") FS-NER 的關(guān)鍵挑戰(zhàn)
FS-NER 的關(guān)鍵挑戰(zhàn)
小樣本 NER 需要從很少的實(shí)例和外部資源中獲取有效信息。本文提出了一個(gè)自描述機(jī)制,可以通過使用全局概念集(universal concept set)描述實(shí)體類型(types)和提及(mentions)來有效利用實(shí)例和外部資源的知識。
具體來講,我們設(shè)計(jì)了自描述網(wǎng)絡(luò)(SDNet),一個(gè) Seq2Seq 的生成模型可以使用概念來全局地描述提及,自動(dòng)將新的實(shí)體類型映射到概念中,然后對實(shí)體進(jìn)行識別。SDNet 在一個(gè)大規(guī)模語料中預(yù)訓(xùn)練,在 8 個(gè) benchmarks 上進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果表明,SDNet 取得了很有競爭力的效果,并且在 6 個(gè) benchmarks 上達(dá)到了 SOTA。
Intro
小樣本 NER(FS-NER)的目標(biāo)是通過很少的樣本來識別出屬于新實(shí)體類的實(shí)體提及。FS-NER 面臨兩個(gè)主要的挑戰(zhàn):
1. limited information challenge:少量樣本所包含的語義信息有限。
2. knowledge mismatch challenge:使用外部的知識直接與新任務(wù)進(jìn)行匹配可能有各種偏差甚至產(chǎn)生沖突。
具體來說,在 Wikipedia,OntoNotes 和 WNUT17 中,“America” 的標(biāo)注分別為 “geographic entity”、“GPE” 和 “l(fā)ocation”。因此,如何有效利用少量數(shù)據(jù)并且準(zhǔn)確遷移外部知識是 FS-NER 的關(guān)鍵挑戰(zhàn)。
為此,作者提出了自描述機(jī)制,其主要思想是將所有的實(shí)體類型描述為同一個(gè)概念集,類型和概念之間的映射是可以建模和學(xué)習(xí)的,這種方式可以解決知識不匹配的問題。同時(shí),因?yàn)檫@種映射是全局的,對于少量新實(shí)體類樣本來說,只需要將這部分?jǐn)?shù)據(jù)用來構(gòu)建新實(shí)體類型和概念之間的映射,也解決了信息不足的問題。
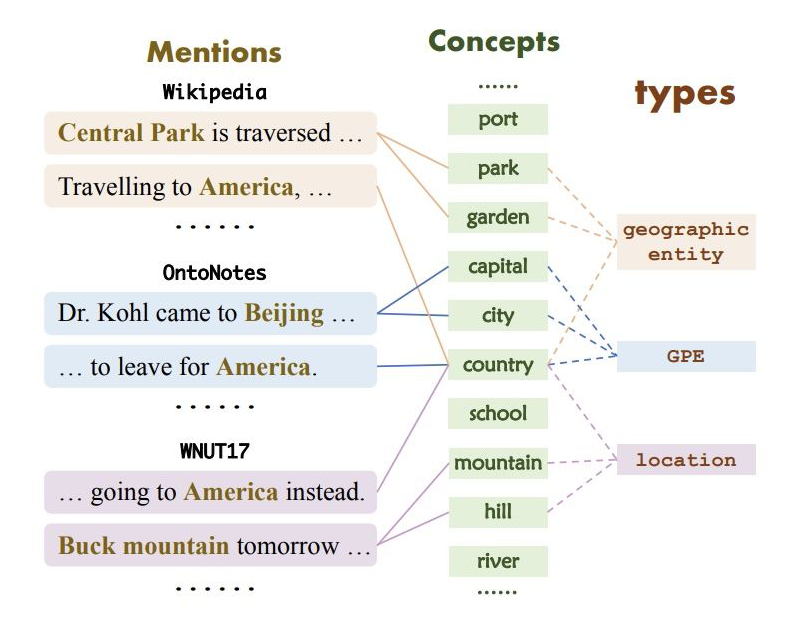
▲ 實(shí)體類型、提及和概念映射示例
基于以上想法,我們提出了一個(gè)自描述網(wǎng)絡(luò)——SDNet,是一個(gè) Seq2Seq 的生成模型,可以全局的使用概念來描述提及,自動(dòng)將新實(shí)體類型映射到概念集,并且能夠識別實(shí)體。
