") 如何將PP-OCRv3英文識別模型部署在Corstone-300虛擬硬件平臺上
如何將PP-OCRv3英文識別模型部署在Corstone-300虛擬硬件平臺上
項目概述
經(jīng)典的深度學(xué)習(xí)工程是從確認(rèn)任務(wù)目標(biāo)開始的,我們首先來簡單地介紹一下 OCR 中的文本識別任務(wù)以及本期部署實戰(zhàn)課程中我們所使用的工具和平臺。
1.1 文本識別任務(wù)
文本識別是 OCR 的一個子任務(wù),其任務(wù)為識別一個固定區(qū)域的文本內(nèi)容。在 OCR 的兩階段方法里,它接在文本檢測后面,將圖像信息轉(zhuǎn)換為文字信息。在卡證票據(jù)信息抽取與審核、制造業(yè)產(chǎn)品溯源、政務(wù)醫(yī)療文檔電子化等行業(yè)場景中應(yīng)用廣泛。

1.2 PP-OCRv3
如下圖所示,PP-OCRv3 的整體框架示意圖與 PP-OCRv2 類似,但較 PP-OCRv2 而言,針對檢測模型和識別模型進(jìn)行了進(jìn)一步地優(yōu)化。例如:文本識別模型在 PP-OCRv2 的基礎(chǔ)上引入 SVTR,并使用 GTC 指導(dǎo)訓(xùn)練和模型蒸餾。
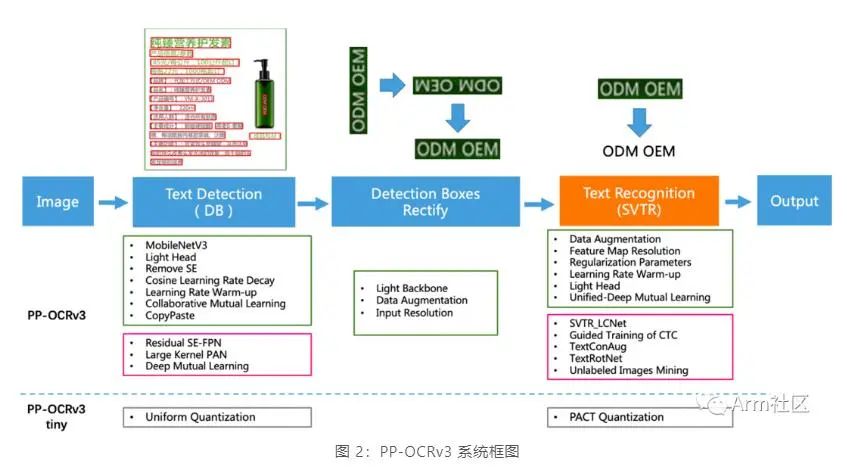
更多關(guān)于 PP-OCRv3 的特征及優(yōu)化策略,可查看 PP-OCRv3 arXiv 技術(shù)報告[5]。
1.3 Arm 虛擬硬件 (Arm Virtual Hardware, AVH)
作為 Arm 物聯(lián)網(wǎng)全面解決方案的核心技術(shù)之一,AVH 很好地解決了實體硬件所面臨的難擴(kuò)展、難運(yùn)維等痛點。AVH 提供了簡單便捷并且可擴(kuò)展的途徑,讓 IoT 應(yīng)用的開發(fā)擺脫了對實體硬件的依賴并使得云原生開發(fā)技術(shù)在嵌入式物聯(lián)網(wǎng)、邊緣側(cè)機(jī)器學(xué)習(xí)領(lǐng)域得到了應(yīng)用。尤其是在芯片緊張的當(dāng)今時代,使用 AVH 開發(fā)者甚至可以在芯片 RTL 之前便可接觸到最新的處理器 IP。
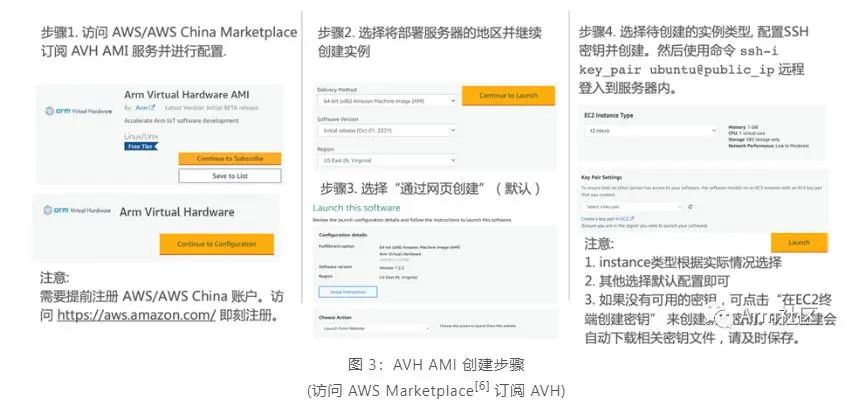
目前 AVH 提供兩種形式供開發(fā)者使用。一種是托管在 AWS 以及 AWS China 上以亞馬遜機(jī)器鏡像 AMI 形式存在的 Arm Corstone 和 Cortex CPU 的虛擬硬件,另外一種則是由 Arm 以 SaaS 平臺的形式提供的 AVH 第三方硬件。本期課程我們將使用第一種托管在 AWS 以及 AWS China 上以亞馬遜機(jī)器鏡像 AMI 形式存在的 Corstone 和 Cortex CPU 的虛擬硬件。
由于目前 AWS China 賬號主要面向企業(yè)級開發(fā)者開放,個人開發(fā)者可訪問 AWS Marketplace 訂閱 AVH 相關(guān)服務(wù)。參考下圖步驟創(chuàng)建 AVH AMI 實例。
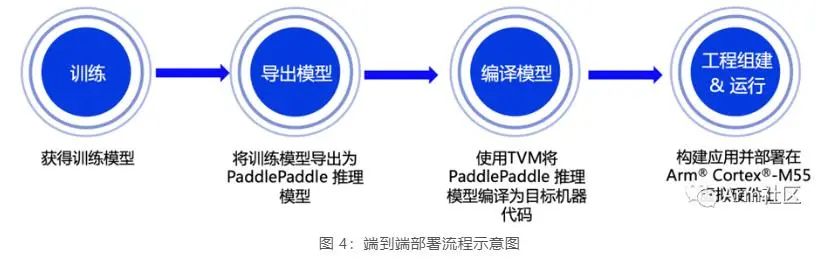
端到端部署流程
接下來小編將重點向大家展示從模型訓(xùn)練到部署的全流程,本期課程所涉及的相關(guān)代碼已在 GitHub 倉庫開源,歡迎大家下載體驗!
(位于 PaddleOCR 的 dygraph 分支下 deploy 目錄的 avh 文件目錄中)
