

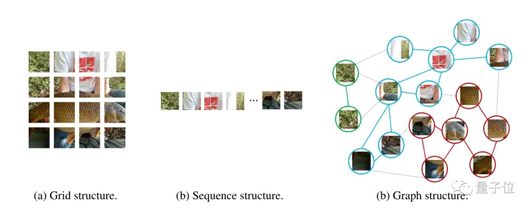
用圖神經(jīng)網(wǎng)絡(luò)(GNN)做CV的研究有不少,但通常是圍繞點(diǎn)云數(shù)據(jù)做文章,少有直接處理圖像數(shù)據(jù)的。其實(shí)與CNN把一張圖片看成一個(gè)網(wǎng)格、Transformer把圖片拉直成一個(gè)序列相比,圖方法更適合學(xué)習(xí)不規(guī)則和復(fù)雜物體的特征。
近期中科院與華為諾亞方舟實(shí)驗(yàn)室等提出一種全新的骨干網(wǎng)絡(luò),把圖片表示成圖結(jié)構(gòu)數(shù)據(jù),讓GNN也能完成經(jīng)典CV三大任務(wù)。
該論文引起GNN學(xué)者廣泛關(guān)注。有人認(rèn)為GNN領(lǐng)域積累多年的技巧都將涌入這一新方向,帶來一波研究熱潮。

