 如何通過在Python中使用并發來加速網頁數據抓取項目
如何通過在Python中使用并發來加速網頁數據抓取項目
從網站中抓取數據是開發者的一個典型“用例”。無論它是屬于副業項目,還是你正在成立一個初創公司,抓取數據似乎都很有必要。
舉個例子,倘若您想要創建一個比價網站,那么您會需要從各種電商網站上抓取價格信息;或者您想要構建一個可以識別商品并在亞馬遜上自動查找價格的“人工智能”。類似的場景還有很多。
但是您有沒有注意到,獲取所有頁面信息的速度有多慢呢?您會選擇一個接一個地去抓取商品嗎?應該會有更好的解決方案吧?答案是肯定的。
抓取網頁可能非常耗時,因為您必須花時間等待服務器響應,抑或是速率受限。這就是為什么我們要向您展示如何通過在 Python 中使用并發來加速您的網頁數據抓取項目。
前提
為了使代碼正常運行,您需要安裝 python 3[1]。部分系統可能已經預裝了它。然后您還需要使用 pip install 安裝所有必要的庫。
pipinstallrequestsbeautifulsoup4aiohttpnumpy
如果您了解并發背后的基礎知識,可以跳過理論部分直接進入實際操作環節。
并發
并發是一個術語,用于描述同時運行多個計算任務的能力。
當您按順序向網站發出請求時,您可以選擇一次發出一個請求并等待結果返回,然后再發出下一個請求。
不過,您也可以同時發送多個請求,并在它們返回時處理對應的結果,這種方式的速度提升效果是非常顯著的。與順序請求相比,并發請求無論是否并行運行(多個 CPU),都會比前者快得多 -- 稍后會詳細介紹。
要理解并發的優勢。我們需要了解順序處理和并發處理任務之間的區別。假設我們有五個任務,每個任務需要 10 秒才能完成。當按順序處理它們時,完成五個任務所需的時間為 50 秒;而并發處理時,僅需要 10 秒即可完成。
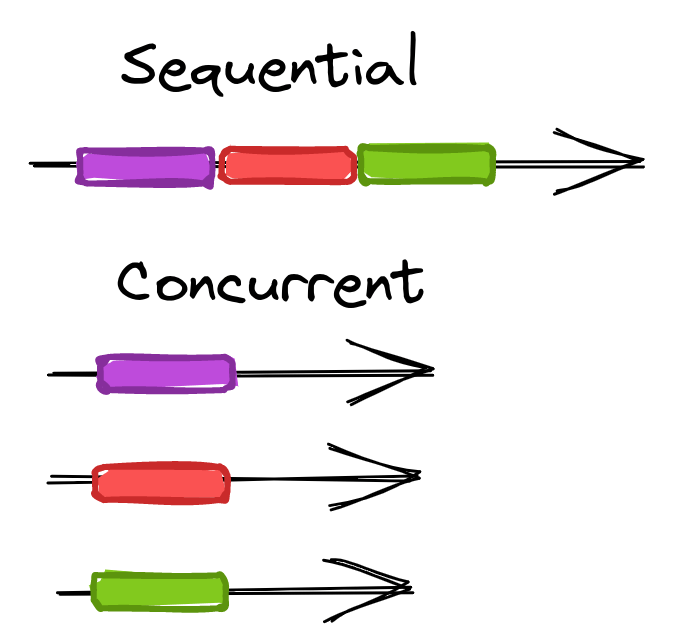
除了提高處理速度之外,并發還允許我們通過將網頁抓取任務負載分布于多個進程中,來實現在更短的時間內完成更多的工作。
這里有幾種實現并行化請求的方式:例如 multiprocessing 和 asyncio。從網頁抓取的角度來看,我們可以使用這些庫來并行處理對不同網站或同一網站不同頁面的請求。在本文中,我們將重點關注 asyncio,這是一個 Python 內置的模塊,它提供了使用協程編寫單線程并發代碼的基礎設施。
由于并發意味著更復雜的系統和代碼,因此在使用前請考慮在您的使用場景中是否利大于弊。
并發的優勢
在更短的時間內完成更多的工作
可以將空閑的網絡時間投入到其他請求中
并發的危險之處
更不易于開發和調試
可能存在競爭條件
需要檢查并使用線程安全的函數
一不小心就會增加程序阻塞的概率
并發自帶系統開銷,因此需要設置合理的并發級別
針對小型站點請求過多的話,可能會變成 DDoS 攻擊
*同時釋放所有請求時要小心*
為何選擇 asyncio
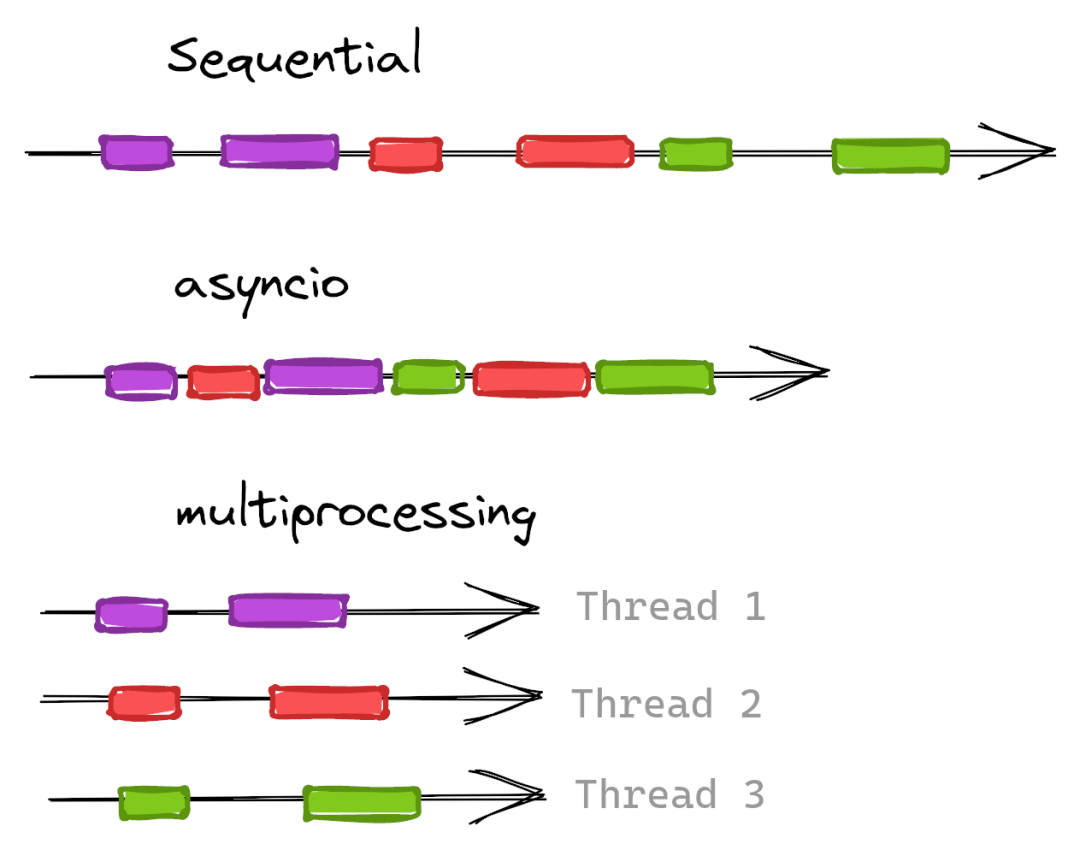
在做出選擇之前,我們有必要了解一下 asyncio 和 multiprocessing 之間的區別,以及 IO 密集型與 CPU 密集型之間的區別。
asyncio[2] “是一個使用 async/await 語法編寫并發代碼的庫”,它在單個處理器上運行。
