 使用TREX探索NVIDIA TensorRT引擎
使用TREX探索NVIDIA TensorRT引擎
NVIDIA TensorRT 的主要功能是加速深度學習推理,通過處理網絡定義并將其轉換為優化的引擎執行計劃來實現。 TensorRT 發動機瀏覽器 ( TREx )是一個 Python 庫和一組 Jupyter 筆記本,用于探索 TensorRT 引擎計劃及其相關推理評測數據。
TREx 提供了對生成引擎的可視性,通過匯總統計數據、圖表實用程序和引擎圖可視化為您提供了新的見解。 TREx 對于高級網絡性能優化和調試非常有用,例如比較網絡兩個版本的性能。對于深入的性能分析,建議使用 NVIDIA Nsight Systems 進行性能分析。
在這篇文章中,我總結了 TREx 的工作流程,并重點介紹了用于檢查數據和 TensorRT 引擎的 API 特性。要查看 TREx 的實際情況,我將通過《 insert action here 》完成如何實現《 value here 》的過程。
TREx 的工作原理
TREx 的主要抽象是trex.EnginePlan,它封裝了與引擎相關的所有信息。一個EnginePlan由幾個輸入 JSON 文件構成,每個文件描述引擎的不同方面,例如其數據依賴關系圖和分析數據。EnginePlan中的信息可以通過 Pandas 數據框訪問,這是一種熟悉、強大且方便的數據結構。
在使用 TREx 之前,必須構建并分析引擎。 TREx 提供了一個簡單的實用程序腳本 process_engine.py 來實現這一點。該腳本作為參考提供,您可以選擇任何方式收集此信息。
此腳本使用 trtexec 從 ONNX 模型構建引擎并分析引擎。它還創建了幾個 JSON 文件,用于捕獲引擎構建和分析會話的各個方面:
平面圖 JSON 文件
計劃圖 JSON 文件以 JSON 格式描述引擎數據流圖。
TensorRT 引擎計劃是 TensorRT 引擎的序列化格式。它包含有關最終推理圖的信息,可以反序列化以執行推理運行時。
TensorRT 8.2 引入了 IEngineInspector API ,它提供了檢查引擎的層、層的配置及其數據依賴性的能力。IEngineInspector使用簡單的 JSON 格式模式提供此信息。此 JSON 文件是 TREx trex.EnginePlan對象的主要輸入,是必需的。
分析 JSON 文件
分析 JSON 文件為每個引擎層提供分析信息。
trtexec 命令行應用程序實現了 IProfiler 接口和 生成 JSON 文件,其中包含每個層的分析記錄。如果您只想調查引擎的結構,而不需要相關的分析信息,則此文件是可選的。
計時記錄 JSON 文件
JSON 文件包含每個分析迭代的計時記錄。
要對引擎進行輪廓分析,trtexec多次執行引擎以平滑測量噪聲。每個引擎執行的計時信息可以作為單獨的記錄記錄在計時 JSON 文件中,平均測量值報告為引擎延遲。此文件是可選的,通常在評估分析會話的質量時非常有用。
如果您看到發動機正時信息變化過大,可能需要確保您只使用 GPU ,并且計算和內存時鐘已鎖定。
元數據 JSON 文件
元數據 JSON 文件描述了引擎的生成器配置以及用于構建引擎的 GPU 的相關信息。此信息為引擎分析會話提供了更有意義的上下文,在比較兩個或多個引擎時尤其有用。
TREx 工作流
圖 1 總結了 TREx 工作流:
首先,將您的深度學習模型轉換為 TensorRT 網絡。
構建和分析引擎,同時生成附帶的 JSON 文件。
旋轉 TREx 以瀏覽文件的內容。

