 AWS為什么過去和現在要做芯片和硬件自研這些事情
AWS為什么過去和現在要做芯片和硬件自研這些事情
編者按去年的AWS re:Invent 2021有很多跟芯片相關的內容值得展開來說的事情。但網上已經有很多專業的文章了,我就不再班門弄斧一一介紹了。只好另辟蹊徑,嘗試從整體和發展的角度,和一些“可能存在”的“向左(定制)還是向右(通用)”的權衡,來分析一下AWS為什么過去和現在要做芯片和硬件自研這些事情,以及未來要往何處去。再次強調一下,芯片定制分為兩個方面:芯片功能的定制還是通用,是個技術路徑的問題;巨頭通過定制芯片,滿足自身需求,這是一個商業選擇的問題。這兩者不能混淆。
1 硬件定制
硬件定制可以簡單地分為兩種模式:-
由外而內。從通用的服務器等硬件出發,進一步優化(裁剪和增強)數據中心各種硬件產品,落地成標準化的硬件和系統設計,再通過規模化的部署,來達到降低成本的目的。例如,OCP倡導的各種OCP兼容的服務器、交換機及其他硬件設計。
-
由內而外。從內在的業務場景需求出發,通過軟硬件深層次的協同優化設計,落地到個性化的硬件定制。各家互聯網云計算公司,如AWS、微軟和阿里云等,主要用于自身業務的各種硬件定制產品。
 (a) AWS定制交換機
(a) AWS定制交換機 (b) AWS定制SDN網卡圖1 AWS定制網絡設備如果采用標準的商用路由器,出現問題,供應商最快需要花費六個月時間來修復問題。如圖1(a),AWS根據自己的軟硬件規格定義定制路由器,并且擁有自己的協議開發團隊。雖然一開始的訴求主要是降低成本,但實際上最終的結果是,定制的網絡設備不僅僅降低了成本,最大的收獲是網絡可靠性。AWS路由器采用的是AWS和博通(Broadcom)聯合定制的具有70億晶體管規模的ASIC芯片,總的處理帶寬為3.2Tbit/s(數據來自AWS Re:Invent 2016)。AWS網絡策略的另一個關鍵部分是SDN,AWS將SDN的其中一部分工作從軟件卸載到硬件。如圖1(b),通過硬件卸載網絡功能,降低了CPU的資源消耗,并且降低了網絡延遲以及網絡的性能抖動。
(b) AWS定制SDN網卡圖1 AWS定制網絡設備如果采用標準的商用路由器,出現問題,供應商最快需要花費六個月時間來修復問題。如圖1(a),AWS根據自己的軟硬件規格定義定制路由器,并且擁有自己的協議開發團隊。雖然一開始的訴求主要是降低成本,但實際上最終的結果是,定制的網絡設備不僅僅降低了成本,最大的收獲是網絡可靠性。AWS路由器采用的是AWS和博通(Broadcom)聯合定制的具有70億晶體管規模的ASIC芯片,總的處理帶寬為3.2Tbit/s(數據來自AWS Re:Invent 2016)。AWS網絡策略的另一個關鍵部分是SDN,AWS將SDN的其中一部分工作從軟件卸載到硬件。如圖1(b),通過硬件卸載網絡功能,降低了CPU的資源消耗,并且降低了網絡延遲以及網絡的性能抖動。 (a) AWS定制芯片
(a) AWS定制芯片 (b) AWS定制計算服務器
(b) AWS定制計算服務器 (c) AWS定制存儲服務器圖2 AWS定制芯片及服務器如圖2(a),2015年AWS收購了Annapurna labs公司,之后Annapurna labs設計并生產了AWS定制芯片,可用于AWS各類定制服務器。AWS不僅僅定制硬件(板卡及服務器),也定制自己的芯片。通過芯片定制,可以更好地實現AWS對數據中心的各種創新。如圖2(b),AWS定制1U的服務器,因此其在機架上會占滿1U的槽位。沒有采用更密集的在1U的槽位集成更多的服務器節點的做法,這樣做是為了提高熱效率和功率效率。如圖2(c),AWS自定義的存儲服務器在一個42U標準的機架上部署880塊磁盤,升級后的存儲服務器可以容納1110塊磁盤,存儲容量為11 PB(數據來自AWS的Re:Invent 2016)。
(c) AWS定制存儲服務器圖2 AWS定制芯片及服務器如圖2(a),2015年AWS收購了Annapurna labs公司,之后Annapurna labs設計并生產了AWS定制芯片,可用于AWS各類定制服務器。AWS不僅僅定制硬件(板卡及服務器),也定制自己的芯片。通過芯片定制,可以更好地實現AWS對數據中心的各種創新。如圖2(b),AWS定制1U的服務器,因此其在機架上會占滿1U的槽位。沒有采用更密集的在1U的槽位集成更多的服務器節點的做法,這樣做是為了提高熱效率和功率效率。如圖2(c),AWS自定義的存儲服務器在一個42U標準的機架上部署880塊磁盤,升級后的存儲服務器可以容納1110塊磁盤,存儲容量為11 PB(數據來自AWS的Re:Invent 2016)。2 虛擬化卸載和Nitro DPU芯片
