") 算法將如何引領(lǐng)AI芯片的未來
算法將如何引領(lǐng)AI芯片的未來
12納米擊敗4納米。
1970年底,英特爾發(fā)布了“一件劃時代的作品”——Intel 4004微處理器。
這塊全球第一款大規(guī)模商用微處理器,出自英特爾“有史以來最偉大的芯片工程師”費德里科.法金(Frederico Faggin)之手。他將2250個晶體管以10微米的距離,集成在了這片僅有3cm×4cm的芯片上,并把自己的名字縮寫“F.F.”刻了上去。
這塊每秒運算6萬次、能夠處理4bit數(shù)據(jù)、成本僅不到100美元的10微米制程芯片,在當時直接宣告了集成電子設(shè)備新時代的來臨。英特爾CEO戈登.摩爾(Gordon Moore)甚至將4004稱為:人類歷史上最具革新性的產(chǎn)品之一。
如今,距離劃時代的4004芯片已經(jīng)過了51個年頭。在這51年里,芯片技術(shù)急速增長。今年6月蘋果發(fā)布的5納米M2芯片擁有200億晶體管,晶體管數(shù)量已是4004的900萬倍,而制程卻僅是它的兩千分之一。
通常來說,芯片制程決定了其所能集成的晶體管數(shù)量,也直接影響著芯片性能。但制程數(shù)據(jù)也并非完全是越小越好,凡事都有例外。
就在前不久剛剛發(fā)布的MLPerf推理v2.1的榜單中,來自中國深圳的AI計算服務(wù)與平臺提供商墨芯人工智能憑借12納米制程,在Resnet-50模型中超越了4納米制程的英偉達最強GPU芯片H100。
2018年,墨芯人工智能在硅谷創(chuàng)立,目前總部位于深圳。創(chuàng)始團隊來自于卡內(nèi)基梅隆大學頂尖AI科學家、世界頂尖半導(dǎo)體公司(如Intel、Marvell和Oracle等)核心高量產(chǎn)芯片研發(fā)團隊。
甲子光年曾在今年3月報道過墨芯。當時,墨芯即將發(fā)布搭載Antoum芯片的AI計算卡:S4、S10和S30。
盡管與許多明星創(chuàng)業(yè)公司同樣做AI芯片,但墨芯的重點與其他家非常不同。不管是最近火熱的GPGPU,還是曾經(jīng)AI芯片熱潮的ASIC,過去各家公司都把重點放在硬件層面的精進上。但墨芯主打的卻是從軟件——稀疏化算法出發(fā)進行軟硬協(xié)同設(shè)計。
稀疏化算法由于其本身存在一定的難以繞開的技術(shù)難點,以往選擇該路線的芯片公司并不多。但隨著數(shù)據(jù)計算量的增大,稀疏化算法開始越發(fā)展現(xiàn)出其高算力、低功耗、高性價比的價值。
這也是墨芯能夠憑借12納米制程贏下4納米H100的重要原因。
本次的MLPerf中,另一家主打稀疏化算法的美國創(chuàng)業(yè)公司Neural Magic也提交了成績。這是兩家稀疏化算法路線公司首次參加MLPerf,讓MLCommons的創(chuàng)始人David Kanter感嘆:“新架構(gòu)令人振奮,展示出了業(yè)界的創(chuàng)新力和創(chuàng)造力”。
日前,「甲子光年」采訪了墨芯創(chuàng)始人兼CEO王維,與他探討墨芯為何能做到MLPerf的結(jié)果,以及算法將如何引領(lǐng)AI芯片的未來。
1.MLPerf測試——AI算力領(lǐng)域的“圖靈獎”
自英特爾發(fā)布4004后的51年里,芯片制造公司不斷改進工藝,讓單位面積能夠容納更多的晶體管。
英特爾創(chuàng)始人預(yù)計,單位面積的晶體管數(shù)量約每兩年會增加一倍,而芯片性能大約18個月會提升一倍。這就是著名的“摩爾定律”。
