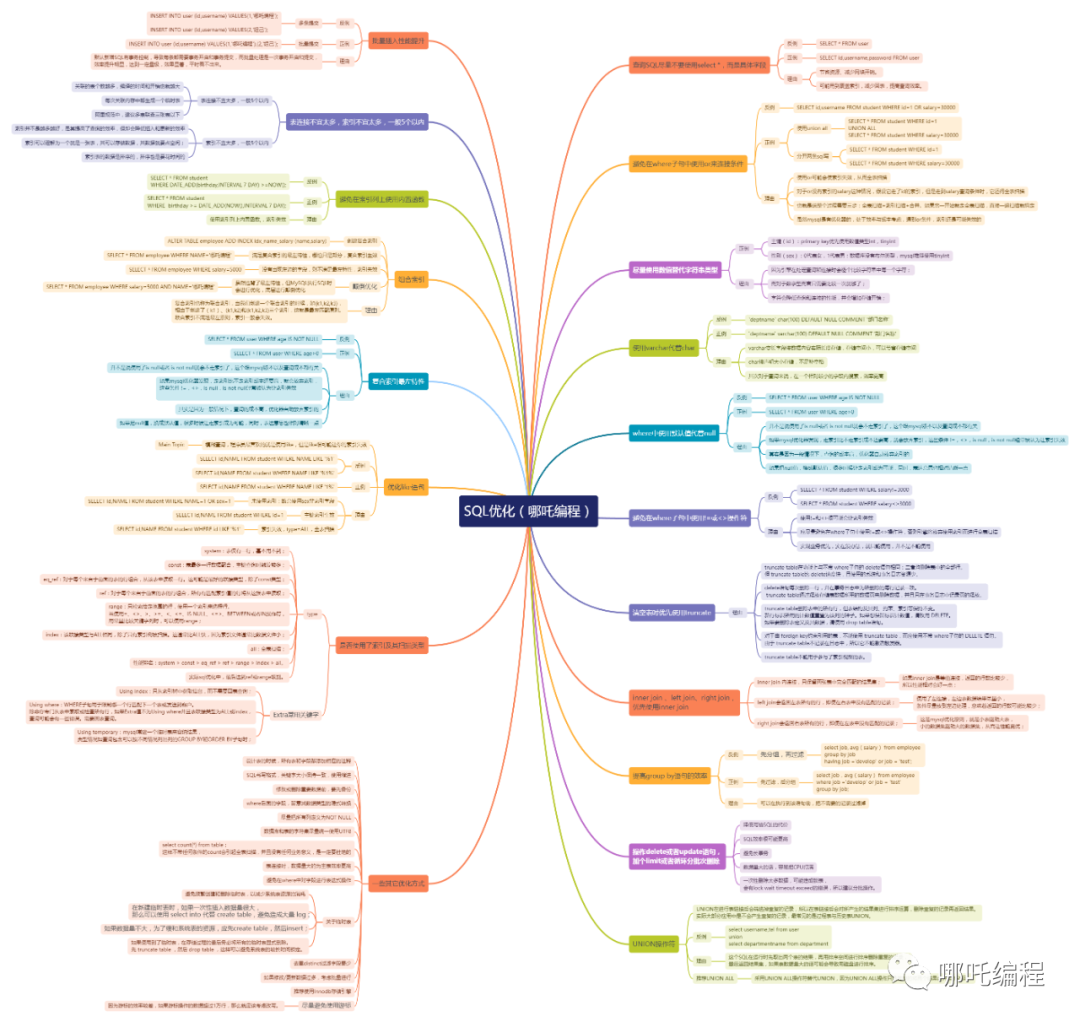
 SQL優化技巧分享
SQL優化技巧分享
1、反例
SELECT*FROMuser
2、正例
SELECTid,username,telFROMuser
3、理由
注意:為節省時間,下面的樣例字段都用*代替了。
二、避免在where子句中使用 or 來連接條件
1、反例
SELECT*FROMuserWHEREid=1ORsalary=5000
2、正例
(1)使用union all
SELECT*FROMuserWHEREid=1
UNIONALL
SELECT*FROMuserWHEREsalary=5000
(2)分開兩條sql寫
SELECT*FROMuserWHEREid=1
SELECT*FROMuserWHEREsalary=5000
3、理由
-
使用
or可能會使索引失效,從而全表掃描; -
對于
or沒有索引的salary這種情況,假設它走了id的索引,但是走到salary查詢條件時,它還得全表掃描; - 也就是說整個過程需要三步:全表掃描+索引掃描+合并。如果它一開始就走全表掃描,直接一遍掃描就搞定;
-
雖然
mysql是有優化器的,出于效率與成本考慮,遇到or條件,索引還是可能失效的;
三、盡量使用數值替代字符串類型
1、正例
2、理由
- 因為引擎在處理查詢和連接時會逐個比較字符串中每一個字符;
- 而對于數字型而言只需要比較一次就夠了;
- 字符會降低查詢和連接的性能,并會增加存儲開銷;
四、使用varchar代替char
1、反例
`address`char(100)DEFAULTNULLCOMMENT'地址'
2、正例
`address`varchar(100)DEFAULTNULLCOMMENT'地址'
3、理由
-
varchar變長字段按數據內容實際長度存儲,存儲空間小,可以節省存儲空間; -
char按聲明大小存儲,不足補空格; - 其次對于查詢來說,在一個相對較小的字段內搜索,效率更高;
五、技術延伸,char與varchar2的區別?