multiprocessing[3] “是一個支持使用 API 生產進程的包 [...] 允許程序員充分利用給定機器上的多個處理器”。每個進程將在不同的 CPU 中啟動自己的 Python 解釋器。
IO 密集型意味著程序將受 I/O 影響而變得運行緩慢。在我們的案例中,主要指的是網絡請求。
CPU 密集型意味著程序會由于 CPU 計算壓力導致運行緩慢 -- 例如數學計算。
為什么這會影響我們選擇用于并發的庫?因為并發成本的很大一部分是創建和維護線程/進程。對于 CPU 密集型問題,在不同的 CPU 中擁有多個進程將會提升效率。但對于 I/O 密集型的場景,情況可能并非如此。
由于網頁數據抓取主要受 I/O 限制,因此我們選擇了 asyncio。但如果有疑問(或只是為了好玩),您可以使用 multiprocessing 嘗試這個場景并比較一下結果。
順序實現的版本
我們將從抓取 scrapeme.live 作為示例開始,這是一個專門用于測試的電子商務網站。
首先,我們將從順序抓取的版本開始。以下幾個片段是所有案例的一部分,因此它們將保持不變。
通過訪問目標主頁,我們發現它有 48 個子頁面。由于是測試環境,這些子頁面不會很快發生變化,我們會使用到以下兩個常量:
base_url="https://scrapeme.live/shop/page" pages=range(1,49)#maxpage(48)+1
現在,從目標產品中提取基礎數據。為此,我們使用 requests.get 獲取 HTML 內容,然后使用 BeautifulSoup 解析它。我們將遍歷每個產品并從中獲取一些基本信息。所有選擇器都來自對內容的手動審查(使用 DevTools),但為簡潔起見,我們不會在這里詳細介紹。
importrequests frombs4importBeautifulSoup defextract_details(page): #concatenatepagenumbertobaseURL response=requests.get(f"{base_url}/{page}/") soup=BeautifulSoup(response.text,"html.parser") pokemon_list=[] forpokemoninsoup.select(".product"):#loopeachproduct pokemon_list.append({ "id":pokemon.find(class_="add_to_cart_button").get("data-product_id"), "name":pokemon.find("h2").text.strip(), "price":pokemon.find(class_="price").text.strip(), "url":pokemon.find(class_="woocommerce-loop-product__link").get("href"), }) returnpokemon_list
extract_details 函數將獲取一個頁碼并將其連接起來,用于創建子頁面的 URL。獲取內容并創建產品數組后返回。這意味著返回的值將是一個字典列表,這是一個后續使用的必要細節。
我們需要為每個頁面運行上面的函數,獲取所有結果,并存儲它們。
importcsv
#modifiedtoavoidrunningallthepagesunintentionally
pages=range(1,3)