NVIDIA TensorRT 的主要功能是加速深度學習推理,通過處理網絡定義并將其轉換為優化的引擎執行計劃來實現。 TensorRT 發動機瀏覽器 ( TREx )是一個 Python 庫和一組 Jupyter 筆記本,用于探索 TensorRT 引擎計劃及其相關推理評測數據。
TREx 提供了對生成引擎的可視性,通過匯總統計數據、圖表實用程序和引擎圖可視化為您提供了新的見解。 TREx 對于高級網絡性能優化和調試非常有用,例如比較網絡兩個版本的性能。對于深入的性能分析,建議使用 NVIDIA Nsight Systems 進行性能分析。
在這篇文章中,我總結了 TREx 的工作流程,并重點介紹了用于檢查數據和 TensorRT 引擎的 API 特性。要查看 TREx 的實際情況,我將通過《 insert action here 》完成如何實現《 value here 》的過程。
TREx 的工作原理
TREx 的主要抽象是trex.EnginePlan,它封裝了與引擎相關的所有信息。一個EnginePlan由幾個輸入 JSON 文件構成,每個文件描述引擎的不同方面,例如其數據依賴關系圖和分析數據。EnginePlan中的信息可以通過 Pandas 數據框訪問,這是一種熟悉、強大且方便的數據結構。
在使用 TREx 之前,必須構建并分析引擎。 TREx 提供了一個簡單的實用程序腳本 process_engine.py 來實現這一點。該腳本作為參考提供,您可以選擇任何方式收集此信息。
此腳本使用 trtexec 從 ONNX 模型構建引擎并分析引擎。它還創建了幾個 JSON 文件,用于捕獲引擎構建和分析會話的各個方面:
平面圖 JSON 文件
計劃圖 JSON 文件以 JSON 格式描述引擎數據流圖。
TensorRT 引擎計劃是 TensorRT 引擎的序列化格式。它包含有關最終推理圖的信息,可以反序列化以執行推理運行時。
TensorRT 8.2 引入了 IEngineInspector API ,它提供了檢查引擎的層、層的配置及其數據依賴性的能力。IEngineInspector使用簡單的 JSON 格式模式提供此信息。此 JSON 文件是 TREx trex.EnginePlan對象的主要輸入,是必需的。
分析 JSON 文件
分析 JSON 文件為每個引擎層提供分析信息。
trtexec 命令行應用程序實現了 IProfiler 接口和 生成 JSON 文件,其中包含每個層的分析記錄。如果您只想調查引擎的結構,而不需要相關的分析信息,則此文件是可選的。
計時記錄 JSON 文件
JSON 文件包含每個分析迭代的計時記錄。
要對引擎進行輪廓分析,trtexec多次執行引擎以平滑測量噪聲。每個引擎執行的計時信息可以作為單獨的記錄記錄在計時 JSON 文件中,平均測量值報告為引擎延遲。此文件是可選的,通常在評估分析會話的質量時非常有用。
如果您看到發動機正時信息變化過大,可能需要確保您只使用 GPU ,并且計算和內存時鐘已鎖定。
元數據 JSON 文件
元數據 JSON 文件描述了引擎的生成器配置以及用于構建引擎的 GPU 的相關信息。此信息為引擎分析會話提供了更有意義的上下文,在比較兩個或多個引擎時尤其有用。
TREx 工作流
圖 1 總結了 TREx 工作流:
首先,將您的深度學習模型轉換為 TensorRT 網絡。
構建和分析引擎,同時生成附帶的 JSON 文件。
旋轉 TREx 以瀏覽文件的內容。
收集所有分析數據后,可以創建一個EnginePlan實例:
圖 1 :。 TensorRT Engine Explorer 工作流