https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph/deploy/avh
2.1 模型訓(xùn)練
PaddleOCR 模型使用配置文件 (.yml) 管理網(wǎng)絡(luò)訓(xùn)練、評估的參數(shù)。在配置文件中,可以設(shè)置組建模型、優(yōu)化器、損失函數(shù)、模型前后處理的參數(shù),PaddleOCR 從配置文件中讀取到這些參數(shù),進(jìn)而組建出完整的訓(xùn)練流程,完成模型訓(xùn)練。在需要對模型進(jìn)行優(yōu)化時,可以通過修改配置文件中的參數(shù)完成配置 (完整的配置文件說明可以參考文檔:配置文件內(nèi)容與生成[7]),使用簡單且便于修改。
為實現(xiàn)與 Cortex-M 的適配,在模型訓(xùn)練時我們需要修改所使用的配置文件[8]。去掉不支持的算子,同時為優(yōu)化模型,在模型調(diào)優(yōu)部分使用了 BDA (Base Data Augmentation),其包含隨機(jī)裁剪,隨機(jī)模糊,隨機(jī)噪聲,圖像反色等多個基礎(chǔ)數(shù)據(jù)增強(qiáng)方法。相關(guān)配置文件可參考如下代碼。
# Example: PP-OCRv3/en_PP-OCRv3_rec.yml Global: debug: false use_gpu: true epoch_num: 500 log_smooth_window: 20 print_batch_step: 10 save_model_dir: ./output/rec save_epoch_step: 3 eval_batch_step: [0, 2000] cal_metric_during_train: true pretrained_model: checkpoints: save_inference_dir: use_visualdl: false infer_img: doc/imgs_words/ch/word_1.jpg character_dict_path: ppocr/utils/en_dict.txt max_text_length: &max_text_length 25 infer_mode: false use_space_char: true distributed: true save_res_path: ./output/rec/predicts_ppocrv3_en.txt Optimizer: name: Adam beta1: 0.9 beta2: 0.999 lr: name: Cosine learning_rate: 0.001 warmup_epoch: 5 regularizer: name: L2 factor: 3.0e-05 Architecture: model_type: rec algorithm: SVTR Transform: Backbone: name: MobileNetV1Enhance scale: 0.5 last_conv_stride: [1, 2] last_pool_type: avg Neck: name: SequenceEncoder encoder_type: reshape Head: name: CTCHead mid_channels: 96 fc_decay: 0.00002 Loss: name: CTCLoss