 基于YOLOv5框架如何訓練一個自定義對象檢測模型
基于YOLOv5框架如何訓練一個自定義對象檢測模型
安裝與測試
最近YOLOv5最新更新升級到v6.x版本,工程簡便性有提升了一大步,本教程教你基于YOLOv5框架如何訓練一個自定義對象檢測模型,首先需要下載對應版本:
https://github.com/ultralytics/yolov5/releases/tag/v6.1
鼠標滾到最下面下載源碼zip包:
https://github.com/ultralytics/yolov5/archive/refs/tags/v6.1.zip
下載完成之后解壓縮到:
D:pythonyolov5-6.1
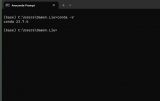
首先運行下面命令行完成依賴庫的安裝:

python detect.py --weights yolov5s.pt --source dataimageszidane.jpg
運行結果如下:

數據集準備與制作
自己百度收集了一個無人機與飛鳥的數據集,其中訓練集270張圖像,測試集26張圖像。
使用labelImg工具完成標注,工具下載地址:
https://gitee.com/opencv_ai/opencv_tutorial_data/tree/master/tools
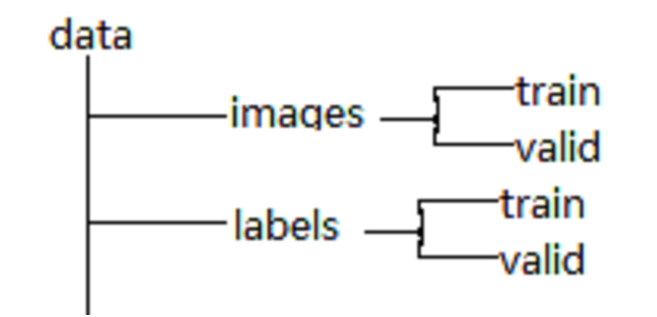
YOLOv5要求的數據集目錄結構如下:
Left top right bottom
轉換為
Center_x, center_y, width, height
并歸一化到0~1之間,這部分我寫了一個腳本來完成label標簽的生成,把xml的標注信息轉換為YOLOv5的labels文件,這樣就完成了數據集制作。最后需要創建一個dataset.ymal文件,放在與data文件夾同一層,它的內容如下:# train and val datasets (image directory or *.txt file with image paths)train: uav_bird_training/data/images/train/val: uav_bird_training/data/images/valid/# number of classesnc: 2# class namesnames: ['bird', 'drone']
三:模型訓練
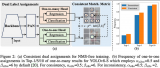
制作好數據集之后,模型訓練就成為一件很簡單事情,一條命令行搞定。運行下面的命令行:
python train.py --img 640 --batch 4 --epochs 25 --data uav_bird_trainingdataset.yaml --weights yolov5s.pt
其中uav_bird_training文件夾里是制作好的數據集。這樣就開始訓練,訓練過程中可以通過tensorboard來查看可視化的結果,

