 面向ARM異構多核系統的性能分析與效能優化
面向ARM異構多核系統的性能分析與效能優化
01背景介紹
性能和能耗之間的平衡是設計新處理器的核心問題之一,因為超過90%的處理器最終用于嵌入式能源受限設備,例如智能手機和物聯網傳感器。異構系統,結合不同的處理器類型,為不同類型的工作負載提供高能效處理。第一個異構系統將處理器與不同的指令集架構(ISA)相結合。最近,單ISA非對稱多核處理器(AMP)開始流行。它們的優勢是顯而易見的——因為處理器共享相同的架構,操作系統線程調度程序可以在運行時做出關于將哪個任務/線程映射到哪個處理器/內核的決定,這不僅取決于工作負載的特征,還取決于通過單個處理器/內核的運行時負載。另一方面,這為調度問題引入了額外的自由度,使其更加復雜。
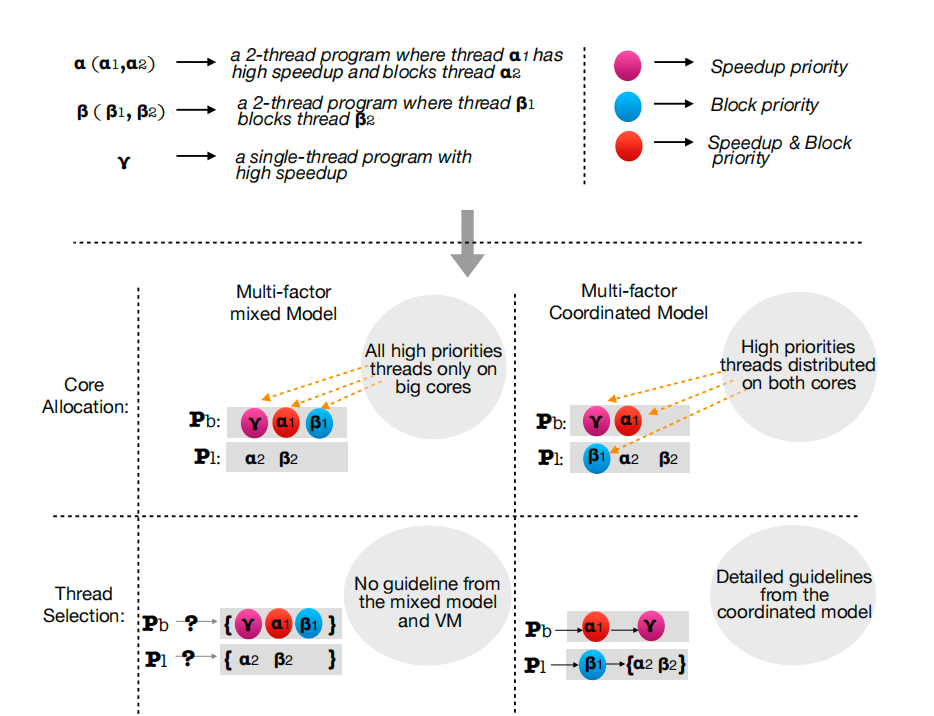
非對稱多核處理器上的多線程多道程序工作負載,具有一個大核和一個小核。僅控制CPU核心親和性會導致次優運行時優化決策。工作負載,這些應用程序具有潛在的不平衡線程,并且線程總數可能高于內核數。雖然向前邁出了重要一步,但WASH僅控制核心親和力,并且以有限的方式這樣做。前者意味著我們無法以整體方式處理核心分配和線程調度來加速最關鍵的線程。后者意味著WASH只真正控制每個線程的調度域,即允許線程使用的內核組。每個線程的實際核心由底層LinuxCFS調度程序選擇,其啟發式忽略異構性和線程關鍵性。
02COLAB方案概覽
COLAB是一種用于非對稱多核處理器的運行時優化策略,它能夠針對線程調度中的所有三個主要因素-核心敏感度、線程關鍵性和公平性做出協調決策。
1.核心敏感度:每種類型的核心都旨在處理不同類型的工作負載。例如,在ARM big.LITTLE系統中,大內核主要用于性能關鍵型工作負載或具有指令級并行(ILP)的工作負載。在它們上執行其他類型的工作負載不會顯著提高性能,但會顯著增加能耗。為了構建高效的AMP調度程序,我們需要預測哪些線程適合哪種內核。
2.線程關鍵性:更快地執行工作負載的單個線程并不總是轉化為整個工作負載的更好性能。如果應用程序的線程不平衡或以不同的速度執行,例如因為不同的線程在不同類型的內核上運行,則應用程序將僅以其最慢或最關鍵的線程(阻塞大部分其他線程的線程)運行線程)。一個好的AMP調度程序會盡可能地加速這些線程,而不管核心敏感度如何。
