 Transformer的出現讓專用AI芯片變得岌岌可危
Transformer的出現讓專用AI芯片變得岌岌可危
本文將分析CNN,還有近期比較火的SwinTransformer以及存內計算對AI芯片發展趨勢的影響,Transformer的出現讓專用AI芯片變得岌岌可危,命懸一線。 所謂AI芯片算力一般指INT8精度下每秒運作次數,INT8位即整數8比特精度。AI芯片嚴格地說應該叫AI加速器,只是加速深度神經網絡推理階段的加速,主要就是卷積的加速。一般用于視覺目標識別分類,輔助駕駛或無人駕駛還有很多種運算類型,需要用到多種運算資源,標量整數運算通常由CPU完成,矢量浮點運算通常由GPU完成,標量、矢量運算算力和AI算力同樣重要,三者是平起平坐的。AI算力遠不能和燃油車的馬力對標,兩者相差甚遠。 AI芯片的關鍵參數除了算力,還有芯片利用率或者叫模型利用率。AI芯片的算力只是峰值理論算力,實際算力與峰值算力之比就是芯片利用率。
圖片來源:互聯網
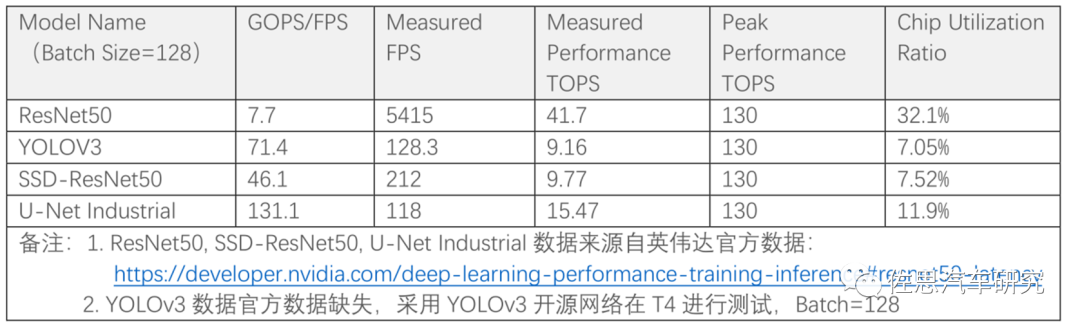
上表為英偉達旗艦人工智能加速器T4的芯片利用率,芯片的利用率很低,大部分情況下93%的算力都是閑置的,這好比一條生產線,93%的工人都無所事事,但工資還是要付的。實際上芯片利用率超過50%就是非常優秀,利用率低于10%是很常見的,極端情況只有1%,也就是說即使你用了4片英偉達頂級Orin,算力高達1000TOPS,實際算力可能只有10TOPS。 這也就是AI芯片主要的工作不是AI芯片本身,而是與之配套的軟件優化,當然也可以反過來,為自己的算法模型定制一塊AI芯片,如特斯拉。但應用面越窄,出貨量就越低,攤在每顆芯片上的成本就越高,這反過來推高芯片價格,高價格進一步縮窄了市場,因此獨立的AI芯片必須考慮盡可能適配多種算法模型。 這需要幾方面的工作:
