 使用NVIDIA Flare 2.1測試新型分布式應用程序
使用NVIDIA Flare 2.1測試新型分布式應用程序
NVIDIA FLARE ( NVIDIA Federated Learning Application Runtime Environment , NVIDIA 聯邦學習應用程序運行時環境)是一個用于協作計算的開源 Python SDK 。 FLARE 設計有一個組件化體系結構,允許研究人員和數據科學家將機器學習、深度學習或一般計算工作流調整為聯合范式,以實現安全、隱私保護的多方協作。
此體系結構提供了用于安全地配置聯合、建立安全通信以及定義和編排分布式計算工作流的組件。 FLARE 在一個可擴展的 API 中提供了這些組件,該 API 允許定制以適應現有的工作流或輕松試驗新的分布式應用程序。

圖 1 :高級 NVIDIA FLARE 體系結構
圖 1 顯示了具有基礎 API 組件的高級 FLARE 體系結構,包括用于保護隱私和安全管理平臺的工具。在此基礎之上是聯邦學習應用程序的構建塊,以及一組聯邦工作流和學習算法。
除了核心 FLARE 堆棧之外,還有一些工具,這些工具允許使用 FL Sim ulator 進行實驗和概念驗證( POC )開發,以及一組用于部署和管理生產工作流的工具。
在這篇文章中,我將重點介紹如何開始使用簡單的 POC ,并概述從 POC 過渡到安全的生產部署的過程。我還強調了從本地 POC 遷移到分布式部署時的一些注意事項。
NVIDIA FLARE 入門
為了幫助您開始使用 NVIDIA FLARE ,我將介紹該平臺的基本知識,并重點介紹版本 2.1 中的一些功能,這些功能可以幫助您將概念驗證引入生產聯合學習工作流。
安裝
開始使用 NVIDIA FLARE 的最簡單方法是在 Quickstart 中所述的 Python 虛擬環境中。
只需幾個簡單的命令,就可以準備一個 FLARE 工作區,該工作區支持獨立服務器和客戶端的本地部署。此本地部署可用于運行 FLARE 應用程序,就像它們在安全的分布式部署上運行一樣,無需配置和部署開銷。
$ sudo apt update $ sudo apt install python3-venv $ python3 -m venv nvflare-env $ source nvflare-env/bin/activate (nvflare-env) $ python3 -m pip install -U pip setuptools (nvflare-env) $ python3 -m pip install nvflare
準備 POC 工作區
安裝了 nvflare pip 包后,您現在可以訪問 poc 命令。執行此命令時所需的唯一參數是所需的客戶端數。
(nvflare-env) $ poc -h usage: poc [-h] [-n NUM_CLIENTS] optional arguments: -h, --help show this help message and exit -n NUM_CLIENTS, --num_clients NUM_CLIENTS number of client folders to create
執行此命令后,例如,對于兩個客戶端執行poc -n 2,您將擁有一個 POC 工作區,其中包含每個參與者的文件夾:管理客戶端、服務器和站點客戶端。
(nvflare-env) $ tree -d poc poc ├── admin │ └── startup ├── server │ └── startup ├── site-1 │ └── startup └── site-2 └── startup
每個文件夾都包含啟動和連接聯合所需的配置和腳本。默認情況下,服務器配置為在本地主機上運行,站點客戶端和管理客戶端分別在端口 8002 和 8003 上連接。您可以在后臺運行服務器和客戶端,例如:
(nvflare-env) $ for i in poc/{server,site-1,site-2}; do \ ./$i/startup/start.sh; \
done
服務器和客戶端進程將狀態消息發送到標準輸出,并記錄到它們自己的poc/{server,site-?}/log.txt文件。如前所示啟動時,此標準輸出是交錯的。您可以在單獨的終端中啟動每個端口,以防止這種交叉輸出。
部署 FLARE 應用程序
連接服務器和站點客戶端后,可以使用管理客戶端管理整個聯合。在深入管理客戶端之前,請從 NVIDIA FLARE GitHub 存儲庫中設置一個示例。
(nvflare-env) $ git clone https://github.com/NVIDIA/NVFlare.git (nvflare-env) $ mkdir -p poc/admin/transfer (nvflare-env) $ cp -r NVFlare/examples/hello-pt-tb poc/admin/transfer/
這會將Hello PyTorch with Tensorboard Streaming示例復制到管理客戶端的傳輸目錄中,將其暫存以部署到服務器和站點客戶端。有關更多信息,請參閱快速啟動( PyTorch with TensorBoard).