plan = EnginePlan( "my-engine.graph.json", "my-engine.profile.json", "my-engine.profile.metadata.json")
對于trex.EnginePlan實例,您可以通過 pandasDataFrame對象訪問大部分信息。數據框中的每一行表示計劃文件中的一個層,包括其名稱、策略、輸入、輸出和描述該層的其他屬性。
# Print layer names
plan = EnginePlan("my-engine.graph.json")
df = plan.df
print(df['Name'])
使用數據幀抽象引擎信息很方便,因為它既是許多 Python 開發人員都知道并喜歡的 API ,也是一種功能強大的 API ,具有數據切片、切割、導出、繪圖和打印功能。
例如,列出引擎中三個最慢的層很簡單:
# Print the 3 slowest layers top3 = plan.df.nlargest(3, 'latency.pct_time') for i in range(len(top3)): layer = top3.iloc[i] print("%s: %s" % (layer["Name"], layer["type"])) features.16.conv.2.weight + QuantizeLinear_771 + Conv_775 + Add_777: Convolution features.15.conv.2.weight + QuantizeLinear_722 + Conv_726 + Add_728: Convolution features.12.conv.2.weight + QuantizeLinear_576 + Conv_580 + Add_582: Convolution
我們經常想把信息分組。例如,您可能想知道每種層類型消耗的總延遲:
# Print the latency of each layer type plan.df.groupby(["type"]).sum()[["latency.avg_time"]]
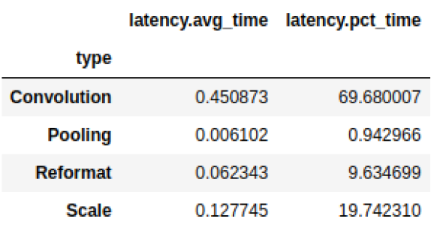
圖 2 :總延遲結果
pandas 與其他庫很好地結合,如用于查看和分析數據幀的方便庫 dtale 和帶有交互式繪圖的圖形庫 Plotly 。這兩個庫都與示例 TREx 筆記本集成,但有許多用戶友好的 備擇方案 ,如 qgrid 、 matplotlib 和 Seaborn 。
還有一些方便的 API ,它們是 Pandas 、 Plotly 和 dtale 的薄包裝:
打印數據(plotting.py)
可視化引擎圖(graphing.py)
交互式筆記本(interactive.py和notebook.py)
報告(report_card.py和compare_engines.py)
最后, linting API (lint.py)使用靜態分析來標記性能危害,類似于軟件 linter 。理想情況下,層過梁提供專家性能反饋,您可以根據這些反饋采取行動,以提高發動機的性能。例如,如果使用次優卷積輸入形狀或次優量化層放置。 linting 功能處于早期開發狀態, NVIDIA 計劃對其進行改進。
TREx 還附帶了兩個教程筆記本和兩個工作流筆記本:一個用于分析單個引擎,另一個用于比較兩個或多個引擎。
使用 TREx API ,您可以編寫新的方法來探索、提取和顯示 TensorRT 引擎,您可以與社區共享。
