 使用NVIDIA Merlin庫構建基于會話的建議
使用NVIDIA Merlin庫構建基于會話的建議
推薦系統可以幫助您發現新產品并做出明智的決策。然而,在許多依賴于推薦的領域,如電子商務、新聞和流媒體服務,用戶可能無法跟蹤,或者根據當時的需求,用戶的口味可能會迅速變化。
基于會話的推薦系統是順序推薦的一個子領域,最近很受歡迎,因為它們可以在任何給定的時間點根據用戶的情況和偏好推薦項目。在這些領域中,捕捉用戶對項目的短期或上下文偏好很有幫助。
在本文中,我們將介紹基于會話的推薦任務,該任務由 NVIDIA Merlin 平臺的 Transformers4Rec 庫支持。然后,我們展示了使用 Transformers4Rec 在幾行代碼中創建基于會話的推薦模型是多么容易,最后,我們展示了使用 NVIDIA Merlin 庫的端到端基于會話的推薦管道。
Transformers4Rec 庫功能
NVIDIA Merlin 團隊于 ACM RecSys’21 發布,通過利用最先進的 Transformers 體系結構,為順序和基于會話的推薦任務設計并公開了 NVIDIA Merlin Transformers4Rec 庫。該庫可由研究人員擴展,對從業者來說很簡單,在工業部署中又快速又可靠。
它利用了 擁抱面( HF )變壓器 庫中的 SOTA NLP 體系結構,可以在 RecSys 域中快速試驗許多不同的 transformer 體系結構和預訓練方法。
Transformers4Rec 還幫助數據科學家、行業從業者和院士構建推薦系統,該系統可以利用同一會話中過去用戶交互的短序列,然后動態建議用戶可能感興趣的下一個項目。
以下是 Transformers4Rec 庫的一些亮點:
靈活性和效率: 構建塊模塊化,與 vanilla PyTorc h 模塊和 TF Keras 層兼容。您可以創建自定義體系結構,例如,使用多個塔、多個頭/任務和損耗。 Transformers4Rec 支持多個輸入功能,并提供可配置的構建塊,這些構建塊可以輕松組合用于定制體系結構。
與集成 HuggingFace Transformers : 使用最前沿的 NLP 研究,并為 RecSys 社區提供最先進的 transformer 體系結構,用于順序和基于會話的推薦任務。
支持多種輸入功能: Transformers4Rec 支持使用任何類型的順序表格數據的高頻變壓器。
與無縫集成 NVTabular 用于預處理和特征工程。
Production-ready: 導出經過培訓的模型以用于 NVIDIA Triton 推理服務器 在單個管道中進行在線特征預處理和模型推理。
開發您自己的基于會話的推薦模型
只需幾行代碼,就可以基于 SOTA transformer 體系結構構建基于會話的模型。下面的示例顯示了如何將強大的 XLNet transformer 體系結構用于下一個項目預測任務。
正如您可能注意到的,使用 PyTorch 和 TensorFlow 構建基于會話的模型的代碼非常相似,只有幾個不同之處。下面的代碼示例使用 Transformers4Rec API 使用 PyTorch 和 TensorFlow 構建基于 XLNET 的推薦模型:
#from transformers4rec import torch as tr
from transformers4rec import tf as tr
from merlin_standard_lib import Schema schema = Schema().from_proto_text("")
max_sequence_length, d_model = 20, 320
# Define input module to process tabular input-features and to prepare masked inputs
input_module = tr.TabularSequenceFeatures.from_schema( schema, max_sequence_length=max_sequence_length, continuous_projection=64, aggregation="concat", d_output=d_model, masking="clm",
) # Define Next item prediction-task prediction_task = tr.NextItemPredictionTask(hf_format=True,weight_tying=True) # Define the config of the XLNet architecture
transformer_config = tr.XLNetConfig.build( d_model=d_model, n_head=8, n_layer=2,total_seq_length=max_sequence_length
)
# Get the PyT model
model = transformer_config.to_torch_model(input_module, prediction_task)
# Get the TF model
#model = transformer_config.to_tf_model(input_module, prediction_task)
為了證明該庫的實用性和 transformer 體系結構在用戶會話的下一次點擊預測中的適用性, NVIDIA Merlin 團隊使用 Transformers4Rec 贏得了兩次基于會話的推薦比賽:
2021 WSDM WebTour 研討會挑戰賽 通過預訂。 com ( NVIDIA solution )
Coveo 2021 SIGIR 電子商務研討會數據挑戰賽 ( NVIDIA solution )
使用 NVIDIA Merlin 構建端到端、基于會話的推薦管道的步驟
圖 3 顯示了使用 NVIDIA Merlin Transformers4Rec 的基于會話的推薦管道的端到端管道。