2.1 AWS EC2虛擬化技術的演進
在介紹虛擬化演進之前,我們先介紹下虛擬化的三種方式:-
完全軟件虛擬化(Virt. in Software, VS):支持不需要修改的客戶機OS,所有的操作都被軟件模擬,但性能消耗高達50%-90%。
-
類虛擬化(Para-Virt., PV):客戶機OS通過修改內核和驅動,調用Hypervisor提供的hypercall,客戶機和Hypervisor共同合作,讓模擬更高效。類虛擬化性能消耗大概為10%-50%。
-
完全硬件虛擬化(Virt. in Hardware, VH):硬件支持虛擬化,性能接近裸機,只有0.1%-1.5%的虛擬化消耗。
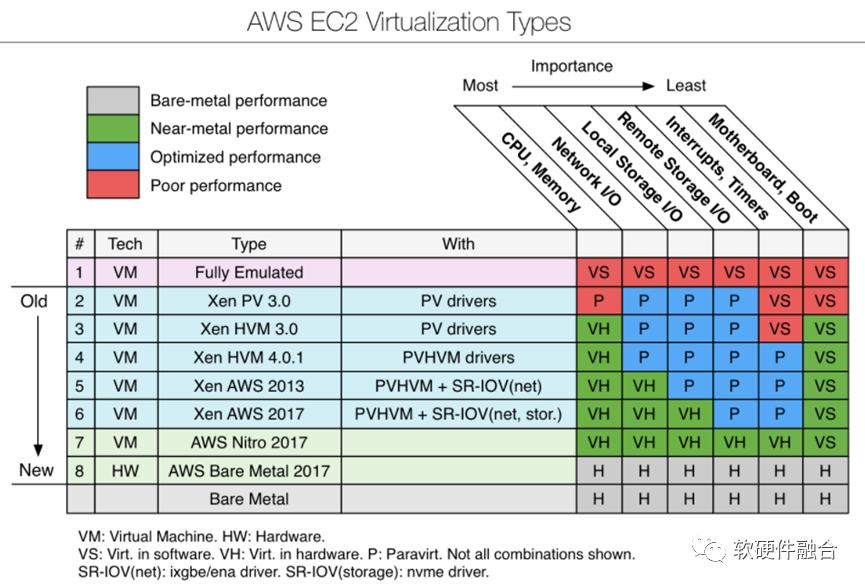 圖3 AWS EC2虛擬化技術演進圖3是AWS“教科書”般的虛擬化迭代優化的演進示意圖。我們只關注與性能最相關的CPU/Mem、網絡I/O、本地存儲I/O、遠程存儲I/O四類計算機資源。大致的演進介紹如下:
圖3 AWS EC2虛擬化技術演進圖3是AWS“教科書”般的虛擬化迭代優化的演進示意圖。我們只關注與性能最相關的CPU/Mem、網絡I/O、本地存儲I/O、遠程存儲I/O四類計算機資源。大致的演進介紹如下:-
最開始,所有的計算機資源都是純軟件模擬的。
-
Xen PV 3.0引入了PV,部分提升了性能。
-
Xen HVM 3.0引入了CPU和內存的硬件虛擬化(基于Intel VT-x和AMD-v技術),大幅度提升了性能;這一時期,網絡和存儲I/O對處理帶寬的要求還不高,PV的I/O虛擬化還是滿足要求的。
-
Xen HVM 4.0.1,沒有優化四個主要的資源,性能提升不算明顯。
-
Xen AWS 2013,通過PCIe SR-IOV技術,正式引入了網絡I/O硬件虛擬化。
-
Xen AWS 2017,通過PCIe SR-IOV技術,正式引入了本地存儲I/O硬件虛擬化。
-
2017年,AWS Nitro 2017。Nitro項目正式登場。站在I/O虛擬化的角度,NITRO項目的創新有限。NITRO最有價值的創新在于把Backend的網絡和遠程存儲的Workload卸載到了NITRO卡上。從Nitro開始,云計算架構就走上了業務和基礎設施在物理上完全隔離的路子。
-
AWS Bare Metal 2017。裸金屬機器和用于EC2虛擬機的Nitro 2017最大的區別在于有沒有一層Lite Hypervisor。
2.2 Nitro DPU芯片的演進
嚴格來說,2017年底AWS宣布的Nitro系統是全球第一家真正商業落地的DPU芯片。AWS引領了DPU的潮流,隨后DPU這個方向才逐漸火熱了起來。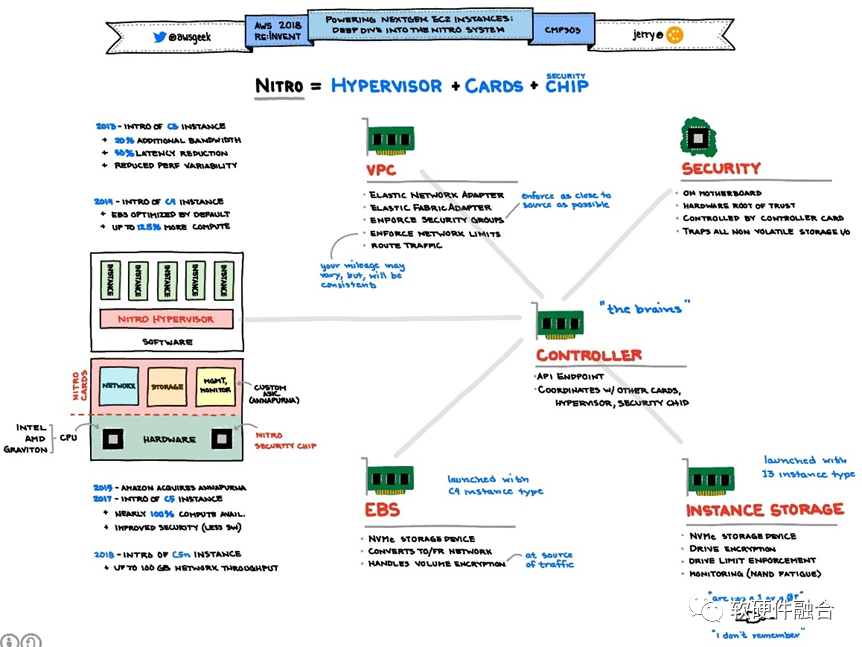 圖4 AWS Nitro系統如圖4所示,不同的EC2服務器實例類型包括不同的Nitro系統特性,一些服務器類型有許多Nitro系統卡,實現AWS Nitro系統的五大主要特性:
圖4 AWS Nitro系統如圖4所示,不同的EC2服務器實例類型包括不同的Nitro系統特性,一些服務器類型有許多Nitro系統卡,實現AWS Nitro系統的五大主要特性:-
Nitro VPC(虛擬私有云)卡;
-
Nitro EBS(彈性塊存儲)卡;
-
Nitro本地存儲卡;
-
Nitro控制器卡;
-
Nitro安全芯片。
-
CPU性能弱,一張不夠,就多張卡整合到一起完成想要的功能;
-
CPU完全可編程,同樣的芯片,同樣的板卡,只需要后期運行不同的軟件,就可以非常方便的實現不同的功能。
-
做到了把VM的業務和宿主機側的管理任務完全隔離,這樣提供了很多安全方面的好處,并且可以打平虛擬機和物理機環境。業務和管理分離,還有很多其他好處,這里不一一展開了。
-
因為是嵌入式的CPU,所以,可以快速地開發新功能。例如基于Nitro嵌入式CPU,開發了SRD和EFA,為高性能的HPC提供解決方案。快速地為業務提供更強大的功能和服務價值,給客戶提供更加快速而積極的功能支持,是云計算的核心競爭力。雖然消耗Nitro卡的資源多一些,但這些可以留待后續持續優化。
2.3 AWS Nitro與NVIDIA DPU的本質區別
