 數據中心將進入完全可編程時代
數據中心將進入完全可編程時代
大家看到這個標題,第一個反應應該會是疑問:難道現在數據中心的處理器不可編程? 首先,強調一下,現在數據中心的處理器,當然是可編程的。但是,我標題這么寫,一定是有原因的。 NVIDIA有DPU和DOCA;Intel有IPU和IPDK,而且還發起了OPI;然后博通剛剛宣布收購VMWare。這些看似沒有聯系的事情之間,其實有一個共通的底層邏輯。
01先聊聊功能機到智能機的發展
直到現在,我仍然印象深刻的記得,在2010年的時候,諾基亞還保持著全球手機銷量霸主的地位。但這個時候,整個市場已經不看好諾基亞了,它的日子并不好過。當時我還覺得諾基亞就是再不濟,也應該作為智能手機和移動互聯網時代的一個重要的參與者而存在。誰能想到,短短幾年,諾基亞手機就“煙消云散”了。 據說,當年諾基亞遲遲未推出能夠挑戰iPhone的產品的主要原因,是該公司認為iPhone注定失敗,因為其未能通過抗摔測試。第一代iPhone面市時,諾基亞工程師就對其進行了全面的研究,最終認定,它不會對諾基亞產生威脅,原因是造價太高,并且只兼容2G網絡,而且未能通過基本的抗摔測試。而此時的諾基亞正如日中天,諾基亞引領了很多手機功能的“創新”,比如手機攝像、全功能鍵盤、塞班操作系統,當然也包括和旋鈴聲、換殼等。 換湯不換藥,不本質創新的諾基亞,難以改變被市場無情拋棄的命運。 我們來總結一下iPhone這樣的智能手機的成功之處。我個人總結,主要有兩點:
一個是,不要試圖幫助用戶決策。智能手機提供給用戶的是一個平臺,而不是一個具有具體功能的產品。用戶是通過安裝APP來實現自己要的五花八門又各自不同的具體功能的。
另一個是,易用性。在智能手機表現的則是人機交互,也就是劃時代意義的觸摸劃屏交互。在2017年iPhone之前,其實微軟已經早在2000年就發布了基于Windows的智能手機。但其因為通過觸控筆實現類似鼠標的單擊雙擊,非常難用,所以一直沒能流行起來。
02再分析一下各類處理引擎
2.1 CPU
在數據中心等復雜計算場景,對靈活可編程性要求非常高。 CPU是可編程的,而且CPU還是靈活性最好的可編程平臺。因此,目前數據中心的處理器主要還是CPU。而GPU/ASIC等均不滿足靈活可編程性的要求。 而隨著技術發展,CPU的性能逐漸瓶頸,基于CPU的摩爾定律失效。但算力的需求并沒有停滯,仍在不斷提升,因此,各類其他的處理引擎和芯片逐漸走上了舞臺。
2.2 GPU
GPU(默認為GPGPU),一方面其數以千計的引擎可編程能力不錯,可以覆蓋非常多的領域。也因為CUDA強大生態的加持,使得GPU這幾年以及未來若干年,在數據中心會得到非常大規模的采用。 但是,相比DSA/ASIC來說,GPU的性能還是不夠極致。