1、char的長度是固定的,而varchar2的長度是可以變化的。
比如,存儲字符串“101”,對于char(10),表示你存儲的字符將占10個字節(包括7個空字符),在數據庫中它是以空格占位的,而同樣的varchar2(10)則只占用3個字節的長度,10只是最大值,當你存儲的字符小于10時,按實際長度存儲。
2、char的效率比varchar2的效率稍高。
3、何時用char,何時用varchar2?
char和varchar2是一對矛盾的統一體,兩者是互補的關系,varchar2比char節省空間,在效率上比char會稍微差一點,既想獲取效率,就必須犧牲一點空間,這就是我們在數據庫設計上常說的“以空間換效率”。
varchar2雖然比char節省空間,但是假如一個varchar2列經常被修改,而且每次被修改的數據的長度不同,這會引起“行遷移”現象,而這造成多余的I/O,是數據庫設計中要盡力避免的,這種情況下用char代替varchar2會更好一些。char中還會自動補齊空格,因為你insert到一個char字段自動補充了空格的,但是select后空格沒有刪除,因此char類型查詢的時候一定要記得使用trim,這是寫本文章的原因。
如果開發人員細化使用rpad()技巧將綁定變量轉換為某種能與char字段相比較的類型(當然,與截斷trim數據庫列相比,填充綁定變量的做法更好一些,因為對列應用函數trim很容易導致無法使用該列上現有的索引),可能必須考慮到經過一段時間后列長度的變化。如果字段的大小有變化,應用就會受到影響,因為它必須修改字段寬度。
正是因為以上原因,定寬的存儲空間可能導致表和相關索引比平常大出許多,還伴隨著綁定變量問題,所以無論什么場合都要避免使用char類型。
六、where中使用默認值代替null
1、反例
SELECT*FROMuserWHEREageISNOTNULL
2、正例
SELECT*FROMuserWHEREage>0
3、理由
-
并不是說使用了
is null或者is not null就會不走索引了,這個跟mysql版本以及查詢成本都有關; -
如果
mysql優化器發現,走索引比不走索引成本還要高,就會放棄索引,這些條件!=,<>,is null,is not null經常被認為讓索引失效; - 其實是因為一般情況下,查詢的成本高,優化器自動放棄索引的;
-
如果把
null值,換成默認值,很多時候讓走索引成為可能,同時,表達意思也相對清晰一點;
七、避免在where子句中使用!=或<>操作符
1、反例
SELECT*FROMuserWHEREsalary!=5000
SELECT*FROMuserWHEREsalary<>5000
2、理由
-
使用
!=和<>很可能會讓索引失效 -
應盡量避免在
where子句中使用!=或<>操作符,否則引擎將放棄使用索引而進行全表掃描 - 實現業務優先,實在沒辦法,就只能使用,并不是不能使用
八、inner join 、left join、right join,優先使用inner join
三種連接如果結果相同,優先使用inner join,如果使用left join左邊表盡量小。
- inner join 內連接,只保留兩張表中完全匹配的結果集;
- left join會返回左表所有的行,即使在右表中沒有匹配的記錄;
- right join會返回右表所有的行,即使在左表中沒有匹配的記錄;
為什么?