看2.2節的內容,很多人可能會認為,Nitro采用CPU設計,AWS的設計水平有限。為什么不像NVIDIA一樣,集成各種ASIC的加速引擎呢?還有一個類似的問題,在手機端,集成各種專用硬件加速引擎的手機SOC芯片已經非常成熟,但為什么數據中心的計算平臺依然是以CPU為主?原因只有一個:數據中心場景,對軟件靈活性的要求,遠高于對性能的要求。如果不能提供靈活性(或者說易用性、可編程性),提供再多的性能都是“無本之木”。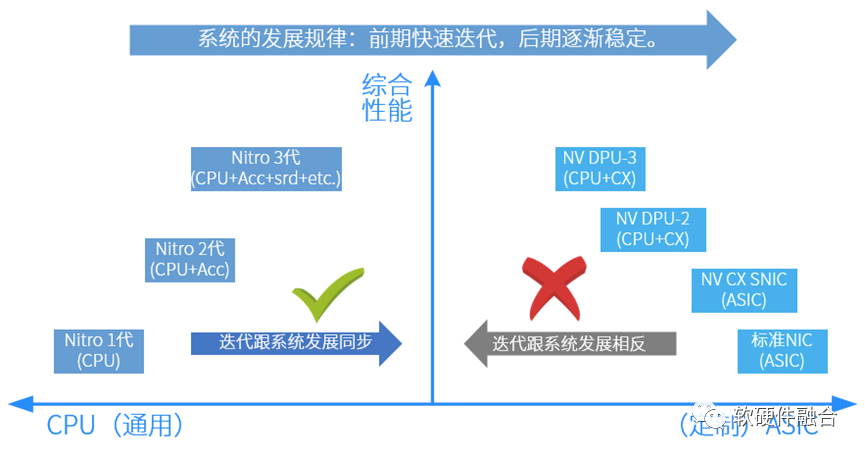 圖4 Nitro和NVIDIA DPU的演進對比互聯網云計算廠家的上層軟件業務邏輯各不相同并且快速迭代,這幾乎無法采用定制的ASIC設計。簡而言之:定制的ASIC很難適合靈活多變的云場景。如圖4所示,芯片公司(NVIDIA)根據自身對業務的理解,做定制ASIC。但這些ASIC實現的加速功能是芯片公司對業務場景的理解,并把業務邏輯固化到定制的設計中,使得云廠家很難基于此硬件平臺開發出差異化的創新功能。并且,定制的設計,限制了云廠家的創新能力,并且使得云場景不得不跟硬件平臺廠家深度綁定,這些對云廠家來說,并不是一件好事。如圖4所示,AWS Nitro和NVIDIA DPU是兩種不同方向的演進:
圖4 Nitro和NVIDIA DPU的演進對比互聯網云計算廠家的上層軟件業務邏輯各不相同并且快速迭代,這幾乎無法采用定制的ASIC設計。簡而言之:定制的ASIC很難適合靈活多變的云場景。如圖4所示,芯片公司(NVIDIA)根據自身對業務的理解,做定制ASIC。但這些ASIC實現的加速功能是芯片公司對業務場景的理解,并把業務邏輯固化到定制的設計中,使得云廠家很難基于此硬件平臺開發出差異化的創新功能。并且,定制的設計,限制了云廠家的創新能力,并且使得云場景不得不跟硬件平臺廠家深度綁定,這些對云廠家來說,并不是一件好事。如圖4所示,AWS Nitro和NVIDIA DPU是兩種不同方向的演進:-
NVIDIA DPU演進:從硬到軟,NIC -> SNIC -> DPU(DPU = SNIC+嵌入式CPU);定制設計,客戶無法差異化,與云系統發展規律相悖。
-
AWS Nitro演進:從軟到硬,CPU基礎上,逐步增加足夠彈性的加速引擎;通用的設計,符合云系統發展規律。
3 Graviton CPU,跟Nitro走向不同的方向
3.1 Graviton CPU的演進
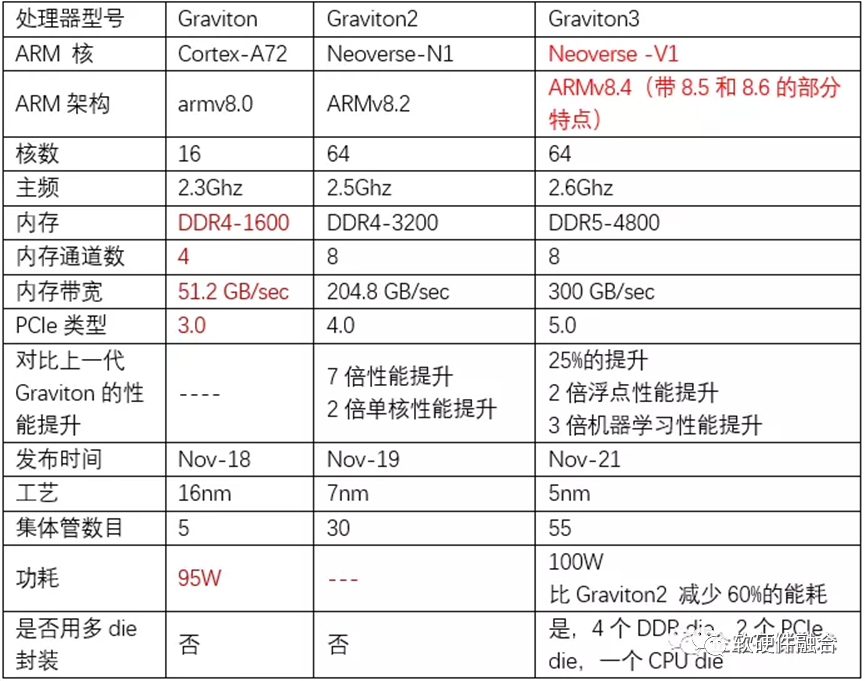 圖5 Winnie Shao博士總結的Graviton CPU的3代演進在AWS re:Invent 2021大會上,AWS發布了最新一代的ARM CPU芯片Graviton 3。相比2018年發布的Graviton 1和2019年發布Graviton 2,有了很大的改進。話不多說,直接上圖。如圖5所示,Winnie Shao博士是CPU領域的專家,她總結的這個表格已經非常完善了,我就不再班門弄斧了。
圖5 Winnie Shao博士總結的Graviton CPU的3代演進在AWS re:Invent 2021大會上,AWS發布了最新一代的ARM CPU芯片Graviton 3。相比2018年發布的Graviton 1和2019年發布Graviton 2,有了很大的改進。話不多說,直接上圖。如圖5所示,Winnie Shao博士是CPU領域的專家,她總結的這個表格已經非常完善了,我就不再班門弄斧了。3.2 Graviton CPU和Nitro DPU的淵源
第一代Nitro是在AWS re:Invent 2017上發布的,初代Nitro本質是一款CPU芯片。隨后一年,re:Invent 2018發布了Nitro 2代以及Graviton 1代ARM CPU芯片。我們大約可以推斷,Nitro 2主要升級了CPU的性能,Nitro 2代和Graviton CPU 1代是比較接近同一款芯片的設計。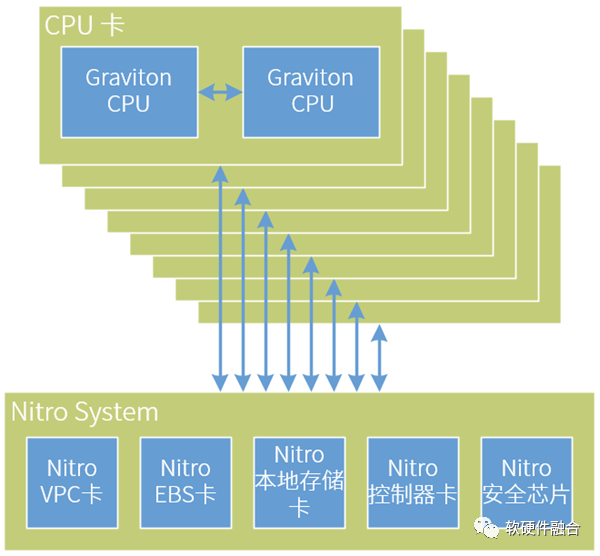 圖6 推測的AWS ARM服務器架構示意圖由于ARM CPU核的單核性能相比x86 CPU核仍有差距,要想更好地實現降成本的目標,勢必需要在ARM服務器的高計算密度方面做文章。如圖6所示,這是我們推測的ARM服務器內部架構,也只有這樣,Nitro System組成一個平臺化的系統,提供Multi-Host的機制給到CPU,可以支持4-8塊CPU計算節點。這樣,可以在單臺服務器規模,最多容納16顆ARM CPU。更極端的推測,如果Graviton和Nitro是同一顆芯片的話,AWS ARM服務器相當于包含了21顆CPU芯片。