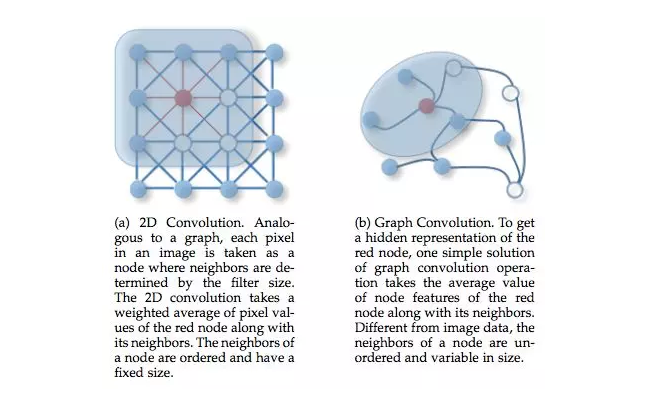
在研究團(tuán)隊(duì)看來,圖結(jié)構(gòu)是一種更通用的數(shù)據(jù)結(jié)構(gòu)。甚至網(wǎng)格和序列可以當(dāng)作圖結(jié)構(gòu)的特例,用圖結(jié)構(gòu)來做視覺感知會更加靈活。圖數(shù)據(jù)由節(jié)點(diǎn)和邊組成,如果把每個(gè)像素都看作節(jié)點(diǎn)計(jì)算難度過于大了,因此研究團(tuán)隊(duì)采用了切塊(patch)方法。
對于224x224分辨率的圖像,每16x16像素為一個(gè)Patch,也就是圖數(shù)據(jù)中的一個(gè)節(jié)點(diǎn),總共有196個(gè)節(jié)點(diǎn)。對每個(gè)節(jié)點(diǎn)搜索他們距離最近的節(jié)點(diǎn)構(gòu)成邊,邊的數(shù)量隨網(wǎng)絡(luò)深度而增加。接下來,網(wǎng)絡(luò)架構(gòu)分為兩部分:一個(gè)圖卷積網(wǎng)絡(luò)(GCN),負(fù)責(zé)處理圖數(shù)據(jù)、聚合相鄰節(jié)點(diǎn)中的特征。一個(gè)前饋神經(jīng)網(wǎng)絡(luò)(FFN),結(jié)構(gòu)比較簡單是兩個(gè)全連接層的MLP,負(fù)責(zé)特征的轉(zhuǎn)換。
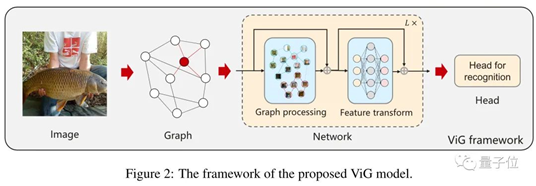
傳統(tǒng)GCN會出現(xiàn)過度平滑現(xiàn)象,為解決這個(gè)問題,團(tuán)隊(duì)在圖卷積層前后各增加一個(gè)線性層,圖卷積層后再增加一個(gè)激活函數(shù)。
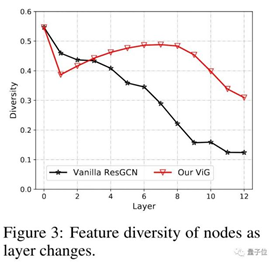
實(shí)驗(yàn)表明,用上新方法,當(dāng)層數(shù)較多時(shí)ViG學(xué)習(xí)到的特征會比傳統(tǒng)ResGCN更為多樣。
為了更準(zhǔn)確評估ViG的性能,研究團(tuán)隊(duì)設(shè)計(jì)了ViT常用的同質(zhì)結(jié)構(gòu)(isotropic)和CNN常用的金字塔結(jié)構(gòu)(Pyramid)兩種ViG網(wǎng)絡(luò),來分別做對比實(shí)驗(yàn)。同質(zhì)架構(gòu)ViG分為下面三種規(guī)格。
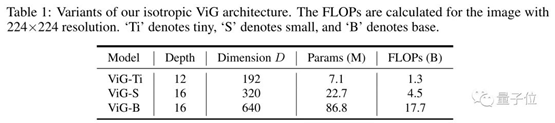
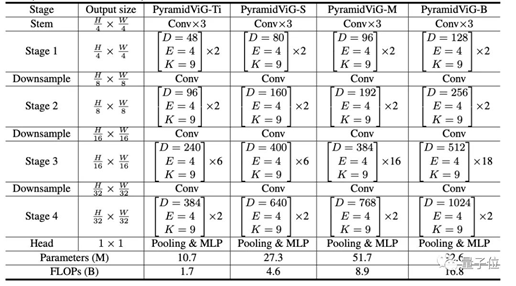
與常見的同質(zhì)結(jié)構(gòu)CNN、ViT與MLP網(wǎng)絡(luò)相比,ViG在同等算力成本下ImageNet圖像分類的表現(xiàn)更好。金字塔結(jié)構(gòu)的ViG網(wǎng)絡(luò)具體設(shè)置如下。
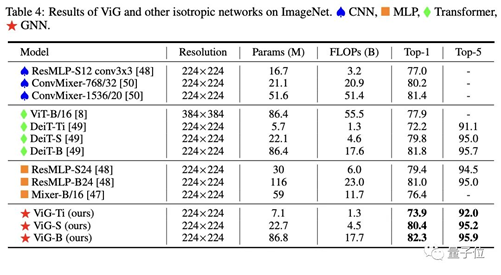
同等算力成本下,ViG也與最先進(jìn)的CNN、ViT和MLP相比,性能也能超越或表現(xiàn)相當(dāng)。
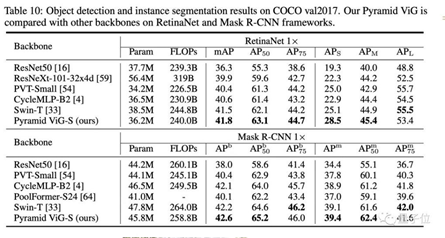
在目標(biāo)檢測和實(shí)例分割測試上,ViG表現(xiàn)也與同等規(guī)模的Swin Transformer相當(dāng)。
最后,研究團(tuán)隊(duì)希望這項(xiàng)工作能作為GNN在通用視覺任務(wù)上的基礎(chǔ)架構(gòu),Pytorch版本和Mindspore版本代碼都會分別開源。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4794瀏覽量
102113 -
cnn
+關(guān)注
關(guān)注
3文章
353瀏覽量
22557 -
圖卷積網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
8瀏覽量
1547
原文標(biāo)題:?圖神經(jīng)網(wǎng)絡(luò)(GNN)直接處理圖像數(shù)據(jù)
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
圖神經(jīng)網(wǎng)絡(luò)概述第三彈:來自IEEE Fellow的GNN綜述
神經(jīng)網(wǎng)絡(luò)教程(李亞非)
labview BP神經(jīng)網(wǎng)絡(luò)的實(shí)現(xiàn)
【案例分享】ART神經(jīng)網(wǎng)絡(luò)與SOM神經(jīng)網(wǎng)絡(luò)
GNN(圖神經(jīng)網(wǎng)絡(luò))硬件加速的FPGA實(shí)戰(zhàn)解決方案
如何構(gòu)建神經(jīng)網(wǎng)絡(luò)?
基于BP神經(jīng)網(wǎng)絡(luò)的PID控制
如何使用stm32cube.ai部署神經(jīng)網(wǎng)絡(luò)?
卷積神經(jīng)網(wǎng)絡(luò)一維卷積的處理過程
神經(jīng)網(wǎng)絡(luò)移植到STM32的方法
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
圖神經(jīng)網(wǎng)絡(luò)GNN的卷積操作流程

圖形神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)知識兩種較高級的算法
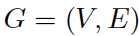
GNN解釋技術(shù)的總結(jié)和分析與圖神經(jīng)網(wǎng)絡(luò)的解釋性綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論