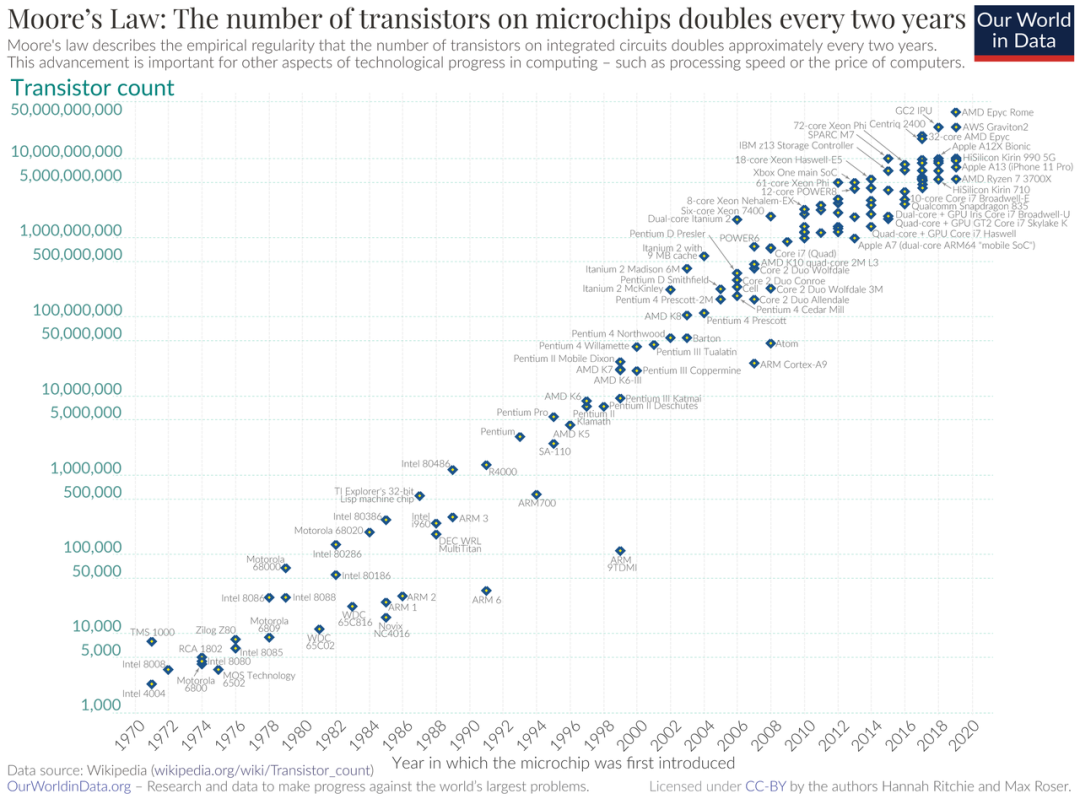
過去10年中,隨著人工智能的快速發(fā)展,數(shù)據(jù)計算量變得越來越大。人們對芯片性能的需求,遠遠超過了芯片性能的增長速度。業(yè)內(nèi)專家估計,目前,人工智能的算力需求每3.5個月就會翻倍。
這就導(dǎo)致原來的CPU不再適用于人工智能計算。而能夠進行海量并行運算的GPU,以及滿足特定功能的ASIC逐漸成為AI計算芯片的主流,伴隨著制程的提升而更新迭代。
為了更好地推動人工智能發(fā)展、建立衡量機器學習性能的行業(yè)指標,2018年,來自谷歌、百度、哈佛大學、斯坦福大學和加州大學伯克利分校的工程師和研究人員,成立了一個名為“MLCommons”的組織,并共同編寫測試套件,用以測試芯片算力,也就是后來的MLPerf。
工作開展得很快。同年,該組織就推出了訓(xùn)練和高性能計算測試套件。并且在隨后的兩年里又推出了3套推理測試套件。
推出套件的同時,MLCommons每年都會邀請世界各個企業(yè)和組織加入,并通過MLPerf套件對芯片性能進行測試。MLCommons每季度都會組織成員提交結(jié)果并發(fā)布成績。每年一、三季度發(fā)布推理結(jié)果,二、四季度發(fā)布訓(xùn)練結(jié)果。
隨著MLCommons越來越受到認可和關(guān)注,加入其中的公司也越來越多。如今,MLCommons已經(jīng)受到全球超過70個公司和組織的支持,除了最初創(chuàng)始的公司外,商業(yè)企業(yè)還包括英特爾、英偉達、Meta、微軟等芯片和云計算巨頭。
本季度的推理測試是MLPerf的第6次測試,共收到超過5300個測試結(jié)果,其中包括中國企業(yè)阿里巴巴、H3C、浪潮、聯(lián)想、墨芯、壁仞。
MLPerf測試主要分為固定任務(wù)(Closed division)和開放任務(wù)(Open division)兩種。
根據(jù)MLCommons官方信息,MLPerf為了鼓勵軟件和硬件創(chuàng)新,有兩個分區(qū),在實現(xiàn)結(jié)果時有不同程度的靈活性。封閉任務(wù)旨在對硬件平臺或軟件框架進行標準一致的比較,要求使用與參考模型相同的模型。開放任務(wù)旨在促進創(chuàng)新,允許使用不同的模型或重新訓(xùn)練。
簡單來說,固定任務(wù)更關(guān)注硬件能力,而開放任務(wù)更關(guān)注創(chuàng)新的可能性,即軟件和硬件融合的能力。由此來看,開放任務(wù)更可能暗示未來人工智能計算的發(fā)展方向。
值得注意的是,如果開放任務(wù)的參賽者使用了不同的模型和數(shù)據(jù)集,需要在提交的結(jié)果中標示出來,由此可以提供開放任務(wù)和固定任務(wù)的比較維度。
本次測試中,墨芯S30計算卡以95784 FPS的單卡算力,奪得Resnet-50模型算力全球第一,是全球旗艦產(chǎn)品H100的1.2倍,是A100的2倍。
同時,墨芯S30運行BERT-Large是A100的2倍,僅次于H100,在Bert-large高精度模型(99.9%),單卡算力達3837 SPS。

作為一個國際組織,MLCommons除了組織成員企業(yè)測試之外,更重要的在于推進行業(yè)內(nèi)的交流。這個季度剛開始,MLCommons就著手聯(lián)系成員企業(yè),并輔導(dǎo)大家每個階段應(yīng)該如何提交數(shù)據(jù)。
