 一種全新的數據蒸餾方法來加速NeRF
一種全新的數據蒸餾方法來加速NeRF
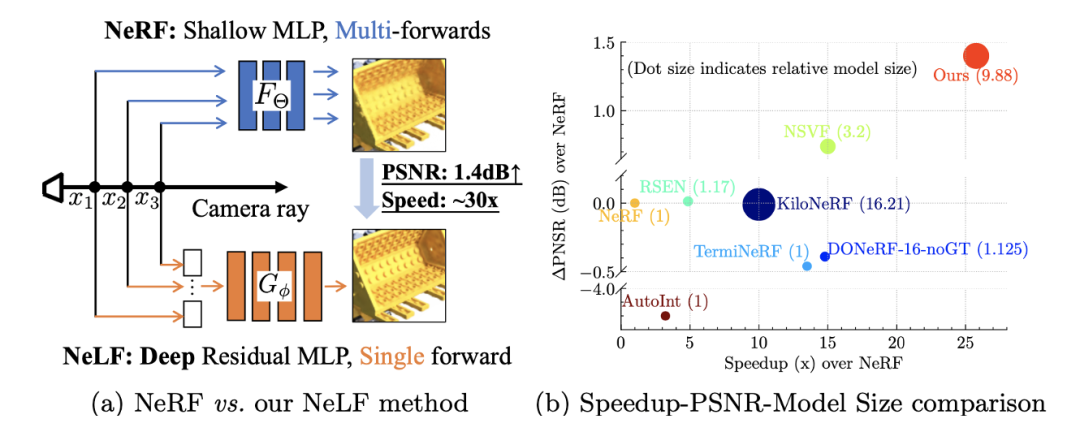
神經輻射場 (Neural Radiance Field, or NeRF) [Mildenhall et al., ECCV, 2020] 開啟了用神經網絡表征三維場景的新范式。NeRF 這兩年在學術界和工業界都很火熱, 但 NeRF 一個比較大的缺點是, 渲染速度慢。雖然 NeRF 用的神經網絡 (11 層的 MLP) 本身很小, 但是渲染一個像素需要采集一條光線上的很多點(上百個), 這導致渲染一張圖的計算量非常大, 如下圖所示: 用 PyTorch 在單張 NVIDIA V100 顯卡測試, 渲染 400x400 的圖片就需要 6.7s 的時間, 這顯然不利于 NeRF 在業界落地 (例如各種 AR/VR 設備, meta universe 等)。
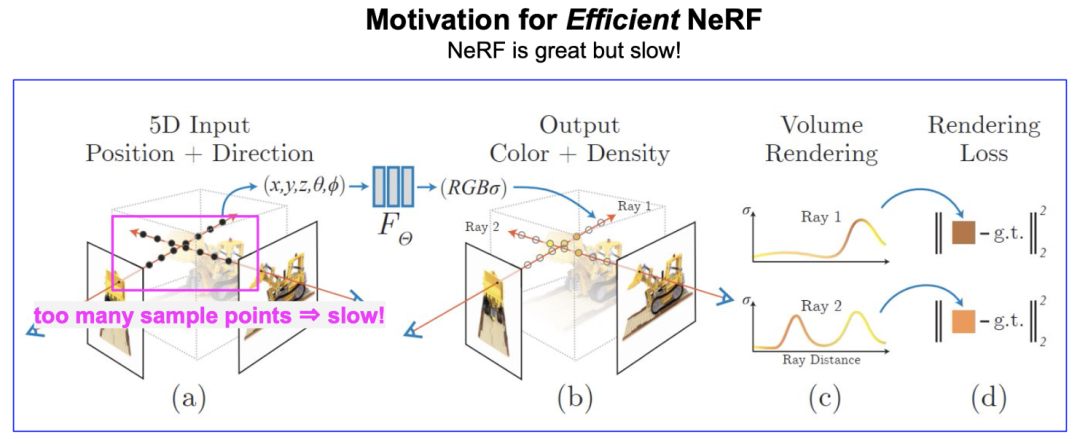
學術界已有不少研究工作來加速 NeRF。比較流行的一種方式是, 給定訓練好的 NeRF, 采用更高效的數據結構進行存儲, 如 Sparse Voxel Octree [Yu et al., ICCV, 2021]. 盡管加速很可觀 (如 [Yu et al., ICCV, 2021] 實現了 3000x 的渲染加速), 但這種數據結構也破壞了 NeRF 作為場景表征存儲小的優點。譬如, 原始 NeRF 網絡僅僅 2.4MB 大小就可以存儲一個場景, 而采用 Sparse Voxel Octree 則需要 1.93GB [Yu et al., ICCV, 2021], 這顯然難以在端上應用。 因此, 如何加速 NeRF 渲染并維持其存儲小的優點 (簡言之: 小且快), 仍然是當前的研究熱點, 也是本文的動因。

Arxiv: https://arxiv.org/abs/2203.17261