- 如果inner join是等值連接,返回的行數比較少,所以性能相對會好一點;
- 使用了左連接,左邊表數據結果盡量小,條件盡量放到左邊處理,意味著返回的行數可能比較少;
- 這是mysql優化原則,就是小表驅動大表,小的數據集驅動大的數據集,從而讓性能更優;
九、提高group by語句的效率
1、反例
先分組,再過濾
selectjob,avg(salary)fromemployee
groupbyjob
havingjob='develop'orjob='test';
2、正例
先過濾,后分組
selectjob,avg(salary)fromemployee
wherejob='develop'orjob='test'
groupbyjob;
3、理由
可以在執行到該語句前,把不需要的記錄過濾掉
十、清空表時優先使用truncate
truncate table在功能上與不帶 where子句的 delete語句相同:二者均刪除表中的全部行。但 truncate table比 delete速度快,且使用的系統和事務日志資源少。
delete語句每次刪除一行,并在事務日志中為所刪除的每行記錄一項。truncate table通過釋放存儲表數據所用的數據頁來刪除數據,并且只在事務日志中記錄頁的釋放。
truncate table刪除表中的所有行,但表結構及其列、約束、索引等保持不變。新行標識所用的計數值重置為該列的種子。如果想保留標識計數值,請改用 DELETE。如果要刪除表定義及其數據,請使用 drop table語句。
對于由 foreign key約束引用的表,不能使用 truncate table,而應使用不帶 where子句的 DELETE 語句。由于 truncate table不記錄在日志中,所以它不能激活觸發器。
truncate table不能用于參與了索引視圖的表。
十一、操作delete或者update語句,加個limit或者循環分批次刪除
1、降低寫錯SQL的代價
清空表數據可不是小事情,一個手抖全沒了,刪庫跑路?如果加limit,刪錯也只是丟失部分數據,可以通過binlog日志快速恢復的。
2、SQL效率很可能更高
SQL中加了limit 1,如果第一條就命中目標return, 沒有limit的話,還會繼續執行掃描表。
3、避免長事務
delete執行時,如果age加了索引,MySQL會將所有相關的行加寫鎖和間隙鎖,所有執行相關行會被鎖住,如果刪除數量大,會直接影響相關業務無法使用。
4、數據量大的話,容易把CPU打滿
如果你刪除數據量很大時,不加 limit限制一下記錄數,容易把cpu打滿,導致越刪越慢。
5、鎖表
一次性刪除太多數據,可能造成鎖表,會有lock wait timeout exceed的錯誤,所以建議分批操作。
十二、UNION操作符
UNION在進行表鏈接后會篩選掉重復的記錄,所以在表鏈接后會對所產生的結果集進行排序運算,刪除重復的記錄再返回結果。實際大部分應用中是不會產生重復的記錄,最常見的是過程表與歷史表UNION。如:
selectusername,telfromuser
union
selectdepartmentnamefromdepartment
這個SQL在運行時先取出兩個表的結果,再用排序空間進行排序刪除重復的記錄,最后返回結果集,如果表數據量大的話可能會導致用磁盤進行排序。推薦方案:采用UNION ALL操作符替代UNION,因為UNION ALL操作只是簡單的將兩個結果合并后就返回。