首先主流的神經網絡模型自然要支持;
其次是壓縮模型的規模并優化,將浮點轉換為定點;
最后是提供編碼器Compiler,將模型映射為二進制指令序列。
早期的AI運算完全依賴GPU,以致于早期的神經網絡框架如Caffee、TensorFlow、mxnet都必須考慮在GPU上優化,簡單地說就是都得適應GPU的編碼器CUDA,這也是英偉達為何如此強的原因,它無需優化,因為早期的神經網絡就是為GPU訂做的。CUDA為英偉達筑起了高高的城墻,你要做AI運算,不兼容CUDA是不可能的,所有的程序員都已經用習慣了CUDA。但要兼容CUDA,CUDA的核心是不開源的,無論你如何優化,都不如英偉達的原生CUDA更優。車載領域好一點,可以效仿特斯拉。 卷積運算就是乘積累加,Cn=A×B+Cn-1,A是輸入矩陣,簡單理解就是一副圖像,用像素數字矩陣來表示一副圖像,B是權重模型,就是深度學習搜集訓練數據,經過幾千萬人民幣的數據中心訓練出的算法模型,也可以看做是一種特殊的濾波器,右邊的C是上一次乘積的結果。左邊的C就是本次計算的輸出結果。卷積運算后經過全連接層輸出,畫出Bounding Box并識別。用代碼表示如下。

圖片來源:互聯網
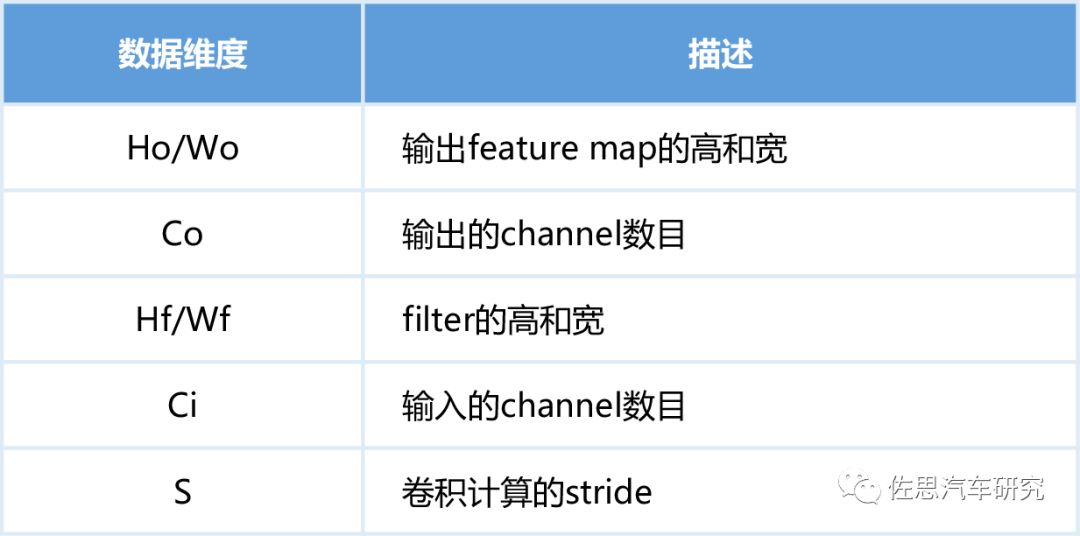
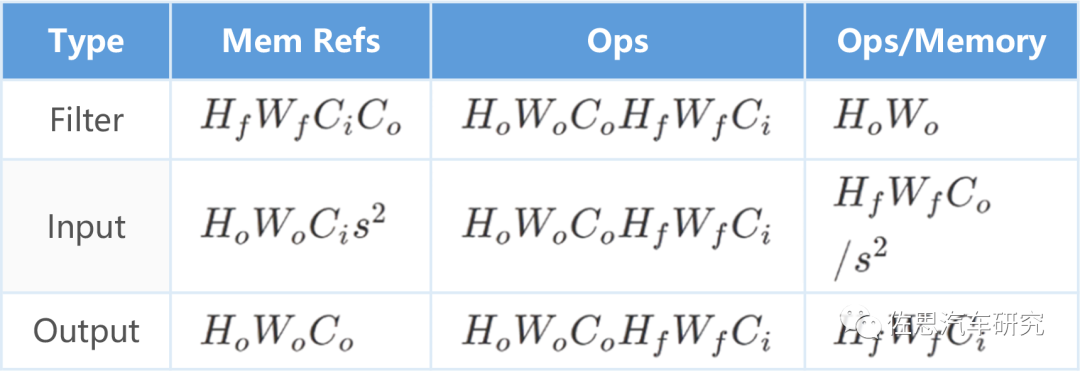
這些計算中有大量相同的數據存取,如下表。
