 Linux內核的內存屏障的原理和用法分析
Linux內核的內存屏障的原理和用法分析
圈里流傳著一句話“珍愛生命,遠離屏障”,這足以說明內存屏障是一個相當晦澀和難以準確把握的東西。使用過弱的屏障,會導致軟件不穩定。使用過強的屏障,會引起性能問題。所以工程上,追求恰到好處、不偏不倚的屏障。本文力求用最淺顯的語言,講清楚內存屏障最晦澀的道理,本文也會給出五個工程案例,這些案例皆見于開源的代碼,不涉及任何組織和個人未公開的技術。
一、引子
我國古代著名程序猿韓愈曾經寫下一個名為《春雪》的函數:
新年都未有芳華,二月初驚見草芽。
白雪卻嫌春色晚,故穿庭樹作飛花。
這段代碼講述了一個關于memory reorder的故事,在計算機世界里面,冬天和春天并沒有明確的界限,明明已經是春天了,但是還飄著冬天的雪。
下面我們看另外一段程序:

我們能確保c = 4嗎?實際上,任何一個角度都確定不了。比如CPU0上面a = 3是“下雪”,flag = 1是“春天”,a=3看似在flag=1之前,實際可能由于memory reorder的原因發生在flag = 1之后,所以flag即便已經等于1,a也不一定等于3。
我們再退一萬步講,哪怕CPU0上面確實確保了春天不下雪,flag=1的時候a 100%就等于了3,那CPU1那邊就萬無一失了嗎?答案也是否定的,因為,在CPU1上面,即便我們的代碼是if(flag==1),接下來才做c=a+1,我們也不能確保a的load一定發生在flag==1之后。別忘了,CPU1會投機執行,比如碰到if(flag==1)這種條件,CPU可能直接忽略,不管三七二十一,還是可能先執行 load a, a+1的動作,然后反過來發現flag等于1,然后我認為我的投機是成功的;即便投機失敗,CPU只需要保證load a, a+1的這些指令不retired就好。所以CPU1的load a, a+1完全可能發生在flag確切地等于1之前,因此即便CPU0保序了,CPU1仍然不能確保c=4。
我們看看CPU1在投機成功時候的行為邏輯和思想情感:
1. flag==1嗎?
2. 不知道啊!我現在還沒讀出flag呢!
3. 管它呢,先假裝flag==1吧,投機一把,執行loada, 把a+1看看
4.flag==1嗎?哇,它真地等于1,太爽了,load a和a+1已經做完了。
如果投機失敗了呢?
1. flag==1嗎?
2.不知道啊!我現在還沒讀出flag呢!
3. 管它呢,先假裝flag==1吧,投機一把,執行loada, 把a+1看看
4. flag==1嗎?Oh,shit,它不等于1,load a, a+1白做了.....
這就是弱序系統的典型特點。請問CPU為什么要這么“混亂”?這正是現代CPU為了保證高效執行厲害的地方,但是也引入軟件使用上的復雜度。這種復雜度,類似于宋代著名程序媛李清照的函數《聲聲慢·尋尋覓覓》:“尋尋覓覓,冷冷清清,凄凄慘慘戚戚。乍暖還寒時候,最難將息。三杯兩盞淡酒,怎敵他、晚來風急?雁過也,正傷心,卻是舊時相識。滿地黃花堆積,憔悴損,如今有誰堪摘?守著窗兒,獨自怎生得黑。梧桐更兼細雨,到黃昏、點點滴滴。這次第,怎一個愁字了得!”請問李清照童鞋說的究竟是春天還是秋天還是春天呢?據說至今也沒有人能夠解密。僅憑“乍暖還寒”一定會覺得是初春,但是你再繼續看到“雁過也”、“滿地黃花堆積”,這顯然又不是春天的景象。
罷了罷了,這一切都不重要了,重要的是,四季并不分明,四季沒有明確的界限。這是我們要牢記的第一個point!
二、屏障
正是因為四季沒有明確的界限,所以當我們希望看到明確的順序的時候,我們希望引入一道屏障。讓冬天跑不到春天,讓春天跑不過去冬天。
典型的ARM64有這么幾種屏障:
a. DMB:Data Memory Barrier
b. DSB:Data Synchronization Barrier
c. ISB:Instruction Synchronization Barrier
d. LDAR(Load-Acquire)/STLR(Store-Release)
我們隨便打開ARM的手冊,看一個DMB的定義:
The Data Memory Barrier (DMB) prevents the reordering of specified explicit data accesses acrossthe barrier instruction. All explicit data load or store instructions, which are executed by the PEin program order before the DMB, are observed by all Observers within a specified Shareabilitydomain before the data accesses after the DMB in program order.
碼農的內心是崩潰的,人生已經這么悲催了,你為什么還要拿這樣的繞口令來折磨我?什么叫“are observed by all Observers”?