十三、批量插入性能提升
1、多條提交
INSERTINTOuser(id,username)VALUES(1,'哪吒編程');
INSERTINTOuser(id,username)VALUES(2,'妲己');
2、批量提交
INSERTINTOuser(id,username)VALUES(1,'哪吒編程'),(2,'妲己');
3、理由
默認新增SQL有事務控制,導致每條都需要事務開啟和事務提交,而批量處理是一次事務開啟和提交,效率提升明顯,達到一定量級,效果顯著,平時看不出來。
十四、表連接不宜太多,索引不宜太多,一般5個以內
1、表連接不宜太多,一般5個以內
- 關聯的表個數越多,編譯的時間和開銷也就越大
- 每次關聯內存中都生成一個臨時表
- 應該把連接表拆開成較小的幾個執行,可讀性更高
- 如果一定需要連接很多表才能得到數據,那么意味著這是個糟糕的設計了
- 阿里規范中,建議多表聯查三張表以下
2、索引不宜太多,一般5個以內
- 索引并不是越多越好,雖其提高了查詢的效率,但卻會降低插入和更新的效率;
- 索引可以理解為一個就是一張表,其可以存儲數據,其數據就要占空間;
- 索引表的數據是排序的,排序也是要花時間的;
-
insert或update時有可能會重建索引,如果數據量巨大,重建將進行記錄的重新排序,所以建索引需要慎重考慮,視具體情況來定; - 一個表的索引數最好不要超過5個,若太多需要考慮一些索引是否有存在的必要;
十五、避免在索引列上使用內置函數
1、反例
SELECT*FROMuserWHEREDATE_ADD(birthday,INTERVAL7DAY)>=NOW();
2、正例
SELECT*FROMuserWHEREbirthday>=DATE_ADD(NOW(),INTERVAL7DAY);
3、理由
使用索引列上內置函數,索引失效。
十六、組合索引
排序時應按照組合索引中各列的順序進行排序,即使索引中只有一個列是要排序的,否則排序性能會比較差。
createindexIDX_USERNAME_TELonuser(deptid,position,createtime);
selectusername,telfromuserwheredeptid=1andposition='java開發'orderbydeptid,position,createtimedesc;
實際上只是查詢出符合 deptid= 1 and position = 'java開發'條件的記錄并按createtime降序排序,但寫成order by createtime desc性能較差。
十七、復合索引最左特性
1、創建復合索引
ALTERTABLEemployeeADDINDEXidx_name_salary(name,salary)
2、滿足復合索引的最左特性,哪怕只是部分,復合索引生效
SELECT*FROMemployeeWHERENAME='哪吒編程'
3、沒有出現左邊的字段,則不滿足最左特性,索引失效
SELECT*FROMemployeeWHEREsalary=5000
4、復合索引全使用,按左側順序出現 name,salary,索引生效
SELECT*FROMemployeeWHERENAME='哪吒編程'ANDsalary=5000