具體來講,為了獲取一個(gè)提及的語義,SDNet 生成一個(gè)全局的概念集作為描述。例如:生成 {capital,city} 對于句子“Dr。Kohl came to [Beijing].”。為了映射實(shí)體類型和概念,SDNet 將屬于同一實(shí)體類型的提及映射到這些提及所對應(yīng)的概念中。例如:對于 [Beijing] 和 [America] 兩個(gè)屬于 GPE 類型的提及,將 GPE 這一類型映射到 {country,capital,city}。
對于實(shí)體識別,SDNet 使用 concept-enriched 的前綴 prompt 的方式直接在一個(gè)句子中生成出所有的實(shí)體。例如:在 “France is beautiful.” 這句話中通過生成出 “France is GPE.” 來識別實(shí)體,構(gòu)建一個(gè)前綴 prompt“[EG] GPE:{country,capital,city}”。因?yàn)楦拍钍侨值模晕覀兛梢栽?SDNet上使用大規(guī)模語料庫預(yù)訓(xùn)練,并且可以很容易的使用 web 資源,具體來說,我們通過使用 wikipedia 錨詞到 wikidata items 之間的連接構(gòu)建了包含 56M 個(gè)句子,31K 個(gè)概念的數(shù)據(jù)集。
本文的主要貢獻(xiàn)總結(jié)如下:
1. 我們提出了自描述機(jī)制來解決 FS-NER 問題,可以有效解決信息限制和知識不匹配的挑戰(zhàn)通過使用一個(gè)全局的概念集描述實(shí)體類型和提及;
2. 我們提出 SDNet,一個(gè)可以全局的使用概念描述提及,自動(dòng)映射新實(shí)體類型和概念并且識別實(shí)體的 Seq2Seq 生成模型;
3. 我們在一個(gè)大規(guī)模的公開數(shù)據(jù)集上預(yù)訓(xùn)練 SDNet,對 FS-NER 提供了全局信息并且對未來 NER 的研究有益。
Method
模型整體流程包含兩部分:
1. Mention describing:生成提及的概念描述;
2. Entity generation:生成屬于新實(shí)體類的提及。
模型結(jié)構(gòu)圖如下:
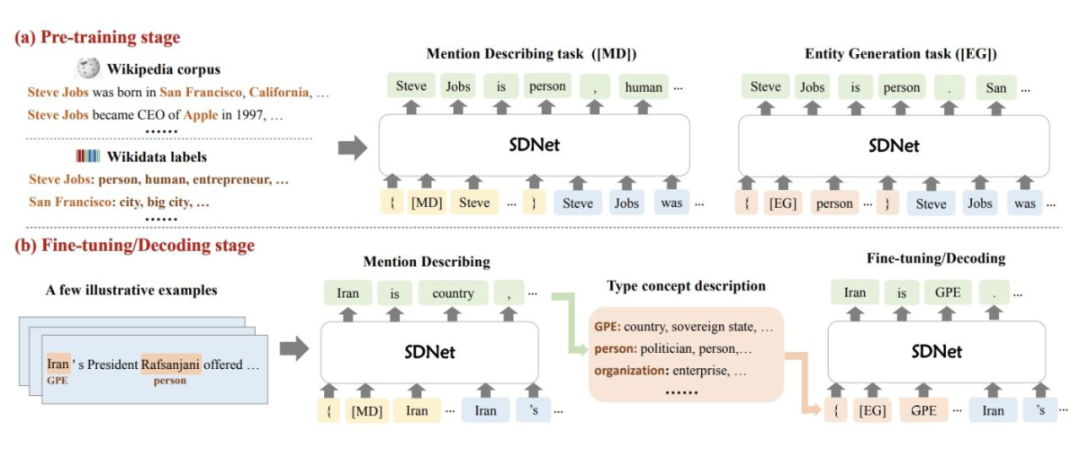
▲ 模型結(jié)構(gòu)
2.1 Self-describing Networks
SDNet 可以完成兩個(gè)生成任務(wù),就是上文提到的 mention describing 和 entity generation,分別使用了不同的提示 P 并且生成不同的輸出 Y。具體形式如下圖所示:
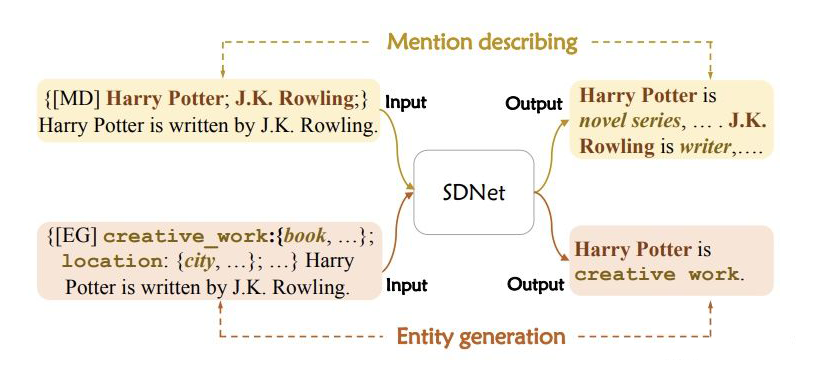
▲mention describing和entity generation示例
對于 mention describing,提示模板由一個(gè)標(biāo)識 [MD] 和一個(gè)目標(biāo)實(shí)體提及組成;對于 entity generation,提示模板由標(biāo)識 [EG] 和一個(gè)新實(shí)體類型和其對應(yīng)的描述組成。上述兩個(gè)過程是一組對稱的過程:一個(gè)是給定實(shí)體提及,獲取其概念描述;另一個(gè)是識別包含特定概念的實(shí)體。
2.2 Entity Recognition via Entity Generation
具體來講,entity generation 的輸入提示為
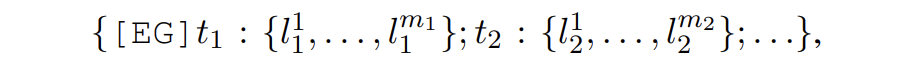
其中 t 是實(shí)體類型,l 是實(shí)體類型對應(yīng)的概念。SDNet 會(huì)生成如下形式的輸出:
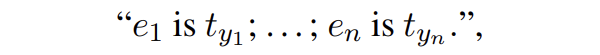
這里就相當(dāng)于獲取了每個(gè)實(shí)體對應(yīng)的實(shí)體類型:
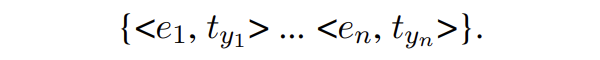
可以看出,SDNet 可以實(shí)時(shí)進(jìn)行控制,通過使用不同的 prompts。例如:給一個(gè)句子 “Harry Potter is written by J.K. Rowling.”,如果想要識別 person 類,提示模板采用 {[EG] person: {actor, writer}},如果想要識別 creative work 類,則模板采用 {[EG] creative work: {book, music}} 即可。
2.3 Type Description Construction via Mention Describing
Mention Describing
給定一個(gè)句子 X,包含新類的實(shí)體提及{e1, e2, ...},使用的提示模板為:
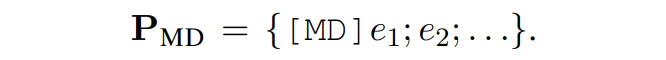
SDNet 會(huì)產(chǎn)生如下形式的輸出:
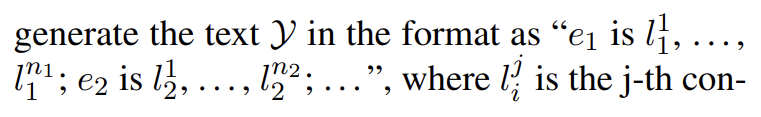
這一步會(huì)生成每個(gè)實(shí)體提及的概念。
Type Description Construction
SDNet 會(huì)將屬于同一實(shí)體類型的提及生成的概念,融合成一個(gè)概念集合 C,將這個(gè)概念集合 C 作為類型 t 的描述。