TREx 演練示例
現在您已經了解了 TREx 的操作方式,下面是一個顯示 TREx 實際操作的示例。
在本例中,您創建了一個量化的優化 TensorRT 引擎 ResNet18 PyTorch ,對其進行分析,最后使用 TREx 檢查發動機計劃。]然后根據所學內容調整模型,以提高其性能。此示例的代碼可在 TREx GitHub 存儲庫中找到。
首先,將 PyTorch ResNet 模型導出為 ONNX 格式。使用 NVIDIA PyTorch 量化工具包 用于在模型中添加量化層,但您不執行校準和微調,因為您關注的是性能,而不是準確性。
在實際用例中,您應該遵循完整的量化感知訓練( QAT )方法。 QAT 工具包自動將假量化操作插入火炬模型。這些操作導出為 QuantizeLinear 和 DequantizeLinear ONNX 運算符:
import torch
import torchvision.models as models
# For QAT
from pytorch_quantization import quant_modules
quant_modules.initialize()
from pytorch_quantization import nn as quant_nn
quant_nn.TensorQuantizer.use_fb_fake_quant = True resnet = models.resnet18(pretrained=True).eval()
# Export to ONNX, with dynamic batch-size
with torch.no_grad(): input = torch.randn(1, 3, 224, 224) torch.onnx.export( resnet, input, "/tmp/resnet/resnet-qat.onnx", input_names=["input.1"], opset_version=13, dynamic_axes={"input.1": {0: "batch_size"}})=
接下來,使用 TREx 實用程序process_engine.py腳本執行以下操作:
從 ONNX 模型構建引擎。
創建引擎計劃 JSON 文件。
分析引擎執行并將結果存儲在分析 JSON 文件中。您還可以將計時結果記錄在一個計時 JSON 文件中。
python3/utils/process_engine.py /tmp/resnet/resnet-qat.onnx /tmp/resnet/qat int8 fp16 shapes=input.1:32x3x224x224
腳本process_engine.py使用trtexec來完成繁重的工作。您可以從process_engine.py命令行透明地將參數傳遞給trtexec,只需列出它們,而不需要--前綴。
在該示例中,參數int8、fp16和shapes=input.1:32x3x224x224被轉發到trtexec,指示其優化 FP16 和 INT8 精度,并將輸入批次大小設置為 32 。第一個腳本參數是輸入 ONNX 文件(/tmp/resnet/resnet-qat.onnx),第二個參數(/tmp/resnet/qat)指向包含生成的 JSON 文件的目錄。
現在,您已經準備好檢查優化的引擎計劃,所以請轉到 TREx 引擎報告卡筆記本 。在這篇文章中,我不會瀏覽整個筆記本,只有幾個單元格對這個例子有用。
