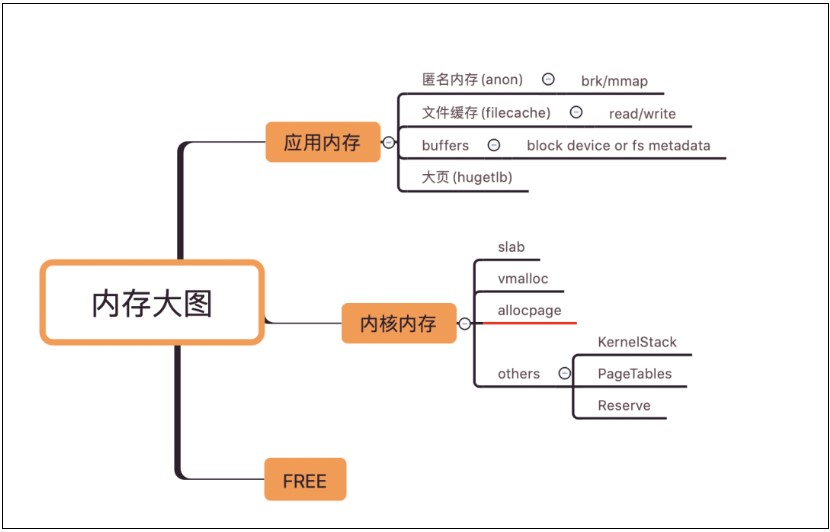
其中 allocpage 指通過 __get_free_pages/alloc_pages 等 API 接口直接從伙伴系統(tǒng)申請的內(nèi)存量(不包含 slab 和 vmalloc)。
2.1.1 內(nèi)存分析
根據(jù)內(nèi)存大圖分別計(jì)算應(yīng)用內(nèi)存和內(nèi)核內(nèi)存,就可以知道是哪部分存在異常,但這些指標(biāo)計(jì)算比較繁瑣,很多內(nèi)存值還存在重疊。針對這個痛點(diǎn),SysOM 運(yùn)維平臺的內(nèi)存大盤功能以可視化的方式展示內(nèi)存的使用情況,并直接給出內(nèi)存是否存在泄漏,本案例中,使用 SysOM 檢測,直接顯示 allocpage 存在泄漏,使用量接近 6G。
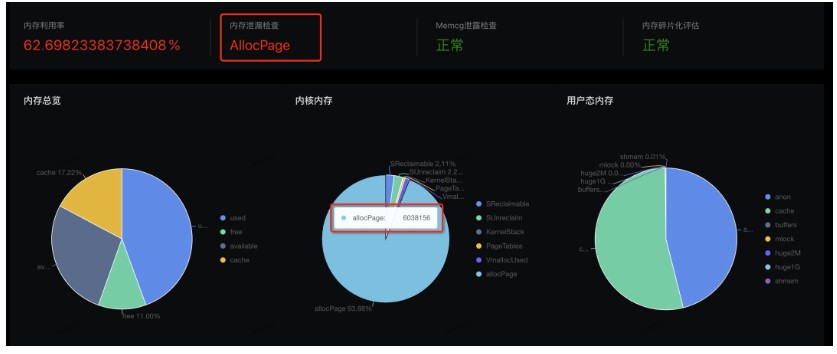
2.1.2 allocpage 內(nèi)存
那既然是 alloc page 類型的內(nèi)存占用多,是否可以直接從 sysfs、procfs 文件節(jié)點(diǎn)查看其內(nèi)存使用了?很遺憾,這部分內(nèi)存是內(nèi)核/驅(qū)動直接調(diào)用 __get_free_page/alloc_pages 等函數(shù)從伙伴系統(tǒng)申請單個或多個連續(xù)的頁面,系統(tǒng)層面沒有接口查詢這部分內(nèi)存使用詳情。如果這類內(nèi)存存在泄漏,就會出現(xiàn)"內(nèi)存憑空消失"的現(xiàn)象,比較難發(fā)現(xiàn),問題原因也難排查。針對這個難點(diǎn),我們的SysOM系統(tǒng)運(yùn)維能夠覆蓋這類內(nèi)存統(tǒng)計(jì)和原因診斷。
所以需要進(jìn)一步通過SysOM的診斷利器 SysAK 動態(tài)抓取這類內(nèi)存的使用情況。
2.2 allocPage 類型內(nèi)存排查
2.2.1 動態(tài)診斷