下面我們給大家講述2只狗狗出家門的故事:
上圖的2只狗,首先在一個inner shareable domain里面,比如是自己的家門里面;然后是在一個outer shareable domain里面,比如是小區的出口;最后在太陽系里面。這2只小狗,出每一道門,都有observer可以看見它,有的observer是inner的(observer1),有的observer是outer的(observer2),有的observer屬于full system,比如天上的嫦娥(observer3)。
現在我們提出如下需求:
a. 黃狗狗出門后白狗狗出門。
b. 黃狗狗和白狗狗出門后,放煙霧消殺。
當我們提出這樣的需求的時候,我們看3樣東西:
1. 我們首先要看需要保證順序的2個事物的特征
在需求1里面,是2只特征一樣的東西,都是狗狗;在需求2里面,兩個事物之間一個是狗狗,一個是消殺的煙霧,顯然不是同類。
狗狗在硬件和Linux軟件層面上,可以理解為針對內存的memory load/store指令;放煙霧,這種不屬于memory的load/store,比如你執行的是tlbi、add加法或者寫的是ARM64系統寄存器(MSR指令),則顯然不屬于memory load/store。
這里就涉及到DMB和DSB的一個本質區別,DMB針對的是memory的load/store之間;DSB強調的是同類或不同類事物的先后完成。
所以對于這個場景,我們正確的屏障是:
load黃狗狗
dmb ??
load白狗狗
dsb ??
MSR消毒煙霧
第一個是dmb,第2個是dsb。上面dmb和dsb后面都加了兩個“?”,證明這里有情況,什么情況?接著看。
2. 其次我們要看保序的observer在哪里
比如是家門口的小姑娘observer1(ISH,inner shareable)、還是小區門口的小姑娘observer2(OSH,outer shareable),還是天上的嫦娥呢(SY, Full System)?如果只是observer1看到黃狗狗先出門,白狗狗再出門,延遲顯然更小。在越大的訪問范圍保序,硬件的延遲越大。假設我們現在的保序需求是:
a. 小區門口(outer shareable)的observer2先看到黃狗狗出來,再看到白狗狗出來;
b. 家門口(inner shareable)的observer1先看到兩只狗狗出來,再看到放煙霧。
對于這個場景,我們正確的屏障是:
load黃狗狗
dmb OSH?
load白狗狗
dsb ISH?
MSR消毒煙霧