在部署之前,還需要安裝一些必備組件。
(nvflare-env) $ python3 -m pip install torch torchvision tensorboard
現在您已經準備好了應用程序,可以啟動管理客戶端了。
(nvflare-env) $ ./poc/admin/startup/fl_admin.sh Waiting for token from successful login... Got primary SP localhost:8002:8003 from overseer. Host: localhost Admin_port: 8003 SSID: ebc6125d-0a 56-4688-9b08-355fe9e4d61a login_result: OK token: d50b9006-ec21-11ec-bc73-ad74be5b77a4 Type ? to list commands; type "? cmdName" to show usage of a command. >
連接后,管理客戶端可用于檢查服務器和客戶端的狀態、管理應用程序和提交作業。
對于本例,提交hello-pt-tb應用程序以執行。
> submit_job hello-pt-tb Submitted job: 303ffa9c-54ae-4ed6-bfe3-2712bc5eba40
此時,您將看到作業提交確認和作業 ID ,以及服務器和客戶端終端上的狀態更新,這些更新顯示了執行培訓時服務器控制器和客戶端執行器的進度。
您可以使用list_jobs命令檢查作業的狀態。作業完成后,使用download_job命令從服務器下載作業結果。
> download_job 303ffa9c-54ae-4ed6-bfe3-2712bc5eba40 Download to dir poc/admin/startup/../transfer
然后,可以使用下載的作業目錄作為 TensorBoard 日志目錄來啟動 TensorBoard 。
(nvflare-env) $ tensorboard \ --logdir=poc/admin/transfer
這將使用從客戶端流到服務器并保存在服務器運行目錄中的日志啟動本地 TensorBoard 服務器。您可以打開 http://localhost:6006 的瀏覽器以可視化運行。
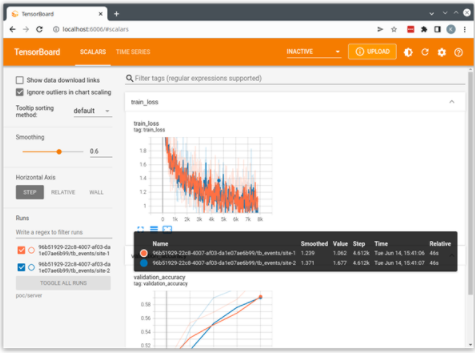
圖 2 :來自的張力板輸出示例 hello-pt-tb application
NVIDIA FLARE 提供的 example applications 均設計為使用此 POC 模式,可以作為開發自定義應用程序的起點。
一些示例,如 CIFAR10 example ,定義了端到端工作流,突出顯示 NVIDIA FLARE 中可用的不同功能和算法,并使用 POC 模式,以及下一節討論的安全資源調配。
從概念驗證轉移到生產
NVIDIA FLARE v2.1 引入了一些新的概念和功能,旨在實現強健的生產聯合學習,其中最明顯的兩個是高可用性和對多作業執行的支持。
高可用性( HA ) 支持多個 FL 服務器,并在當前活動服務器不可用時自動激活備份服務器。這由聯合體中的一個新實體監管者管理,監管者負責監控所有參與者的狀態,并在需要時協調到備份服務器的切換。
Multi-job execution 通過允許并發運行,支持基于資源的多作業執行,前提是滿足作業所需的資源。
具有高可用性的安全部署
上一節介紹了 FLARE 的 POC 模式,其中禁用了安全功能以簡化本地測試和實驗。
為了演示生產部署的高可用性,請再次從 POC 模式中使用的單一系統部署開始,并在 OpenProvision API 中引入 provisioning 的概念。
Sim NVIDIA FLARE 提供了provision命令來驅動 OpenProvision API 。provision命令讀取項目。配置安全部署中使用的參與者和組件的 yml 文件。此命令可以在沒有參數的情況下使用,以創建 sample project.yml 的副本作為起點。
對于這篇文章,繼續使用與上一節中配置的相同的nvflare-venv Python 虛擬環境。
(nvflare-env) $ provision No project.yml found in current folder. Is it OK to generate one for you? (y/N) y project.yml was created. Please edit it to fit your FL configuration.