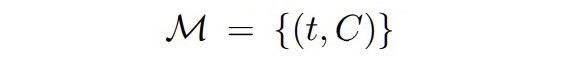
Filtering Strategy
由于下游任務(wù)含有大量新的實(shí)體類型,SDNet 對于其中某些類型沒有足夠的知識來描述,如果強(qiáng)制進(jìn)行生成會(huì)導(dǎo)致一些不準(zhǔn)確的描述。本文提出一個(gè)過濾策略解決這個(gè)問題。具體來講,SDNet 會(huì)對那些不確定的樣本生成 other 這一描述。我們會(huì)計(jì)算生成 other 描述的概率,如果對于一個(gè)樣本生成的 other 超過 0.5,則會(huì)去除掉類型描述,在 P_EG 模板中直接使用類型。
Learning
接下來說明 SDNet 如何進(jìn)行預(yù)訓(xùn)練和微調(diào)。
3.1 SDNet Pre-training
本文使用 wikipedia 和 wikidata 數(shù)據(jù)來構(gòu)建數(shù)據(jù)集。
Entity Mention Collection
對于 SDNet 的預(yù)訓(xùn)練,我們需要收集
1. 首先,從 wikidata 中構(gòu)建實(shí)體字典。我們將 wikidata 中每個(gè) item 作為實(shí)體并且使用 “instance of”、“subclass of” 和 “occupation” 三個(gè)屬性值作為其對應(yīng)的實(shí)體類型。我們使用所有的實(shí)體類型,除去那些實(shí)例少于 5 個(gè)的。對于那些類型名長度超過 3 個(gè) token 的,采用其 head word 作為最終的實(shí)體類型來簡化。通過這種方式,我們收集了 31K 個(gè)類型;
2. 其次我們使用其在 wikipedia 中的錨文本和其條目頁面的前 3 個(gè)頻繁出現(xiàn)的名詞短語來收集每個(gè)實(shí)體的提及。然后對于每一個(gè)提及,通過將其連接到 wikidata 中 item 的類型來識別實(shí)體類型。如果 wikidata 的 item 沒有實(shí)體類型,則給其分配 other。對于每一個(gè)百科頁,將文本分割成句子,并且將沒有實(shí)體的句子過濾掉。最終我們構(gòu)建出了含有 56M 個(gè)實(shí)例的數(shù)據(jù)集。
Type Description Building