Code: https://github.com/snap-research/R2L
Webpage: https://snap-research.github.io/R2L/
核心方法 我們所提出的核心方法從整體范式上來說非常簡單: 通過數據蒸餾將神經輻射場 (NeRF) 轉化為神經光場(Neural Light Field, or NeLF) -- 從 NeRF 到 NeLF, 所以我們把方法命名為 R2L。 NeLF 與 NeRF 一樣, 都可以作為一個場景的表征. 不同的是:
NeRF 的輸入是場景中的一個點 (該點的坐標 + 該點所在視線的方向), 輸出是該點的 RGB 和不透明度。NeRF 網絡的輸出是中間結果, 并不是圖片上的 RGB 值. 要想得到一個像素的 RGB 值, 需要對該像素對應光線上的很多點進行積分 (即 Alpha Compositing)。
而 NeLF 的輸入是一條光線, 輸出直接是該光線對應圖片上像素值, 不需要 Alpha Compositing 這一步。
對于 Novel View Synthesis 這個任務來說, NeLF 的優勢很明顯: 速度快! 要得到一個像素的 RGB 只需要跑一次網絡, 而 NeRF 則需要跑上百次。
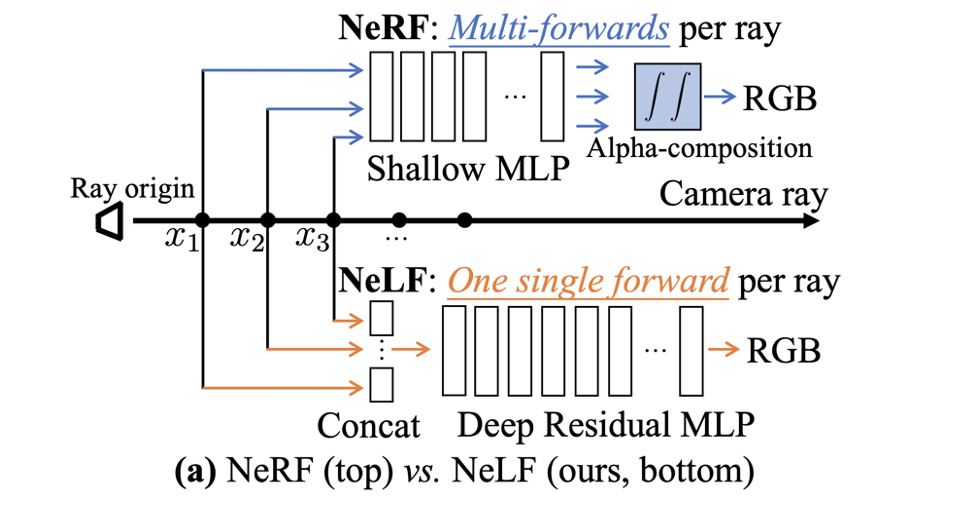
但它的缺點也很明顯, 主要有兩個缺點: (1)NeLF 網絡要擬合的目標函數比 NeRF 更難。這一點可以這么理解: 在一張圖片上相鄰兩個像素的 RGB 可能突變 (因為遮擋), 而相鄰兩個像素的光線方向其實差別很小, 這就意味著, 這個函數的輸入稍微變化一點, 輸出可能劇變, 這種函數的不連續性強, 復雜度高. 相比之下, NeRF 表達的函數是空間中的點, 空間中的點由于物理世界的連續性, 相鄰位置上 RGB 劇變的可能性小, 所以函數相對簡單。 (2)同樣一堆圖片, 用來訓練 NeLF 的話, 樣本量會大幅降低. 