第一個單元格設置引擎文件并創建 trex 。來自各種 JSON 文件的 EnginePlan 實例:
engine_name = "/tmp/resnet/qat/resnet-qat.onnx.engine"
plan = EnginePlan( f"{engine_name}.graph.json", f"{engine_name}.profile.json", f"{engine_name}.profile.metadata.json")
下一個單元格創建引擎數據依賴關系圖的可視化,這對于理解原始網絡到引擎的轉換非常有用。 TensorRT 將引擎作為拓撲排序的層列表執行,而不是作為可并行化的圖形執行。
默認呈現格式為SVG,可搜索,在不同比例下保持清晰,并支持懸停文本以提供附加信息,而不占用大量空間。
graph = to_dot(plan, layer_type_formatter) svg_name = render_dot(graph, engine_name, 'svg')
該函數創建一個 SVG 文件并打印其名稱。即使對于小型網絡,筆記本內部的渲染也很麻煩,您可以在單獨的瀏覽器窗口中打開 SVG 文件進行渲染。
TREx graphing API 是可配置的,允許使用各種顏色和格式,并且可用的格式設置程序包含信息。例如,使用默認的格式化程序,層根據其操作進行著色,并按名稱、類型和分析的延遲進行標記。張量被描述為連接各層的邊,并根據其精度進行著色,并用其形狀和內存布局信息進行標記。
在生成的 ResNet QAT 引擎圖(圖 3 )中,您可以看到一些 FP32 張量(紅色)。進一步研究,因為您希望使用 INT8 precision 執行盡可能多的層。使用 INT8 數據和計算精度可以提高吞吐量,降低延遲和功耗。
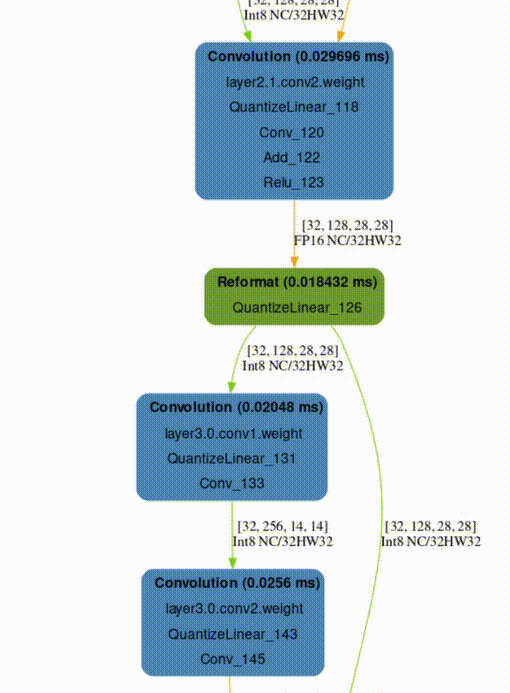
圖 3 :。 QAT ResNet18 引擎的數據依賴關系圖
性能單元提供了各種性能數據視圖,特別是每層精度視圖(圖 4 )顯示了使用 FP32 和 FP16 計算的幾個層。
report_card_perf_overview(plan)
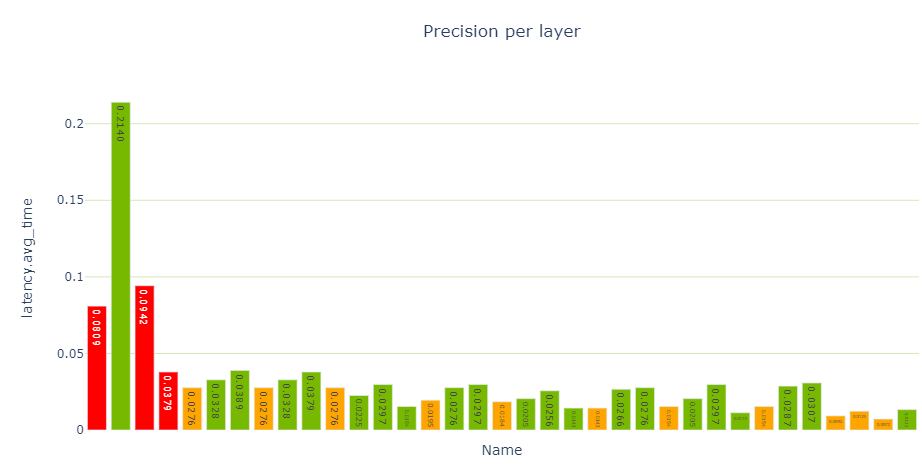
圖 4 :精度每層視圖,帶 ResNet18 QAT ( TREx 使用紅色表示 FP32 ,橙色表示 FP16 , NVIDIA 綠色表示 INT8 精度)
在檢查每層類型的延遲視圖時,共有 12 個重新格式化節點,約占運行時的 26.5% 。那是相當多的。在優化過程中,重新格式化節點會插入到引擎圖中,但也會插入這些節點以轉換精度。每個重新格式化層都有一個原點屬性,描述其存在的原因。
如果您看到太多的精度轉換,您應該看看是否可以做些什么來減少這些轉換。在 TensorRT 8.2 中,您可以看到縮放圖層,而不是為 Q / DQ 操作重新格式化圖層。這是因為 TensorRT 8.2 和 8.4 中使用了不同的圖形優化策略。
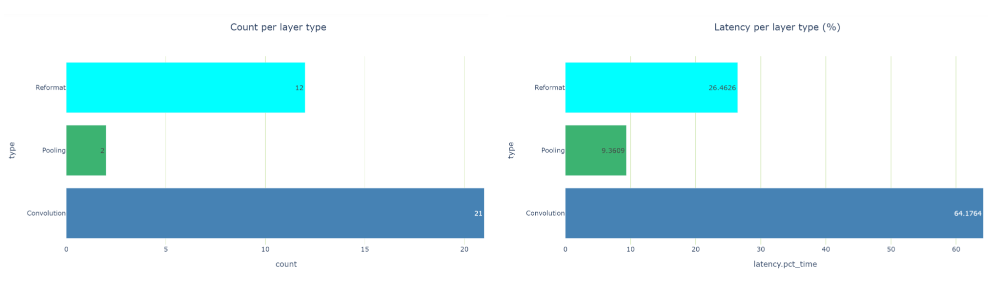
圖 5 每層類型視圖的計數和延遲, ResNet18 QAT
要想挖得更深,請轉到衣料單元中可用的發動機衣料 API 。您可以看到,卷積和 Q / DQ 過濾機都標記了一些潛在的問題。
卷積 linter 標記 13 個具有 INT8 輸入和 FP32 輸出的卷積。理想情況下,如果卷積后面是 INT8 精度層,則希望卷積輸出 INT8 數據。 linter 建議在卷積之后添加量化操作。為什么這些卷積的輸出沒有量化?