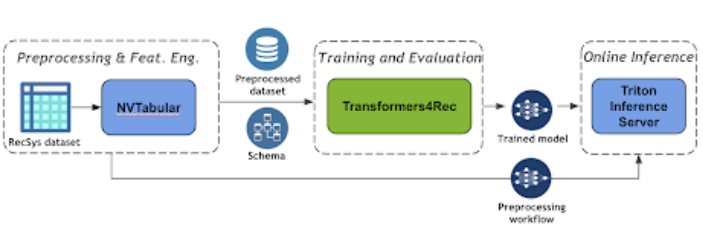
圖 3 :基于端到端會話的推薦管道
NVTabular 是一個用于表格數據的功能工程和預處理庫,旨在快速、輕松地操作用于培訓大規模推薦系統的 TB 級數據集。它提供了一個高級抽象,以簡化代碼,并使用 RAPIDS cuDF library。
NVTabular 支持深度學習 (DL) 模型所需的不同特征工程轉換,例如分類編碼和數值特征歸一化。它還支持特征工程和生成順序特征。有關支持的功能的更多信息,請參見此處。
在下面的代碼示例中,您可以很容易地看到如何創建一個 NVTabular 預處理工作流,以便在會話級別對交互進行分組,并按時間對交互進行排序。最后,您將獲得一個已處理的數據集,其中每一行表示一個用戶會話以及該會話的相應順序特征。
import nvtabular as nvt
# Define Groupby Operator
features = ['session_id', 'item_id', 'timestamp', 'category']
groupby_features = features >> nvt.ops.Groupby( groupby_cols=["session_id"], sort_cols=["timestamp"], aggs={ 'item_id': ["list", "count"], 'category': ["list"], 'timestamp': ["first"], }, name_sep="-") # create dataset object
dataset = nvt.Dataset(interactions_df)
workflow = nvt.Workflow(groupby_features)
# Apply the preprocessing workflow on the dataset sessions_gdf = workflow.transform(dataset).compute()
使用 Triton 推理服務器 簡化人工智能模型在生產中的大規模部署。 Triton 推理服務器使您能夠部署和服務您的模型進行推理。它支持許多不同的機器學習框架,例如 TensorFlow 和 Pytork 。
機器學習( ML )管道的最后一步是將 ETL 工作流和經過訓練的模型部署到產品中進行推理。在生產設置中,您希望像在培訓( ETL )期間那樣轉換輸入數據。例如,在使用 ML / DL 模型進行預測之前,應該對連續特征使用相同的規范化統計信息,并使用相同的映射將類別編碼為連續 ID 。
幸運的是, NVIDIA Merlin 框架有一個集成機制,可以將預處理工作流(用 NVTABLAR 建模)和 PyTorch 或 TensorFlow 模型作為 NVIDIA Triton 推理的集成模型進行部署。集成模型保證對原始輸入應用相同的轉換。
下面的代碼示例展示了使用 NVIDIA Merlin 推理 API 函數創建集成配置文件,然后將模型提供給 TIS 是多么容易。
import tritonhttpclient
import nvtabular as nvt workflow = nvt.Workflow.load("") from nvtabular.inference.triton import export_tensorflow_ensemble as export_ensemble
#from nvtabular.inference.triton import export_pytorch_ensemble as export_ensemble
export_ensemble( model, workflow, name="", model_path="", label_columns=["
只需幾行代碼,就可以為 NVIDIA PyTorch 推理服務器提供 NVTabular 工作流、經過培訓的 Triton 或 TensorFlow 模型以及集成模型,以便執行端到端的模型部署。 使用 NVIDIA Merlin 推理 API ,您可以將原始數據集作為請求(查詢)發送到服務器,然后從服務器獲取預測結果。
本質上, NVIDIA Merlin 推理 API 使用 NVIDIA Triton ensembling 特性創建模型管道。 NVIDIA Triton ensemble 表示一個或多個模型的管道以及這些模型之間輸入和輸出張量的連接。
結論
在這篇文章中,我們向您介紹了 NVIDIA Merlin Transformers4Rec ,這是一個用于順序和基于會話的推薦任務的庫,它與 NVIDIA NVTabular 和 NVIDIA Triton 推理服務器無縫集成,為此類任務構建端到端的 ML 管道。
關于作者
Ronay Ak 是 NVIDIA RAPIDS 團隊的數據科學家。
GabrielMoreira 是 NVIDIA ( NVIDIA ) Merlin 團隊的高級研究員,致力于推薦系統的深度學習,這是他的博士學位的重點。他曾擔任首席數據科學家和軟件工程師多年。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5025瀏覽量
103270 -
API
+關注
關注
2文章
1505瀏覽量
62184
發布評論請先 登錄
相關推薦
使用NVIDIA JetPack 6.0和YOLOv8構建智能交通應用
應用NVIDIA Spectrum-X網絡構建新型主權AI云
在NVIDIA Holoscan SDK中使用OpenCV構建零拷貝AI傳感器處理管線

NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業軟件支持
借助NVIDIA DOCA 2.7增強AI 云數據中心和NVIDIA Spectrum-X
利用NVIDIA的nvJPEG2000庫分析DICOM醫學影像的解碼功能
NVIDIA Omniverse USD Composer能用來做什么?如何獲取呢?





 工商網監
工商網監
評論