過去三個月里,參與測試的成員企業(yè)每周都會開展線上會議。墨芯與國際芯片廠商高通、英偉達、英特爾等公司交流探討,不僅了解到各家對于AI計算的側(cè)重點、如何評價算力性能等,更意識到了企業(yè)之間開放互助態(tài)度,并共同將此作為共識向下推進。
也正是這種企業(yè)之間互助的態(tài)度和對技術(shù)創(chuàng)新的追求,讓算法有機會從硬件的競賽中脫穎而出。
2.稀疏化計算——從冷門到熱門
不同于其他公司,墨芯的特色在于稀疏化算法。
稀疏化計算并不是一項新技術(shù)。
“稀疏化計算”的原理不難理解,是指在原有AI計算的大量矩陣運算中,將含有0元素和無效元素剔除,讓神經(jīng)網(wǎng)絡(luò)模型消減冗余,以顯著加快計算速度,提高計算性能。
比如在人臉識別的場景中,傳統(tǒng)的算法需要計算圖片中的所有元素與現(xiàn)有圖片模型的關(guān)聯(lián),而后得出結(jié)論;但稀疏化計算會先在圖片中找出需要比對的元素,而后只需計算這些元素與現(xiàn)有圖片模型的關(guān)聯(lián),不再計算圖片中其他的無效元素。
由于稀疏化算法的這種特性,過去它一直被業(yè)內(nèi)質(zhì)疑會因為舍棄元素而導(dǎo)致最終結(jié)果并不準確。但隨著人工智能所需要計算的數(shù)據(jù)量的急劇膨脹,尋求更高效率、更高性價比的算法,在今天顯得越發(fā)重要。
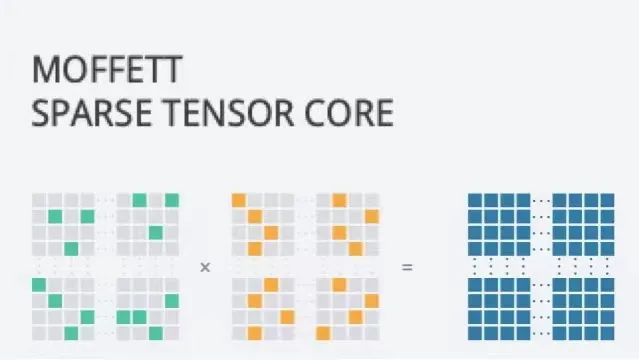
于是近幾年,科技巨頭都開始表達出對稀疏化計算的興趣。
Meta AI 西雅圖研究負責人Luke Zettlemoyer教授指出,在巨大的數(shù)據(jù)量下,訓(xùn)練大模型的難度也在急劇增加。“如果想要模型繼續(xù)變大,最終不得不做出妥協(xié):不再使用稠密的神經(jīng)網(wǎng)絡(luò),而是采用稀疏化的思想”。
谷歌人工智能主管Jeff Dean在今年三月提交了論文,闡述了新的通用AI架構(gòu)Pathways。稀疏、通用和高效是它的關(guān)鍵詞。
更重要的信號來自于硬件領(lǐng)域。
與以往完全不同,硬件公司如今也開始支持稀疏化計算。英偉達在2020年發(fā)布的基于Ampere架構(gòu)的A100芯片,支持2倍的稀疏化計算;今年7月,英特爾與阿里巴巴DeepRec開源推薦引擎合作,共同探索稀疏化模型的訓(xùn)練與預(yù)測。
根據(jù)稀疏化算法的原理,稀疏化計算天然擁有快速、節(jié)省能耗的特性。例如同樣作為旗艦加速卡,A100功耗為400W,H100更是飆升到了700W;而墨芯的S4僅有75W,S30也僅有250W。
而且墨芯采用的還是12納米的工藝,相對于H100的4納米與A100的7納米工藝,成本上預(yù)計節(jié)省一個數(shù)量級。
業(yè)內(nèi)對稀疏化計算的質(zhì)疑主要在于兩方面:
第一,稀疏化計算在訓(xùn)練和執(zhí)行模型進行“稀疏”的步驟時是否會增加資源消耗,從而導(dǎo)致整體的優(yōu)化率不高;
第二,稀疏化計算是否會損失精度。
墨芯CEO王維告訴「甲子光年」:目前墨芯的計算卡已經(jīng)能夠達到4~32倍的稀疏率。通過計算卡優(yōu)化模型,這個過程是“一勞永逸”的。也即優(yōu)化完成后,企業(yè)再做計算時可以直接開啟“瘦身加速”模式。
而在精度層面,MLPerf測試本身就對精度有很高的要求,參賽提交者需要達到相應(yīng)的精度要求才能通過審核。