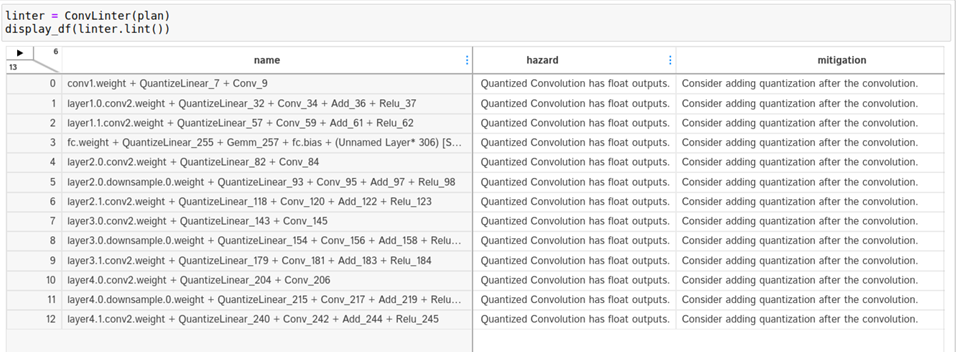
圖 6 卷積過濾機的輸出,關于帶浮點輸出的 INT8 卷積的警告
仔細看看。要在引擎圖中查找卷積,請從 linter 表中復制卷積的名稱,并在圖形 SVG 瀏覽器選項卡中搜索它。結果表明,這些卷積涉及到殘差加法運算。
在咨詢了 Q / DQ 層鋪設建議 之后,您可能會得出結論,您必須在 PyTorch 模型中的剩余連接中添加 Q / DQ 層。不幸的是, QAT 工具包無法自動執行此操作,您必須手動干預 PyTorch 模型代碼。有關更多信息,請參閱 TensorRT QAT 工具包( resnet.py )中的示例。
下面的代碼示例顯示了BasicBlock.forward方法,新的量化代碼以黃色突出顯示。
def forward(self, x: Tensor) -> Tensor: identity = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample is not None: identity = self.downsample(x) if self._quantize: out += self.residual_quantizer(identity) else: out += identity out = self.relu(out) return out
更改 PyTorch 代碼后,必須重新生成模型,并使用修改后的模型再次遍歷筆記本單元格。現在,您可以減少到三個重新格式化層,它們消耗了大約 20.5% 的總延遲(從 26.5% 下降),并且大多數層現在都以 INT8 精度執行。
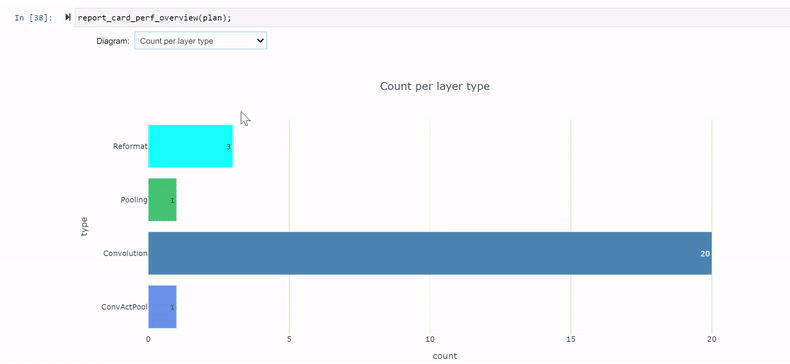
圖 7 : QAT ResNet18 模式,在剩余連接上添加 Q / DQ 后
其余的 FP32 層圍繞網絡末端的全局平均池( GAP )層。再次修改模型以量化間隙層。
def _forward_impl(self, x: Tensor) -》 Tensor: # See note [TorchScript super()] x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) if self._quantize_gap: x = self.gap_quantizer(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x
使用新模型在筆記本單元中進行最后一次迭代。現在只有一個重新格式化層,所有其他層都在 INT8 中執行。搞定了!