PostProcess: name: CTCLabelDecode Metric: name: RecMetric main_indicator: acc Train: dataset: name: LMDBDataset data_dir: MJ_ST ext_op_transform_idx: 1 transforms: - DecodeImage: img_mode: BGR channel_first: false - RecAug: - CTCLabelEncode: - RecResizeImg: image_shape: [3, 32, 320] - KeepKeys: keep_keys: - image - label - length loader: shuffle: true batch_size_per_card: 128 drop_last: true num_workers: 4 Eval: dataset: name: LMDBDataset data_dir: EN_eval transforms: - DecodeImage: img_mode: BGR channel_first: false - CTCLabelEncode: - RecResizeImg: image_shape: [3, 32, 320] - KeepKeys: keep_keys: - image - label - length loader: shuffle: false drop_last: false batch_size_per_card: 128 num_workers: 4
我們使用網(wǎng)上開源英文數(shù)據(jù)集 MJ+ST 作為訓(xùn)練測試數(shù)據(jù)集,并通過以下命令進(jìn)行模型訓(xùn)練。模型訓(xùn)練周期與訓(xùn)練環(huán)境以及數(shù)據(jù)集大小等均密切相關(guān),大家可根據(jù)自身需求進(jìn)行配置。
# Example training command python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global. save_model_dir=output/rec/ Train.dataset.name=LMDBDataSet Train.dataset.data_dir=MJ_ST Eval.dataset.name=LMDBDataSet Eval.dataset.data_dir=EN_eval
2.2 模型導(dǎo)出
模型訓(xùn)練完成后,還需要將訓(xùn)練好的文本識別模型轉(zhuǎn)換為 Paddle Inference 模型,才能使用深度學(xué)習(xí)編譯器 TVM 對其進(jìn)行編譯從而獲得適配在 Cortex-M 處理器上運(yùn)行的代碼。可以參考以下命令導(dǎo)出 Paddle Inference 模型。
# Example exporting model command python3 tools/export_model.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=output/rec/best_accuracy.pdparams Global.save_inference_dir=output/rec/infer
Inference 模型導(dǎo)出后,可以通過以下命令使用 PaddleOCR 進(jìn)行推理驗證。為便于各位開發(fā)者可直接體驗和部署,大家可以通過https://paddleocr.bj.bcebos.com/tvm/ocr_en.tar鏈接直接下載我們訓(xùn)練完成并導(dǎo)出的英文文本識別 Inference 模型。