一張圖片, 長寬為 H, W, 用來訓練 NeLF 的話樣本量就是 H*W, 而訓練 NeRF 樣本量是 H*W*K (K 是 NeRF 中的一條光線上的采樣點個數, 在 NeRF 原文中 K=256). 所以, 從 NeRF 到 NeLF 訓練樣本量會變為原來的 1/K, 這是很大的縮減。 神經網絡有效, 通常需要有大量的訓練數據。從 NeRF 變為 NeLF, 一方面要擬合的目標函數變復雜了, 同時樣本量卻減小了, 無疑雪上加霜. 如何解決這些問題呢? 為了解決上述問題(1), 我們需要用一個更深的網絡來表征更復雜的函數, 所以在我們的文章中提出了一個 88 層的深度殘差 MLP (deep residual MLP), 網絡結構如下:
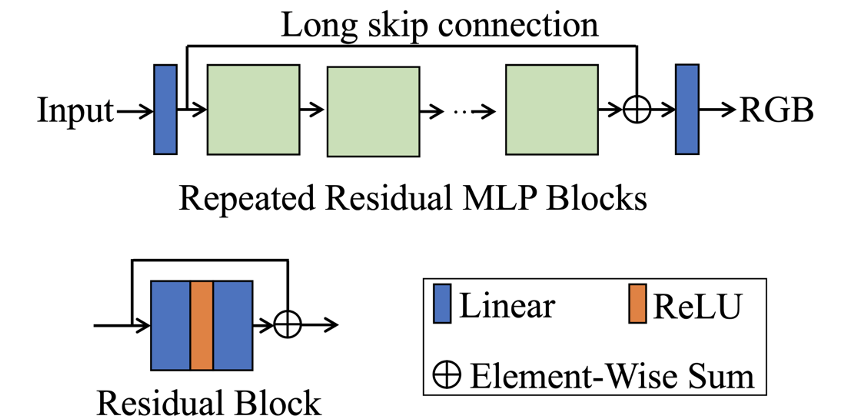
這樣的深層網絡在之前 NeRF 相關的工作沒有出現過 (之前的 NeRF 相關工作大多繼承了原始 NeRF 文章中的網絡結構, 小修小補)。為了能讓它訓練起來, 我們引入了殘差結構的設計。這一點跟 ResNet 的思想一樣, 本身并沒有更多的創新, 但把這一點引入到 NeRF/NeLF 中, 據我們所知, 本文是第一篇工作。殘差結構的引入很有必要, 因為深度網絡沒有殘差結構基本訓練不起來, 這一點在文中的消融實驗中也得到了證實。 另一個值得注意的創新點是關于如何表征一條光線。理論上說, 一條光線用一個方向向量就可以確定, 但如果真的只用方向向量去表征, 就會出現上面說的 “輸入很接近, 輸出卻可能劇變” 的情況, 這就無疑會給 NeLF 網絡的學習帶來困難。為了使得 NeLF 網絡要學習的函數更容易一些, 我們需要增強輸入的差別. 具體來說, 我們采用一條光線上采樣的多個點的坐標 (如下圖所示), 將其串聯(concat) 起來成一個向量, 以此作為該光線的表征, 作為我們 NeLF 網絡的輸入。
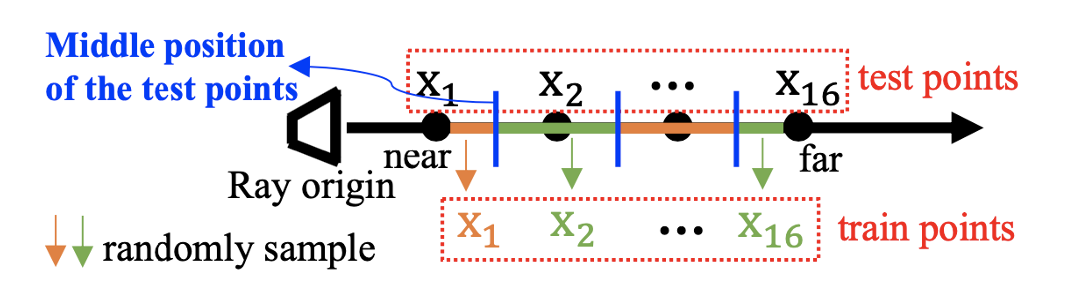