2.3 DSA
John Hennessy和David Patterson是體系結構領域的權威,兩人在其2017年圖靈獎獲獎演講時說,未來十年是體系機構的黃金年代,在CPU性能達到瓶頸的情況下,需要針對特定的領域定制專用處理器,這也就是當前大家熟悉的DSA。 已經被Intel收購的Barefoot公司,設計的可編程網絡DSA芯片Tofino已經得到非常多的落地;但AI類的DSA目前仍沒有看到比較廣泛的落地。兩者的主要區別在于:
網絡領域處于基礎設施層次,其場景變化相對較小。DSA相比ASIC較好,但相比GPU較差,的靈活可編程能力,基本符合網絡領域的靈活性要求。因此,其可以在確保靈活可編程能力的基礎上實現最極致的性能。
而AI領域,目前算法多種多樣,很多新的算法還在出現。AI領域,在性質上,仍然屬于應用層次,也即場景靈活多變。這樣對引擎的靈活可編程能力提出了更高要求,而DSA架構的處理器很難滿足。從實踐可以看到,目前大量的AI是基于更高靈活性的GPU部署的。
當然,隨著時間推移,很多AI類的算法沉淀,勢必逐漸從應用變成基礎設施。當AI逐漸穩定,對靈活性的要求降低,就是AI DSA大顯身手之時。
2.4 ASIC
越是復雜場景,對靈活性的要求越高。 在大芯片場景,ASIC形態的處理引擎會完全消失。
03未來發展:完全可編程
3.1 智能網卡、DPU等芯片的落地困境
因為CPU性能不夠,因此出現了很多類型的芯片來卸載CPU的任務,減輕CPU的負擔,以此來實現性能提升。如單功能加速卡、智能網卡、DPU等。這些處理器目前存在一些共性的挑戰:
因為不同用戶業務場景存在差異化,并且用戶業務場景仍在快速迭代。
跟客戶場景深度綁定,是偏ASIC級別的定制,會導致市場碎片化。碎片化的市場會導致某一芯片產品能覆蓋的規模較小,也即出貨量會少。
偏ASIC的定制會導致芯片設計復雜度高。ASIC緊耦合的系統,把業務邏輯完全變成電路,芯片設計工作量大,設計復雜度高。另外場景的多種多樣和快速迭代,也使得ASIC設計難以覆蓋更多的差異。
芯片NRE、IP等費用高,需要芯片大規模落地。工藝進步,使得大芯片的研發成本進一步提升。這就需要芯片銷量進一步提升,才能攤薄一次性成本。而偏定制的方案則完全走向了相反的方向。大芯片,一定需要足夠通用靈活可編程,才好大規模落地。
類比前面功能機和智能機的區別,可以認為:
目前很多加速卡、智能網卡、DPU的做法仍是類似功能機的做法。整個功能是確定的,硬件中實現了很多具體功能和業務邏輯,越庖代俎,幫助用戶決策。
還沒有做到,類“智能手機”的做法,完全可編程的硬件平臺,把決策交給用戶。
3.2 架構:從同構到異構,再到超異構