圖6 推測的AWS ARM服務器架構示意圖由于ARM CPU核的單核性能相比x86 CPU核仍有差距,要想更好地實現降成本的目標,勢必需要在ARM服務器的高計算密度方面做文章。如圖6所示,這是我們推測的ARM服務器內部架構,也只有這樣,Nitro System組成一個平臺化的系統,提供Multi-Host的機制給到CPU,可以支持4-8塊CPU計算節點。這樣,可以在單臺服務器規模,最多容納16顆ARM CPU。更極端的推測,如果Graviton和Nitro是同一顆芯片的話,AWS ARM服務器相當于包含了21顆CPU芯片。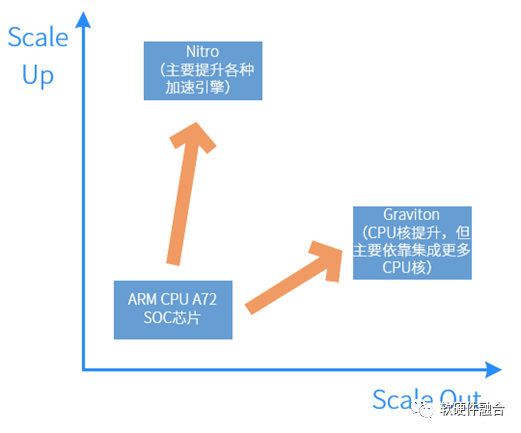 圖7 Graviton和Nitro的演進區別如圖7所示,Graviton和Nitro可以說“同宗同源,師出同門”,但卻因為分工和定位的不同,逐漸走向了兩個不同的方向:
圖7 Graviton和Nitro的演進區別如圖7所示,Graviton和Nitro可以說“同宗同源,師出同門”,但卻因為分工和定位的不同,逐漸走向了兩個不同的方向:-
Graviton的Scale Out模式。Graviton定位為主CPU。勢必需要提供更加強大的單核性能以及提供更高的水平擴展性,也就是說單芯片要集成更多的CPU核,以及要支持多CPU的跨芯片緩沖一致性互聯。
-
Nitro的Scale Up模式。Nitro的主要工作是卸載、隔離和加速。只隔離和卸載,不解決本質問題,只有通過硬件加速才真正實現性能提升和成本降低。所以,Nitro的演進,勢必走向通過硬件加速,瘋狂地提升單芯片的處理性能的路子上。
4 應用加速芯片
4.1 CPU、DPU和GPU/FPGA/DSA
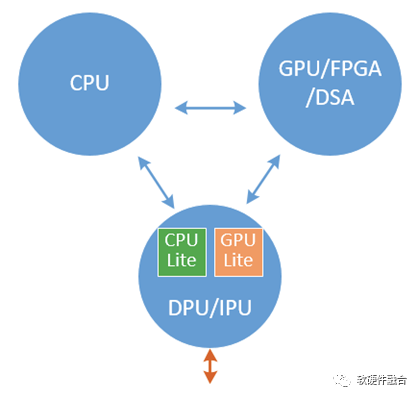 圖8 CPU、GPU/FPGA/DSA以及DPU的關系如圖CPU、GPU/FPGA/DSA和DPU,三者的關系就像《三體》描述的那樣,既相互協作,又相互競爭,最終達到一個相對穩定的狀態:
圖8 CPU、GPU/FPGA/DSA以及DPU的關系如圖CPU、GPU/FPGA/DSA和DPU,三者的關系就像《三體》描述的那樣,既相互協作,又相互競爭,最終達到一個相對穩定的狀態:-
DPU主要定位基礎設施層的加速和處理;
-
GPU/FPGA/DSA主要負責應用層的加速;
-
CPU負責應用層的常規處理。
-
GPU加速的云主機。例如,AWS EC2 P3實例可以提供高性能的計算,可支持高達8個 NVIDIA V100 GPU,可為機器學習、HPC等應用提供高達100Gbps的網絡吞吐量。
-
FPGA加速的云主機。例如,AWS EC2 F1實例使用FPGA實現自定義硬件加速交付。
-
DSA/ASIC加速的云主機。例如,AWS EC2 Inf1實例可在云端提供高性能和最低成本的機器學習推理。這些實例具有多達16個AWS Inferentia芯片,這是由AWS設計和打造的高性能機器學習推理芯片。
4.2 為什么要為特定場景定制芯片
AWS發布了Inferentia定制芯片,它不像Graviton這樣的通用CPU處理器什么都能干,而是專注于機器學習推理。通用CPU處理器可以支持足夠廣泛的各種工作負載類別,當然也包括機器學習推理,為什么還要開發特定工作負載的專用處理器?的確,通用CPU處理器多年來一直承擔著絕大部分的工作負載,CPU數量非常龐大,因此單位的成本可以做到比較低。低成本的優勢可以抵消為特定工作負載芯片定制的優勢。當只有少量服務器運行特定工作負載時,很難從經濟上證明芯片定制優化是合算的。在計算領域之外,芯片定制在網絡領域大放異彩。網絡數據包處理是高度專業化的,網絡協議很少更改。數量足夠大,定制就非常的經濟。因此,大多數網絡數據包處理是使用ASIC芯片完成的。大多數路由器,無論來源如何,基本都是建立在專門的ASIC之上的。雖然,定制ASIC硬件可以將延遲、性能價格比以及性能功耗比提高高達十倍。但是,這么多年以來,大多數的計算工作負載仍“頑強”地停留在通用CPU處理器上。通常,每個客戶服務器數量不多,芯片定制通常意義不大。但是,云計算改變了這一切。在成功且廣泛使用的云中,即使是“稀有”工作負載,其數量也可能達到數千甚至數萬。過去,作為企業,幾乎不可能證明芯片定制,針對特定工作負載的加速處理,是足夠經濟的。但在云中,有成千上萬足夠罕見的工作負載。突然之間,不僅可以針對特定工作負載類型進行硬件的優化,而且如果不這樣做,反而顯得有點“不夠積極”。在很多情況下,芯片定制不僅僅可以把成本降低一個數量級,電量消耗減少到1/10,并且這些定制化的方案可以給客戶以更低的延遲提供更好的服務。定制的芯片將成為未來服務器端計算的重要組成部分,亞馬遜自2015年初以來就有一個專注于AWS的芯片定制團隊,在此之前,AWS與合作伙伴合作構建專業化解決方案。在re:Invent 2016大會上,AWS發布了一款安裝在所有服務器中的定制芯片(James Hamilton的星期二夜現場,Nitro的前身)。