對于內(nèi)核內(nèi)存泄漏,我們直接可以使用SysAK工具來動態(tài)追蹤,啟動命令并等待 10 分鐘。
sysak memleak -t page -i 600
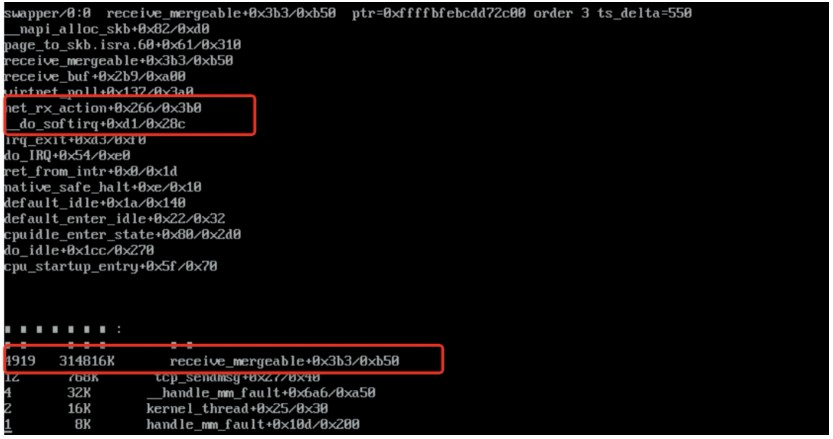
診斷結(jié)果顯示 10 分鐘內(nèi) receive_mergeable 函數(shù)分配的內(nèi)存有 4919 次沒有釋放,內(nèi)存大小在 300M 左右,分析到這里,我們就需要結(jié)合代碼來確認(rèn) receive_mergeable 函數(shù)的內(nèi)存分配和釋放邏輯是否正確。
2.2.2 分配和釋放總結(jié)
1)page_to_skb 每次會分配一個線性數(shù)據(jù)區(qū)為 128 Byte 的 skb。
2)數(shù)據(jù)區(qū)調(diào)用 alloc_pages_node 函數(shù),一次性從伙伴系統(tǒng)申請 32k 內(nèi)存(order=3)。
3)每個 skb 會對 32k 的 head page 產(chǎn)生一次引用計(jì)數(shù),也就是只有當(dāng)所有 skb 都釋放時(shí),這 32k 內(nèi)存才釋放回伙伴系統(tǒng)。
4)receive_mergeable 函數(shù)負(fù)責(zé)申請內(nèi)存,但不負(fù)責(zé)釋放這部分內(nèi)存,只有當(dāng)應(yīng)用從 socket recvQ 中把數(shù)據(jù)讀走才會對 head page 引用計(jì)數(shù)減一,當(dāng) page refs 為 0 時(shí),釋放回伙伴系統(tǒng)。
當(dāng)應(yīng)用消費(fèi)數(shù)據(jù)比較慢,可能會導(dǎo)致 receive_mergeable 函數(shù)申請的內(nèi)存釋放不及時(shí),而且最壞情況一個 skb 會占用 32k 內(nèi)存,使用 sysak skcheck 檢查 socket 接收隊(duì)列和發(fā)送隊(duì)列殘留情況。