在DMB后面我們跟的是OSH,在DSB后面我們跟的是ISH,是因為observer的位置不一樣。注意,能用小observer的不用大observer。小區門口的observer,沒有透視眼+望遠鏡,是看不到你家門口的狗狗的。
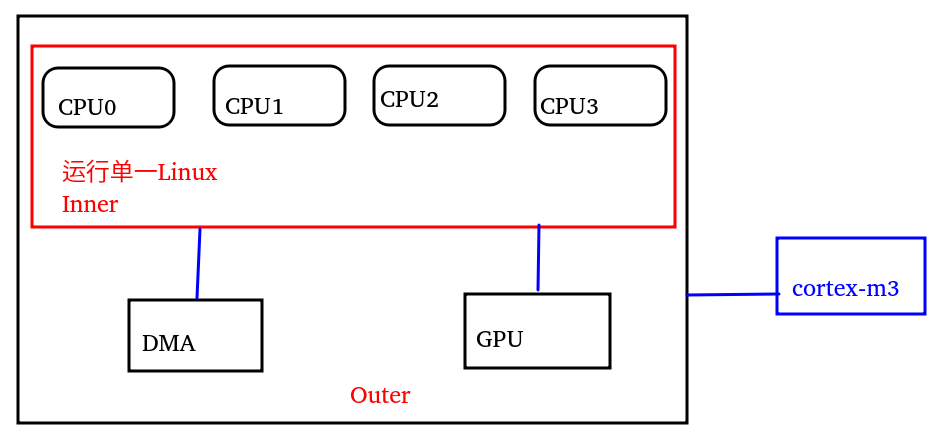
在一個典型的ARM64系統里面,運行Linux的各個CPU在一個inner;而GPU,DMA和CPU則同位于一個outer;當然還有可能孤懸海外的一個Cortex-M3的MCU,盡管可以和CPU以某種方式通信,但是不太參與inner以及outer里面的總線interconnect。
3. 最后我們保序的方向是什么
前面我們只關心狗狗的出門(load),假設兩只狗狗都是進門(store)呢?或者我們現在要求黃狗狗先進門,白狗狗再出門呢?這個時候,我們要約束屏障的方向。
比如下面的代碼,約束了observer1(inner)先看到黃狗狗出門,再看到白狗狗出門:
load黃狗狗
dmb ISHLD
load白狗狗
比如下面的代碼,約束了observer2(outer)先看到黃狗狗進門,再看到白狗狗進門:
store黃狗狗
dmb OSHST
store白狗狗
這里我們看到一個用的是LD,一個用的是ST。我們再來看幾個栗子,它們都是干什么的:
a.A(load); dmb ISHLD; B; C(load/store)
保證Inner內,A和C的順序,只要A是load,無論C是load還是store;如果B既不是load也不是store,而是別的性質的事情,則dmb完全管不到B;
b. A(load); dsb ISHLD; B; C(load/store)
保證Inner內,A和C的順序,只要A是load,無論C是load還是store;無論B是什么事情,inner都先到干完了A,再干B(注意這里是dsb啊,親)。
c. A(store); dmb ISHLD; B; C(store)
A,B,C三個東西完全亂序,因為dmb約束不了性質不同的B,“LD”約束不了A和C的store順序。
d. A(store); dmb ISHST; B; C(store)
ST約束了A和C 2個東西在inner這里看起來是順序的,因為dmb約束不了B,所以B和A、C之間亂序。
注意上述4個屏障,由于都是ISH,故都不能保證observer2和observer3的順序,在observer2和3眼里,上述所有屏障,A、B、C都是亂序的。