# Example infer command python3 tools/infer/predict_rec.py --image_dir="path_to_image/word_116.png" --rec_model_dir="path_to_infer_model/ocr_en" --rec_char_dict_path="ppocr/utils/en_dict.txt" --rec_image_shape="3,32,320"
我們使用與后續(xù)部署中相同的圖進(jìn)行驗證,如下圖所示。預(yù)測結(jié)果為如下,與圖片一致且具有較高的置信度評分,說明我們的推理模型已經(jīng)基本準(zhǔn)備完畢了。
Predicts of /Users/lilwu01/Desktop/word_116.png:('QBHOUSE', 0.9867456555366516)

2.3 模型編譯
為實現(xiàn)在 Cortex-M 上直接完成 PaddlePaddle 模型的部署,我們需要借助深度學(xué)習(xí)編譯器 TVM 來進(jìn)行相應(yīng)模型的轉(zhuǎn)換和適配。TVM 是一款開源的深度學(xué)習(xí)編譯器, 主要用于解決將各種深度學(xué)習(xí)框架部署到各種硬件設(shè)備上的適配性問題。
如下圖所示,他可以接收由 PaddlePaddle 等經(jīng)典的深度學(xué)習(xí)訓(xùn)練框架編寫的模型并將其轉(zhuǎn)換成可在目標(biāo)設(shè)備上運(yùn)行推理任務(wù)的代碼。
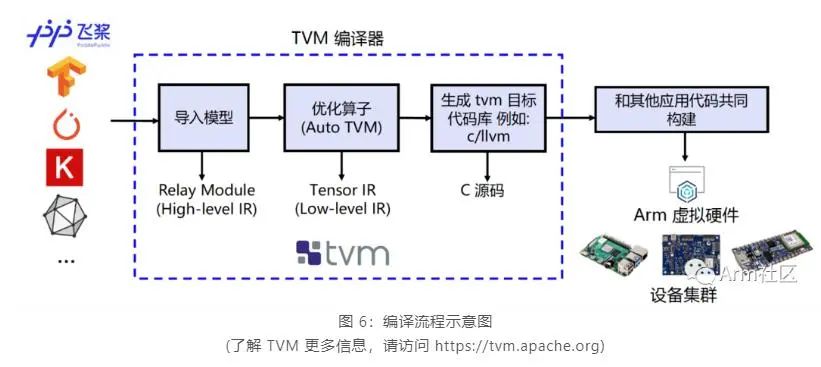
我們使用 TVM 的 Python 應(yīng)用程序 tvmc 來完成模型的編譯。大家可參考如下命令對 Paddle Inference 模型進(jìn)行編譯。通過指定 --target=cmsis-nn,c 使得模型中 CMSIS NN[9] 庫支持的算子會調(diào)用 CMSIS NN 庫執(zhí)行,而不支持的算子則會回調(diào)到 C 代碼庫。
# Example of Model compiling using tvmc python3 -m tvm.driver.tvmc compile path_to_infer_model/ocr_en/inference.pdmodel --target=cmsis-nn,c --target-cmsis-nn-mcpu=cortex-m55 --target-c-mcpu=cortex-m55 --runtime=crt --executor=aot --executor-aot-interface-api=c --executor-aot-unpacked-api=1 --pass-config tir.usmp.enable=1 --pass-config tir.usmp.algorithm=hill_climb --pass-config tir.disable_storage_rewrite=1 --pass-config tir.disable_vectorize=1 --output-format=mlf --model-format=paddle --module-name=rec --input-shapes x:[1,3,32,320] --output=rec.tar
更多關(guān)于參數(shù)配置的具體說明,大家可以直接輸入 tvmc compile --help 來查看。編譯后的模型可以在 –output 參數(shù)指定的路徑下查看 (此處為當(dāng)前目錄下的 rec.tar 壓縮包內(nèi))。
