 解決長尾和冷啟動問題的基本方法
解決長尾和冷啟動問題的基本方法
1什么是長尾問題
長尾問題一直是很多場景中最難優化的問題,特別是在推薦系統領域,長尾問題十分常見,卻很難優化。在推薦系統中,長尾問題指的是,某些實體在訓練數據中出現次數非常少,導致模型對這部分樣本打分效果很差。典型的場景包括,新用戶沒有幾條瀏覽行為,如何準確推薦用戶感興趣的內容;一些商品非常小眾,用戶反饋很少,如何對這些商品進行推薦等等。長尾在一個成熟的系統中往往服從二八定律,即20%的頭部實體貢獻了80%的數據,而剩余80%的實體只有20%的數據,實際場景中甚至比二八還要長尾。
長尾問題的難點主要體現在以下2點。首先,長尾實體的樣本量太少,模型很難學習這部分樣本的規律,例如用戶的embedding、商品的embedding等,都是需要大量數據學習的。其次,頭部樣本在數量上占絕對優勢,導致模型偏向擬合頭部樣本的規律,而尾部樣本的規律和頭部樣本可能有較大差異,導致模型在尾部樣本效果不好。
2如何解決長尾問題
那么,如何解決長尾問題呢?業內工作主要包括兩種核心優化方法。第一種方法是基于meta-learning解決長尾問題。剛才我們說到,長尾用戶或商品的數據量少,模型難學習,那么我們就讓模型具備在少量樣本上能學的比較好的能力就可以了。而meta-learning正是讓模型實現上述能力的方法。我在之前的文章Meta-learning核心思想及近年頂會3個優化方向中對meta-learning的核心思路進行了詳細介紹,感興趣的同學可以進一步深入閱讀。第二種方法是基于圖學習解決長尾問題。長尾部分的由于數據少無法學到良好的embedding,在圖學習中,可以利用豐富的鄰居節點信息對長尾實體的信息進行補充,進而學到更好的embedding。
下面,我們分別來看看基于meta-learning的方法和基于圖學習的方法解決長尾問題的典型工作。
3基于meta-learning的方法
基于meta-learning的長尾問題解決方法又可以分為兩種思路,一種是利用meta-learning生成長尾用戶或商品的良好embedding,另一種是利用meta-learning讓模型獲得在小樣本上的快速學習能力。這里分別介紹兩個思路的兩篇經典文章。
第一篇文章是Improving ctr predictions via learning to learn id embeddings(SIGIR 2019)。這篇文章主要場景是廣告的ctr預估,解決的問題是如何提升冷啟動廣告的預測效果。本文提出了基于meta-learning的冷啟動廣告embedding學習方法。首先將每個ad的ctr預測看成是meta-learning中一個獨立的任務。然后學習一個embedding生成器,生成器的輸入是廣告的特征,輸出embedding。整個過程利用meta-learning的思路進行學習,利用meta-learning中的support set和query set模擬一個冷啟動廣告生成embedding和使用embedding預測,進而優化embedding生成器。
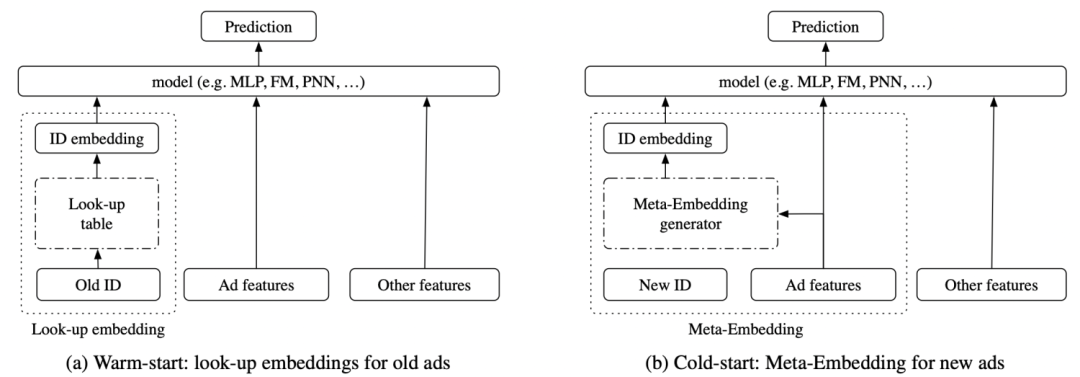
整個meta-learning的過程如下所示,在一個預訓練好的模型基礎上進行。隨機選擇一些廣告,生成兩個batch的數據。使用embedding生成器生成embedding后使用第一個batch計算loss,再利用這個loss更新一步生成器(內循環);然后使用更新后的生成器計算另一個batch上的loss(外循環),并更新最終參數。