常見的多核CPU,即是同構并行計算。CPU是最常見的并行計算架構,但由于單個CPU核的性能已經到達瓶頸,并且單顆芯片所能容納的核數也逐漸到頭。CPU同構并行已經沒有多少性能挖潛的空間。 CPU+xPU的異構加速并行架構,一般情況下,GPU、FPGA及DSA加速器都是作為CPU的協處理加速器的形態存在,不是圖靈完備的。異構計算CPU是輔助,系統的特點跟加速器是一致的,符合我們之前關于GPU、DSA等處理引擎的分析,各有優缺點。
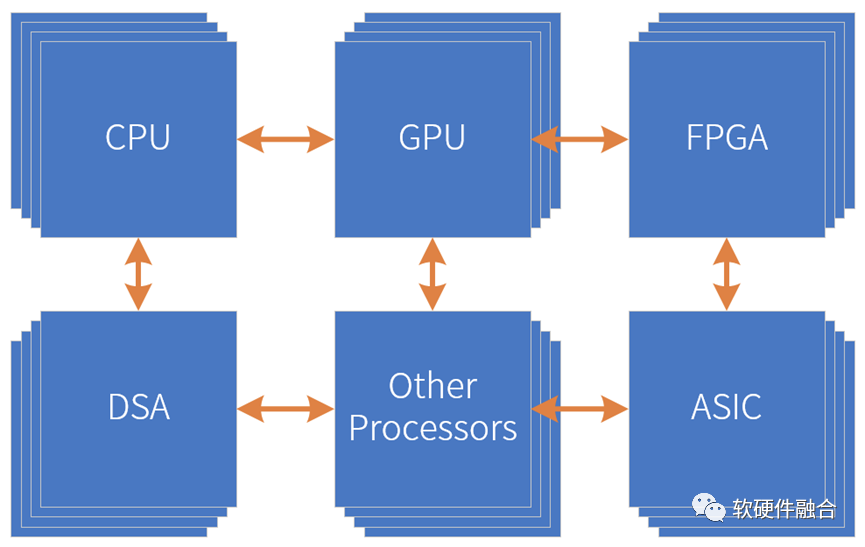
芯片工藝帶來的資源規模越來越大,所能支撐的設計規模也越來越大,這給架構創新提供了非常堅實的基礎。可以采用多種處理引擎,從單兵作戰到團隊協作,來共同完成復雜系統的計算任務,這就是超異構。
3.3 用戶/開發者視角:完全可編程的芯片平臺
像智能手機一樣,完全可編程的處理芯片提供給用戶的是一個沒有具體功能的芯片平臺,具體的功能由用戶通過軟件編程實現。 完全可編程的含義:
所有功能由用戶通過軟件定義。授人以魚不如授人以漁,既然提供的是平臺化解決方案。那么一些主要的組件一定是要集成的,然后這些單元又可以自由組合,給用戶提供一個幾乎“無限”可能的平臺。不同的用戶,根據自己的需求組合功能,實現功能和場景差異。
所有業務邏輯由用戶通過編程實現。用戶自己的軟件已經存在,業務邏輯也是經過長期打磨。業務邏輯是一個非常重要的事情:一些大的云計算公司,其底層業務邏輯支撐的上層云客戶的業務都超萬億。這樣,底層的業務邏輯修改一定是慎之又慎。用戶期望的是不修改業務邏輯情況下,通過硬件實現業務處理的加速。
用戶沒有平臺依賴。軟件熱遷移需要一致性接口的硬件,上層業務邏輯也需要一致性的硬件功能支持。這些都需要,站在用戶視角,不同芯片廠家提供的是接口和架構完全一致標準化的產品。
講完這里,我想大家可能還是有點疑惑,因為CPU就可以做到完全可編程,RISC-v架構CPU可以實現真正的無平臺依賴。完全可編程是個什么? 那么,請接著看下一節。
3.4 性能和靈活性,似拔河一樣拉扯到各自極致
完全可編程性能和靈活性的權衡,像天平,更像拔河比賽。 我們經常講balance或tradeoff,也就是均衡(名詞)/權衡(動詞)。但總覺得少了點什么。思來想后,發現是少了點主動、少了點極致:
完全可編程,是要在滿足靈活可編程的基礎上,實現最極致的性能;
完全可編程,是要在性能滿足要求的情況下,實現最極致的靈活可編程性。
完全可編程:
并不是說所有的事情,都CPU來完成,這是一種“懶惰”、“躺平”,因為CPU的性能是最差的;
也不是說,所有的事情都DSA完成。這樣又會過猶不及。因為很多場景,對靈活性的要求超過了DSA可提供的靈活性能力。最典型場景就是AI加速,目前很多AI芯片落地困難的原因就是不滿足靈活性的要求。