defstore_results(list_of_lists):
pokemon_list=sum(list_of_lists,[])#flattenlists
withopen("pokemon.csv","w")aspokemon_file:
#getdictionarykeysfortheCSVheader
fieldnames=pokemon_list[0].keys()
file_writer=csv.DictWriter(pokemon_file,fieldnames=fieldnames)
file_writer.writeheader()
file_writer.writerows(pokemon_list)
list_of_lists=[
extract_details(page)
forpageinpages
]
store_results(list_of_lists)
運行上面的代碼將獲得兩個產品頁面,提取產品(總共 32 個),并將它們存儲在一個名為 pokemon.csv 的 CSV 文件中。 store_results 函數不影響順序或并行模式下的抓取。你可以跳過它。
由于結果是列表,我們必須將它們展平以允許 writerows 完成其工作。這就是為什么我們將變量命名為list_of_lists(即使它有點奇怪),只是為了提醒大家它不是扁平的。
輸出 CSV 文件的示例:
| id | name | price | url |
|---|---|---|---|
| 759 | Bulbasaur | £63.00 | https://scrapeme.live/shop/Bulbasaur/ |
| 729 | Ivysaur | £87.00 | https://scrapeme.live/shop/Ivysaur/ |
| 730 | Venusaur | £105.00 | https://scrapeme.live/shop/Venusaur/ |
| 731 | Charmander | £48.00 | https://scrapeme.live/shop/Charmander/ |
| 732 | Charmeleon | £165.00 | https://scrapeme.live/shop/Charmeleon/ |
如果您要為每個頁面 (48) 運行腳本,它將生成一個包含 755 個產品的 CSV 文件,并花費大約 30 秒。
timepythonscript.py real0m31,806s user0m1,936s sys0m0,073s
asyncio 介紹
我們知道我們可以做得更好。如果我們同時執行所有請求,它應該花費更少時間,對吧?也許會和執行最慢的請求所花費的時間相等。
并發確實應該運行得更快,但它也涉及一些開銷。所以這不是線性的數學改進。
為此,我們將使用上面提到的 asyncio。它允許我們在事件循環中的同一個線程上運行多個任務(就像 Javascript 一樣)。它將運行一個函數,并在運行時允許時將上下文切換到不同的上下文。在我們的例子中,HTTP 請求允許這種切換。
我們將開始看到一個 sleep 一秒鐘的示例。并且腳本應該需要一秒鐘才能運行。請注意,我們不能直接調用 main。我們需要讓 asyncio 知道它是一個需要執行的異步函數。
importasyncio
asyncdefmain():
print("Hello...")