另外,如果無論什么方向,我們都要保序,我們可以去掉LD和ST,這樣的保序方向是any-any。
到這里我們要牢記3個point:誰和誰保序;在哪里保序;朝哪個方向保序。
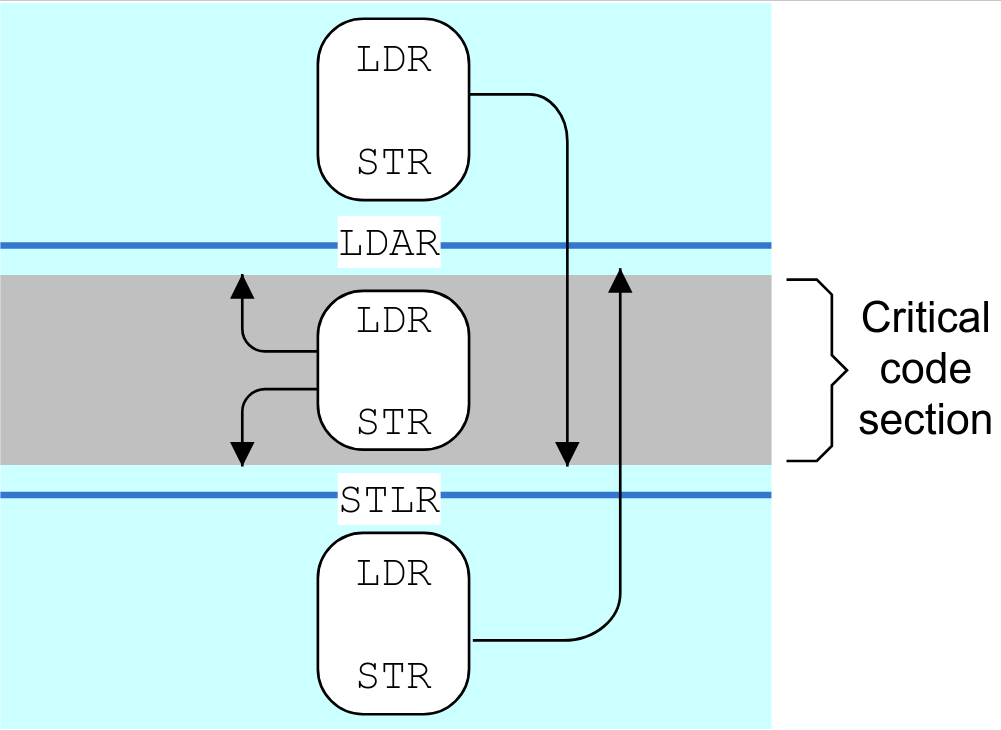
由此,我們可以清楚地看到DMB和DSB的區別,一個是保序內存load,store;一個是保序內存load,store + 其他指令。ISB的性質會有很大的不同,ISB主要用于刷新處理器中的pipeline,因此可確保在 ISB 指令完成后,才從內存系統中fetch位于該指令后的其他指令。比如你更新了代碼段的PTE,需要重新取指。而LDAR(Load-Acquire)/STLR(Store-Release)則是比較新的one-way barrier。如下圖,LDAR之前的LDR、STR可以跑到LDAR之后,但是不能跑到STLR之后;STLR之后的LDR,STR可以跑到STLR之前,但是不能跑到LDAR之前。所以STLR堵住了前面的往后面跑,LDAR堵住了后面的往前面跑。下面夾在LDAR和STLR之間的LDR,STR由于兩邊都是單向車道,而且都與它的行進方向相反,所以它夾在死胡同里,哪里也去不了。
注意,LDAR和STLR與前面的dmb, dsb有本質的不同,它本身是要跟地址的。比如現在家里有3只狗狗:
假設我們現在的要求是黃狗狗一定要在紅尾哈巴狗之后出門,而白狗狗什么時候出我們都不在乎,則代碼邏輯為:
ldr 白狗狗
ldar紅尾哈巴狗
ldr 黃狗狗
黃狗狗被紅尾哈巴狗的ldar擋住了,而白狗狗沒有被任何東西擋住,它可以:
1. 第一個出門
2. 紅尾哈巴狗出門后,黃狗狗出門前出門
3. 最后一個出門。
三、API
在Linux內核,有4組經典API:
SMP屏障
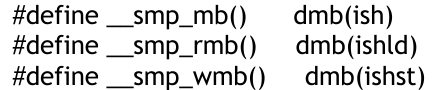
此屏障主要用于運行Linux的多個核之間對內存訪問的保序,所以它主要是dmb,它是ish,通過ld、st來區分保序的方向。
DMA屏障

此屏障主要用于運行Linux的多個核與DMA引擎之間的保序,所以它主要是dmb,它是osh,通過ld、st來區分保序的方向。
屏障

非常嚴格的完成屏障,mb()保證了前面的指令的完成,前面的指令不必是load,store,比如可以是TLBI。dsb(ld)、dsb(st)則要弱一點,分別保證前面的load,store執行完了才執行后面的指令。
load_acquire/store_release