如何做? 系統是分層分塊的,我們大體上可以把系統的工作任務分為三類:
應用層。站在硬件平臺的視角,應用是完全不確定的,也不確定知道運行的應用到底是什么。這樣,應用層的工作就適合CPU來做。
應用加速。有很多應用層的工作,性能敏感,需要通過加速的方式。但一方面受限于應用本身的算法變化較大,另一方面,硬件平臺也可能給其他用戶的相似應用使用,因此,彈性一些的加速會更合適一些。這樣,GPU就成了應用加速的首選。
基礎設施層。基礎設施層相對變化較少(但并不意味著不變化),所以通常DSA架構處理引擎可以滿足靈活性的基礎上,實現最極致的性能。
這個劃分,并不一定完全準確。還需要根據具體的工作任務特定,決定選擇具體的處理器類型。
還有一點就是動態變化。可能隨著系統的發展,有的任務會“上浮”,越來越需要靈活性;有的任務會“下沉”,更可以通過更優的硬件加速來極致的提升性能。
總之,大原則是:要在滿足性能的基礎上,提供最極致的靈活性;或者,在滿足靈活性要求的基礎上盡可能的選擇性能更優的處理引擎方案,實現盡可能極致的性能。 每個引擎都有優勢,也有劣勢,通過單兵作戰,我們只能“權衡”。但通過“團隊協作”的超異構,我們能夠實現優勢互補,可以像拔河一樣,把性能和靈活性都拉扯到極致。
3.5 案例:Intel愿景,完全可編程的網絡
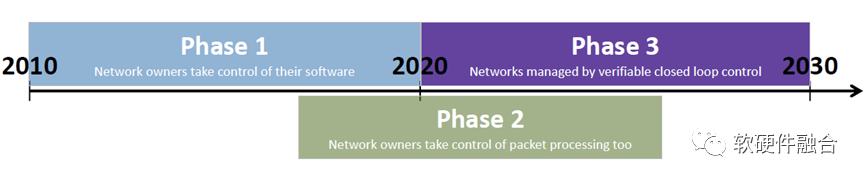
Intel SVP Nick McKeown 在 ONF Connect 2019演講中第一次定義了SDN發展的三個階段:
第一階段(2010–2020年):通過Openflow將控制面和數據面分離,用戶可以通過集中的控制端去控制每個交換機的行為;
第二階段(2015–2025年):通過P4編程語言以及可編程FPGA或ASIC實現數據面可編程,這樣,在包處理流水線加入一個新協議的支持,開發周期從數年降低到數周;
第三階段(2020–2030年):展望未來,網卡、交換機以及協議棧均可編程,整個網絡成為一個可編程平臺。
這預示著,未來不管是交換機側還是網卡側,均需要實現類似CPU于通用程序設計的完全可編程的網絡處理引擎,并且要基于此平臺實現一整套的軟件堆棧。把一個完全可編程的網絡交給用戶,支撐用戶更快速的網絡創新。
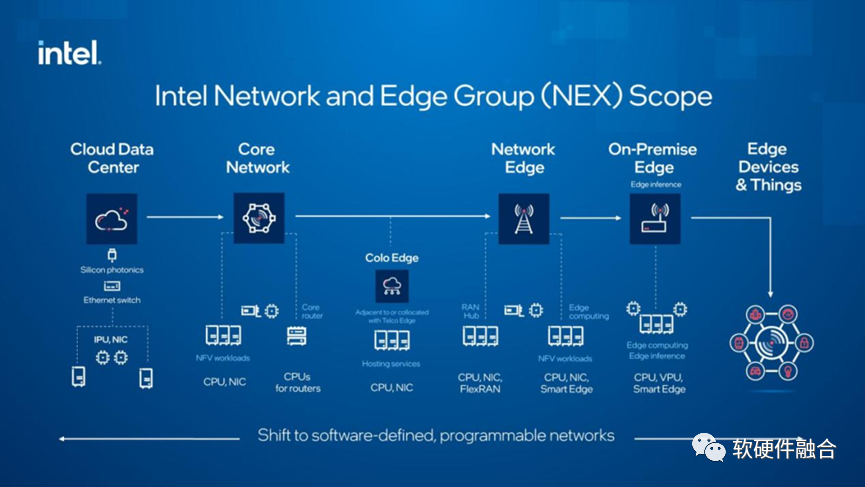
上圖是Intel對整個未來網絡演進趨勢的看法:從云數據中心、核心網、接入網、邊緣計算甚至終端設備,都會演化成完全“軟件定義的可編程網絡”。 當然,只是可編程的網絡還不夠。對數量眾多的計算節點來說,對用戶來說,完全可編程的計算(存儲等其他處理都可以歸到計算部分)才是更重要的。這樣,可編程的網絡和可編程的計算,共同組成了完全可編程的數據中心。
04完全可編程,還需要在硬件層次
提供更多通常屬于軟件的能力
4.1 可擴展
云計算有很多關鍵的能力,如彈性伸縮、虛擬化、多租戶等。這些都對硬件的擴展能力提出了更高的要求:
功能的擴展。各類處理引擎的可編程能力來實現不同的功能;不同引擎的組合可以組織成不同的宏功能。
平行擴展。處理引擎要支持虛擬化,類似硬件里的多通道的概念。可以提供數以千計甚至數以萬計的通道,使得每一個租戶每個VM/容器甚至每一個應用都可以獨占物理通道(資源)。
多芯片擴展。可以通過多芯片、多服務器、多Rack甚至多POD擴展,并且大家都是完全平行的,不產生新的Hierarchy分層(會顯著增加系統復雜度,編程困難)。
4.2 軟件實體和硬件平臺分離