3.負載均衡:在多道程序工作負載中,單獨加速單個應用程序是不夠的,如果它會懲罰其他應用程序。理想情況下,我們需要負載均衡來平衡所有應用程序中資源共享的負面影響。在同構系統中,這很容易通過以循環方式在CPU上為每個應用程序提供固定大小的時間片來實現。AMP使這個簡單的解決方案變得不可行。由于每個內核的性能不同,不同內核類型上相同的CPU時間會導致執行的工作量完全不同。
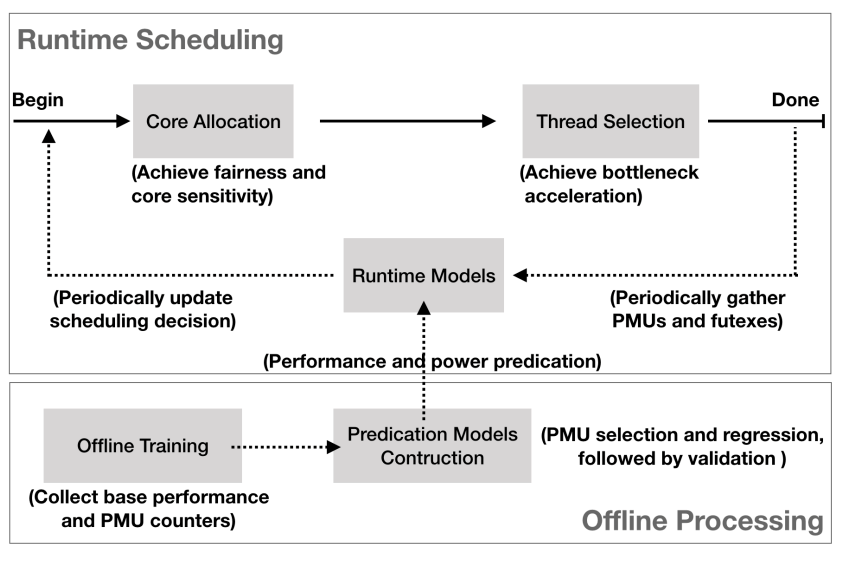
系統分為運行時調度過程和離線建模過程。運行時調度器內置在OS內核中,由
i)一個核心分配器組成,用于處理公平性和核心敏感性;
ii)實現瓶頸加速的線程選擇器;
iii)基于機器學習的運行時模型,它預測異構內核上線程的加速和功耗。離線建模處理用于通過離線訓練構建運行時模型。
COLAB調度程序的主要新穎之處在于它可以以協作的方式處理多個運行時因素(核心敏感性、瓶頸加速和公平性),以實現高系統性能和能源效率。
運行時分析
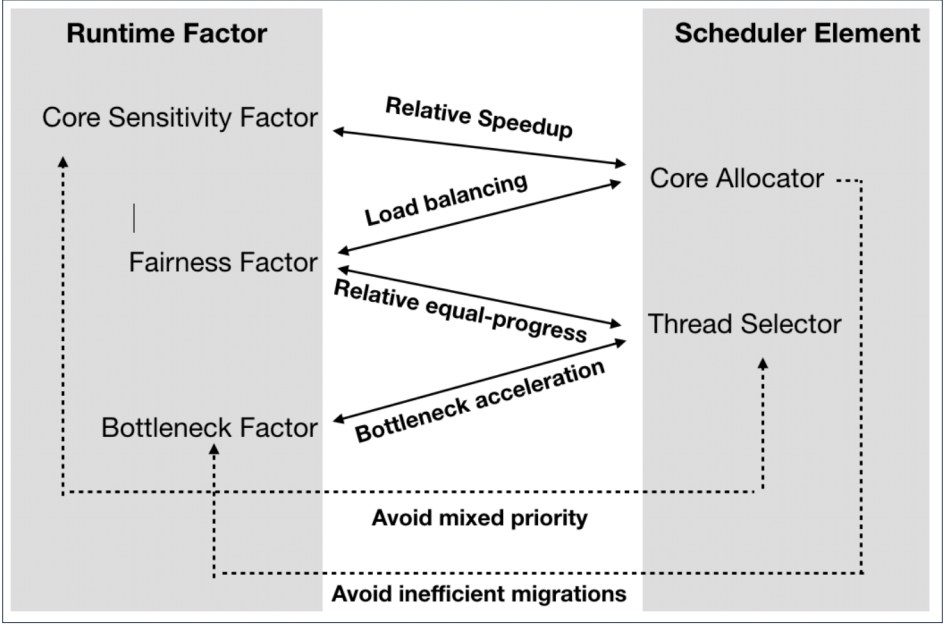
核心分配器:支持AMP的核心分配器主要受線程的核心敏感度因素指導,它量化了將線程從小核心遷移到大核心帶來的性能優勢。將high-speedupthread(在大核心上享有較大的加速)從小核心遷移到大核心通常比遷移low-speedupthread 提供更多好處。然而,考慮到瓶頸因素,它量化了線程阻塞其他線程的程度,揭示了這種啟發式在多道程序工作負載上的問題。以前的方法只是將預測的瓶頸加速和加速結合在一起。這可能會導致次優的調度決策,其中瓶頸線程和高速加速線程都累積在大核心的運行隊列中,更好的核心分配策略將避免瓶頸加速和加速的簡單組合,而是專注于協作環境,其中大核心專注于高速瓶頸線程,小核心處理低加速瓶頸線程而無需額外遷移。此外,核心分配器試圖通過有效地共享異構硬件并盡可能避免讓資源閑置來實現AMP的相對公平。簡單地將就緒線程均勻地映射到不同類型的內核上并不能實現真正的公平性,因為不同類型的內核最終具有不同數量的線程優先級。因此,應采用分層分配來保證整體公平性,從而避免頻繁將線程遷移到空運行隊列的需要。