5、雖然違背了最左特性,但MySQL執行SQL時會進行優化,底層進行顛倒優化
SELECT*FROMemployeeWHEREsalary=5000ANDNAME='哪吒編程'
6、理由
復合索引也稱為聯合索引,當我們創建一個聯合索引的時候,如(k1,k2,k3),相當于創建了(k1)、(k1,k2)和(k1,k2,k3)三個索引,這就是最左匹配原則。
聯合索引不滿足最左原則,索引一般會失效。
十八、優化like語句
模糊查詢,程序員最喜歡的就是使用like,但是like很可能讓你的索引失效。
1、反例
select*fromcityswherenamelike'%大連'(不使用索引)
select*fromcityswherenamelike'%大連%'(不使用索引)
2、正例
select*fromcityswherenamelike'大連%'(使用索引)。
3、理由
-
首先盡量避免模糊查詢,如果必須使用,不采用全模糊查詢,也應盡量采用右模糊查詢, 即
like ‘…%’,是會使用索引的; -
左模糊
like ‘%...’無法直接使用索引,但可以利用reverse + function index的形式,變化成like ‘…%’; - 全模糊查詢是無法優化的,一定要使用的話建議使用搜索引擎。
十九、使用explain分析你SQL執行計劃
1、type
- system:表僅有一行,基本用不到;
- const:表最多一行數據配合,主鍵查詢時觸發較多;
- eq_ref:對于每個來自于前面的表的行組合,從該表中讀取一行。這可能是最好的聯接類型,除了const類型;
- ref:對于每個來自于前面的表的行組合,所有有匹配索引值的行將從這張表中讀取;
- range:只檢索給定范圍的行,使用一個索引來選擇行。當使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比較關鍵字列時,可以使用range;
- index:該聯接類型與ALL相同,除了只有索引樹被掃描。這通常比ALL快,因為索引文件通常比數據文件小;
- all:全表掃描;
- 性能排名:system > const > eq_ref > ref > range > index > all。
- 實際sql優化中,最后達到ref或range級別。
2、Extra常用關鍵字
- Using index:只從索引樹中獲取信息,而不需要回表查詢;
- Using where:WHERE子句用于限制哪一個行匹配下一個表或發送到客戶。除非你專門從表中索取或檢查所有行,如果Extra值不為Using where并且表聯接類型為ALL或index,查詢可能會有一些錯誤。需要回表查詢。
-
Using temporary:mysql常建一個臨時表來容納結果,典型情況如查詢包含可以按不同情況列出列的
GROUP BY和ORDER BY子句時;
二十、一些其它優化方式
1、設計表的時候,所有表和字段都添加相應的注釋。
2、SQL書寫格式,關鍵字大小保持一致,使用縮進。
3、修改或刪除重要數據前,要先備份。
4、很多時候用 exists 代替 in 是一個好的選擇
5、where后面的字段,留意其數據類型的隱式轉換。
未使用索引
SELECT*FROMuserWHERENAME=110
(1) 因為不加單引號時,是字符串跟數字的比較,它們類型不匹配;