圖片來源:互聯網
每一次運算都需要頻繁讀取內存,很多是重復讀取,這非常耗費時間和功率,顯然是一種浪費,AI芯片的核心工作就是提高數據的復用率。 AI芯片分為兩大流派,一是分塊矩陣的One Shot流派,也有稱之為GEMM通用矩陣乘法加速器,典型代表是英偉達、華為。二是如脈動陣列的數據流流派,典型代表是谷歌、特斯拉。還有些非主流的主要用于FPGA的Spatial,FFT快速傅里葉變換。
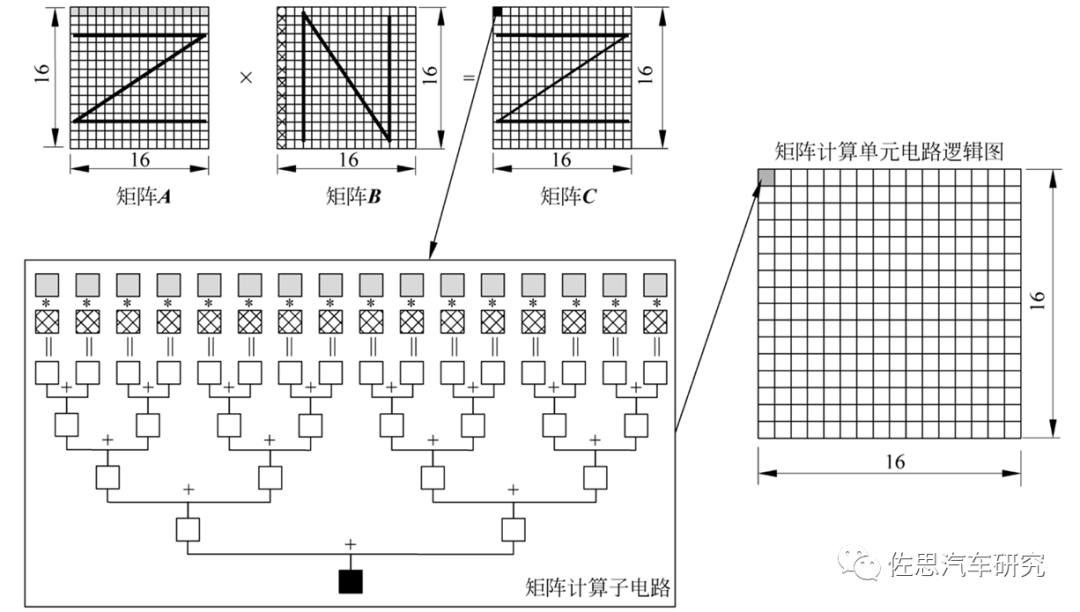
華為AI芯片電路邏輯
圖片來源:互聯網
以華為為例,其將矩陣A按行存放在輸入緩沖區中,同時將矩陣B按列存放在輸入緩沖區中,通過矩陣計算單元計算后得到的結果矩陣C按行存放在輸出緩沖區中。在矩陣相乘運算中,矩陣C的第一元素由矩陣A的第一行的16個元素和矩陣B的第一列的16個元素由矩陣計算單元子電路進行16次乘法和15次加法運算得出。矩陣計算單元中共有256個矩陣計算子電路,可以由一條指令并行完成矩陣C的256個元素計算。 由于矩陣計算單元的容量有限,往往不能一次存放下整個矩陣,所以也需要對矩陣進行分塊并采用分步計算的方式。將矩陣A和矩陣B都等分成同樣大小的塊,每一塊都可以是一個16×16的子矩陣,排不滿的地方可以通過補零實現。首先求C1結果子矩陣,需要分兩步計算:第一步將A1和B1搬移到矩陣計算單元中,并算出A1×B1的中間結果;第二步將A2和B2搬移到矩陣計算單元中,再次計算A2×B2 ,并把計算結果累加到上一次A1×B1的中間結果,這樣才完成結果子矩陣C1的計算,之后將C1寫入輸出緩沖區。由于輸出緩沖區容量也有限,所以需要盡快將C1子矩陣寫入內存中,便于留出空間接收下一個結果子矩陣C2。 分塊矩陣的好處是只計算了微內核,速度很快,比較靈活,編譯器好設計,增加算力也很簡單,只要增加MAC的數量即可。成本低,消耗的SRAM容量小。