線程選擇器:線程選擇器決定接下來將執行每個內核的運行隊列中的哪個線程。線程選擇器通常會優先考慮瓶頸線程,以避免線程被阻塞太久而導致性能損失。在多線程多程序環境中,可能需要同時加速來自不同程序的多個瓶頸線程。不像之前的瓶頸加速調度程序那樣簡單地檢測瓶頸線程并將它們全部分配給大核,線程選擇器需要做出協作決策——理想情況下,大核和小核核心將同時運行瓶頸線程。核心敏感性通常對線程選擇器并不重要,它做出的決定完全由瓶頸加速來指導。一個例外是大核心的運行隊列為空并且調用線程選擇器時。只有在這種情況下,才應考慮就緒線程的核心敏感性的加速因素。必要時,大核甚至可以搶占小核上的線程執行。最后,線程選擇器還關注公平性。通過更新線程選擇器的時間間隔來縮放線程的時間片已被證明可以保證線程的相等進度并實現多線程單程序工作負載的公平性。然而,僅僅確保所有線程的平等進程是不夠的,不足以保證跨程序的公平性。線程選擇器應確保每個單獨的程序都能平等地進行使用大核和小核來加速瓶頸為此提供了機會。線程選擇器試圖通過盡快加速所有程序的瓶頸線程來確保程序之間的公平性。
運行時協作
核心分配器和線程選擇器協作以實現性能和能耗之間的良好折衷,同時確保公平。模型的流程圖如下圖所示。
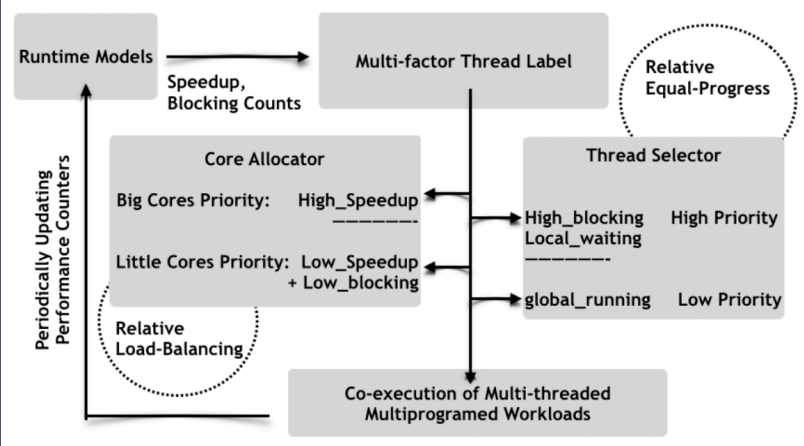
基于加速預測和瓶頸識別的運行時模型,通過定期將就緒線程分類(使用標簽)分為兩個不同的類別來促進協作。
核心分配標簽:在大核心上具有高預測加速的線程將被標記為大核心上的高優先級。具有低預測加速和阻塞級別的線程,即非關鍵線程,將在小核心上獲得高優先級(在大核心上獲得低優先級)。剩余線程在大核或小核上獲得相同的優先級——然后可以自由分配這些線程以平衡核的負載。
線程選擇標簽:具有高阻塞級別的線程將被標記為本地線程選擇的高優先級。無論它們是在大核還是小核上執行,都將給予這些線程相同的優先級。該標簽仍然記錄了當前核心的類型——如果存在具有空運行隊列的相同類型的核心,線程總是優先被相同類型的核心選擇。在小核心上運行的線程也被標記,因為它們可能會在合適的時候被搶占在大核心上遷移和執行,但運行線程永遠不會優先于等待就緒線程。
標簽后處理:在標記過程之后,公平性、核心敏感性和瓶頸加速由線程上的標簽表示,并且可以由核心分配器、線程選擇器或兩者一起處理。基于這種協調模型,核心分配器和線程選擇器從就緒線程集中處理不同的優先級隊列——它們的決策不會像WASH這樣的混合多因素直接排名。相反,他們提供了一個基于時間片的協作方案。