為了安全部署,必須首先配置聯合體中的參與者。您可以修改示例文件project.yml的participants部分,以創建一個簡單的本地部署,如下所示。來自默認項目的更改。 yml 文件以粗體文本顯示。
participants: # change overseer.example.com to the FQDN of the overseer - name: overseer type: overseer org: nvidia protocol: https api_root: /api/v1 port: 8443 # change example.com to the FQDN of the server - name: server1 type: server org: nvidia fed_learn_port: 8002 admin_port: 8003 # enable_byoc loads python codes in app. Default is false. enable_byoc: true components: <<: *svr_comps - name: server2 type: server org: nvidia fed_learn_port: 9002 admin_port: 9003 # enable_byoc loads python codes in app. Default is false. enable_byoc: true components: <<: *svr_comps - name: site-1 type: client org: nvidia enable_byoc: true components: <<: *cln_comps - name: site-2 type: client org: nvidia enable_byoc: true components: <<: *cln_comps # You can also override one component with a different one resource_manager: # This id is reserved by system. Do not change it. path: nvflare.app_common.resource_managers.list_resource_manager.ListResourceManager args: resources: gpu: [0, 1] - name: admin@nvidia.com type: admin org: nvidia roles: - super
定義參與者有幾個要點:
-
每個參與者的名稱必須唯一。就監管者和服務器而言,所有服務器和客戶端都必須能夠解析這些名稱,可以是完全限定的域名,也可以是使用
/etc/hosts的主機名(后面會有更多介紹)。 - 對于本地部署,服務器必須為 FL 和 admin 使用唯一的端口。如果服務器在單獨的系統上運行,則分布式部署不需要此功能。
-
參與者應將
enable_byoc: true設置為允許在/custom文件夾中部署帶有代碼的應用程序,如示例應用程序中所示。
project.yml文件的其余部分配置了定義 FLARE 工作區的builder modules。現在可以將這些保留在默認配置中,但在從安全的本地部署轉移到真正的分布式部署時需要考慮一些問題。
修改后的項目。 yml ,您現在可以為參與者提供安全的啟動工具包。
(nvflare-env) $ provision -p project.yml Project yaml file: project.yml. Generated results can be found under workspace/example_project/prod_00. Builder's wip folder removed. $ tree -d workspace/ workspace/ └── example_project ├── prod_00 │ ├── admin@nvidia.com │ │ └── startup │ ├── overseer │ │ └── startup │ ├── server1 │ │ └── startup │ ├── server2 │ │ └── startup │ ├── site-1 │ │ └── startup │ └── site-2 │ └── startup ├── resources └── state