盡管這是一個非常專業的定制芯片,但AWS每年安裝的此類定制芯片超過一百萬,而且這個數字還在繼續增加。在服務器領域,它實際上是一個銷量非常大的芯片了。機器學習工作負載需要的服務器資源將比當前所有形式的服務器計算的總和還要多。機器學習的客戶價值幾乎適用于每個領域,潛在收益非常巨大。機器學習幾乎可以立即適用于所有業務,包括客戶服務、保險、金融、供暖/制冷以及制造。一項技術很少有像機器學習一樣如此廣泛的應用,當收益如此之大時,這對大多數企業來說就是一種賽跑。那些最先深入應用機器學習的人或組織可以更有效、更經濟地為客戶服務。AWS專注于讓機器學習的快速部署變得更加容易,同時降低成本,讓更多的工作負載可以更經濟地使用機器學習。規模和針對特定場景的優化,是Inferentia等工作負載專用加速芯片發展的最本質的驅動力量。未來,在大型數據中心,除了AI訓練和推理芯片,也會出現很多面向其他工作負載,如視頻圖像處理、大數據分析、基因組學、電子設計自動化 (EDA)等,的特定加速芯片。4.3 AI-DSA推理芯片Inferentia
Inferentia是AWS第一款AI推理芯片,而基于Inferentia的Inf1實例針對ML推理進行了優化,與基于GPU的同類EC2實例相比,Inferentia的推理成本下降80%,吞吐量提高2.3倍。使用Inf1實例,客戶可以在云端低成本運行大規模ML推理應用程序,例如圖像識別、語音識別、自然語言處理、個性化和欺詐檢測。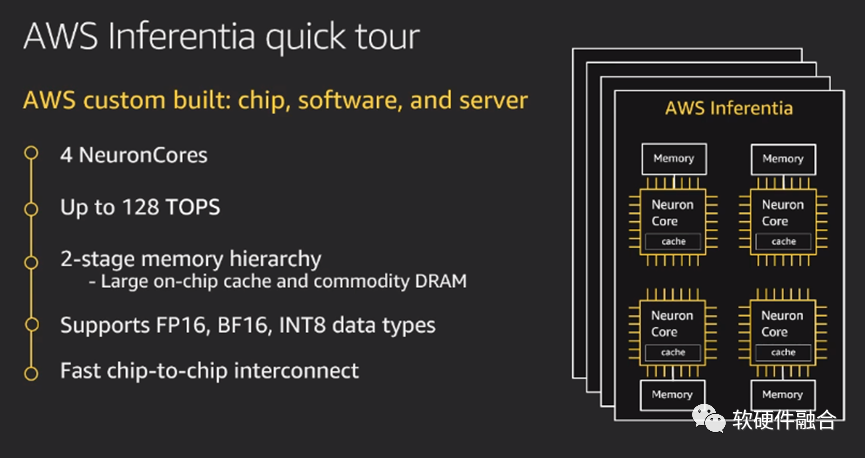 圖9 AWS inferentia AI推理芯片Inferentia的高性能。每個芯片具有4個神經元核心,可以執行高達128 TOPS(每秒數萬億次操作)。它支持BF16、INT8和FP16數據類型。并且,Inferentia可以采用32位訓練模型,并使用BF16的16位模型的速度運行它。亞馬遜推理,低延遲的實時輸出。隨著ML變得越來越復雜,模型不斷增長,將模型傳入和傳出內存成為最關鍵的任務,這帶來了高延遲并放大了計算問題。Inferentia芯片具有在更大程度上解決延遲問題的能力。多芯片互聯:首先可以將模型跨多個內核進行分區,并使用100%的片內內存——通過內核流水線全速傳輸數據,防止片外內存訪問引起的延遲。支持所有框架。機器學習愛好者可以輕松地將幾乎所有可用的框架上運行在Inferentia。要運行Inferentia,需要將模型編譯為硬件優化表示。可以通過AWS Neuron SDK中提供的命令行工具或通過框架API執行操作。
圖9 AWS inferentia AI推理芯片Inferentia的高性能。每個芯片具有4個神經元核心,可以執行高達128 TOPS(每秒數萬億次操作)。它支持BF16、INT8和FP16數據類型。并且,Inferentia可以采用32位訓練模型,并使用BF16的16位模型的速度運行它。亞馬遜推理,低延遲的實時輸出。隨著ML變得越來越復雜,模型不斷增長,將模型傳入和傳出內存成為最關鍵的任務,這帶來了高延遲并放大了計算問題。Inferentia芯片具有在更大程度上解決延遲問題的能力。多芯片互聯:首先可以將模型跨多個內核進行分區,并使用100%的片內內存——通過內核流水線全速傳輸數據,防止片外內存訪問引起的延遲。支持所有框架。機器學習愛好者可以輕松地將幾乎所有可用的框架上運行在Inferentia。要運行Inferentia,需要將模型編譯為硬件優化表示。可以通過AWS Neuron SDK中提供的命令行工具或通過框架API執行操作。4.4 AI-DSA訓練芯片Trainium
 圖10 AWS Trainium AI訓練芯片如圖10所示,在AWS re:Invent 2020開發者大會上,AWS發布了其設計的主要用于機器學習訓練的第二款定制的AI芯片--AWS Trainium。它提供比云端任何競爭對手更高的性能,同時支持TensorFlow、PyTorch和MXNet等。這款定制芯片的主要優勢是速度和成本,AWS承諾與標準AWS GPU實例相比,吞吐量提高30%,每次推斷的成本降低45%。Trainium芯片還專門針對深度學習訓練工作負載進行了優化,包括圖像分類、語義搜索、翻譯、語音識別、自然語言處理和推薦引擎等。它將以EC2(亞馬遜彈性計算云)實例的形式出現在亞馬遜的機器學習平臺SageMaker中。Trainium與Inferentia有著相同的AWS Neuron SDK,這使得使用Inferentia的開發者可以很容易地開始使用Trainium。因為Neuron SDK集成了流行的機器學習框架,包括TensorFlow、PyTorch和MXNet,開發人員可以輕松地從基于GPU的實例遷移到Trainium,代碼更改很少。