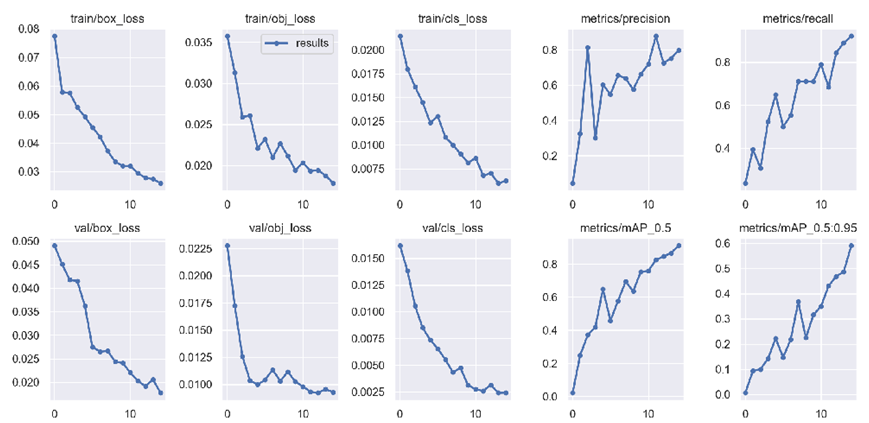
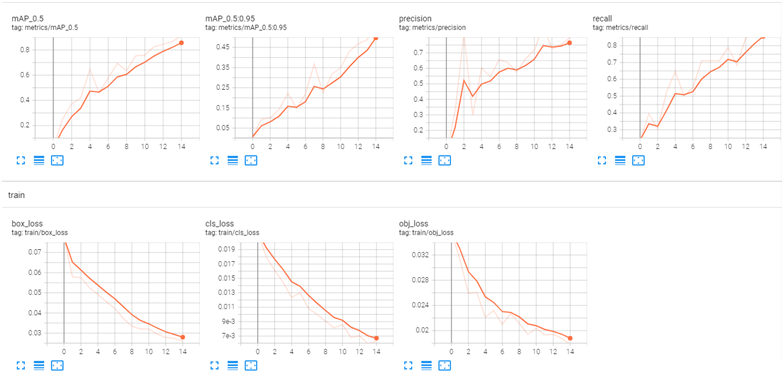
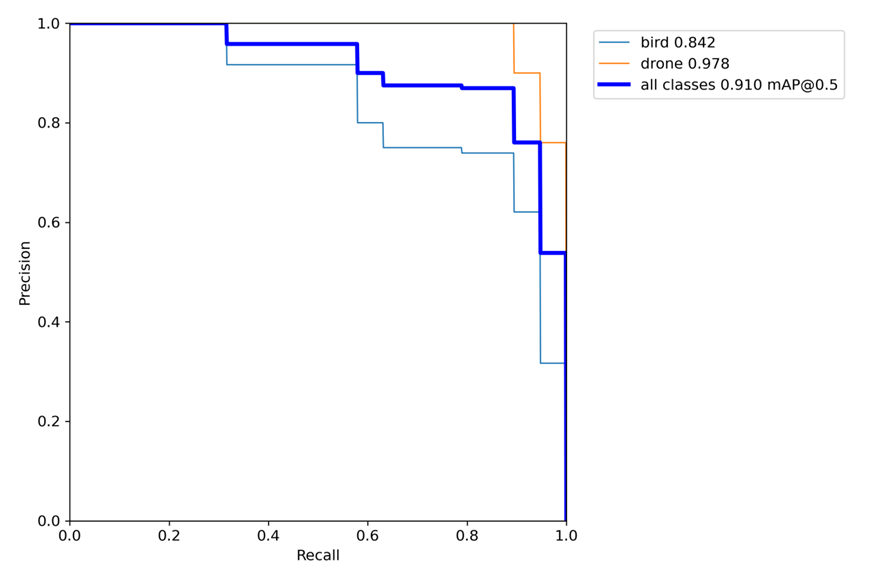
PR曲線說明訓練效果還錯!
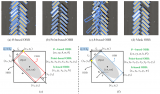
不同框架與硬件平臺推理比較
YOLOv5的6.x版本支持不同框架模型導出與推理,看下圖:

測試,分別截圖如下:-OpenCV DNN-OpenVINO-ONNXRUNTIME-TensorRT
OpenCV DNN推理速度

OpenVINO平臺上的推理速度

ONNXRUNTIME GPU推理速度

TensorRT框架部署-FP32版本模型推理統計:

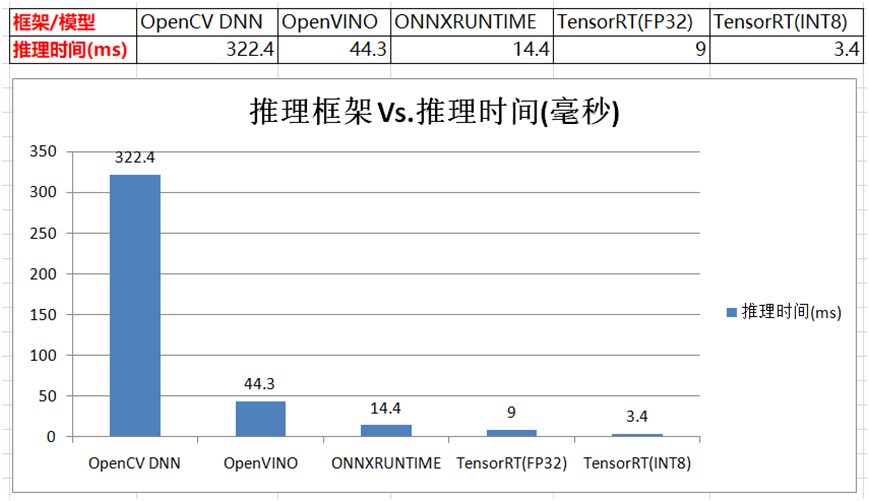
YOLOv5的6.x版本,是支持TensorRT 量化到FP16模型直接導出的,但是不支持INT8量化生成,所以自己實現了導出量化INT8版本,測試結果如下:
python detect.py --weights uav_bird_training/uav_bird_int8.engine --data uav_bird_training/dataset.yaml --source D:/bird/bird_fly.mp4
TensorRT框架部署-INT8版本模型推理統計:

最終比較:
番外篇:C++推理與比較
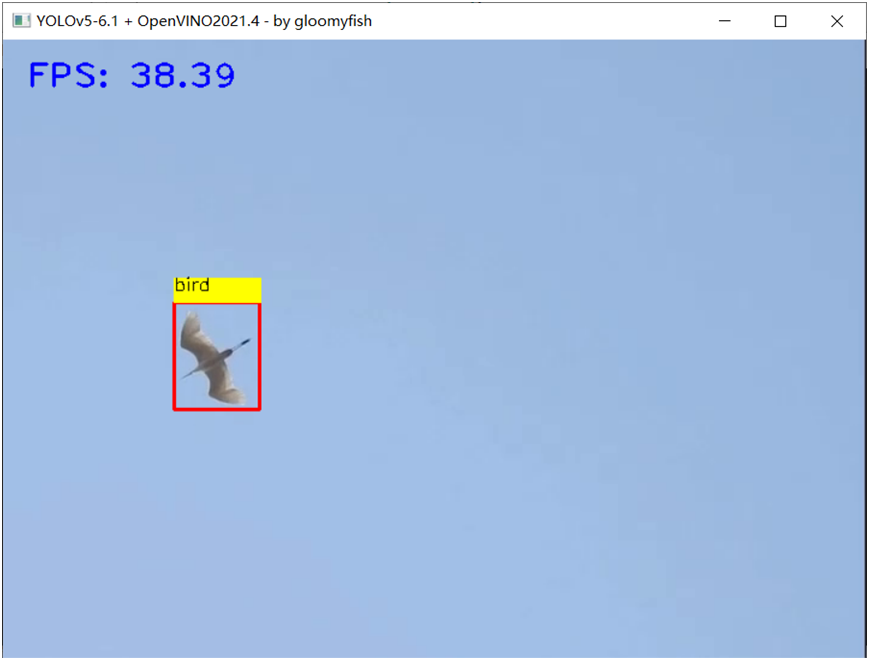
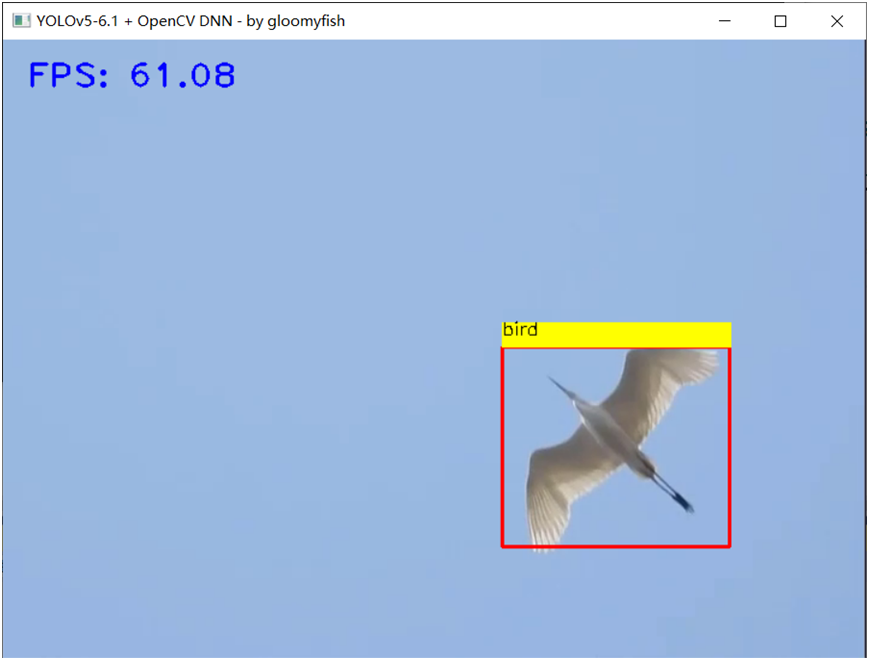
使用C++部署時候,前后處理都改成了基于OpenCV 完成,使用CPU完成前后處理,OpenVINO+CPU運行速度截圖如下:
OpenCV DNN + CUDA版本推理
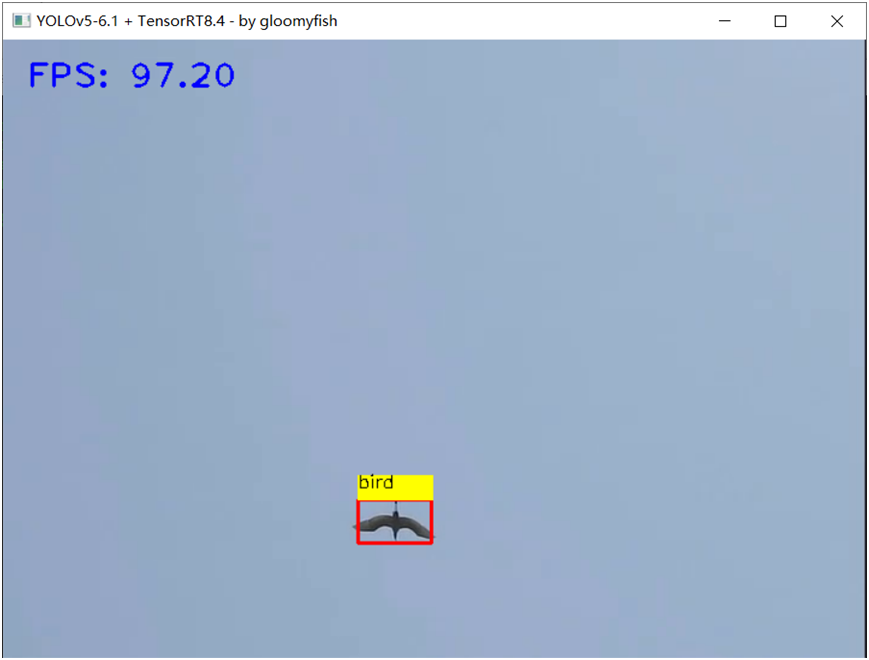
TensorRT-FP32模型推理速度
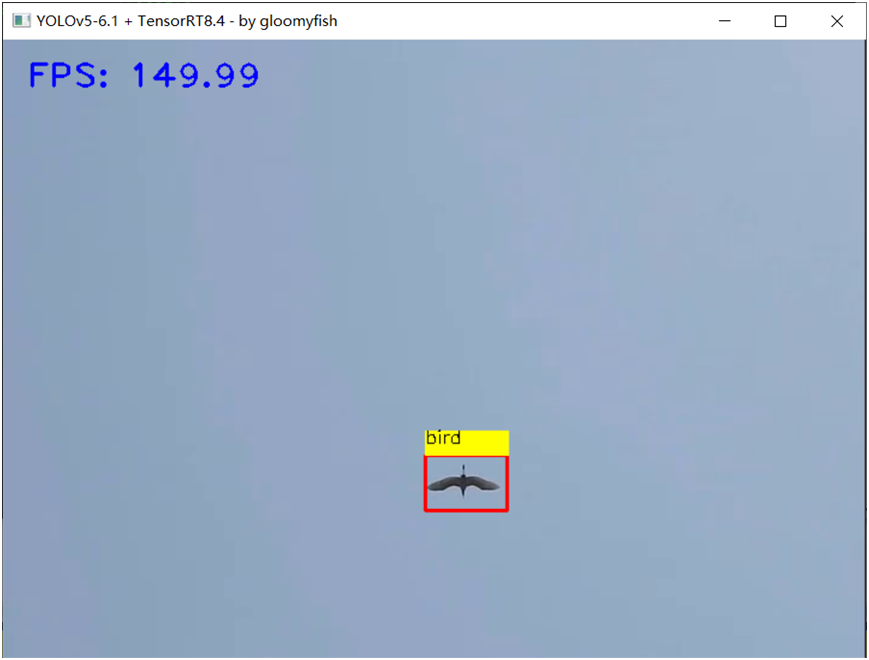
TensorRT-INT8模型推理速度
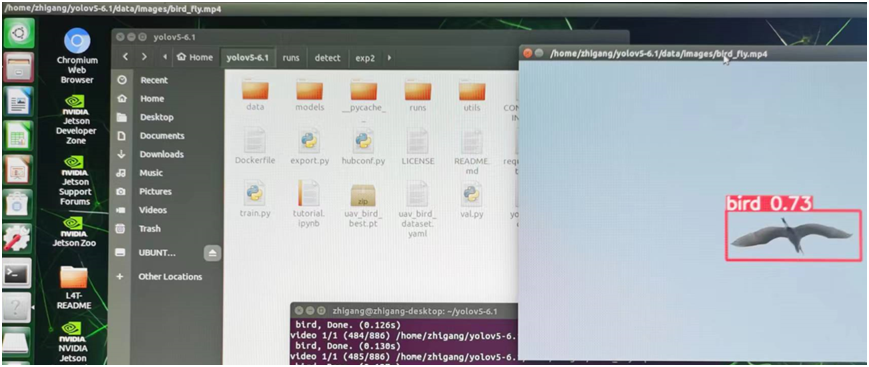
最后把自定義訓練導出的模型轉換為TensorRT Engine文件之后,部署到了我的一塊Jetson Nano卡上面,實現了邊緣端的部署,有圖有真相:
審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
檢測模型
+關注
關注
0文章
17瀏覽量
7326 -
數據集
+關注
關注
4文章
1208瀏覽量
24749
原文標題:YOLOv5新版本6.x 自定義對象檢測-從訓練到部署
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
think-cell:自定義think-cell(四)
C.5 設置默認議程幻燈片布局 think-cell 議程可以在演示文稿中使用特定的自定義布局來定義議程、位置和議程幻燈片上的其他形狀,例如標題或圖片。通過將此自定義布局添加到模板,您
think-cell;自定義think-cell(一)
本章介紹如何自定義 think-cell,即如何更改默認顏色和其他默認屬性;這是通過 think-cell 的樣式文件完成的,這些文件將在前四個部分中進行討論。 第五部分 C.5 設置默認議程幻燈片