awaitasyncio.sleep(1)
print("...World!")
asyncio.run(main())
timepythonscript.py Hello... ...World! real0m1,054s user0m0,045s sys0m0,008s
簡單的并行代碼
接下來,我們將擴展一個示例案例來運行一百個函數。它們每個都會 sleep 一秒鐘并打印一個文本。如果我們按順序運行它們大約需要一百秒。使用 asyncio,只需要一秒!
這就是并發背后的力量。如前所述,對于純 I/O 密集型任務,它將執行得更快 - sleep 不是,但它對示例很重要。
我們需要創建一個輔助函數,它會 sleep 一秒鐘并打印一條消息。然后,我們編輯 main 以調用該函數一百次,并將每個調用存儲在一個任務列表中。最后也是關鍵的部分是執行并等待所有任務完成。這就是 asyncio.gather[4] 所做的事情。
importasyncio
asyncdefdemo_function(i):
awaitasyncio.sleep(1)
print(f"Hello{i}")
asyncdefmain():
tasks=[
demo_function(i)
foriinrange(0,100)
]
awaitasyncio.gather(*tasks)
asyncio.run(main())
正如預期的那樣,一百條消息和一秒鐘的執行時間。完美!
使用 asyncio 進行抓取
我們需要將這些知識應用于數據抓取。遵循的方法是同時請求并返回產品列表,并在所有請求完成后存儲它們。每次請求后或者分批保存數據可能會更好,以避免實際情況下的數據丟失。
我們的第一次嘗試不會有并發限制,所以使用時要小心。在使用數千個 URL 運行它的情況下......好吧,它幾乎會同時執行所有這些請求。這可能會給服務器帶來巨大的負載,并可能會損害您的計算機。
requests 不支持開箱即用的異步,因此我們將使用 aiohttp[5] 來避免復雜化。 requests 可以完成這項工作,并且沒有實質性的性能差異。但是使用 aiohttp 代碼更具可讀性。
importasyncio importaiohttp frombs4importBeautifulSoup asyncdefextract_details(page,session): #similartorequests.getbutwithadifferentsyntax asyncwithsession.get(f"{base_url}/{page}/")asresponse: #noticethatwemustawaitthe.text()function soup=BeautifulSoup(awaitresponse.text(),"html.parser") #[...]sameasbefore returnpokemon_list asyncdefmain(): #createanaiohttpsessionandpassittoeachfunctionexecution asyncwithaiohttp.ClientSession()assession: tasks=[ extract_details(page,session) forpageinpages ] list_of_lists=awaitasyncio.gather(*tasks) store_results(list_of_lists) asyncio.run(main())
CSV 文件應該像以前一樣包含每個產品的信息 (共 755 個)。由于我們同時執行所有頁面調用,結果不會按順序到達。如果我們將結果添加到 extract_details 內的文件中,它們可能是無序的。但我們會等待所有任務完成然后處理它們,因此順序性不會有太大影響。
timepythonscript.py real0m11,442s user0m1,332s sys0m0,060s
我們做到了!速度提升了 3 倍,但是……不應該是 40 倍嗎?沒那么簡單。許多因素都會影響性能(網絡、CPU、RAM 等)。
在這個演示頁面中,我們注意到當執行多個調用時,響應時間會變慢,這可能是設計使然。一些服務器/提供商可以限制并發請求的數量,以避免來自同一 IP 的過多流量。它不是一種阻塞,而是一個隊列。你會得到服務響應,但需要稍等片刻。
要查看真正的加速,您可以針對延遲[6]頁面進行測試。這是另一個測試頁面,它將等待 2 秒然后返回響應。
base_url="https://httpbin.org/delay/2" #... asyncdefextract_details(page,session): asyncwithsession.get(base_url)asresponse: #...