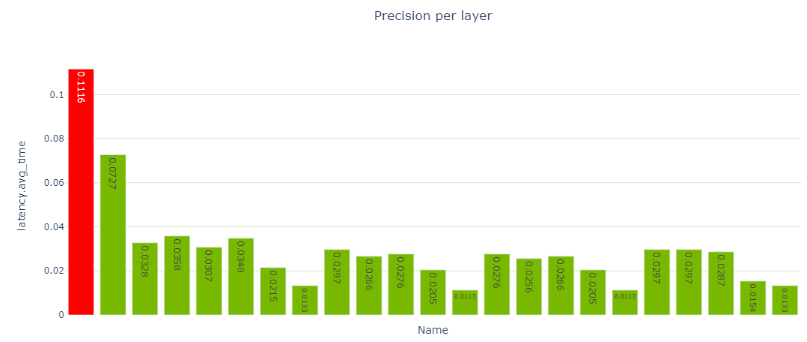
圖 8 :在剩余連接上添加 Q / DQ 并量化間隙層后的逐層精度視圖
現在您已經完成了優化,可以使用 發動機比較筆記本 來比較這兩個引擎。此筆記本不僅在您正在積極優化網絡性能時有用,而且在以下情況下也有用:
當您想要比較為不同的 GPU HW 平臺或不同的 TensorRT 版本構建的引擎時。
當您想要評估層的性能如何跨不同的批處理大小進行擴展時。
了解發動機之間的精度不一致是否是由于 TensorRT 層精度選擇不同所致。
發動機比較筆記本提供了表格和圖形視圖來比較發動機,這兩種視圖都適用,具體取決于您需要的詳細程度。圖 8 顯示了我們為 PyTorch ResNet18 模型構建的五個引擎的疊加延遲。為簡潔起見,我沒有討論創建 FP32 和 FP16 引擎,但這些引擎可以在 TREx GitHub 存儲庫中找到。
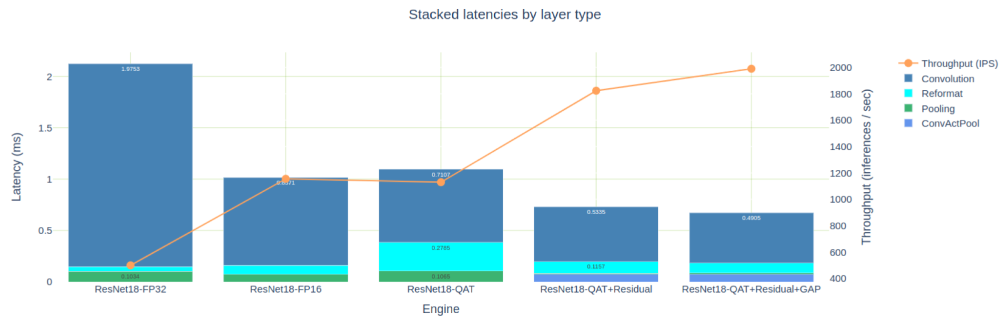
圖 9 :同一 ResNet18 網絡的五個引擎的疊加延遲
為 FP16 精度優化的引擎大約比 FP32 引擎快 2 倍,但也比我們首次嘗試的 INT8 QAT 引擎快。如前所述,這是由于許多 INT8 卷積輸出 FP16 數據,然后需要重新格式化層以顯式量化回 INT8 。
如果您只關注本文中優化的三個 QAT 引擎,那么您可以看到,在向剩余連接添加 Q / DQ 時,您是如何消除 11 個 FP16 引擎層的。量化間隙層時,消除了另外兩個 FP32 層。
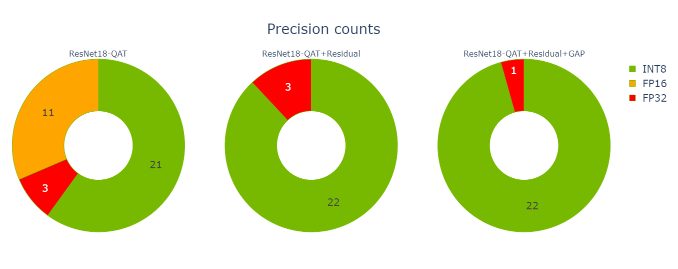
圖 10 :優化的三臺發動機的精度計數
您還可以查看優化如何影響三個引擎的延遲(圖 10 )。
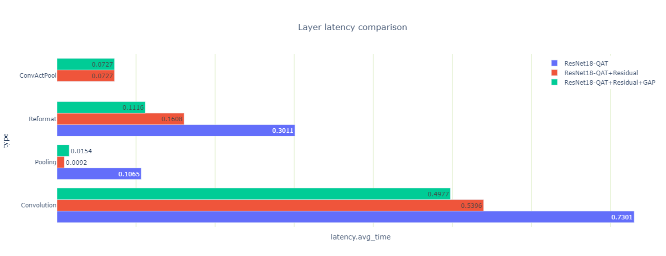
圖 11 :三個引擎的延遲,按層類型分組
您可能會注意到一些看起來很奇怪的池層延遲結果:當您量化剩余連接時,總池延遲下降了 10 倍,然后當您量化間隙層時,總池延遲上升了 70% 。
這兩個結果都是違反直覺的,所以請仔細觀察它們。有兩個池層,第一次卷積之后是一個大的池層,最后一次卷積之前是一個小的池層。量化剩余連接后,可以使用 INT8 精度的輸出執行第一個池和卷積層。它們與夾在中間的 ReLU 融合到 ConfactPool 層中,但浮點類型不支持這種融合。