從MLPerf公布的結(jié)果看,墨芯采用的是和固定任務(wù)賽道同樣的模型和數(shù)據(jù)集,選擇的模型也是Bert-large高精度模型——Bert-large99.9%,即結(jié)果精度需要達到官方原始Bert模型精度90.9的99.9%,也就是90.8%以上。
而在實際任務(wù)中,墨芯面對精度需求嚴格的客戶,采取使用“更大模型+高稀疏倍率”模式,兼顧其對于大幅提高算力和保證精度的要求;反之,對于算力優(yōu)先的客戶,可以在可接受的范圍內(nèi)調(diào)整精度,換取更高倍率的加速。
但對于墨芯來說,這些都只是剛剛開始。
目前,不管是墨芯還是墨芯的客戶,都主要在推理側(cè)用到稀疏化計算,而在訓(xùn)練側(cè)依舊是稠密計算。未來,墨芯希望將稀疏化帶入訓(xùn)練端,創(chuàng)造更多的性能提升。
3.AI芯片2.0——算法與硬件融合發(fā)展
既然稀疏化算法早已存在,并且具有一定的可取之處,為什么過去沒有公司來做呢?背后的答案其實非常簡單:因為原有的GPU不支持。
人工智能計算本質(zhì)是海量的并行計算。相對于CPU而言,GPU擁有許多結(jié)構(gòu)簡單的計算單元,適合處理海量并行計算。但在稀疏化計算中,這些簡單的計算單元在內(nèi)部很難進行高倍的稀疏。
比如英偉達的Tensor Core,擁有4*4的結(jié)構(gòu),就無法實現(xiàn)墨芯需要的32倍的稀疏。
墨芯的首席科學家嚴恩勖曾在采訪中指出,推進稀疏化計算過程中最大的挑戰(zhàn)在于“找不到合適的硬件”。
所以,為了同時滿足高倍稀疏化和大規(guī)模并行運算,墨芯決定從算法和軟件出發(fā),重新定義相應(yīng)的架構(gòu)和硬件。墨芯堅持軟硬協(xié)同開發(fā),構(gòu)建了持續(xù)多層次優(yōu)化稀疏運算的底層算法能力,架構(gòu)保證可編程性、高度可拓展性及快速迭代能力,讓整個硬件從設(shè)計之初就完全地支持算法。
這顛覆了外界對AI芯片公司的想象。
一直以來,芯片公司總是從硬件架構(gòu)來精進,比如GPU、ASIC專用芯片,以及近年來受到關(guān)注的Chiplet、存算一體等技術(shù),都是硬件的迭代。軟件像是附屬品,幾乎不被提起。
但事實上,幾乎每家AI芯片公司都有比硬件工程師人數(shù)更多的軟件團隊。比如墨芯目前的軟硬件人數(shù)比大約為6:4。英偉達每年芯片發(fā)布后,次年依靠軟件和系統(tǒng)的升級,又可以提升50%以上的效果。
中國最早一批成立和上市的AI芯片公司寒武紀,在英偉達的CUDA之外,重新搭建了自己的軟件系統(tǒng)。但整個過程不僅花費了比硬件更多的時間和人力,教育依舊長路漫漫。吸取了寒武紀的經(jīng)驗,新創(chuàng)業(yè)的AI芯片公司,都在軟件層面兼容CUDA,但又逐步推出自己的軟件棧,吸引更多人加入研發(fā)。
而墨芯走了一條不一樣的路——從創(chuàng)業(yè)之初就堅持以算法和軟件為主,基于算法來設(shè)計架構(gòu)和硬件。
王維告訴「甲子光年」:“其實在我看來,這些都是計算科學的問題,軟硬件我不太區(qū)分。只是到具體技術(shù)實現(xiàn)的時候,哪些事情用硬件做,哪些事情用軟件做而已,本質(zhì)上大家都在解決計算問題”。
墨芯在此次MLPerf的成績正是這種理念照射進現(xiàn)實。軟硬件協(xié)同設(shè)計的創(chuàng)新稀疏化架構(gòu)讓高倍率稀疏計算得以實現(xiàn),助力墨芯達成MLPerf出色結(jié)果。