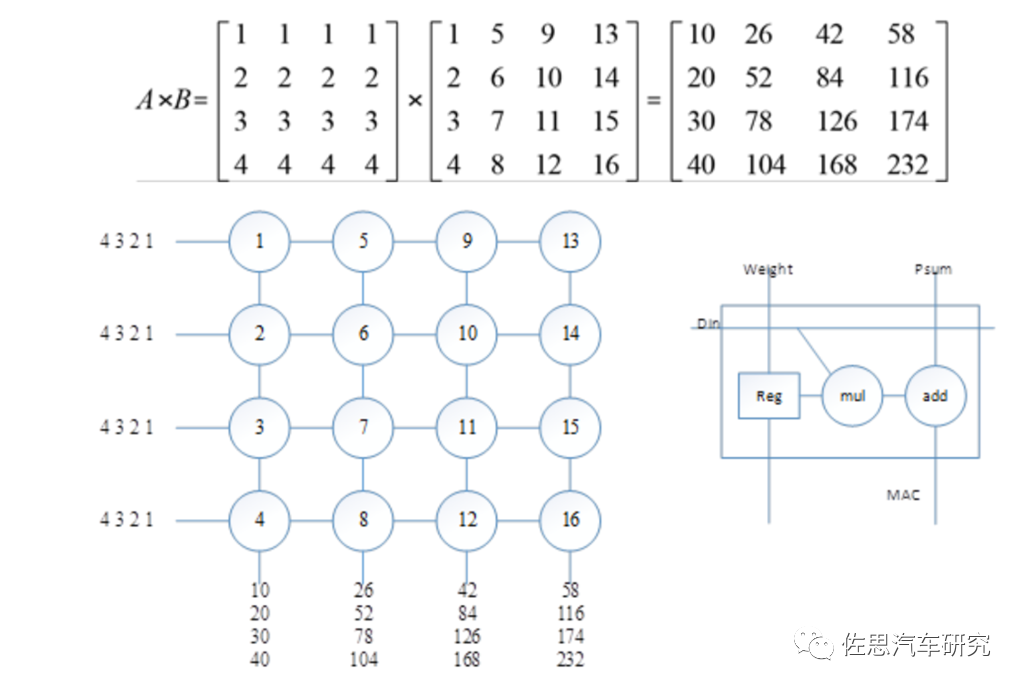
圖片來源:互聯網
上圖為一個典型的脈動陣列,右側是一個乘加單元即PE單元的內部結構,其內部有一個寄存器,在TPU內對應存儲Weight,此處存儲矩陣B。左圖是一個4×4的乘加陣列,假設矩陣B已經被加載到乘加陣列內部;顯然,乘加陣列中每一列計算四個數的乘法并將其加在一起,即得到矩陣乘法的一個輸出結果。依次輸入矩陣A的四行,可以得到矩陣乘法的結果。PE單元在特斯拉FSD中就是96*96個PE單元。
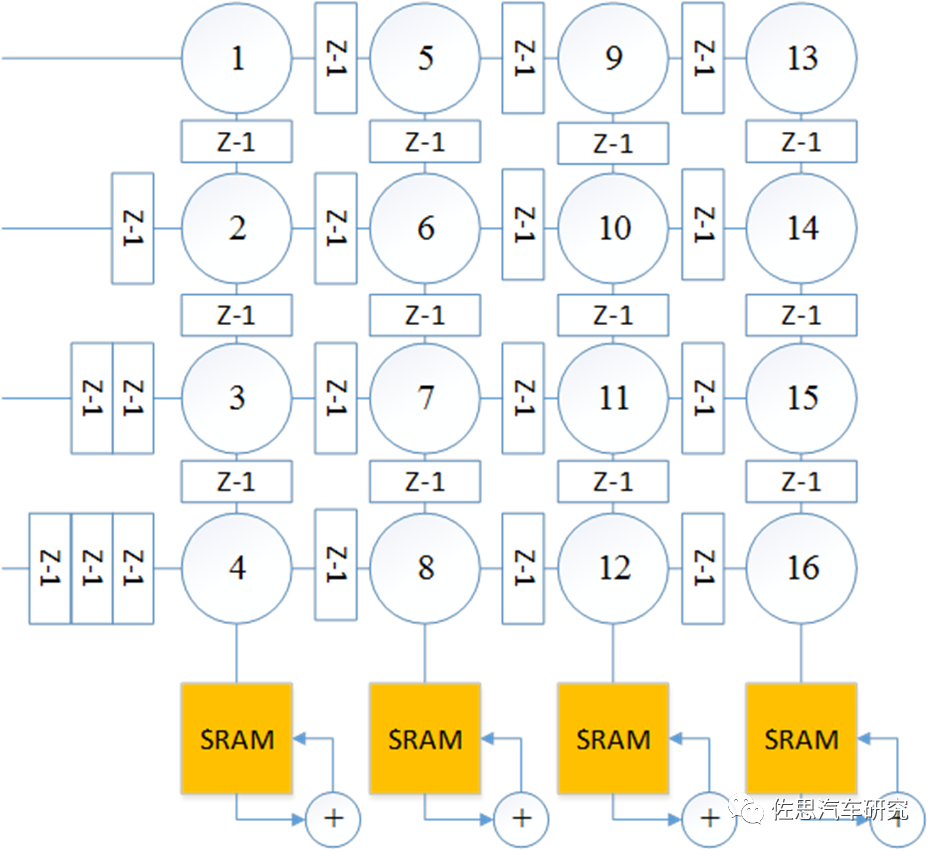
圖片來源:互聯網
不過最后還要添加累加器,需要多個SRAM加入。 脈動式優點是流水線式,不依賴一次一次的指令,一次指令即可啟動。吞吐量很高。算力做到1000TOPS易如反掌,單PE占硅片面積小。但是其編譯器難度高,靈活度低,要做到高算力,需要大量SRAM,這反過來推高成本。 在實際應用當中,情況會比較復雜,完整的深度學習模型都太大,而內存是很耗費成本的,因此,模型都必須要壓縮和優化,常見的壓縮有兩種,一種是Depthwise Convolution,還包括了Depthwise Separable Convolution。另一種是Pointwise Convolution。Depthwise層,只改變feature map的大小,不改變通道數。而Pointwise層則相反,只改變通道數,不改變大小。這樣將常規卷積的做法(改變大小和通道數)拆分成兩步走。