與 POC 模式一樣,資源調配會生成一個工作區,其中包含每個參與者的啟動工具包以及每個參與者的 zip 文件。 zip 文件可用于在分布式部署中輕松分發啟動工具包。每個工具包都包含 POC 模式下的配置和啟動腳本,并添加了一組共享證書,用于在參與者之間建立身份和安全通信。
在安全資源調配中,對這些啟動工具包進行簽名以確保它們未被修改。查看 server1 的啟動工具包,您可以看到這些附加組件。
(nvflare-env) $ tree workspace/example_project/prod_00/server1 workspace/example_project/prod_00/server1 └── startup ├── authorization.json ├── fed_server.json ├── log.config ├── readme.txt ├── rootCA.pem ├── server.crt ├── server.key ├── server.pfx ├── signature.json ├── start.sh ├── stop_fl.sh └── sub_start.sh
要連接參與者,所有服務器和客戶端必須能夠解析project.yml中定義的名稱處的服務器和監管者。對于分布式部署,這可能是一個完全限定的域名。
您還可以在每個服務器和客戶端系統上使用/etc/hosts將服務器和監管者名稱映射到其 IP 地址。對于此本地部署,請使用/etc/hosts重載環回接口。例如,以下代碼示例為監督者和兩個服務器添加了條目:
(nvflare-env) $ cat /etc/hosts 127.0.0.1 localhost 127.0.0.1 overseer 127.0.0.1 server1 127.0.0.1 server2
因為監管者和服務器都使用唯一的端口,所以您可以在本地 127.0.0.1 界面上安全地運行所有端口。
與上一節一樣,您可以循環訪問參與者集,以執行啟動工具包中包含的start.sh腳本,以連接監管者、服務器和站點客戶端。
(nvflare-env) $ export WORKSPACE=workspace/example_project/prod_00/
(nvflare-env) $ for i in $WORKSPACE/{overseer,server1,server2,site-1,site-2}; do \ ./$i/startup/start.sh & \
done
從這里開始,使用管理客戶端部署應用程序的過程與在 POC 模式下相同,但有一個重要的更改。在安全資源調配中,管理客戶端會提示輸入用戶名。在此示例中,用戶名為admin@nvidia.com,如project.yml中所配置。
安全、分布式部署的注意事項
在前面的部分中,我討論了 POC 模式和在單個系統上的安全部署。這種單一系統部署消除了真正安全的分布式部署的許多復雜性。在單個系統上,您可以享受共享環境、共享文件系統和本地網絡的好處。分布式系統上的生產 FLARE 工作流必須解決這些問題。
一致的環境
聯盟中的每個參與者都需要 NVIDIA FLARE 運行時,以及服務器和客戶端工作流中實現的任何依賴項。這很容易在具有 Python 虛擬環境的本地部署中實現。
當運行分布式時,環境不容易約束。解決這個問題的一種方法是在容器中運行。對于前面的示例,您可以創建一個簡單的 Dockerfile 來捕獲依賴項。
ARG PYTORCH_IMAGE=nvcr.io/nvidia/pytorch:22.04-py3
FROM ${PYTORCH_IMAGE} RUN python3 -m pip install -U pip
RUN python3 -m pip install -U setuptools
RUN python3 -m pip install torch torchvision tensorboard nvflare WORKDIR /workspace/