2.4 模型部署
參考圖 3 所示的 AVH AMI 實例 (instance) 創(chuàng)建的流程并通過 ssh 命令遠(yuǎn)程登錄到實例中去,當(dāng)看到如下所示的提示畫面說明已經(jīng)成功登入。


2.1-2.3 中所述的模型訓(xùn)練、導(dǎo)出、編譯等步驟均可以選擇在本地機(jī)器上完成或者在 AVH AMI 中完成,大家可根據(jù)個人需求確定。為便于開發(fā)者朋友更直觀地體驗如何在 AVH 上完成 PaddlePaddle 模型部署,我們?yōu)榇蠹姨峁┝瞬渴鸬氖纠a來幫助大家自動化的完成環(huán)境配置,機(jī)器學(xué)習(xí)應(yīng)用構(gòu)建以及在含有 Cortex-M55 的 Corstone-300 虛擬硬件上執(zhí)行并獲取結(jié)果。
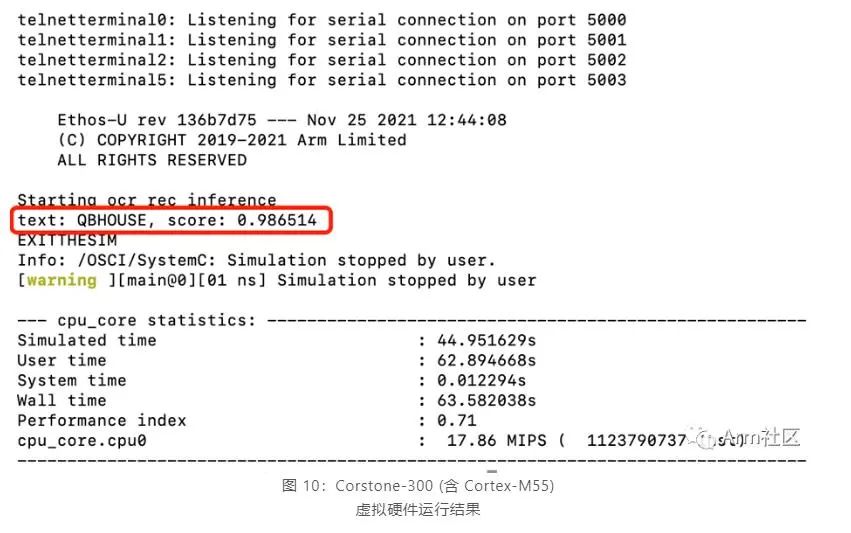
登入 AVH AMI 實例后,可以輸入以下命令來完成模型部署和查看應(yīng)用執(zhí)行結(jié)果。run_demo.sh[11] 腳本將會執(zhí)行以下 6 個步驟來自動化的完成應(yīng)用構(gòu)建和執(zhí)行,執(zhí)行結(jié)果如圖 10 所示。
$ git clone https://github.com/PaddlePaddle/PaddleOCR.git $ cd PaddleOCR $ git pull origin dygraph $ cd deploy/avh $ ./run_demo.sh

不難看出,該飛槳英文識別模型在含有 Cortex-M55 處理器的 Corstone-300 虛擬硬件上的推理結(jié)果與 2.2 章節(jié)中在服務(wù)器主機(jī)上直接進(jìn)行推理的推理結(jié)果高度一致,說明將 PaddlePaddle 模型直接部署在 Cortex-M55 虛擬硬件上運(yùn)行良好。
總結(jié)
本期課程,小編帶領(lǐng)大家學(xué)習(xí)了如何將 PP-OCRv3 中發(fā)布的英文識別模型 (完成算子適配后) 部署在 Corstone-300 的虛擬硬件平臺上。在下期推送中,我們將以計算機(jī)視覺領(lǐng)域的目標(biāo)檢測任務(wù) (Detection) 為目標(biāo),一步步地帶領(lǐng)大家動手完成從模型訓(xùn)練優(yōu)化到深度學(xué)習(xí)應(yīng)用部署的整個端到端的開發(fā)流程。
-
開源
+關(guān)注
關(guān)注
3文章
3398瀏覽量
42646 -
硬件平臺
+關(guān)注
關(guān)注
0文章
21瀏覽量
11947 -
識別模型
+關(guān)注
關(guān)注
0文章
5瀏覽量
6755
原文標(biāo)題:AVH 動手實踐 (二) | 在 Arm 虛擬硬件上部署 PP-OCR 模型
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論