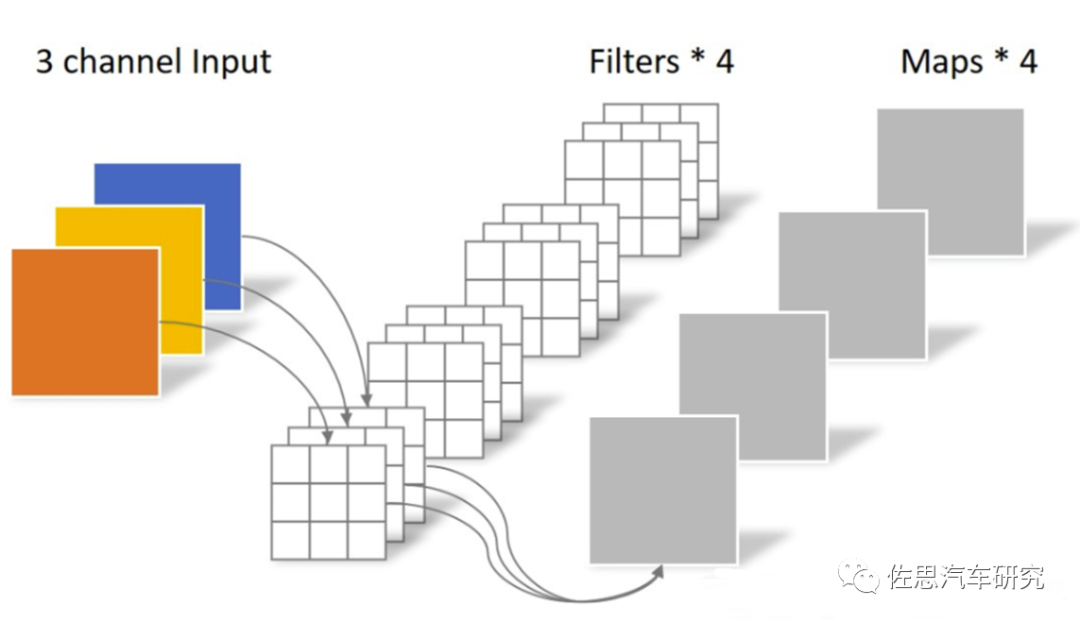
圖片來源:互聯網
常規卷積,4組(3,3,3)的卷積核進行卷積,等于108。
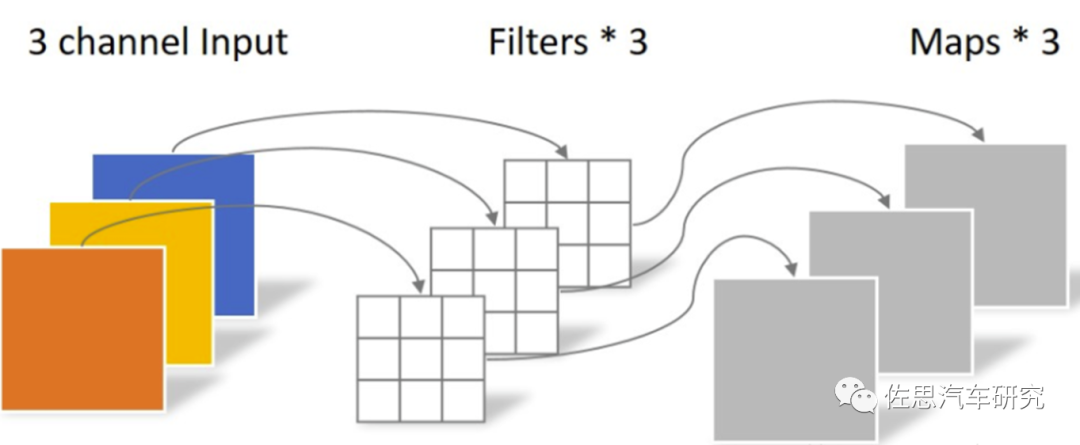
圖片來源:互聯網
Depthwise卷積,分成了兩步走,第一步是3*3*3,第二步是1*1*3*4,合計是39,壓縮了很多。 谷歌TPU v1的算力計算是700MHz*256*256*2=92Top/s@int8,之所以乘2是因為還有個加法累積。高通AI100的最大算力計算是16*8192*2*1600MHz=419Top/s@int8,高通是16核,每個核心是8192個陣列,最高運行頻率1.6GHz,最低估計是500MHz。
性能最大化對應的模型要求
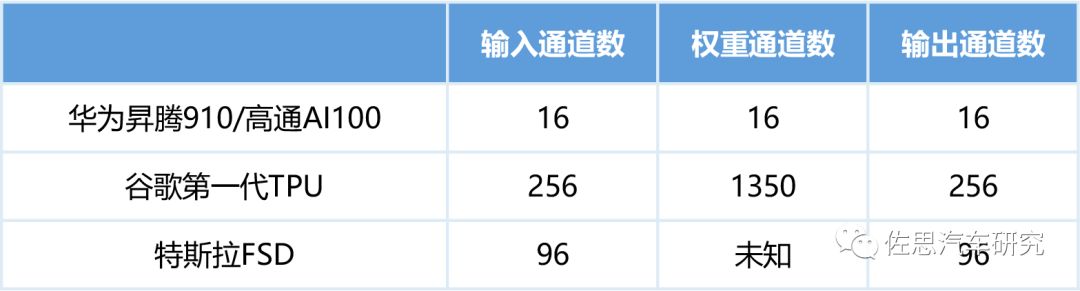
圖片來源:互聯網
對谷歌TPU v1來說,其最優性能是輸入為256,而不少Depthwise是3*3,其利用率為9/256,即3.5%。對高通AI100來說,如果算法模型輸入通道是256,那么效率會降低至16/256,即6.3%。顯然對于精簡算法模型,TPU非常不適合。對于精簡模型來說,高通AI100非常不適合。 以上這些都是針對CNN的,目前圖像領域的AI芯片也都是針對CNN的。近期大火的Swin Transformer則與之不同。