這種表征非常簡單直接, 同時也很有效。在文中, 我們也展示了它比之前的 NeLF 工作中用到的其他表征 (例如 Plucker 坐標 [Sitzmann et al, NeurIPS, 2021]) 要更為有效。 為了解決上述問題(2), 我們使用了一個預訓練好的 NeRF 模型來產生大量偽數據 (pseudo data)。具體來說, 當 NeRF 對一個場景學習完之后, 給定任意一個角度 (ray direction), NeRF 都能返回這個角度下的圖片, 我們就把這些圖片收集起來, 形成了很多 (origin, direction, RGB) triplets。這些 triplets 就是訓練我們模型的數據, loss 函數是 mean squared error (MSE), 如下所示:
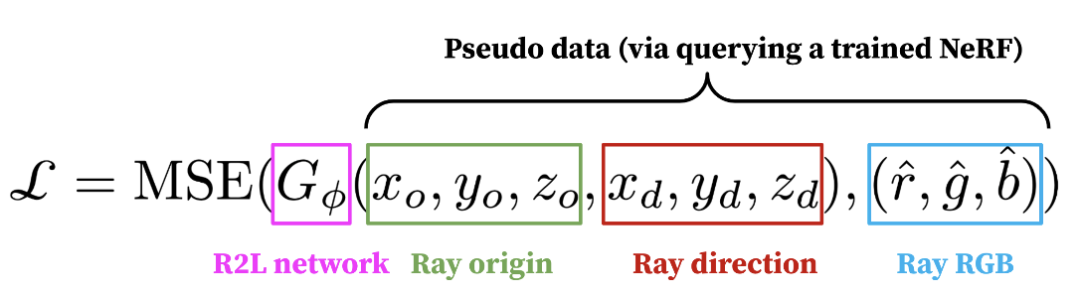
在我們的實驗中, 我們收集了 10k 張圖片, 是原始數據集 (大概 100 張圖片) 的 100 倍, 這些數據確保了有充足的樣本去訓練 NeLF。文中的消融實驗也表明, 大量偽數據對性能至關重要 (6.9dB PSNR 提升)! 值得一提的是, 如果僅僅是用偽數據訓練, 我們的模型最優也只能復制 teacher NeRF, 無法超越它。為了能超越, 我們在原始圖片上再微調 (Finetune) 一下模型。這個操作被證明有非常顯著的效果, 使得我們的模型可以顯著超越 teacher NeRF。 實驗效果 總的來說, 我們的模型在 NeRF Synthetic 數據集 (圖片尺寸 400x400) 上實現了將近 30x 的加速, 并把 PSNR 大幅提升了 1.4dB, 比同類其他方法更加高效。
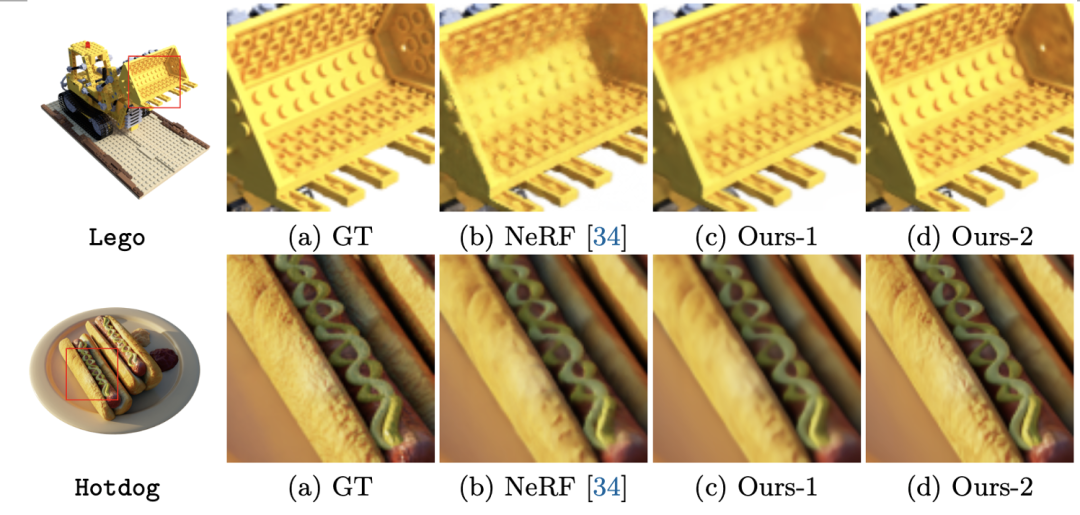
視覺效果圖對比如下, 可以看到, 相比于 NeRF, 我們的模型 (Ours-2, 即在原始數據上微調后的模型)有肉眼可見的提升, 且計算量僅僅是 NeRF 的 1/26。