第二篇文章是MeLU: meta-learned user preference estimator for cold-start recommendation(KDD 2019)。這篇文章主要也是借助了meta-learning讓模型具有快速學習能力,讓模型能夠在冷啟動樣本上,只看到少數幾個item就能進行快速的更新參數。
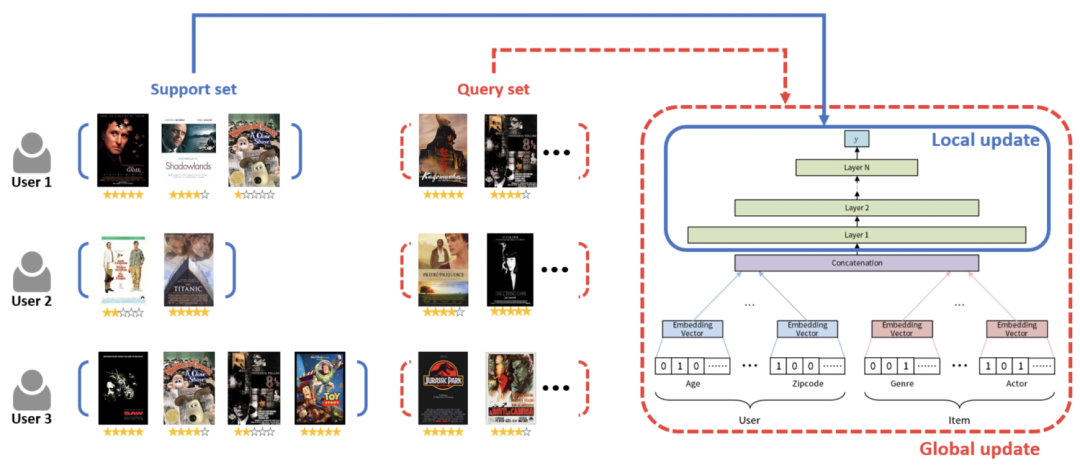
這篇文章重點解決的是user側的冷啟動問題,對于一個user的數據分成support set和query set,在support set內循環后在queryset評估效果并進行全局更新。embedding層不使用meta-learning,只在全連接層進行meta-learning。