邏輯通常是一種成對的__smp_load_acquire()、__smp_store_release()邏輯,特別適合2個或者多個CPU之間的鏈式保序。在ARM64里面用的是stlr,ldar實現如下:

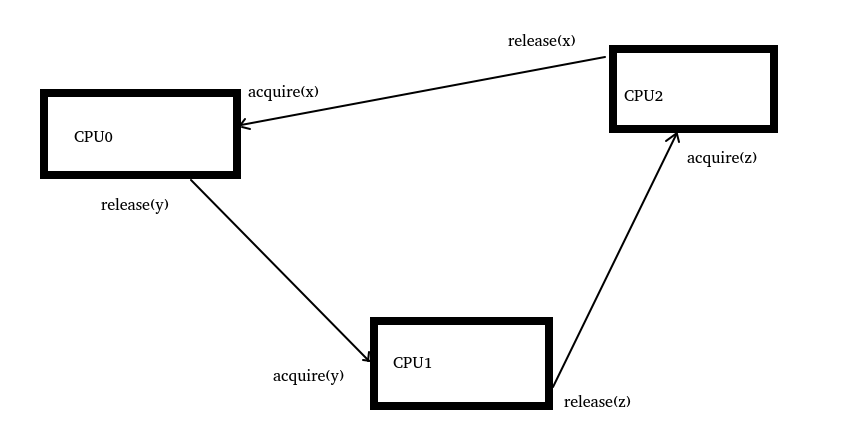
比如,下面的代碼邏輯,保證了CPU0、CPU1、CPU2這3個CPU在鏈條上保序訪問:

中間循環了一個鏈條邏輯,從而保證了這三個CPU中間內存訪問的一些保序:
下面我們進入五個工程實戰,“熟讀唐詩三百首,不會吟詩也會吟”,最后我們會形成針對內存屏障正確用法的語感,而全然忘記語法。
實戰一:運行Linux的多核通過中斷通信
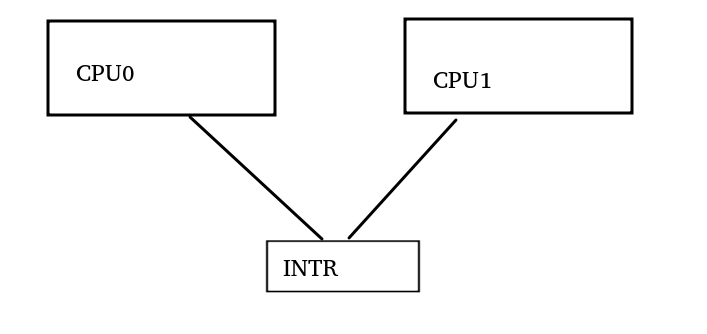
它的一般模式是:CPU0在DDR填入一段數據,然后通過store指令寫INTR的寄存器向CPU1發送中斷。
store數據
barrier?
store intr寄存器
中間應該用什么barrier?我們來回憶一下三要素:
a. 誰和誰保序?-> CPU0和CPU1這2個observer之間看到保序
b. 在哪里保序?-> 只需要CPU1看到CPU0寫入DDR和intr寄存器是保序的
c. 朝哪個方向保序?-> CPU0寫入一段數據,然后寫入intr寄存器,只需要在st方向保序。
由此,我們得出結論,應該使用的barrier是:dmb + ish + st,顯然就是smp_wmb。內核代碼drivers/irqchip/irq-bcm2836.c也可以證實這一點:
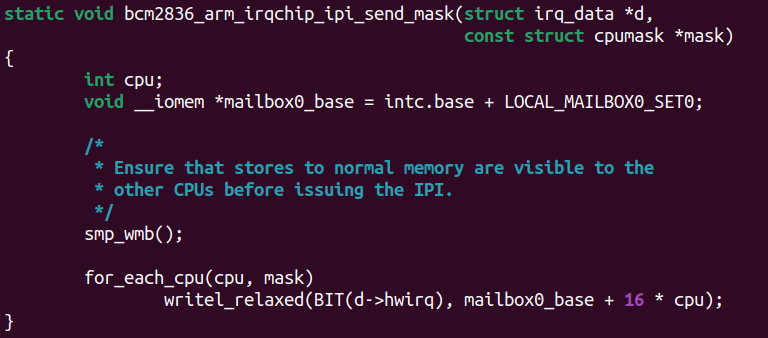
里面的注釋非常清晰,smp_wmb()保證了發起IPI之前,其他CPU應該先觀察到內存的數據在位。
現在我們把INTR換成gic-v3,就會變地tricky很多。gic-v3的IPI寄存器并不是映射到內存空間的,而是一個sys寄存器,通過MSR來寫入。前面我們說過DMB只能搞定load/store之間,搞不定load/store與其他東西之間。
最開始的gic-v3驅動的作者其實也誤用了smp_wmb,造成了該驅動的穩定性問題。于是Shanker Donthineni童鞋進行了一個修復,這個修復的commit如下:
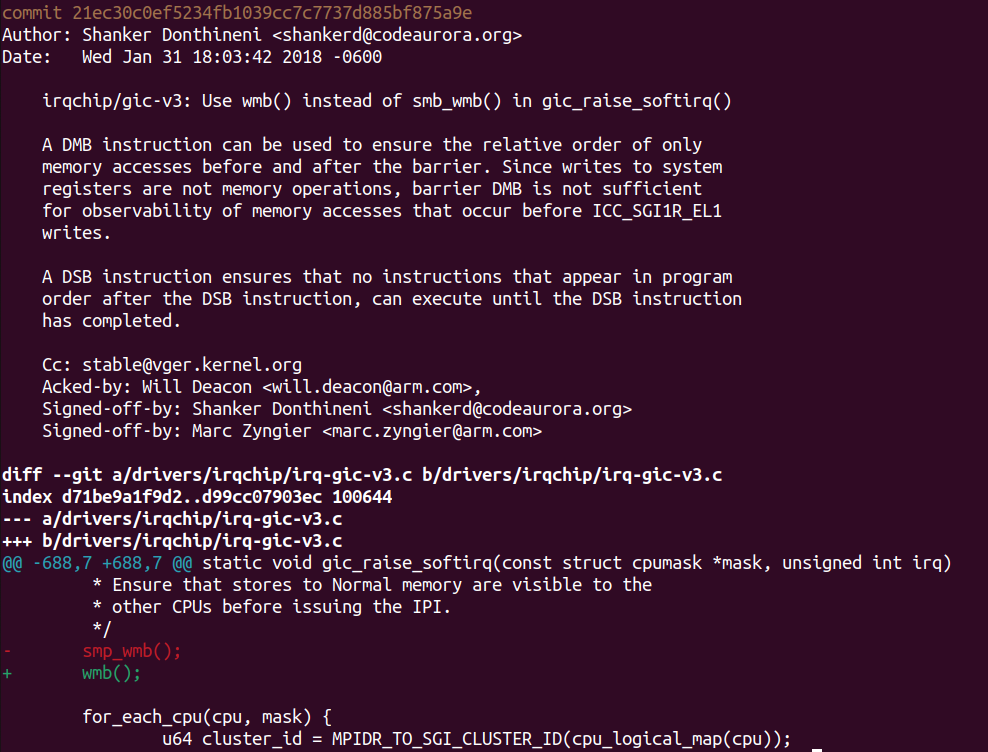
這個commit解釋了我們不能用dmb搞定memory和sysreg之間的事情,于是這個patch替換為了更強力的wmb(),那么這個替換是正確的嗎?
我們還是套一下三要素:
a. 誰和誰保序?-> CPU0和CPU1保序
b. 在哪里保序?-> 只需要CPU1看到CPU0寫入DDR后,再看到它寫sysreg
c. 朝哪個方向保序?-> CPU0寫入一段數據,然后寫入sysreg寄存器,只需要在st方向保序。
我們要進行保序的是CPU0和CPU1之間,顯然他們屬于inner。于是,我們得出正確的barrier應該是:dsb + ish + st,wmb()屬于用力過猛了,因為wmb = dsb(st),保序范圍是full system。基于此,筆者再次在主線內核對Shanker Donthineni童鞋的“修復”進行了“修復”,縮小屏障的范圍,提升性能:
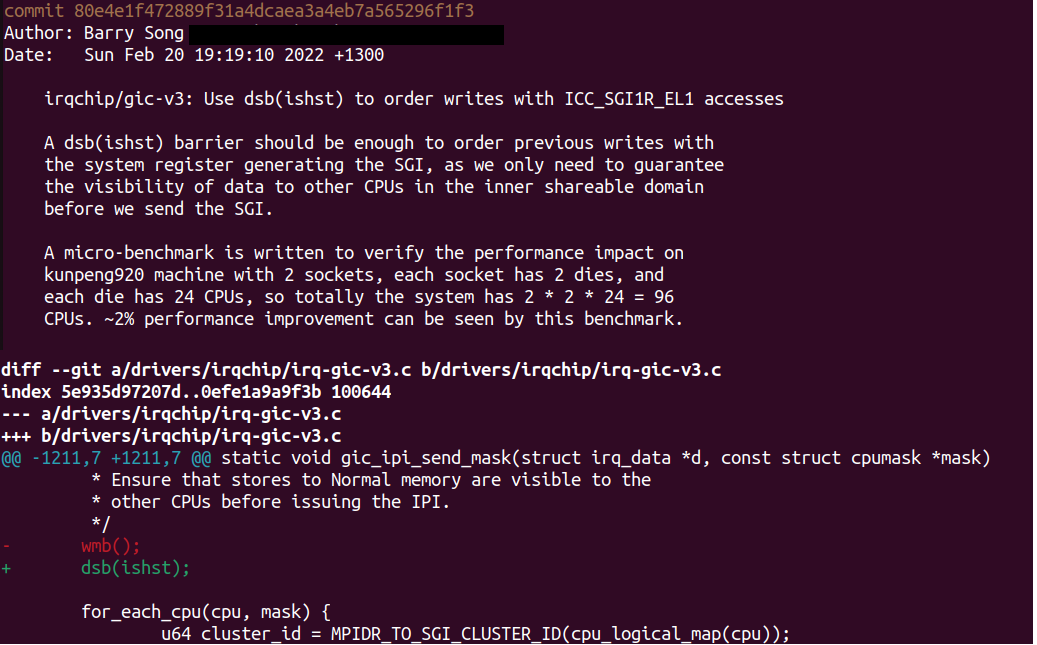
實戰二:寫入數據到內存后,發起DMA
下面我們把需求變更為,CPU寫入一段數據后,寫Ethernet控制器與CPU之間的doorbell,發起DMA操作發包。
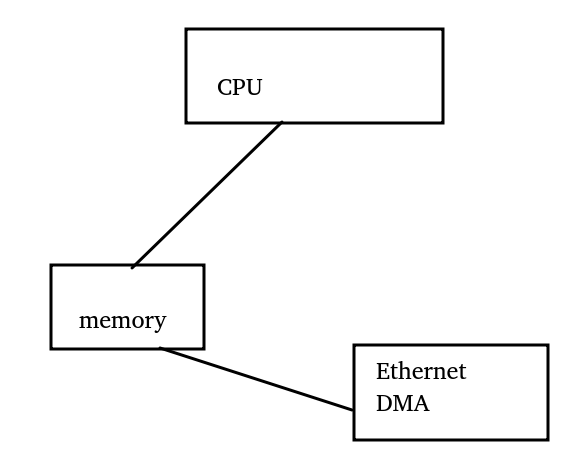
我們還是套一下三要素:
a. 誰和誰保序?-> CPU和EMAC的DMA保序,DMA和CPU顯然不是inner
b. 在哪里保序?-> 只需要EMAC的DMA看到CPU寫入發包數據后,再看到它寫doorbell
c. 朝哪個方向保序?-> CPU寫入一段數據,然后寫入doorbell,只需要在st方向保序。
于是,我們得出正確的barrier應該是:dmb + osh + st,為什么是dmb呢,因為doorbell也是store寫的。我們來看看Yunsheng Lin童鞋的這個commit,它把用力過猛的wmb(),替換成了用writel()來寫doorbell:
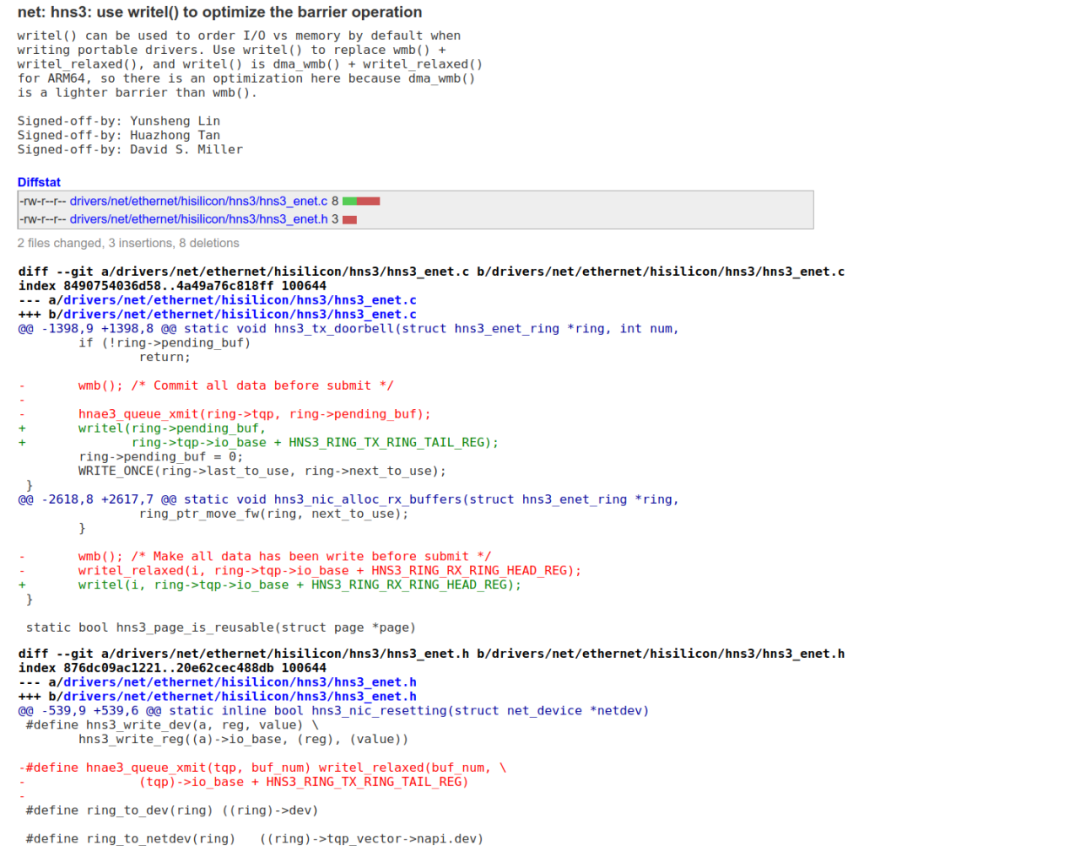
在ARM64平臺下,writel內嵌了一個dmb + osh + st,這個從代碼里面可以看出來:

同樣的邏輯也可能發生在CPU與其他outer組件之間,比如CPU與ARM64的SMMU:
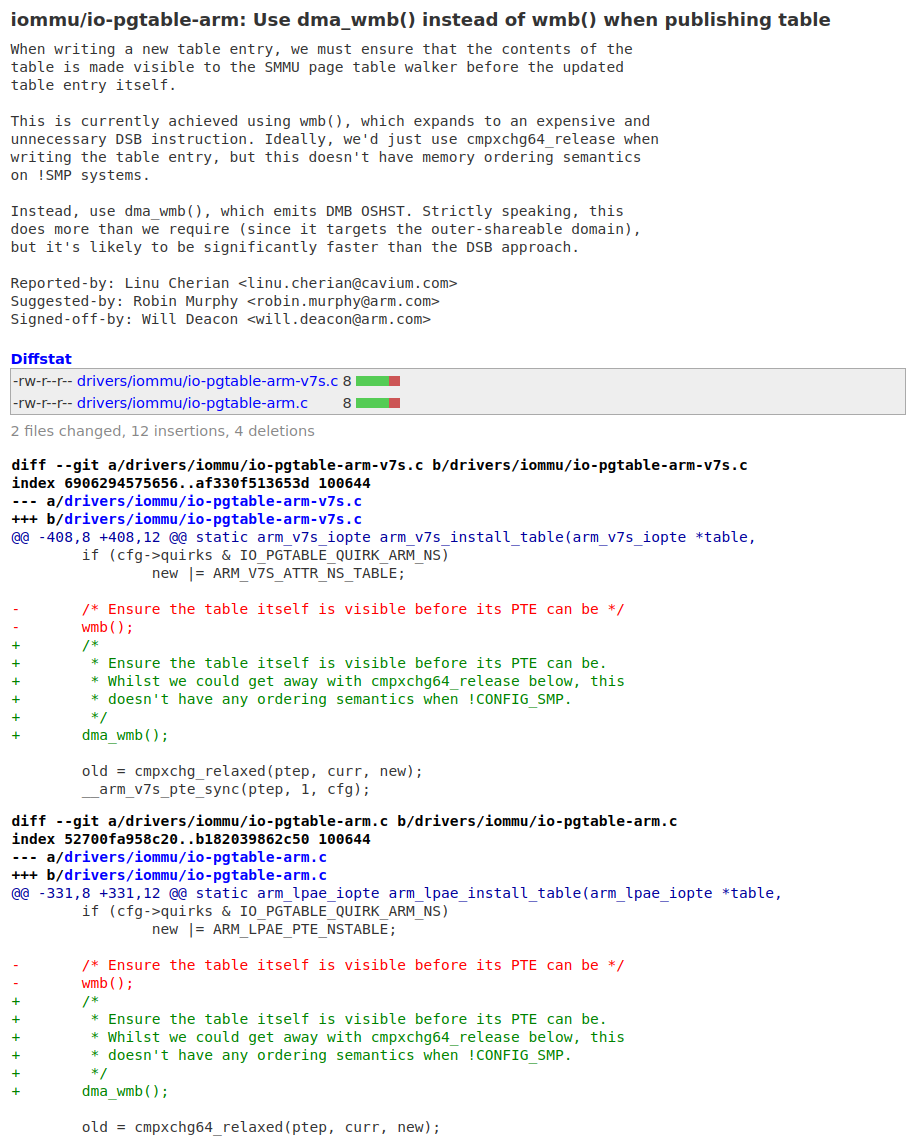
實戰三:CPU與MCU通過共享內存和hwspinlock通信
下面我們把場景變更為主CPU和另外一個cortex-m的MCU通過一片共享內存通信,對這片共享內存的訪問透過硬件里面自帶的hwspinlock(hardware spinlock)來解決。
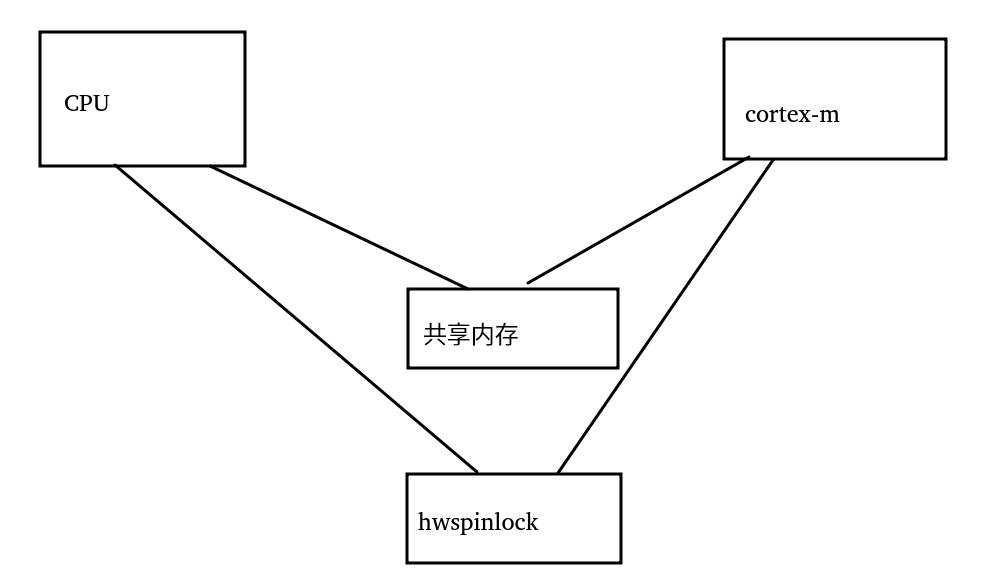