2021年由微軟亞洲研究院開源的SwinTransformer的橫掃計算機視覺,從圖像分類的ViT,到目標檢測的DETR,再到圖像分割的SETR以及3D人體姿態的METRO,大有壓倒CNN的態勢。但其原生Self-Attention的計算復雜度問題一直沒有得到解決,Self-Attention需要對輸入的所有N個token計算N的二次方大小的相互關系矩陣,考慮到視覺信息本來就是二維(圖像)甚至三維(視頻),分辨率稍微高一點就會暴增運算量,目前所有視覺類AI芯片都完全無法勝任。
Swin Transformer的模型結構
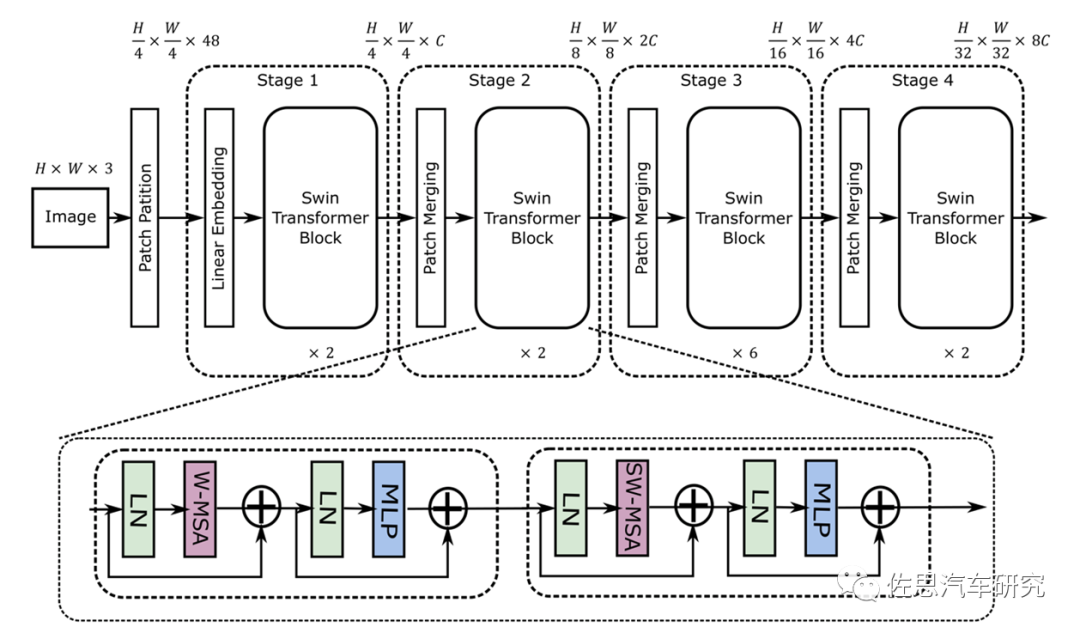
圖片來源:互聯網
從圖上就能看出其采用了4*4卷積矩陣,而CNN是3*3,這就意味著目前的AI芯片有至少33%的效率下降。再者就是其是矢量與矩陣的乘法,這會帶來一定的浮點矢量運算。 假設高和寬都為112,窗口大小為7,C為128,那么未優化的浮點計算是4*112*112*128*128+2*112*112*112*112*128=41GFLOP/s。大部分AI芯片如特斯拉的FSD和谷歌的TPU,未考慮這種浮點運算。不過華為和高通都考慮到了,英偉達就更不用說了,GPU天生就是針對浮點運算的。看起來41GFLOP/s不高,但如果沒有專用浮點運算處理器,效率也會急速下降。
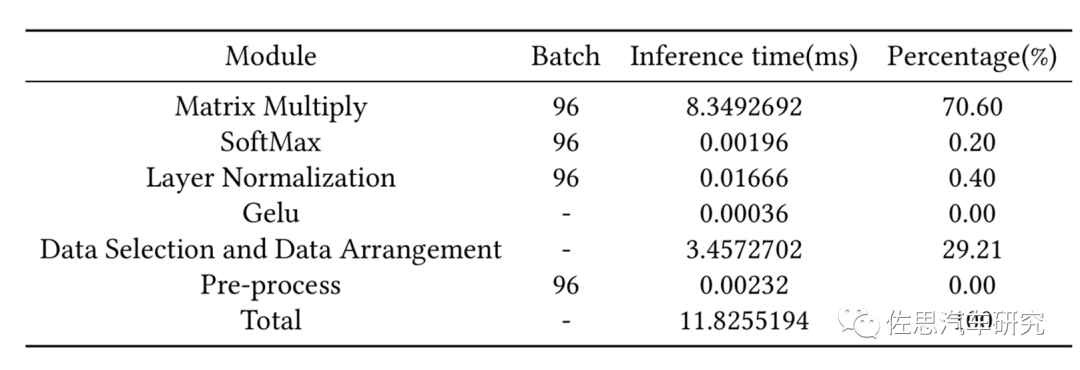
圖片來源:互聯網
與CNN不同,Swin Transformer的數據選擇與布置占了29%的時間,矩陣乘法占了71%,而CNN中,矩陣乘法至少占95%。
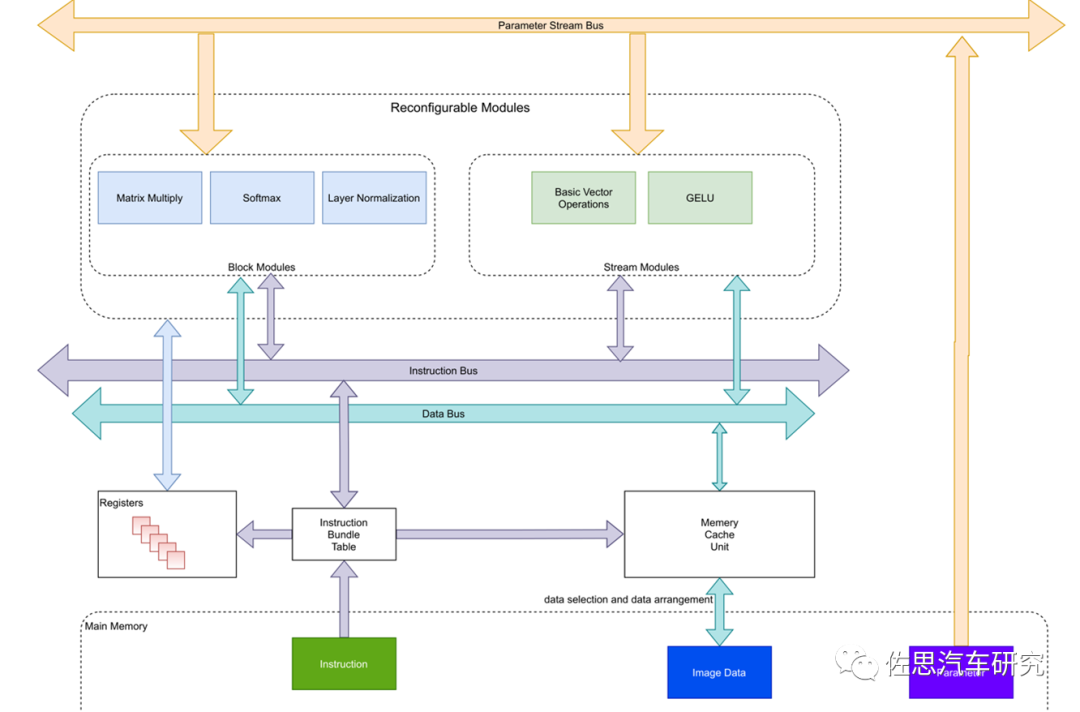