在RK3568教學實驗箱上實現基于YOLOV5的算法物體識別案例詳解
種非常流行的實時目標檢測模型,它提供了出色的性能和精度。YOLOv5可以分為三個部分,分別是:
1、主干特征提取網絡(Backbone)
2、加強特征提取網絡(FPN)
3、分類器與回
發表于 12-03 14:56
YOLOv10自定義目標檢測之理論+實踐
概述 YOLOv10 是由清華大學研究人員利用 Ultralytics Python 軟件包開發的,它通過改進模型架構并消除非極大值抑制(NMS)提供了一種新穎的實時目標檢測方法。這些
在樹莓派上部署YOLOv5進行動物目標檢測的完整流程
卓越的性能。本文將詳細介紹如何在性能更強的計算機上訓練YOLOv5模型,并將訓練好的模型部署到樹莓派4B上,通過樹莓派的攝像頭進行實時動物目
RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測-迅為電子
RK3588 技術分享 | 在Android系統中使用NPU實現Yolov5分類檢測-迅為電子


NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型
Retriever 微服務,以實現準確響應 埃森哲率先使用新服務,為客戶創建自定義 Llama 3.1 模型;Aramco、ATT 和優步。 ? Llama 3.1 多語種大語言模型(LLM)集合是
發表于 07-24 09:39
?727次閱讀

YOLOv5的原理、結構、特點和應用
YOLOv5(You Only Look Once version 5)是一種基于深度學習的實時目標檢測算法,它屬于卷積神經網絡(CNN)的范疇。下面我將詳細介紹
口罩佩戴檢測算法
,口罩佩戴檢測算法利用YOLOv5模型框架,修改其相關配置文件和檢測參數,并采用數據增強和Dropout技術防止過擬合。實驗結果驗證了

如何在IDF框架中使用自定義的靜態庫和動態庫?
基于商業需要,我們需要在 ESP-IDF v4.0-rc 這個版本的IDF中開發與使用自定義庫,有如下問題請協助:
1如何利用IDF框架編寫自定義靜態庫和動態庫?
2如何在IDF框架中
發表于 06-25 07:57
用yolov5的best.pt導出成onnx轉化成fp32 bmodel后在Airbox上跑,報維度不匹配怎么處理?
用官方的模型不出錯,用自己的yolov5訓練出來的best.pt導出成onnx轉化成fp32 bmodel后在Airbox上跑,出現報錯:
linaro@bm1684:~/yolov5
發表于 05-31 08:10
鴻蒙ArkUI實例:【自定義組件】
組件是 OpenHarmony 頁面最小顯示單元,一個頁面可由多個組件組合而成,也可只由一個組件組合而成,這些組件可以是ArkUI開發框架自
OpenCV4.8 C++實現YOLOv8 OBB旋轉對象檢測
YOLOv8框架在在支持分類、對象檢測、實例分割、姿態評估的基礎上更近一步,現已經支持旋轉對象





 工商網監
工商網監
評論