文本將上述獲取的實(shí)體類型作為概念,對于給定的一個(gè)實(shí)體類型,使用與其共同出現(xiàn)的實(shí)體類型作為其描述。舉例來說,Person 類可以描述為 {businessman, CEO, musician, pianist} 通過以下兩個(gè)實(shí)例 “Steve Jobs:{person, businessman, CEO}” 和 “Beethoven:{person, musician, pianist}”。通過這種方式生成每個(gè)實(shí)體類型的描述概念集。因?yàn)橛行╊愋偷母拍罴貏e大,因此本文為每個(gè)實(shí)體隨機(jī)采樣不超過 10 個(gè)概念作為概念集合。
Pretraining via Mention Describing and Entity Generation
給定一個(gè)句子 X 以及它的提及-類型元組:
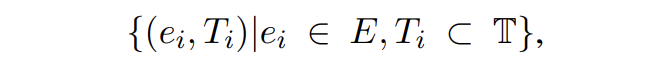
我們從 E 中采樣一些目標(biāo)提及 E' 輸入到模板 P_MD 中生成它的對應(yīng)概念。對于實(shí)體生成,從正類型和負(fù)類型中采樣類型集輸入到模板 P_EG 中生成提及對應(yīng)的實(shí)體類型。模型損失如下:
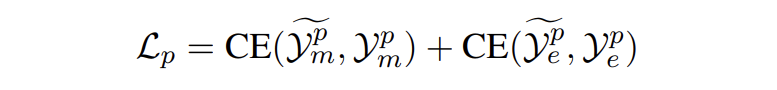
▲ 交叉熵?fù)p失
3.2 Entity Recognition Fine-tuning
微調(diào)階段給定一個(gè)樣本三元組
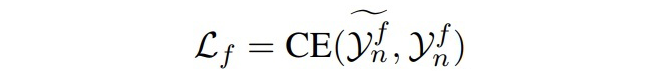
▲EG過程的損失
Experiments
4.1 主實(shí)驗(yàn)
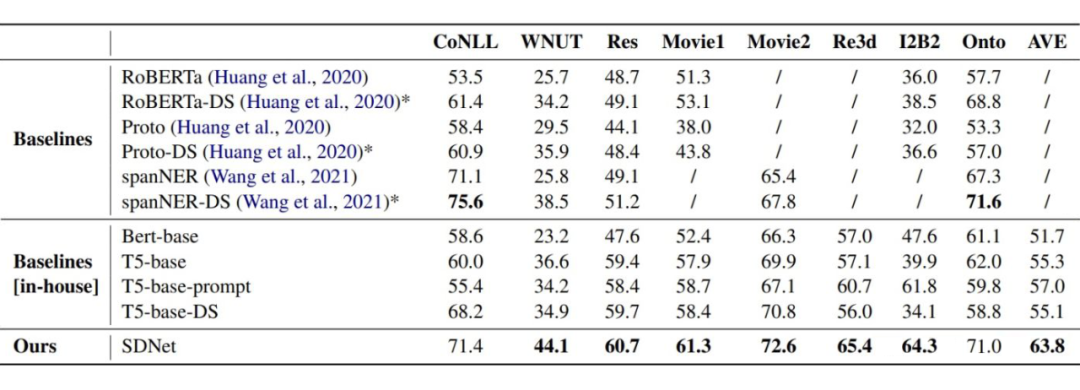
▲ 主實(shí)驗(yàn),評價(jià)指標(biāo)采用 micro-F1
實(shí)驗(yàn)結(jié)果可以看出,在 6 個(gè) benchmark 中 SDNet 達(dá)到了 SOTA。作者也分析了在 Res 這一 benchmark 上與 T5 表現(xiàn)接近的原因,因?yàn)?Res 與 wikipedia 數(shù)據(jù)有巨大的領(lǐng)域漂移,導(dǎo)致模型經(jīng)常生成 other。
4.2 樣本數(shù)的影響
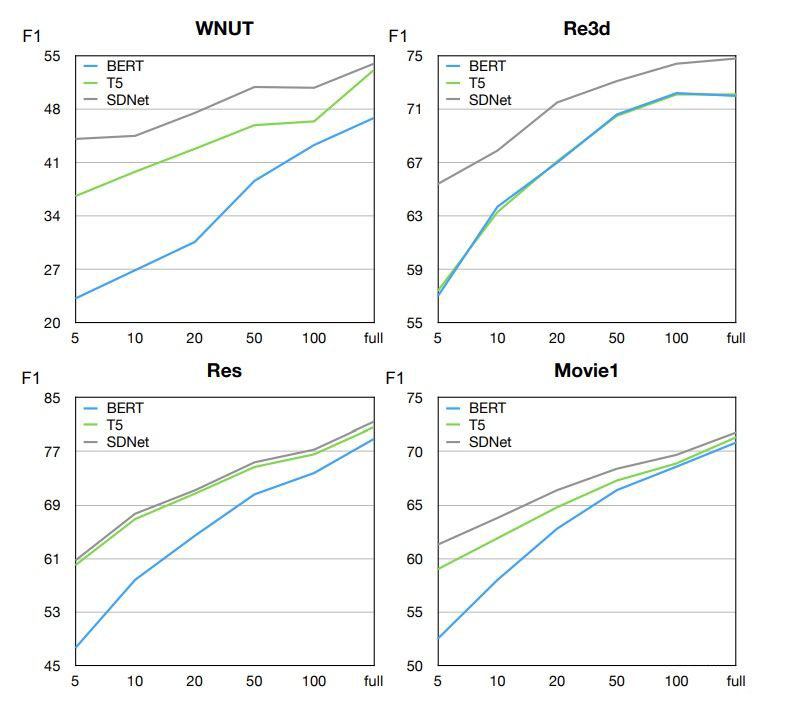
▲ 樣本數(shù)的影響
實(shí)驗(yàn)結(jié)果可以看出,SDNet 在任何樣本數(shù)設(shè)置下都有更好的表現(xiàn)。作者認(rèn)為,基于生成的模型要比基于分類的模型有更好的表現(xiàn),因?yàn)樯赡P涂梢岳?a target="_blank">標(biāo)簽的 utterance 更有效的獲取實(shí)體類型的語義。
4.3 消融實(shí)驗(yàn)
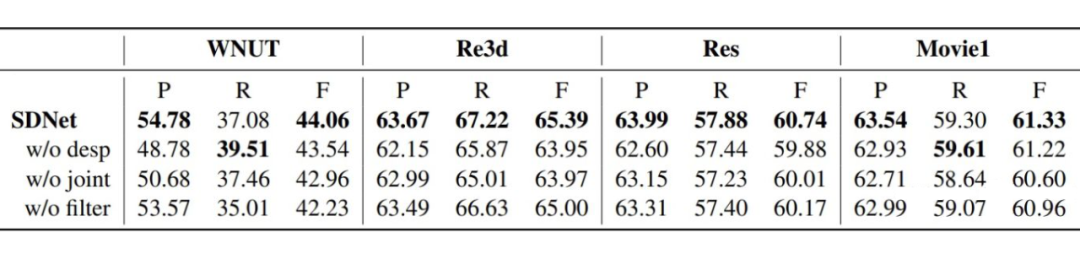