通常情況下,軟件是附屬于硬件而存在,軟件實體和硬件平臺是綁定的。 而在數據中心,軟件和硬件是分離的:同一個軟件實體會在不同的硬件實體遷移,而同樣的一個硬件實體也需要運行不同的軟件實體。 這樣的需求,對硬件平臺的一致性提出了很高的要求。
4.3 云網邊端融合
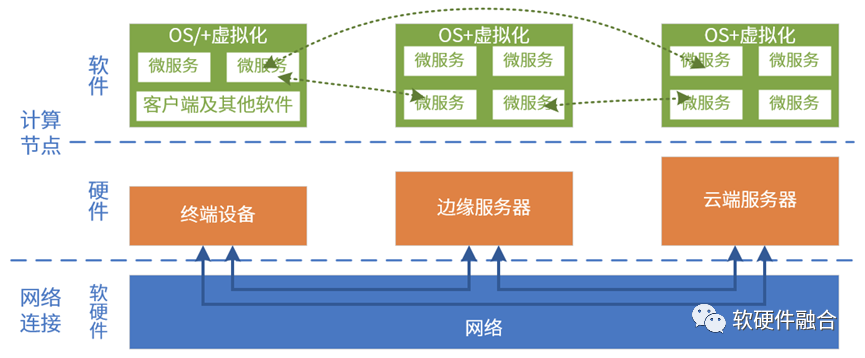
云計算、邊緣計算、終端以及網絡,算力需求不斷提高,系統復雜度不斷提高,對硬件的靈活可編程性要求也越來越高。 云網邊端不是割裂的,而是組合成一個更大的系統的。微服務可運行在云端、邊緣端,甚至終端本地。這就需要云數據中心內部,以及跨云邊端的硬件平臺一致性。
4.4 開放生態
隨著系統越來越復雜,未來,所有的芯片都會是超異構架構芯片。所有的芯片也都需要支持虛擬化。并且,隨著性能的提升,軟件虛擬化代價越來越高,要盡可能的把虛擬化下沉到硬件加速。廣義的虛擬化,不僅僅包括Hypervisor和I/O設備模擬,也包括網絡VPC和分布式存儲。DPU等芯片,本質上就是實現整個廣義虛擬化的加速。 關于生態,這里講三個仍在早期發展的對比案例:
NVIDIA DPU和DOCA。NVIDIA走的是一套完全封閉的路子,給客戶提供性強勁功能相對完善的解決方案;但對可編程能力的支持,不是很友好。我們是不是可以類比為塞班?
Intel IPU和IPDK和OPI。Intel走的是開放平臺的路子,如果類比到智能手機領域,那么IPDK是否可以類比為安卓?
博通計劃收購VMWare。博通走的是直接收購現有技術生態的路子。底層芯片公司收購虛擬化技術和生態公司,強強整合,從DPU芯片到系統到生態,在企業和私有云場景,基本上可以通吃。VMWare的虛擬化技術本身,也是全球領先。博通可以通過這次收購,引領虛擬化相關技術發展趨勢。現在收購還未成功,說類比蘋果iOS還為時尚早,未來發展,繼續觀察。
從CPU到ASIC,越來越多的不同領域/不同場景的處理引擎。而且即使是同一領域或場景,不同廠家的實現架構也會完全不同。領域或場景越來越碎片化,構建生態越來越困難。系統的設計,逐步從硬件定義軟件,轉向軟件定義硬件。這也符合目前“軟件定義一切”的大趨勢。 此外,需要軟件原生支持硬件加速。軟件在架構設計的時候就要區分控制平面和計算平面,實現兩者分離,然后把計算平面下沉到硬件。 當異構處理器的引擎架構越來越多,(不同廠家)芯片數量越來越多,所處的環境(云網邊端)也越來越多,需要構建高效的、標準的、開放的生態體系。
審核編輯 :李倩
-
處理器
+關注
關注
68文章
19349瀏覽量
230313 -
cpu
+關注
關注
68文章
10882瀏覽量
212248 -
NVIDIA
+關注
關注
14文章
5025瀏覽量
103270 -
數據中心
+關注
關注
16文章
4816瀏覽量
72226
原文標題:類似智能手機的發展,數據中心將進入完全可編程時代
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據中心產品通常包括哪些

可編程晶振的優點和缺點

可編程晶振都有什么頻率的呢?分享3個挑選可編程晶振的技巧

AI時代,我們需要怎樣的數據中心?AI重新定義數據中心

可編程電源的作用是什么
可編程電源使用方法
可編程電源如何編程
什么是現場可編程邏輯陣列?它有哪些特點和應用?

可編程片上系統是什么
現場可編程門陣列的原理和應用
現場可編程門陣列是什么
用于電視的高分辨率、完全可編程LCD偏置IC TPS65168數據表

可編程控制器的組成 可編程控制器有哪些特點?






 工商網監
工商網監
評論