為什么間隙層在量化時延遲增加?這個層的激活大小很小,每個 INT8 輸入系數都轉換為 FP32 ,以便使用高精度進行平均。最后,將結果轉換回 INT8 。
該層的數據大小也很小,并且駐留在快速二級緩存中,因此額外的精度轉換計算相對昂貴。盡管如此,因為您可以去掉圍繞間隙層的兩個重新格式化層,所以總的引擎延遲(這是您真正關心的)會減少。
總結
在這篇文章中,我介紹了 TensorRT 引擎瀏覽器,簡要回顧了它的 API 和特性,并通過一個示例演示了 TREx 如何幫助優化 TensorRT 引擎的性能。 TREx 可以在 TensorRT 的 GitHub 存儲庫中的 實驗工具 目錄下找到。
-
NVIDIA
+關注
關注
14文章
5039瀏覽量
103311 -
gpu
+關注
關注
28文章
4754瀏覽量
129101 -
深度學習
+關注
關注
73文章
5508瀏覽量
121317
發布評論請先 登錄
相關推薦
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

【AIBOX應用】通過 NVIDIA TensorRT 實現實時快速的語義分割

解鎖NVIDIA TensorRT-LLM的卓越性能
NVIDIA TensorRT-LLM Roadmap現已在GitHub上公開發布

使用NVIDIA TensorRT提升Llama 3.2性能
TensorRT-LLM低精度推理優化

NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

魔搭社區借助NVIDIA TensorRT-LLM提升LLM推理效率
MediaTek與NVIDIA TAO加速物聯網邊緣AI應用發展
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
利用NVIDIA組件提升GPU推理的吞吐
降本增效:NVIDIA路徑優化引擎創下多項世界紀錄!
NVIDIA路徑優化引擎創下23項世界紀錄
TensorRT LLM加速Gemma!NVIDIA與谷歌牽手,RTX助推AI聊天





 工商網監
工商網監
評論