圖10 AWS Trainium AI訓練芯片如圖10所示,在AWS re:Invent 2020開發者大會上,AWS發布了其設計的主要用于機器學習訓練的第二款定制的AI芯片--AWS Trainium。它提供比云端任何競爭對手更高的性能,同時支持TensorFlow、PyTorch和MXNet等。這款定制芯片的主要優勢是速度和成本,AWS承諾與標準AWS GPU實例相比,吞吐量提高30%,每次推斷的成本降低45%。Trainium芯片還專門針對深度學習訓練工作負載進行了優化,包括圖像分類、語義搜索、翻譯、語音識別、自然語言處理和推薦引擎等。它將以EC2(亞馬遜彈性計算云)實例的形式出現在亞馬遜的機器學習平臺SageMaker中。Trainium與Inferentia有著相同的AWS Neuron SDK,這使得使用Inferentia的開發者可以很容易地開始使用Trainium。因為Neuron SDK集成了流行的機器學習框架,包括TensorFlow、PyTorch和MXNet,開發人員可以輕松地從基于GPU的實例遷移到Trainium,代碼更改很少。5 Nitro SSD
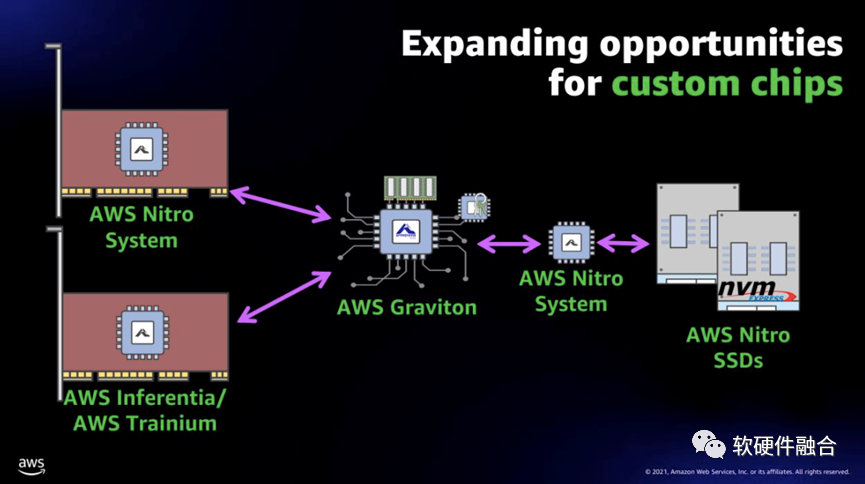 圖11 Nitro SSD的位置Nitro SSD是一張獨立的SSD盤,使用了專用的SSD控制器芯片,我們姑且稱之為Nitro SSD Controller。為什么叫“Nitro” SSD?我理解是因為這個SSD是掛在Nitro卡之下,并且為了整個系統極致的優化,內部的一些協議或算法跟Nitro卡內部有一定的協同,不管是用于本地存儲或者是EBS遠程存儲。AWS Nitro SSD,使AWS能夠為客戶提供具有大量IOPS、大量吞吐量和 64 TiB 的最大卷大小的EBS卷。Im4gn和Is4gen實例使用第二代AWS Nitro SSD,未來許多新的EC2實例也將使用Nitro SSD。AWS Nitro SSD每個設備內部的固件負責實現許多較低級別的功能。當客戶將設備推向極限運行時,客戶希望我們能夠診斷并解決他們觀察到的任何性能不一致問題。構建AWS自己的設備使AWS能夠設計操作遙測和診斷,以及使AWS能夠以云規模和云速度安裝固件更新的機制。更進一步的,AWS開發了自己的代碼來管理實例級存儲,以進一步提高可靠性和調試能力。在性能方面,對云工作負載的深入了解促使AWS對設備進行設計,以便它們能夠在持續的負載下提供最高性能。SSD由快速、密集的閃存構成。由于這種半導體存儲器的特性,每個單元只能被寫入、擦除和重寫有限的次數。為了使設備的使用壽命盡可能長,固件負責一個稱為磨損均衡的過程。這個過程涉及一些內務管理(一種垃圾收集形式),在處理大量寫入時,各種類型的SSD可能會在不可預測的時間變慢(產生延遲峰值)。AWS還利用數據庫的專業知識,在SSD固件中構建了一個非常復雜、斷電安全的基于日志的數據庫。第二代AWS Nitro SSD旨在避免延遲峰值并在實際工作負載上提供出色的I/O性能。基準測試顯示,使用AWS Nitro SSD的實例(例如新的 Im4gn 和 Is4gen)的延遲可變性比I3實例低75%,從而為客戶提供更加一致的SSD性能。
圖11 Nitro SSD的位置Nitro SSD是一張獨立的SSD盤,使用了專用的SSD控制器芯片,我們姑且稱之為Nitro SSD Controller。為什么叫“Nitro” SSD?我理解是因為這個SSD是掛在Nitro卡之下,并且為了整個系統極致的優化,內部的一些協議或算法跟Nitro卡內部有一定的協同,不管是用于本地存儲或者是EBS遠程存儲。AWS Nitro SSD,使AWS能夠為客戶提供具有大量IOPS、大量吞吐量和 64 TiB 的最大卷大小的EBS卷。Im4gn和Is4gen實例使用第二代AWS Nitro SSD,未來許多新的EC2實例也將使用Nitro SSD。AWS Nitro SSD每個設備內部的固件負責實現許多較低級別的功能。當客戶將設備推向極限運行時,客戶希望我們能夠診斷并解決他們觀察到的任何性能不一致問題。構建AWS自己的設備使AWS能夠設計操作遙測和診斷,以及使AWS能夠以云規模和云速度安裝固件更新的機制。更進一步的,AWS開發了自己的代碼來管理實例級存儲,以進一步提高可靠性和調試能力。在性能方面,對云工作負載的深入了解促使AWS對設備進行設計,以便它們能夠在持續的負載下提供最高性能。