這里去掉了所有的提取和存儲邏輯,只調用了延遲 URL 48 次,并在 3 秒內運行完畢。
timepythonscript.py real0m2,865s user0m0,245s sys0m0,031s
使用信號量限制并發
如上所述,我們應該限制并發請求的數量,尤其是針對單個域名。
asyncio 帶有 Semaphore[7],一個將獲取和釋放鎖的對象。它的內部功能將阻塞一些調用,直到獲得鎖,從而創建最大的并發性。
我們需要創建盡可能最大值的信號量。然后等待提取函數運行,直到 async with sem 可用。
max_concurrency=3
sem=asyncio.Semaphore(max_concurrency)
asyncdefextract_details(page,session):
asyncwithsem:#semaphorelimitsnumofsimultaneousdownloads
asyncwithsession.get(f"{base_url}/{page}/")asresponse:
#...
asyncdefmain():
#...
loop=asyncio.get_event_loop()
loop.run_until_complete(main())
它完成了工作,并且相對容易實現!這是最大并發設置為 3 的輸出。
timepythonscript.py real0m13,062s user0m1,455s sys0m0,047s
這表明無限并發的版本并沒有全速運行。如果我們將限制增加到 10,總時間與未限制的腳本運行時間相近。
使用 TCPConnector 限制并發
aiohttp 提供了一種替代解決方案,可提供進一步的配置。我們可以創建傳入自定義 TCPConnector[8] 的客戶端會話。
我們可以使用兩個適合我們需求的參數來構建它:
limit - “同時連接的總數”。
limit_per_host - “限制同時連接到同一端點的連接數”(同一主機、端口和 is_ssl)。
max_concurrency=10 max_concurrency_per_host=3 asyncdefmain(): connector=aiohttp.TCPConnector(limit=max_concurrency,limit_per_host=max_concurrency_per_host) asyncwithaiohttp.ClientSession(connector=connector)assession: #... asyncio.run(main())
這種寫法也易于實施和維護!這是每個主機最大并發設置為 3 的輸出。
timepythonscript.py real0m16,188s user0m1,311s sys0m0,065s
與 Semaphore 相比的優勢是可以選擇限制每個域的并發調用和請求的總量。我們可以使用同一個會話來抓取不同的站點,每個站點都有自己的限制。
缺點是它看起來有點慢。需要針對真實案例,使用更多頁面和實際數據運行一些測試。
multiprocessing
就像我們之前看到的那樣,數據抓取是 I/O 密集型的。但是,如果我們需要將它與一些 CPU 密集型計算混合怎么辦?為了測試這種情況,我們將使用一個函數,該函數將在每個抓取的頁面之后 count_a_lot。這是強制 CPU 忙碌一段時間的簡單(且有些愚蠢)的方法。
defcount_a_lot(): count_to=100_000_000 counter=0 whilecounter
對于 asyncio 版本,只需像以前一樣運行它。可能需要很長時間。
timepythonscript.py real2m37,827s user2m35,586s sys0m0,244s
現在,比較難理解的部分來了:
直接引入 multiprocessing 看起來有點困難。實際上,我們需要創建一個 ProcessPoolExecutor,它能夠“使用一個進程池來異步執行調用”。它將處理不同 CPU 中每個進程的創建和控制。
但它不會分配負載。為此,我們將使用 NumPy 的 array_split,它會根據 CPU 的數量將頁面范圍分割成相等的塊。
main 函數的其余部分類似于 asyncio 版本,但更改了一些語法以匹配 multiprocessing 的語法風格。
此處的本質區別是我們不會直接調用extract_details。實際上是可以的,但我們將嘗試通過將 multiprocessing 與 asyncio 混合使用來獲得最好的執行效率。
