 如何計算模型對預測結果的信心
如何計算模型對預測結果的信心
在很多問題中,獲取標注準確的大量數據需要很高的成本,這也往往限制了深度學習的應用。主動學習通過對未標注的數據進行篩選,可以利用少量的標注數據取得較高的學習準確度。本文將提供代碼實現,展示實驗效果及一些思考。
1. 原理
通過命名實體識別模型對未標注數據進行預測,根據不同的評價標準計算模型對該數據預測結果的信心(概率)。對于信心較低的樣本,往往包含模型更多未知的信息,挑選出這些信心較低的樣本進行優先標注。更詳細的原理可以閱讀參考文章:基于深度主動學習的命名實體識別[1](這篇小喵很早之前已經拜讀過了,非常推薦大家閱讀,相信大家一定會有所收獲)。
2. 模型設計
模型的上游采用Bert,采用最普通的序列標注的方式,即在 token-level 進行多標簽分類。
另一方面,為了解決實體重疊的問題,使用 Sigmoid 代替 SoftMax。
此外,我們沒有使用 crf 層,在原論文中也沒有使用 crf 層。這樣做的原因主要是因為主動學習是為了挑選出最有標注價值的數據,而不是為了追求模型的準確率。crf 層會增加模型預測的時間,所以沒有選擇使用。
3. 如何計算模型對預測結果的信心
這里介紹論文中提及的兩種計算方式 Least Confidence(簡稱 LC)和 Maximum Normalized Log-Probality(簡稱 MNLP):
LC:是計算預測中最大概率序列的對應概率值。
MNLP:基于 LC 并且考慮到生成中的序列長度對于不確定性的影響,我們做一個 normalization(即除以每個句子的長度),概率則是用每一個點概率輸出的 log 值求和來代替。
在論文中作者表示 MNLP 是非常理想的方法。在實際實驗中 MNLP 比 LC 更為”公平“。原因是:句子越長,對于 LC 這種評價標準來說,分數會更高;而 MNLP 不會。
但是在研究 MNLP 給出評分較高和較低的case后,會發現 MNLP 對于句子中預測出的實體數量很敏感,如果預測出的實體很少,分數往往很高,相對的,實體數量很多,分數會很低。
所以本文的實現中提供了一種補償方案,在 MNLP 的基礎上根據實體數量進行補償,讓其對實體數量不那么敏感。具體的做法是除以一個補償參數 ,這個參數主要由句子中預測出的實體數決定。
代碼
lc_confidence=0 MNLP_confidence=0 forlableinlabels: lc_con=1 mnlp_con=1 forlinlable: ifl<=?0.5: ????????????????l?=?1?-?l ????????????lc_con?*=?l ????????????mnlp_con?+=?math.log(l) ????????lc_confidence?+=?lc_con??? ????????MNLP_confidence?+=?mnlp_con ????MNLP_confidence?=?MNLP_confidence/(len(labels)) ????entry_MNLP_confidence?=?1?-?(1?-?MNLP_confidence)/((len(res)?+?2)**0.5)?*?(2)
其中 labels 是模型對句子序列預測的結果 可以參考下圖示例。其中,單元格中的數字代表:對應標簽類別對當前位置是否屬于自己類別的預測概率。
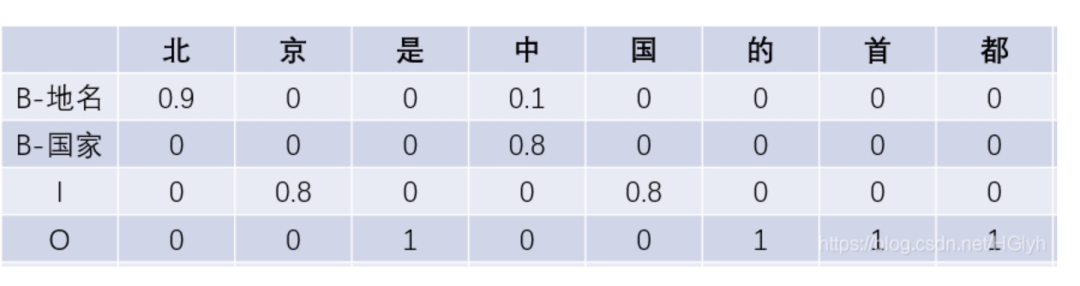
舉個例子,0.9 代表模型預測 ‘北’ 字是 ‘B-地名’ 標簽的概率為0.9。對于B-地名標簽來說,就有
4. 結果與思考
結果示例
"'公告編號:2021-067中南紅文化集團股份有限公司關于公司職工代表監事辭職暨補選職工代表監事的公告本公司及監事會全體成員保證信息披露內容真實、準確和完整,沒有虛假記載、誤導性陳述或者重大遺漏。中南紅文化集團股份有限公司(以下簡稱“公司”)監事會于2021年6月11日收到公司職工代表監事王哲女士提交的書面辭職報告。王哲女士因個人原因申請辭去公司第五屆監事會職工代表監事職務。王哲女士辭職后,不再擔任公司任何職務。截至本公告發布之日,王哲女士未持有公司股份。":{ "res":[ [ "中南紅文化集團股份有限公司", "職位變動_辭職_公司" ], [ "職工代表監事", "職位變動_辭職_職位" ], [ "王哲", "職位變動_辭職_人物" ] ], "LC":217.5803241119802, "MNLP_confidence":0.9695068267227575, "entry_MNLP_confidence":0.9863630383404811 }, "3月31日,金剛玻璃再次發布公告,董事會于3月29日收到汕頭市公安局送達的《拘留通知書》,董事莊毓新因涉嫌違規披露、不披露重要信息罪被刑事拘留。圖片來源:深交所面對董秘辭職、董事被刑拘,金剛玻璃4月7日發布公告,公司董事會將提前換屆選舉。此前,金剛玻璃還曾因信披違規等被證監會處罰。2020年4月,廣東證監局對金剛玻璃下發《行政處罰決定書》和《市場禁入決定書》。經查,2015年-2018年間,金剛玻璃存在虛增營收、利潤、貨幣資金以及未按規定披露關聯交易等違法行為。":{ "res":[ [ "金剛玻璃", "職位變動_辭職_公司" ] ], "LC":219.0427916272391, "MNLP_confidence":0.9781149683847055, "entry_MNLP_confidence":0.9873646711056863 },
思考
通過主動學習的結果,我們可以得到信心最少的樣本進行標注。同時信心最大的樣本也需要我們關注,如果這些樣本中存在明顯的錯誤,是否我們可以認為模型學到了一些錯誤信息,并且特別的自信呢。
-
數據
+關注
關注
8文章
7104瀏覽量
89294 -
模型
+關注
關注
1文章
3279瀏覽量
48974 -
代碼
+關注
關注
30文章
4809瀏覽量
68817 -
nlp
+關注
關注
1文章
489瀏覽量
22064
原文標題:寫在前面
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
永磁同步電機模型預測控制matlab/simulink仿真模型
模型預測控制+邏輯控制
LabVIEW進行癌癥預測模型研究
基于短波的天波傳播衰減預測模型
膜計算優化支持向量機的風速預測
如何使用改進GM模型進行房價預測模型資料說明
工作流故障并了解如何預測它們
工作流故障并了解如何預測它們






 工商網監
工商網監
評論