我們想象CPU持有了hwspinlock,然后讀取對方cortex-m給它寫入共享內存的數據,并寫入一些數據到共享內存,然后解鎖spinlock,通知cortex-m,這個時候cortex-m很快就可以持有鎖。
我們還是套一下三要素:
a. 誰和誰保序?-> CPU和Cortex-M保序
b. 在哪里保序?-> CPU讀寫共享內存后,寫入hwspinlock寄存器解鎖,需要cortex-m看到同樣的順序
c. 朝哪個方向保序?-> CPU讀寫數據,然后釋放hwspinlock,我們要保證,CPU的寫入對cortex-m可見;我們同時要保證,CPU放鎖前的共享內存讀已經完成,如果我們不能保證解鎖之前CPU的讀已經完成,cortex-m很可能馬上寫入新數據,然后CPU讀到新的數據。所以這個保序是雙向的。
Talk is cheap, show me the code:

里面用的是mb(),這是一個dsb+full system+ld+st,讀代碼的注釋也是一種享受。
實戰四:SMMU與CPU通過一個queue通信
現在我們把場景切換為,SMMU與CPU之間,通過一片放入共享內存的queue來通信,比如SMMU要通知CPU一些什么event,它會把event放入queue,放完了SMMU會更新另外一個pointer內存,表示queue增長到哪里了。
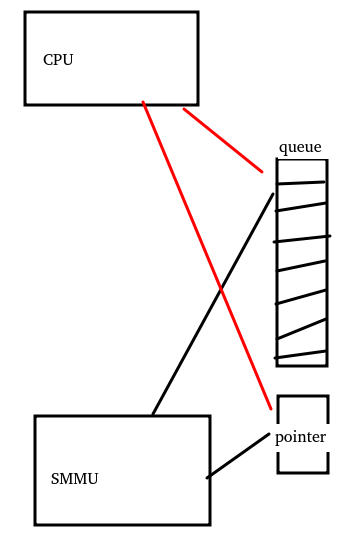
然后CPU通過這樣的邏輯來工作

這是一種典型的控制依賴,而控制依賴并不能被硬件自動保序,CPU完全可以在if(pointer滿足什么條件)滿足之前,投機load了queue的內容,從而load到了錯誤的queue內容。
我們還是套一下三要素:
a.誰和誰保序?-> CPU和SMMU保序
b.在哪里保序?-> 要保證CPU先讀取SMMU的pointer后,再讀取SMMU寫入的queue;
c.朝哪個方向保序?-> CPU讀pointer,再讀queue內容,在load方向保序
于是,我們得出正確的barrier應該是:dmb + osh + ld,我們來看看wangzhou童鞋的這個修復:

ARM64平臺的readl()也內嵌了dmb + osh + ld屏障。顯然這個修復的價值是非常大的,這是一個由弱變強的過程。前面我們說過,由強變弱是性能問題,而由弱變強則往往修復的是穩定性問題。也就是這種用錯了弱barrier的場景,往往bug非常難再現,需要很長時間的測試才再現一次。
實戰五:修改頁表PTE后刷新tlb