更多結果請參考我們的文章。代碼已經開源: https://github.com/snap-research/R2L, 歡迎嘗試! 總結與未來工作 本文提出了一種全新的數據蒸餾方法來加速 NeRF: 我們使用訓練好的 NeRF 模型產生偽數據, 來訓練提出的深度殘差 NeLF 網絡。該 NeLF 網絡可以達到超過 NeRF 的渲染質量, 且實現將近 30x 加速, 并維持了存儲小的優點。 未來工作方向: (1) 從 NeRF 中可以得到深度信息, 目前我們還沒提供從 NeLF 網絡中得到深度信息的方法, 這是不錯的探索方向。(2) 如何用更少, 更高質量的偽數據 (譬如進行數據篩選) 來加速 NeLF 的訓練也非常值得探索。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4776瀏覽量
100952 -
數據結構
+關注
關注
3文章
573瀏覽量
40163 -
pytorch
+關注
關注
2文章
808瀏覽量
13283
原文標題:ECCV 2022|Snap&東北大學提出R2L:用數據蒸餾加速NeRF
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

全面總結動態NeRF
PyTorch GPU 加速訓練模型方法
一種創新的動態軌跡預測方法
一種簡單高效配置FPGA的方法

一種無透鏡成像的新方法

rup是一種什么模型
干貨分享 數據記錄儀自動測量與記錄加速度:振動,顛簸,沖擊和定位
基于助聽器開發的一種高效的語音增強神經網絡
AD8338有沒有可行的方法來測量大增益?
看一下通過采用HPC方法來解決汽車行業工程挑戰的兩個具體實例
基于NeRF/Gaussian的全新SLAM算法

一種使用石墨陽極制造快速充電鋰離子電池的新方法





 工商網監
工商網監
評論