SSD由快速、密集的閃存構成。由于這種半導體存儲器的特性,每個單元只能被寫入、擦除和重寫有限的次數。為了使設備的使用壽命盡可能長,固件負責一個稱為磨損均衡的過程。這個過程涉及一些內務管理(一種垃圾收集形式),在處理大量寫入時,各種類型的SSD可能會在不可預測的時間變慢(產生延遲峰值)。AWS還利用數據庫的專業知識,在SSD固件中構建了一個非常復雜、斷電安全的基于日志的數據庫。第二代AWS Nitro SSD旨在避免延遲峰值并在實際工作負載上提供出色的I/O性能。基準測試顯示,使用AWS Nitro SSD的實例(例如新的 Im4gn 和 Is4gen)的延遲可變性比I3實例低75%,從而為客戶提供更加一致的SSD性能。6 綜合分析
從定制硬件整機開始,再逐步深入到定制芯片,然后慢慢地把上層的軟件、芯片以及硬件整機全方位協同并整合到一起,亞馬遜AWS逐漸構筑起自己特有的、最強大的競爭優勢。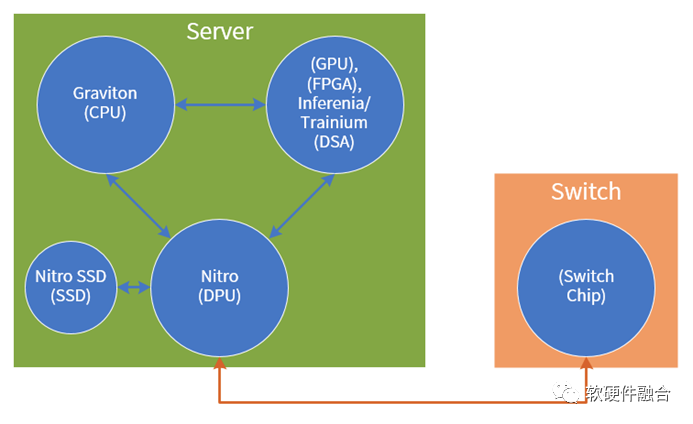 圖12 以AWS為例的數據中心核心芯片示意圖聚焦到芯片,簡單總結一下。如圖12所示,整個數據中心核心的芯片有如下類型:CPU、GPU/FPGA/各種DSA加速芯片、DPU、SSD等高性能存儲控制芯片以及交換機芯片。未來AWS應該要做的是:數據中心關鍵芯片還沒有的會逐漸補齊,已有的芯片類型后續會持續增強。詳細的綜合分析如表1所示。表1 AWS芯片自研綜合分析
圖12 以AWS為例的數據中心核心芯片示意圖聚焦到芯片,簡單總結一下。如圖12所示,整個數據中心核心的芯片有如下類型:CPU、GPU/FPGA/各種DSA加速芯片、DPU、SSD等高性能存儲控制芯片以及交換機芯片。未來AWS應該要做的是:數據中心關鍵芯片還沒有的會逐漸補齊,已有的芯片類型后續會持續增強。詳細的綜合分析如表1所示。表1 AWS芯片自研綜合分析| 位置 | 類型 | 子類型 | 代號 | 分析&推測 |
| 服務器側 | CPU | CPU | Graviton | 重要性:★★★★★CPU是數據中心算力的最核心器件,ARM服務器CPU反響不錯,AWS應該會持續重金投入,加大ARM服務器CPU的使用量,提升ARM服務器的整體占比。 |
| 應用加速 | GPU | 無 | 重要性:★★★★★在AI的算法模型還沒有穩定之前,GPU都是AI算力的重要承擔者,NVIDIA如日中天。AWS因為其上層軟件生態的優勢,以及云計算的運營模式,有能力抵消其在GPU生態上的劣勢。預計未來AWS會自研GPGPU芯片,并加入EC2家族對外提供服務。 | |
| FPGA | 無 | 重要性:★★☆☆☆FPGA作為FaaS平臺,對云計算上層服務來說,沒有那么直接,需要客戶或第三方ISV開發加速硬件和配套的軟件。FaaS不是主流的云服務,并且Xilinx和Intel的FPGA都相對成熟穩定,FPGA應該不是AWS發展的重心。 | ||
| DSA-AI-推理 | Inferentia | 重要性:★★★★☆AI推理和訓練我們放到一起。AI是應用的王者,并且是算力的吞金獸,必須要做各種定制加速DSA。并且,云計算的模式也可以先天抵消DSA-AI的許多使用門檻。通過云的封裝,可以提供各種框架服務甚至SaaS層AI服務,使得AI-DSA芯片能大范圍地用起來。對AWS來說,AI相關的定制芯片,是必須要持續投入,持續優化和增強的。 | ||
| DSA-AI-訓練 | Trainium | |||
| DSA-其他 | 無 | 重要性:★★★☆☆除了AI,也有很多其他算力需求高的工作任務。隨著發展,也會出現新的需要高算力的工作任務,比如元宇宙,就對圖形圖形處理、網絡等提出了更高的要求。GPGPU的效率有所欠缺,并且可見的未來也會像CPU一樣達到性能瓶頸。專用的圖形GPU或者VPU可能會成為AWS下一個定制的DSA芯片。 | ||
| DPU | DPU | Nitro | 重要性:★★★★★(★)因為軟件生態的強大,CPU是數據中心最核心的芯片。但CPU芯片的功能定義已經足夠成熟,只需要持續優化升級改進即可。而DPU的挑戰在于,DPU是整個云計算服務承載的核心,不僅僅是要提供足夠的性能,更是要把現有的許多服務,不僅僅是IaaS層服務,也包括PaaS甚至SaaS的服務,要融入DPU中。可以說,DPU是云計算最戰略級的芯片,沒有之一。給六顆星,不為過。 | |
| CPU、GPU、DPU的整合 | 無 | 重要性:★★★★★NVIDIA有CPU+GPU的處理器,也有CPU+GPU+DPU的Atlan,未來CPU、GPU、DPU兩兩整合,或者三者整合成獨立的單芯片加速平臺是一個越來越明顯的趨勢。集成大芯片,會在性能和成本方面帶來很多的好處。隨著數據中心規模的增大,以及一些場景逐漸穩定成熟,把CPU、GPU、GPU重新整合重構,是一個必然的趨勢。 | ||