RUN git clone https://github.com/NVIDIA/NVFlare.git
sample project.yml文件中引用的 WorkspaceBuilder 包含一個用于定義 Docker 映像的變量:
# when docker_image is set to a Docker image name, # docker.sh is generated on server/client/admin docker_image: nvflare-pyt:latest
當在 WorkspaceBuilder 配置中定義了docker_image時,設置會在每個啟動工具包中生成一個docker.sh腳本。
假設此示例 Dockerfile 已在標記為 n vflare-pyt:latest的每個服務器、客戶端和管理系統上構建,則可以使用docker.sh腳本啟動容器。這將啟動容器,其中映射了啟動工具包并準備運行。當然,這需要 Docker 以及服務器和客戶端主機系統上的適當權限和網絡配置。
另一種選擇是提供要求。 txt 文件,如許多聯機示例所示,可以在運行分布式啟動工具包之前將其安裝在nvflare-venv虛擬環境中。
分布式系統
在到目前為止討論的 POC 和安全部署環境中,我們假設了一個單一的系統,您可以在其中利用本地共享文件系統,并且通信僅限于本地網絡接口。
在分布式系統上運行時,必須解決這些簡化問題以建立聯邦系統。圖 3 顯示了具有高可用性的分布式部署所需的組件,包括管理客戶端、監管者、服務器和客戶端系統之間的關系。
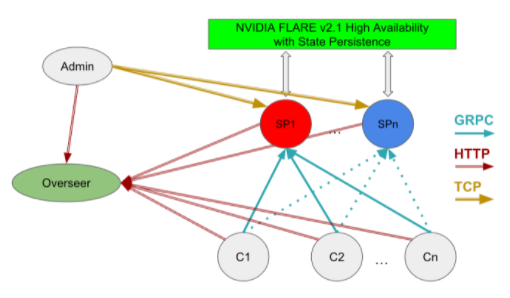
圖 3 : NVIDIA FLARE 高可用性部署( HA )
在此模型中,您必須考慮以下因素:
Network: 客戶端系統必須能夠在其完全限定的域名或通過將 IP 地址映射到主機名來解析監督者和服務提供商。
Storage: 服務器系統必須能夠訪問共享存儲,以便于從活動(熱)服務提供商處進行切換,如project.yml文件snapshot_persistor中所定義。
向每位參與者分發配置或啟動工具包
應用程序配置和客戶端數據集的位置
如前一節所述,可以通過在容器化環境中運行來解決其中的一些問題,其中啟動工具包和數據集可以安裝在每個系統上的一致路徑上。
分布式部署的其他方面取決于主機系統和網絡的本地環境,必須單獨解決。
總結
NVIDIA FLARE v2.1 提供了一套強大的工具,使研究人員或開發人員能夠將聯合學習概念引入到實際的生產工作流中。
這里討論的部署場景基于我們自己構建 FLARE 平臺的經驗,以及我們早期采用者將聯合學習工作流引入生產的經驗。希望這些可以作為開發您自己的聯邦應用程序的起點。
關于作者
Kris Kersten 是 NVIDIA 的解決方案架構師,專注于 AI ,致力于擴展 ML 和 DL 解決方案,以解決當今醫療領域最緊迫的問題。在加入 NVIDIA 之前, Kris 曾在 Cray 超級計算機公司工作,研究從低級緩存基準測試到大規模并行模擬的硬件和軟件性能特征。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5038瀏覽量
103304 -
機器學習
+關注
關注
66文章
8428瀏覽量
132820 -
深度學習
+關注
關注
73文章
5508瀏覽量
121314
發布評論請先 登錄
相關推薦
基于ptp的分布式系統設計
分布式、域控及SOA架構車身功能測試方案
HarmonyOS Next 應用元服務開發-分布式數據對象遷移數據權限與基礎數據
分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進

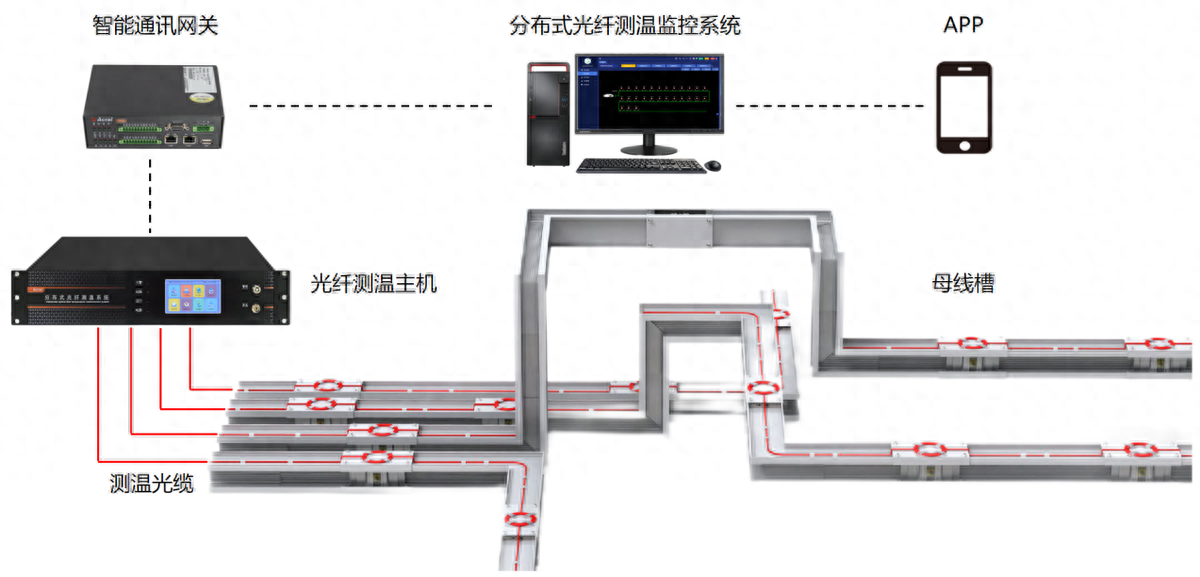
分布式光纖測溫是什么?應用領域是?
分布式輸電線路故障定位中的分布式是指什么

基于分布式計算的AR光波導中測試圖像的仿真
鴻蒙開發接口數據管理:【@ohos.data.distributedData (分布式數據管理)】

分布式能源是什么意思?分布式能源有什么優勢?
HarmonyOS開發實例:【分布式數據服務】
HarmonyOS實戰案例:【分布式賬本】
Docker在JMeter分布式測試中的作用





 工商網監
工商網監
評論