圖片來源:互聯網
針對Swin Transformer的AI芯片最好將區塊模型與數據流模型分開,指令集與數據集當然也最好分開。
圖片來源:互聯網
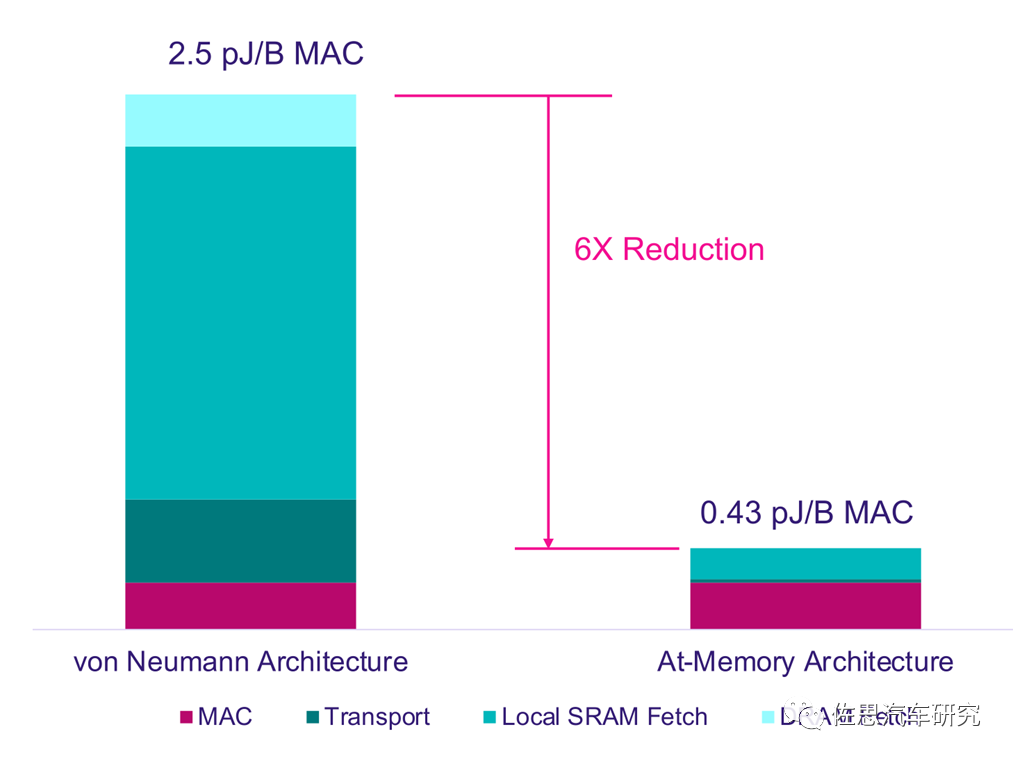
針對Swin Transformer,理論上最好的選擇是存內計算也叫存算一體,上圖是存內計算架構與傳統AI芯片的馮諾依曼架構的功耗對比,存內計算架構在同樣算力的情況下,只有馮諾依曼架構1/6的功耗。
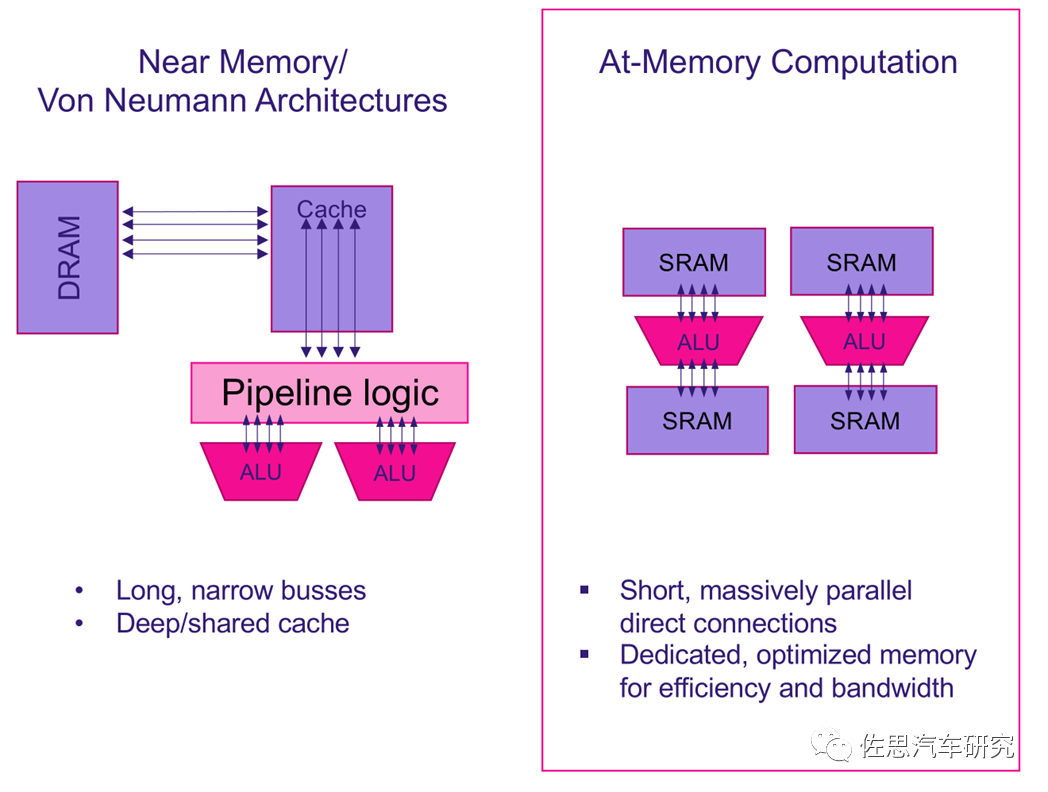
馮諾依曼架構與存內計算架構對比
圖片來源:互聯網
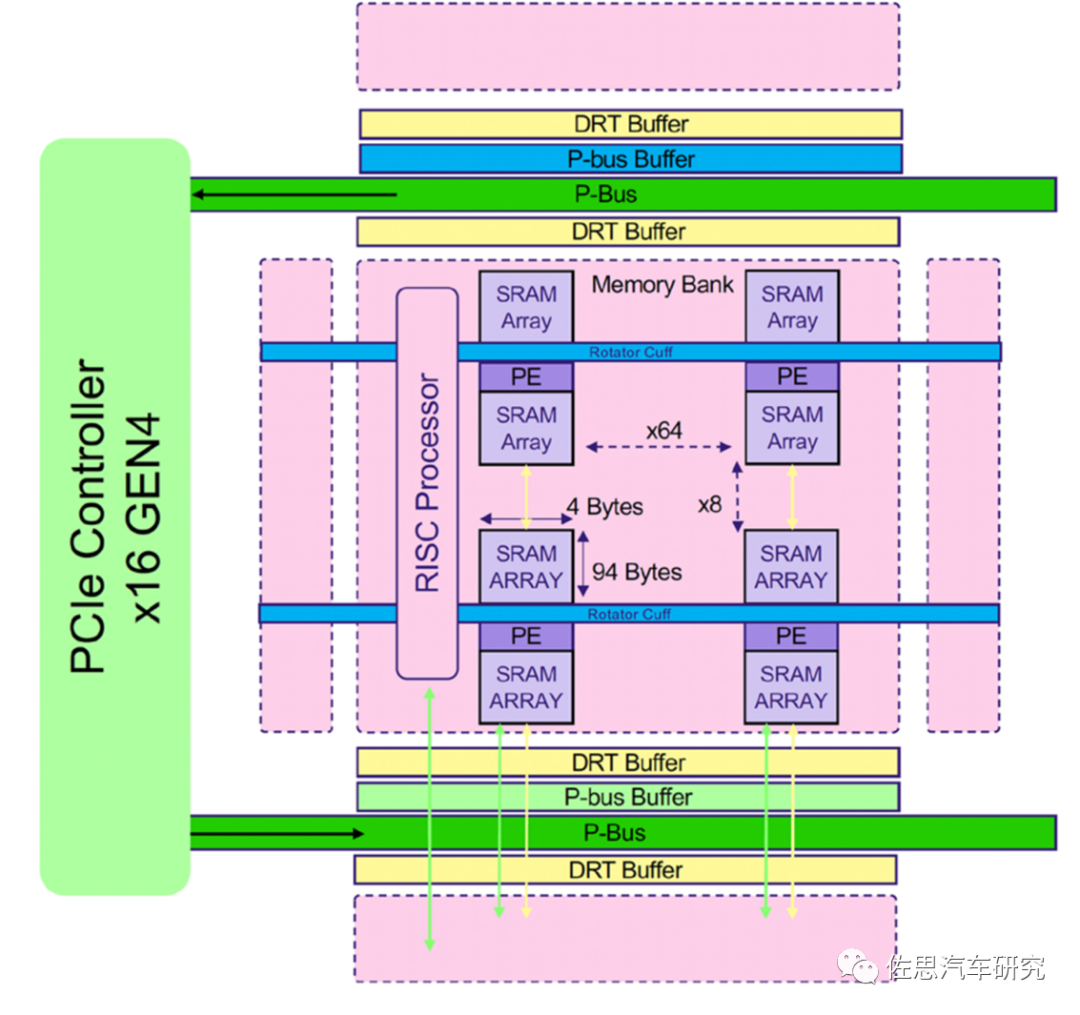
典型的存內計算架構芯片
圖片來源:互聯網
不過目前存內計算離實用距離還非常遙遠:
第一,內存行業由三星、美光和SK Hynix三家占了90%的市場,行業門檻極高,這三家極力保持內存價格穩定。
第二,目前AI模型都是越來越大,用存內計算存儲大容量AI模型成本極高。三星的存內計算芯片測試用的是二十年前的MNIST手寫字符識別,這種AI模型是kb級別的。而自動駕駛用的至少也是10MB以上。
第三,精度很低,當前存內計算研究的一個重點方法是使用電阻式RAM(ReRAM)實現位線電流檢測。由于電壓范圍,噪聲和PVT的變化,模擬位線電流檢測和ADC的精度受到限制,即使精度低到1比特也難以實現,而輔助駕駛目前是8比特。
第四,電阻式RAM可靠性不高。經常更新權重模型,可能導致故障。