在S30的芯片架構(gòu)設(shè)計中,除了用于原生稀疏卷積和矩陣計算的稀疏處理單元(SPU),該處理器還集成了一個矢量處理單元(VPU),實現(xiàn)了靈活的可編程性,以跟上AI模型的快速發(fā)展。
對于一個創(chuàng)業(yè)公司來說,需要找到一個具有顛覆性的角度和方向。墨芯專注于稀疏化計算,并通過硬件適配算法的方式,希望把稀疏化計算的潛力發(fā)揮到極致。通過這一路徑,墨芯的目標不僅僅是“替代”現(xiàn)有的GPU,還要創(chuàng)造更多的可能性。
著名的自然語言大模型GPT-3擁有1700多億參數(shù)。應(yīng)用GPU來運行這個模型,需要10張A100的加速卡才行。但應(yīng)用稀疏化算法,一張墨芯的S30卡就可以讓這個模型跑起來。
這其中的差異,并不只是1張卡和10張卡的成本的區(qū)別,它還意味著能夠解決更多技術(shù)方面的難題。比如10張卡連接時候的計算能力損耗,在1張卡時就無需考慮;又如在功耗限制下運行的復(fù)雜計算也會成為可能。
在未來,通過稀疏化計算,企業(yè)能夠有機會設(shè)計出更為復(fù)雜的模型,為產(chǎn)業(yè)應(yīng)用創(chuàng)造新的機會。
目前,墨芯已在一些頭部互聯(lián)網(wǎng)公司進入適配階段;在垂直行業(yè)市場,墨芯也已經(jīng)與生命科學領(lǐng)域的頭部企業(yè)達成合作。
未來,AI芯片和算法都需要往更通用和智能的方向發(fā)展。正如王維所說,我們不僅要關(guān)注芯片企業(yè)是如何發(fā)展起來的,也要關(guān)注AI本身是如何發(fā)展的。
最終,AI芯片的本質(zhì)是支撐和賦能算法。當AI芯片從1.0邁向2.0,軟硬融合將成為最重要的競爭力。
審核編輯 :李倩
-
算法
+關(guān)注
關(guān)注
23文章
4625瀏覽量
93143 -
晶體管
+關(guān)注
關(guān)注
77文章
9728瀏覽量
138643 -
AI芯片
+關(guān)注
關(guān)注
17文章
1901瀏覽量
35139
原文標題:算法引領(lǐng)AI芯片走入2.0時代 | 甲子光年
文章出處:【微信號:jazzyear,微信公眾號:甲子光年】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
【「從算法到電路—數(shù)字芯片算法的電路實現(xiàn)」閱讀體驗】+介紹基礎(chǔ)硬件算法模塊
AI for Science:人工智能驅(qū)動科學創(chuàng)新》第4章-AI與生命科學讀后感
平衡創(chuàng)新與倫理:AI時代的隱私保護和算法公平
后摩智能引領(lǐng)AI芯片革命,推出邊端大模型AI芯片M30
Imagination 引領(lǐng)邊緣計算和AI創(chuàng)新,擁抱AI未來發(fā)展

聚焦AI技術(shù)引領(lǐng),智象未來全面賦能圖片及視頻內(nèi)容生產(chǎn)

中國AI芯片行業(yè),自主突破與未來展望

賦能未來:VOC技術(shù)如何引領(lǐng)AI新篇章
risc-v多核芯片在AI方面的應(yīng)用
炬芯科技趙新中:無線音頻SoC的AI算法未來和應(yīng)用







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論