現在我們的故事演變成了,CPU0修改了頁表PTE,然后通知其他所有CPU,PTE應該被更新,其他CPU需要刷新TLB。
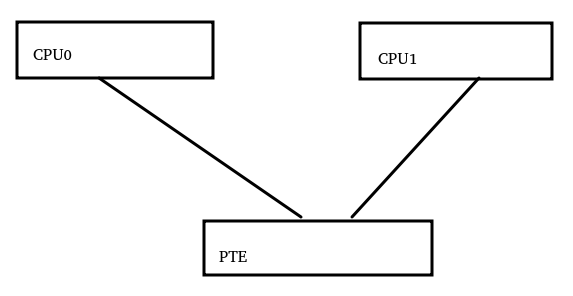
它的一般流程是CPU調用set_pte_at()修改了內存里面的PTE,然后進行tlbi等動作。這里就變地非常復雜了:

我們看看barrier1,它在屏障store和tlbi之間,由于二者一個是狗狗,一個是消殺煙霧,顯然不能是dmb,只能是dsb;我們需要CPU1看到set_pte_at的動作先于tlbi的動作,所以這個屏障的范圍應該是ISH;由于屏障需要保障的是set_pte_at的store,而不是load,所以方向是st,由此我們得出第一個barrier應該是:dsb + ish + st。
詳細的流程我們可以參考下如下代碼:

barrier2用的是dsb(ish),它保證了inner內的CPU都先看到了tlbi的完成;barrier3用的isb(),它保證了CPU fetch到PTE修正之后的指令。
結語
本文對Linux內核的內存屏障的原理和用法進行一些分析和實戰,它并未覆蓋內存屏障的全部知識,但是應該可應付工程里面90%以上的迷惘和困惑。由于作者水平有限,文中疏漏與錯誤在所難免,懇請讀者朋友們海涵。本文完成之時,北半球正在告別烈日炙烤的夏季,南半球即將迎來姹紫嫣紅的春天,愿所有人都有一個美好的未來。
-
cpu
+關注
關注
68文章
10873瀏覽量
212019 -
內存
+關注
關注
8文章
3029瀏覽量
74103 -
軟件
+關注
關注
69文章
4958瀏覽量
87614 -
LINUX內核
+關注
關注
1文章
316瀏覽量
21660
原文標題:原理和實戰解析Linux中如何正確地使用內存屏障
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從硬件引申出內存屏障,帶你深入了解Linux內核RCU
Linux的內存管理是什么,Linux的內存管理詳解
Linux內核之內存映射原理分析
ARM體系結構之內存序與內存屏障
Linux內核內存管理架構解析

Linux內核地址映射模型與Linux內核高端內存詳解
導致ARM內存屏障的原因究竟有哪些
內存屏障機制及內核相關源代碼分析
高端內存的詳解:linux用戶空間與內核空間
可以了解并學習Linux 內核的同步機制
干貨:Linux內核中等待隊列的四個用法
Linux內核源碼分析-進程的哪些內存類型容易引起內存泄漏?






 工商網監
工商網監
評論