(2)MySQL會做隱式的類型轉換,把它們轉換為數值類型再做比較;
6、盡量把所有列定義為NOT NULL
NOT NULL列更節省空間,NULL列需要一個額外字節作為判斷是否為 NULL的標志位。NULL列需要注意空指針問題,NULL列在計算和比較的時候,需要注意空指針問題。
7、偽刪除設計
8、數據庫和表的字符集盡量統一使用UTF8
(1)可以避免亂碼問題;
(2)可以避免,不同字符集比較轉換,導致的索引失效問題;
9、select count(*) from table;
這樣不帶任何條件的count會引起全表掃描,并且沒有任何業務意義,是一定要杜絕的。
10、避免在where中對字段進行表達式操作
(1)SQL解析時,如果字段相關的是表達式就進行全表掃描 ;
(2)字段干凈無表達式,索引生效;
11、關于臨時表
(1)避免頻繁創建和刪除臨時表,以減少系統表資源的消耗;
(2)在新建臨時表時,如果一次性插入數據量很大,那么可以使用 select into 代替 create table,避免造成大量 log;
(3)如果數據量不大,為了緩和系統表的資源,應先create table,然后insert;
(4)如果使用到了臨時表,在存儲過程的最后務必將所有的臨時表顯式刪除。先 truncate table ,然后 drop table ,這樣可以避免系統表的較長時間鎖定;
12、索引不適合建在有大量重復數據的字段上,比如性別,排序字段應創建索引
13、去重distinct過濾字段要少
-
帶distinct的語句占用
cpu時間高于不帶distinct的語句 -
當查詢很多字段時,如果使用
distinct,數據庫引擎就會對數據進行比較,過濾掉重復數據 -
然而這個比較、過濾的過程會占用系統資源,如
cpu時間
14、盡量避免大事務操作,提高系統并發能力
15、所有表必須使用Innodb存儲引擎
Innodb「支持事務,支持行級鎖,更好的恢復性」,高并發下性能更好,所以呢,沒有特殊要求(即Innodb無法滿足的功能如:列存儲,存儲空間數據等)的情況下,所有表必須使用Innodb存儲引擎。
16、盡量避免使用游標
因為游標的效率較差,如果游標操作的數據超過1萬行,那么就應該考慮改寫。
審核編輯:湯梓紅
-
SQL
+關注
關注
1文章
764瀏覽量
44128 -
字符
+關注
關注
0文章
233瀏覽量
25208 -
select
+關注
關注
0文章
28瀏覽量
3920
原文標題:SQL優化 21 連擊 + 思維導圖
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據庫SQL的優化
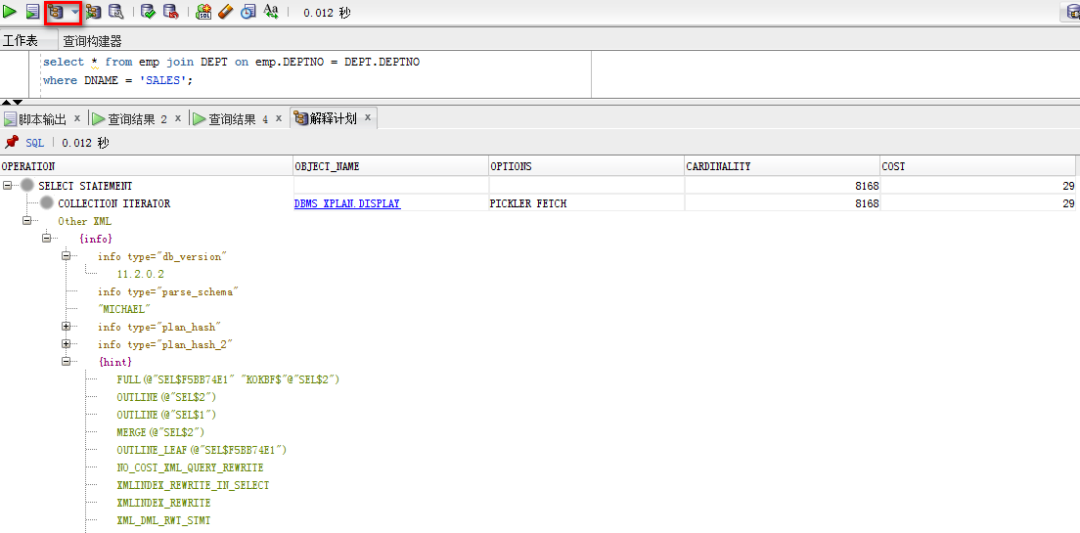
淺談SQL優化小技巧
SQL優化器原理 - 查詢優化器綜述
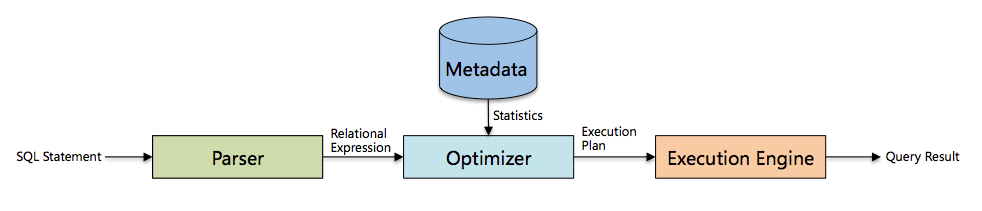
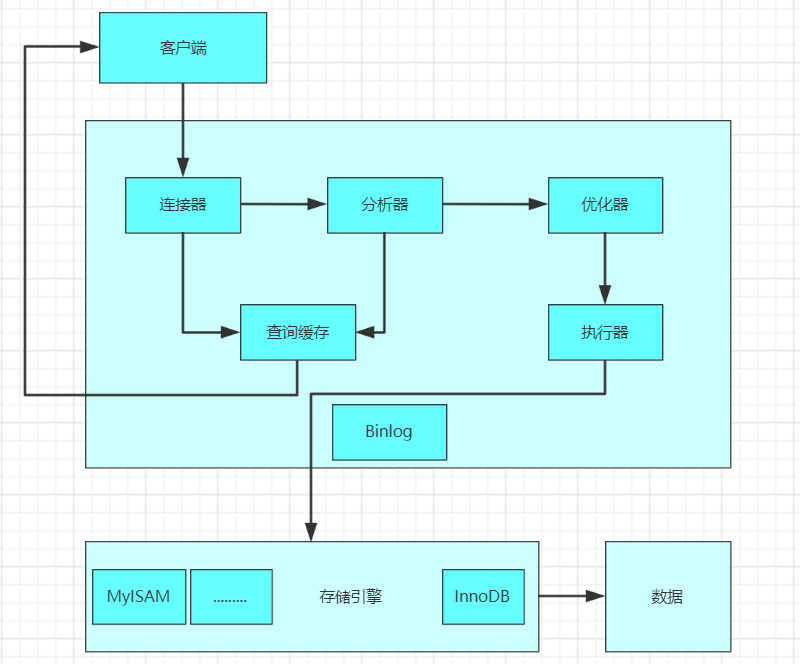
MySQL基本架構及SQL優化詳解
SQL優化的一般步驟與案例分析
SQL優化思路與經典案例分析
sql優化常用的幾種方法
關于SQL優化的硬核文章
Oracle長耗時SQL優化案例

MySQL的基礎架構 一文詳解SQL優化方案
MySQL執行過程:如何進行sql 優化
QPS提升10倍的sql優化





 工商網監
工商網監
評論