4基于圖學習的方法
基于圖的學習方法通過圖建立不同實體之間的關系,進而可以用其他實體的信息豐富長尾實體的信息,緩解由于長尾導致的樣本不充分無法學習良好表示的問題。
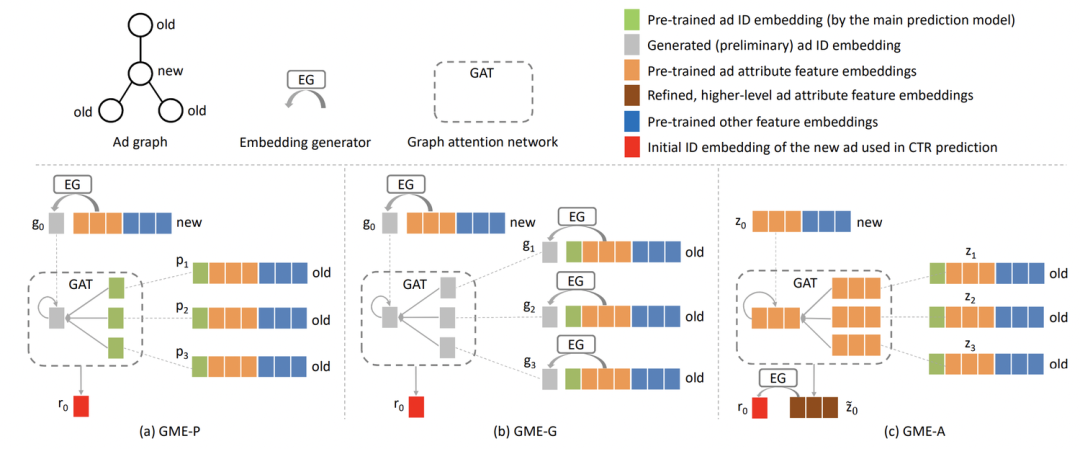
Learning Graph Meta Embeddings for Cold-Start Ads in Click-Through Rate Prediction(SIGIR 2021)利用圖學習解決新ad的embedding生成問題。對于新ad,使用屬性特征和圖學習生成一個合理的embedding。根據屬性重合度構造新ad的相似鄰居,并按照屬性的重合度排序,得到最相似的幾個ad。然后利用GAT進行new ad和其鄰居的信息融合,再用全連接生成新ad的向量表示,作為id embedding。這個過程相當于根據屬性找到與新ad最相似的舊ad,用舊ad的信息豐富新ad的embedding。在訓練方法上,先用舊ad訓練一個正常的ctr預估模型,然后固定ctr模型的參數,單獨訓練新ad表示生成部分的參數,利用meta-learning的方法更新模型參數。
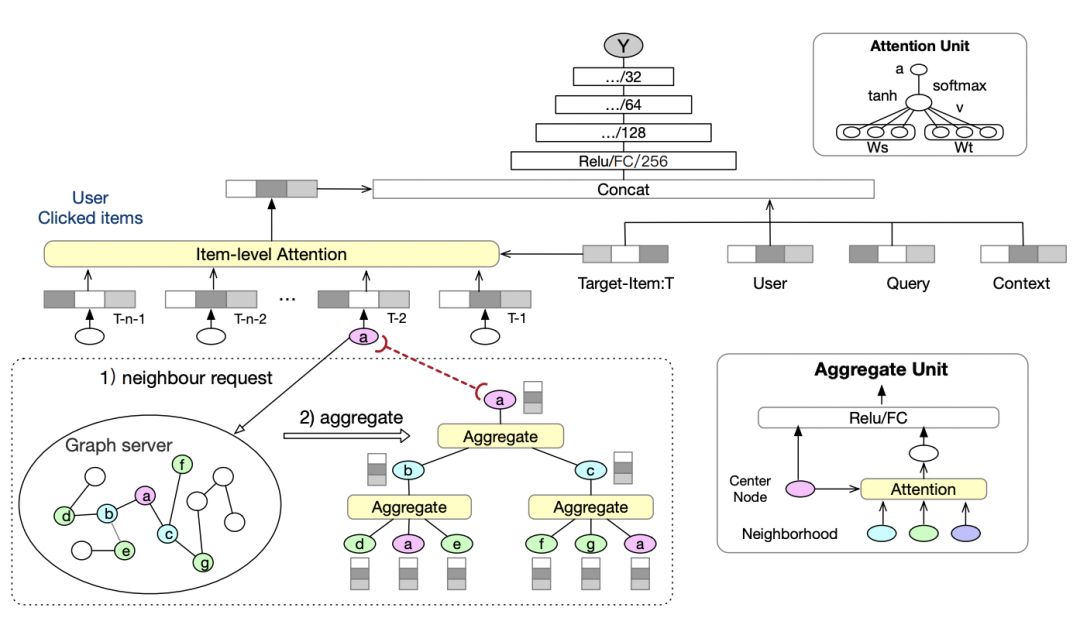
Graph Intention Network for Click-through Rate Prediction in Sponsored Search(SIGIR 2019)也是一篇比較有代表性的工作。CTR預估中經常需要對歷史行為建模提升效果(比如用戶歷史點擊過的商品),但是長尾用戶的歷史行為比較稀疏。因此這篇文章提出,利用點擊行為構造商品和商品之間的圖,利用這個圖補充歷史行為信息。通過商品-商品圖,可以挖掘出和當前商品高度相關的其他商品,這些商品雖然沒有直接的點擊行為,但由于和點擊過的商品高度相關,因此用戶點擊這些商品的概率可能也很高。通過這種基于圖擴展信息的方法,解決長尾用戶歷史行為稀疏的問題。
5總結
本文為大家介紹了解決長尾和冷啟動問題的基本方法,主要包括meta-learning和圖學習兩個路線。Meta-learning更側重于讓模型具有在小樣本上快速學習的能力;而圖學習更側重于挖掘和長尾實體相關的鄰居,用鄰居信息補充長尾實體的信息。
審核編輯 :李倩
-
數據
+關注
關注
8文章
7085瀏覽量
89204 -
模型
+關注
關注
1文章
3268瀏覽量
48926 -
生成器
+關注
關注
7文章
317瀏覽量
21053
原文標題:長尾預測效果不好怎么辦?試試這兩種思路
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何降低半導體制造無塵車間設備振動問題的影響?

USB驅動問題:設備無法識別的全面指南!
增加電容器設備是否可以解決電壓波動問題

AIC3254啟動過程是怎樣的?需要功能調節延時,請問怎么實現?
基于DPU的容器冷啟動加速解決方案
鼠籠式三相異步電動機啟動方法有什么啟動
如何選擇合適的電動機降壓啟動方法
bq05504冷啟動電壓600mV,在微弱光線下小型太陽能板達不到這么大怎么辦?
大功率電機啟動方法
TC3x CAN20在冷啟動復位時出現MTU故障怎么解決?
PMP31114.1-適合 3V 冷啟動的同步 SEPIC PCB layout 設計

PMP22063.1-具有熱/冷啟動功能的汽車儀表組和顯示電源 PCB layout 設計





 工商網監
工商網監
評論