(1)w/o desp:在EG過程直接使用實(shí)體類型,而不加入全局的概念描述,例如:
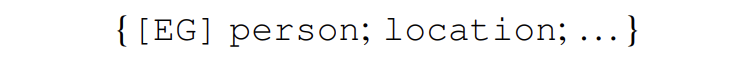
(2)w/o joint:將 MD 和 EG 過程分為兩個(gè)單獨(dú)的過程分開訓(xùn)練。
(3)w/o filter:不進(jìn)行過濾策略。
4.4 零樣本實(shí)驗(yàn)
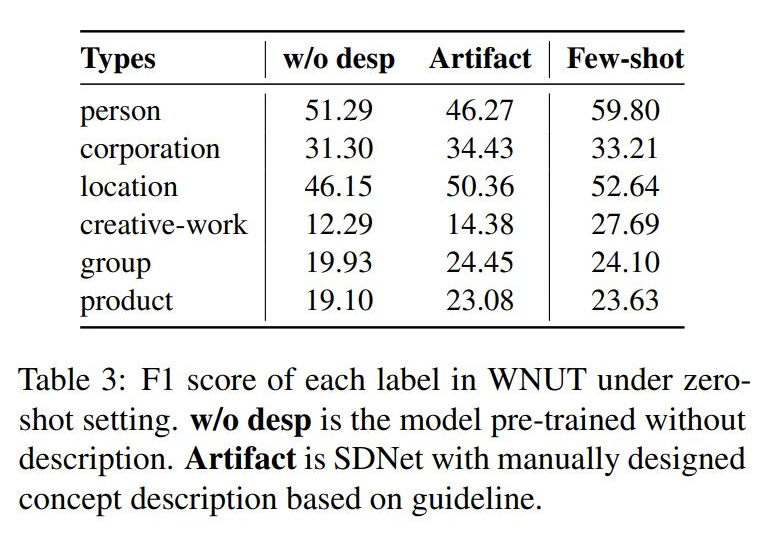
4.4 EG模板的影響

總結(jié)
本文一大優(yōu)點(diǎn)是為 FS-NER 引用外部知識提供了一個(gè)新的思路,本文的預(yù)訓(xùn)練模型也可以直接做遷移。
不足之處在于在與 Wikipedia 之間存在巨大的領(lǐng)域漂移的情況下,模型會(huì)生成大量 other 從而嚴(yán)重影響效果。在維基百科中可能存在大量人名地名等常見實(shí)體,而在一些實(shí)際問題中,可能存在很多不常見的實(shí)體,模型可能很難對這些實(shí)體做到很好的描述。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7073瀏覽量
89147 -
模型
+關(guān)注
關(guān)注
1文章
3255瀏覽量
48902
原文標(biāo)題:ACL2022 | 自描述網(wǎng)絡(luò)的小樣本命名實(shí)體識別
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
下一代超快I-V測試系統(tǒng)關(guān)鍵的技術(shù)挑戰(zhàn)有哪些?
功耗成為HPC和Networking的關(guān)鍵設(shè)計(jì)挑戰(zhàn)
光學(xué)傳感器的系統(tǒng)NER模擬

一些NER的英文數(shù)據(jù)集推薦
一種單獨(dú)適配于NER的數(shù)據(jù)增強(qiáng)方法
如何解決NER覆蓋和不連續(xù)問題
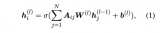
怎么構(gòu)建命名實(shí)體識別(NER)任務(wù)的標(biāo)注數(shù)據(jù)
基于填表方式的NER方法
介紹兩個(gè)few-shot NER中的challenge
Few-shot NER的三階段
如何簡單粗暴的提升NER效果?
EMI電磁干擾:挑戰(zhàn)與機(jī)遇并存,如何應(yīng)對是關(guān)鍵

EMI電磁干擾行業(yè):行業(yè)發(fā)展的關(guān)鍵與挑戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論