協同多因素模型處理的另一個重要問題是確保線程的平等進展,我們不會干擾線程選擇的優先級和決策,而是根據在大內核上運行的線程的預測加速值,通過按比例縮放的時間片方法在線程中實現相等的進展。大核上的線程片比小核上的相對短。線程選擇功能更頻繁地被觸發以交換大核上的執行線程,這保證了在所有核上執行的線程的相對等進度。運行時模型會定期提取性能計數器,該計數器代表AMP上多線程多程序工作負載的當前執行環境。模型計算更新的運行時因素包括預測的加速值和阻塞計數。此信息附加到線程并報告回多因素貼標機以供下一輪使用。
03總結
本期報告著重介紹了COLAB運行時優化框架,該框架針對非對稱多核處理器(AMP)上的多線程多道程序工作負載。AMP在當今處理器市場尤其是嵌入式系統中占據重要部分。COLAB是第一個通用調度程序,通過對核心敏感性、線程關鍵性和調度公平性做出協作決策,優化了影響AMP調度的所有這三個因素-核心親和力、線程關鍵性和調度公平性。COLAB調度程序在性能方面分別比最先進的WASH、ARMGTS 和LinuxCFS調度程序高出21%、20%和25%,平均系統吞吐量高了6%、2%和15%,與WASH和ARMGTS相比,COLAB實現了平均5%的節能。
審核編輯 :李倩
-
ARM
+關注
關注
134文章
9164瀏覽量
368791 -
多核處理器
+關注
關注
0文章
109瀏覽量
19959 -
線程
+關注
關注
0文章
505瀏覽量
19733
原文標題:面向ARM異構多核系統的運行時性能分析與效能優化
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何優化總線系統的性能
如何優化SOC芯片性能
如何優化FPGA設計的性能
【米爾NXP i.MX 93開發板試用評測】1、異構核心通信的技術內容
CPU單核性能與多核性能的區別
淺談國產異構雙核RISC-V+FPGA處理器AG32VF407的優勢和應用場景
復旦微PS+PL異構多核開發案例分享,基于FMQL20SM國產處理器平臺
66AK2L06多核DSP+ARM KeyStone II片上系統(SoC)數據表

66AK2Hxx多核DSP+ARM? KeyStone II片上系統(SoC)數據表
如何在RK3562J的AMP雙系統實現裸核中斷嵌套機制
一文解析嵌入式多核異構方案,東勝物聯RK3588多核異構核心板系列一覽

多核異構通信框架(RPMsg-Lite)

YY3568多核異構(Linux+RT-Thread)--啟動流程






 工商網監
工商網監
評論