從輸出可以知道,系統(tǒng)中只有 nginx 進(jìn)程的接收隊(duì)列有殘留數(shù)據(jù),socket fd=11 的 Recv-Q 有接近 3M 的數(shù)據(jù)沒有接收,通過直接 kill 146935,系統(tǒng)內(nèi)存恢復(fù)正常了,所以問題根本原因就是 nginx 沒有及時(shí)收走數(shù)據(jù)了。
三、問題結(jié)論
經(jīng)過與業(yè)務(wù)方溝通,最終確認(rèn)是業(yè)務(wù)配置問題,導(dǎo)致 nginx 有一個線程沒有處理數(shù)據(jù),從而導(dǎo)致網(wǎng)卡驅(qū)動申請的內(nèi)存沒有及時(shí)釋放,而 allocpage 內(nèi)存又是無法統(tǒng)計(jì)的,從而出現(xiàn)內(nèi)存憑空消失的現(xiàn)象。
3.1 結(jié)論驗(yàn)證
接收隊(duì)列真的有數(shù)據(jù)殘留嗎,這里結(jié)合 crash 工具的 files 指令通過 fd 找到對應(yīng)的sock:

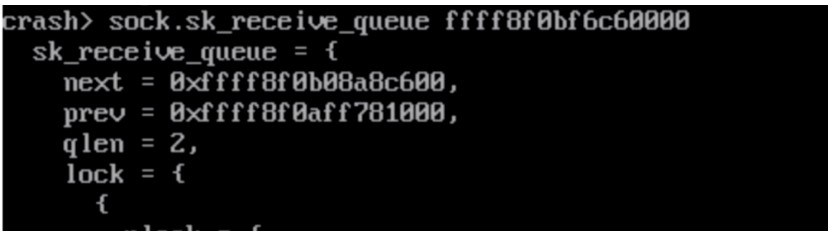
通過多次觀察,發(fā)現(xiàn) sk_receive_queue 上的 skb 長時(shí)間沒有變化,這也證明了 nginx 沒有及時(shí)處理接收隊(duì)列上的 skb,導(dǎo)致在網(wǎng)卡驅(qū)動中分配的內(nèi)存沒有釋放。
四、內(nèi)存泄漏疑點(diǎn)
在排查過程還遇到一個非常較困惑的地方,sockstat 和 slabtop 看檢查 tcp mem 和 skbuff_head_cache 使用都很正常,導(dǎo)致進(jìn)一步掩蓋了網(wǎng)絡(luò)占用的內(nèi)存。
tcp mem = 32204*4K=125M
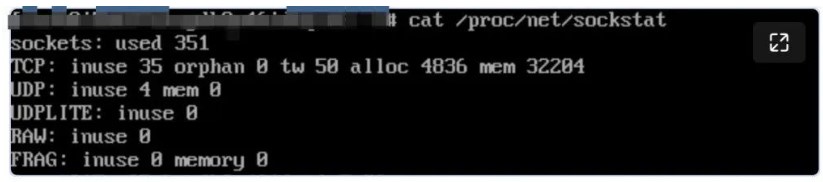
skb 數(shù)量在 1.5萬~3 萬之間。
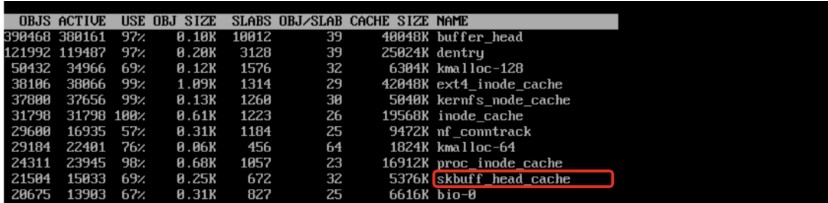
按照前面分析,一個skb最壞情況占用 32k 內(nèi)存,那么 2 萬個 skb 最大也就占 600M 左右,怎么會占用幾個 G 了,難道分析有問題?如下圖所示,skb 的非線性區(qū)可能還存在若干個 frag page,而每個 frag page 又可能由 compund page 組成。
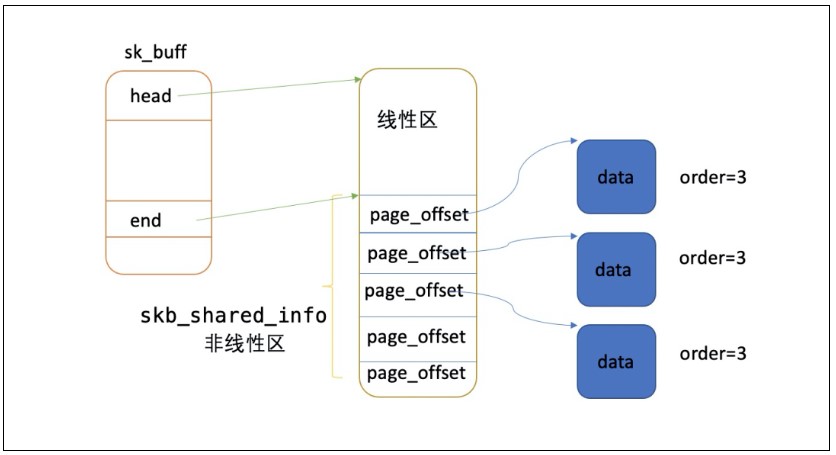
用 crash 實(shí)際讀取 skb 內(nèi)存發(fā)現(xiàn),有些 skb 存在 17 個 frag page,并且數(shù)據(jù)大小只有 10 Byte。
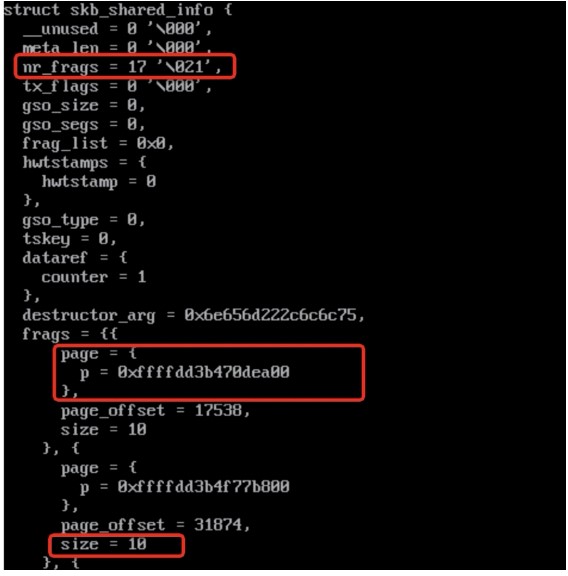
解析 frag page 的 order 為 3,意味著一個 frag page 占用 32k 內(nèi)存。