最后,存內計算的工具鏈基本為零。最樂觀的估計,存內計算實用化也要5年以上,且是用在很小規模計算,如AIoT領域,自動駕駛領域十年內都不可能見到存內計算。即使存內計算實用化,恐怕也是內存三巨頭最有優勢。
Transformer的出現讓專用AI芯片變得非常危險,難保未來不出現別的技術,而適用面很窄的AI專用芯片會完全喪失市場,通用性比較強的CPU或GPU還是永葆青春,至于算力,與算法模型高度捆綁,但捆綁太緊,市場肯定很小,且生命周期可能很短。 聲明:本文僅代表作者個人觀點。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4777瀏覽量
100973 -
AI芯片
+關注
關注
17文章
1900瀏覽量
35134 -
算力
+關注
關注
1文章
1008瀏覽量
14886
原文標題:Transformer挑戰CNN,AI芯片需要改變
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
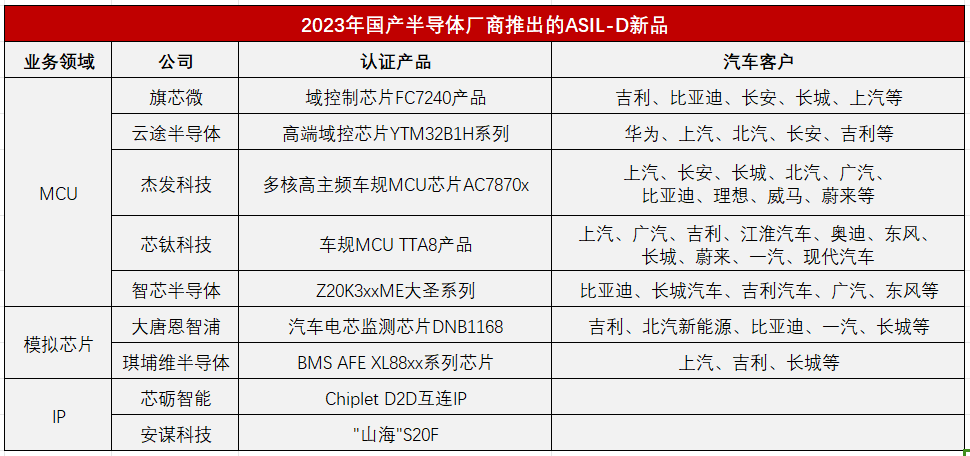
盤點2023年國產廠商推出ASIL-D芯片新品
危化品運輸車遠程監控智能管理平臺方案
transformer專用ASIC芯片Sohu說明

恒玄科技研發AI眼鏡專用芯片
TB1801線性車燈專用芯片可完美替代LAN1165E

AI芯片的混合精度計算與靈活可擴展
新思科技解讀是什么讓AI芯片設計與眾不同?
只能跑Transformer的AI芯片,卻號稱全球最快?
AI初創公司Etched獲1.2億美元A輪融資,加速專用AI芯片研發

risc-v多核芯片在AI方面的應用







 工商網監
工商網監
評論