| 存儲盤 | SSD | Nitro SSD | 重要性:★★★☆☆存儲控制器廠家,很容易“只見樹木,不見森林”,導致無法站在數據中心超大規模的全局去思考問題,這也會導致存儲卡會成為性能穩定性和數據安全的潛在風險。類似ZNS技術,AWS通過自研Nitro SSD跟Nitro DPU芯片更好地協同,給客戶提供更穩定更安全的存儲服務。只是,與整個數據中心計算相比,這塊相對來說屬于“枝葉”,一旦穩定,后期應該不需要投入太多。 | |
| 交換機側 | Switch | Switch | 無 | 重要性:★★★★★更簡單的網絡,還是更復雜的網絡?網絡到底要不要分擔計算的壓力,足夠Smart來處理一些計算的任務?還是提供極致簡單且極致性能的網絡,把可能的計算都交給用戶,讓用戶掌控一切?上面說的這些話,如何選擇都沒關系。重要的是,交換機是網絡的核心,網絡又是云計算的前提。沒有網絡,計算和存儲什么都不是。這一條就夠了!交換機側,AWS這種體量的云計算公司一定不會放過。期待AWS在交換機側的創新! |
-
AWSInnovationScale,JamesHamilton,Re:Invent2016,https://mvdirona.com/jrh/talksandpapers/ReInvent2016_James%20Hamilton.pdf
-
AWSEC2Virtualization2017:IntroducingNitro,https://www.brendangregg.com/blog/2017-11-29/aws-ec2-virtualization-2017.html
-
AWSNitroSystem,JamesHamilton,https://perspectives.mvdirona.com/2019/02/aws-nitro-system/
-
AWS Graviton3:遵循摩爾定律又有自己節奏,Winnie shao,“企業存儲技術”公眾號,https://mp.weixin.qq.com/s/IFIIJ5sF4yvyGkrcsTPnLw
-
AWSInferentiaMachineLearningProcessor,JamesHamilton,https://perspectives.mvdirona.com/2018/11/aws-inferentia-machine-learning-processor/
-
DeepdiveintoAmazonInferentia:Acustom-builtchiptoenhanceMLandAI,https://www.cloudmanagementinsider.com/amazon-inferentia-for-machine-learning-and-artificial-intelligence/
-
MacOS上云了!AWS還推出機器學習Trainium芯片:萬億次浮點運算,推理成本再降45%,新智元,https://mp.weixin.qq.com/s/4xkLq4S1ZaZLuqQSNHI0_Q
-
AWSNitroSSD–HighPerformanceStorageforyourI/O-IntensiveApplications,https://aws.amazon.com/cn/blogs/aws/aws-nitro-ssd-high-performance-storage-for-your-i-o-intensive-applications/
審核編輯 :李倩
-
芯片
+關注
關注
456文章
50950瀏覽量
424749 -
硬件
+關注
關注
11文章
3348瀏覽量
66305 -
AWS
+關注
關注
0文章
432瀏覽量
24404
原文標題:亞馬遜AWS自研芯片深度分析
文章出處:【微信號:Rocker-IC,微信公眾號:路科驗證】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
蘋果計劃2025年起采用自研藍牙Wi-Fi芯片
蘋果自研5G芯片或于明年亮相
蘋果加速自研芯片進程,iPhone SE 4將首發自研5G基帶
比亞迪最快于11月實現自研算法量產,推進智駕芯片自研進程
蘋果自研Wi-Fi芯片或明年商用,用于部分iPad
小鵬自研智駕芯片:面向L4+AI大模型,集成40核+NPU+ISP






 工商網監
工商網監
評論