極端情況下,一個 skb 可能占用(1+17)*8=144 頁,上圖 slabinfo 中skbuff_head_cache 活躍 object 數(shù)量為 15033 個,所以理論最大總內(nèi)存 =144*15033*4K = 8.2G,而我們現(xiàn)在遇到的場景消耗 6G 的內(nèi)存是完全有可能的。
審核編輯:劉清
-
接口
+關(guān)注
關(guān)注
33文章
8667瀏覽量
151514 -
驅(qū)動
+關(guān)注
關(guān)注
12文章
1844瀏覽量
85405 -
內(nèi)存泄漏
+關(guān)注
關(guān)注
0文章
39瀏覽量
9227
發(fā)布評論請先 登錄
相關(guān)推薦
LabVIEW的"連接字符串"VI,會造成內(nèi)存泄漏嗎?
分享一種內(nèi)存泄漏定位排查技巧
為什么打印函數(shù)rt_kprintf("");會多一個空行?
教你如何搭建淺層神經(jīng)網(wǎng)絡(luò)"Hello world"
幾種IO口模擬串口"硬核"操作
"STM32F0 Error: Flash Download failed - ""Cortex-M0""解決"

&quot;跨越地平線 &quot;的電視和電話信號傳輸
喜訊 | 凌科電氣榮獲國家級專精特新&amp;quot;小巨人&amp;quot;企業(yè)

西門子博途LAD-( JMP ):若 RLO = &quot;1&quot; 則跳轉(zhuǎn)
芯片工藝的&quot;7nm&quot; 、&quot;5nm&quot;到底指什么?
橙群微電子NanoBeacon SoC 在 &amp;quot;Truly Innovative Electronics &amp;quot;評選中脫穎而出

程控交流電源開機(jī)顯示&quot;ERR&quot;的原因及解決方法分析
第二代配網(wǎng)行波故障預(yù)警與定位裝置YT/XJ-001:守護(hù)電力線路的超能&amp;quot;哨兵&amp;quot;

科沃斯掃地機(jī)器人通過TüV萊茵&quot;防纏繞&quot;和&quot;高效邊角清潔&quot;認(rèn)證
全方位精準(zhǔn)測量技術(shù)助力:中國經(jīng)濟(jì)加力發(fā)展向前&amp;quot;進(jìn)&amp;quot;






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論