fromconcurrent.futuresimportProcessPoolExecutor frommultiprocessingimportcpu_count importnumpyasnp num_cores=cpu_count()#numberofCPUcores defmain(): executor=ProcessPoolExecutor(max_workers=num_cores) tasks=[ executor.submit(asyncio_wrapper,pages_for_task) forpages_for_taskinnp.array_split(pages,num_cores) ] doneTasks,_=concurrent.futures.wait(tasks) results=[ item.result() foritemindoneTasks ] store_results(results) main()
長話短說,每個 CPU 進程都會有幾頁需要抓取。一共有 48 個頁面,假設你的機器有 8 個 CPU,每個進程將請求 6 個頁面(6 * 8 = 48)。
這六個頁面將同時運行!之后,計算將不得不等待,因為它們是 CPU 密集型的。但是我們有很多 CPU,所以它們應該比純 asyncio 版本運行得更快。
asyncdefextract_details_task(pages_for_task): asyncwithaiohttp.ClientSession()assession: tasks=[ extract_details(page,session) forpageinpages_for_task ] list_of_lists=awaitasyncio.gather(*tasks) returnsum(list_of_lists,[]) defasyncio_wrapper(pages_for_task): returnasyncio.run(extract_details_task(pages_for_task))
這就是神奇的地方。每個 CPU 進程將使用頁面的子集啟動一個 asyncio(例如,第一個頁面從 1 到 6)。
然后,每一個都將調用幾個 URL,使用已知的 extract_details 函數。
上述內容需要花點時間來吸收它。整個過程是這樣的:
創建執行器
拆分頁面
每個進程啟動 asyncio
創建一個 aiohttp 會話并創建頁面子集的任務
提取每一頁的數據
合并并存儲結果
下面是本次的執行時間。雖然之前我們沒有提到它,但這里的 user 時間卻很顯眼。對于僅運行 asyncio 的腳本:
timepythonscript.py real2m37,827s user2m35,586s sys0m0,244s
具有 asyncio 和多個進程的版本:
timepythonscript.py real0m38,048s user3m3,147s sys0m0,532s
發現區別了嗎?實際運行時間方面第一個用了兩分鐘多,第二個用了 40 秒。但是在總 CPU 時間(user 時間)中,第二個超過了三分鐘!看起來系統開銷的耗時確實有點多。
這表明并行處理“浪費”了更多時間,但程序是提前完成的。顯然,您在決定選擇哪種方法時,需要考慮到開發和調試的復雜度。
結論
我們已經看到 asyncio 足以用于抓取,因為大部分運行時間都用于網絡請求,這種場景屬于 I/O 密集型并且適用于單核中的并發處理。
如果收集的數據需要一些 CPU 密集型工作,這種情況就會改變。雖然有關計數的例子有一點愚蠢,但至少你理解了這種場景。
在大多數情況下,帶有 aiohttp 的 asyncio 比異步的 requests 更適合完成目標工作。同時我們可以添加自定義連接器以限制每個域名的請求數、并發請求總數。有了這三個部分,您就可以開始構建一個可以擴展的數據抓取程序了。
審核編輯:彭靜
-
數據
+關注
關注
8文章
7079瀏覽量
89165 -
服務器
+關注
關注
12文章
9225瀏覽量
85616 -
網頁
+關注
關注
0文章
73瀏覽量
19335 -
python
+關注
關注
56文章
4798瀏覽量
84800
原文標題:抓取速度提升 3 倍!Python 的這個內置庫你用上了嗎?
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
labview與IE瀏覽器如何通過網頁name值進行網頁數據交互
使用curl+wget抓取網頁方法
通過html控件讀取網頁數據的控件在哪里?
labview抓取網頁的數據和賣家庫存采集工具mshtml應用
labview的網絡蜘蛛的實現(post請求,非python)
Python爬蟲簡介與軟件配置
網頁抓取之Headless Chrome技巧
Python網頁爬蟲,文本處理,科學計算,機器學習和數據挖掘工具集

用Python寫個小工具網頁
如何在Python中使用MQTT






 工商網監
工商網監
評論