 知識圖譜構建與應用推薦學習分享
知識圖譜構建與應用推薦學習分享
一、語言表征學習 Language Representation Learning
通過自監督語言模型預訓練的語言表征學習已經成為許多NLP系統的一個組成部分。傳統的語言建模不利用文本語料庫中經常觀察到的實體事實,如何將知識整合到語言表征中已引起越來越多的關注。
二、知識圖譜語言模型(KGLM):通過選擇和復制實體來學習并呈現知識。
ERNIE-Tsinghua:通過聚合的預訓練和隨機Mask來融合信息實體。
K-BERT:將領域知識注入BERT上下文編碼器。
ERNIE-Baidu:引入了命名實體Mask和短語Mask以將知識集成到語言模型中,并由ERNIE 2.0通過持續的多任務學習進一步改進。
KEPLER:為了從文本中獲取事實知識,通過聯合優化將知識嵌入和Mask語言建模損失相結合。
GLM:提出了一種圖引導的實體Mask方案來隱式地利用知識圖譜。
CoLAKE:通過統一的詞-知識圖譜和改進的Transformer編碼器進一步利用了實體的上下文。
BERT-MK:與K-BERT模型類似,更專注于醫學語料庫,通過知識子圖將醫學知識集成到預訓練語言模型中。
Petroni等人:重新思考語言模型的大規模訓練和知識圖譜查詢,分析了語言模型和知識庫,他們發現可以通過預訓練語言模型獲得某些事實知識。
基于知識圖譜的問答(KG-QA)用知識圖譜中的事實回答自然語言問題。基于神經網絡的方法表示分布式語義空間中的問題和答案,有些方法還進行符號知識注入以進行常識推理。
Single-fact QA:以知識圖譜為外部知識源,simple factoid QA或single-fact QA是回答一個涉及單個知識圖譜事實的簡單問題。
Dai等人:提出了一種條件聚焦神經網絡,配備聚焦修剪以減少搜索空間。
BAMnet:使用雙向注意機制對問題和知識圖譜之間的雙向交互進行建模。盡管深度學習技術在KG-QA中得到了廣泛應用,但它們不可避免地增加了模型的復雜性。
Mohammed等人:通過評估有和沒有神經網絡的簡單KG-QA,發現復雜的深度模型(如LSTM和GRU等啟發式算法)達到了最先進的水平,非神經模型也獲得了相當好的性能。
多跳推理(Multi-hop Reasoning):處理復雜的多跳關系需要更專門的設計才能進行多跳常識推理。結構化知識提供了信息豐富的常識,這促進了最近關于多跳推理的符號空間和語義空間之間的常識知識融合的研究。
Bauer等人:提出了多跳雙向注意力和指針生成器(pointer-generator)解碼器,用于有效的多跳推理和連貫的答案生成,利用來自ConceptNet的relational path selection和selectively-gated注意力注入的外部常識知識。
Variational Reasoning Network(VRN):使用reasoning-graph嵌入進行多跳邏輯推理,同時處理主題實體識別中的不確定性。
KagNet:執行concept recognition以從ConceptNet構建模式圖,并通過GCN、LSTM和hierarchical path-based attention學習基于路徑的關系表示。
CogQA:結合了implicit extraction和explicit reasoning,提出了一種基于BERT和GNN的認知圖模型,用于多跳QA。
將知識圖譜集成為外部信息,使推薦系統具備常識推理能力,具有解決稀疏問題和冷啟動問題的潛力。通過注入實體、關系和屬性等知識圖譜的輔助信息,許多方法致力于使用基于嵌入的正則化模塊以改進推薦效果。
collaborative CKE:通過平移KGE模型和堆疊自動編碼器聯合訓練KGE、文本信息和視覺內容。
DKN:注意到時間敏感和主題敏感的新聞文章由大量密集的實體和常識組成,通過知識感知CNN模型將知識圖譜與多通道word-entity-aligned文本輸入相結合。但是,DKN不能以端到端的方式進行訓練,因為它需要提前學習實體嵌入。
MKR:為了實現端到端訓練,通過共享潛在特征和建模高階項目-實體交互,將多任務知識圖譜表示和推薦相關聯。
KPRN:雖然其他工作考慮了知識圖譜的關系路徑和結構,但KPRN將用戶和項目之間的交互視為知識圖譜中的實體關系路徑,并使用LSTM對路徑進行偏好推斷以捕獲順序依賴關系。
PGPR:在基于知識圖譜的user-item交互上執行reinforcement policy-guided的路徑推理。
KGAT:在entity-relation和user-item圖的協作知識圖譜上應用圖注意力網絡,通過嵌入傳播和基于注意力的聚合對高階連接進行編碼。
總而言之,基于知識圖的推薦本質上是通過在知識圖譜中嵌入傳播與多跳來處理可解釋性。
五、文本分類和特定任務應用程序 Text Classification and Task-Specific Applications
知識驅動的自然語言理解(NLU)是通過將結構化知識注入統一的語義空間來增強語言表征能力。最近成果利用了明確的事實知識和隱含的語言表征。
Wang等人:通過加權的word-concept嵌入,通過基于知識的conceptualization增強了短文本表征學習。
Peng等人:集成了外部知識庫,以構建異構信息圖譜,用于短社交文本中的事件分類。
在精神衛生領域,具有知識圖譜的模型有助于更好地了解精神狀況和精神障礙的危險因素,并可有效預防精神健康導致的自殺。
Gaurs等人:開發了一個基于規則的分類器,用于知識驅動的自殺風險評估,其中結合了醫學知識庫和自殺本體的自殺風險嚴重程度詞典。
情感分析與情感相關概念相結合,可以更好地理解人們的觀點和情感。
SenticNet:學習用于情感分析的概念原語,也可以用作常識知識源。為了實現與情感相關的信息過濾。
Sentic LSTM:將知識概念注入到vanilla LSTM中,并為概念級別的輸出設計了一個知識輸出門,作為對詞級別的補充。
對話系統 Dialogue Systems
問答(QA)也可以被視為通過生成正確答案作為響應的單輪對話系統,而對話系統考慮對話序列并旨在生成流暢的響應以通過語義增強和知識圖譜游走來實現多輪對話。
Liu等人:在編碼器-解碼器框架下,通過知識圖譜檢索和圖注意機制對知識進行編碼以增強語義表征并生成知識驅動的響應。
DialKG Walker:遍歷符號知識圖譜以學習對話中的上下文轉換,并使用注意力圖路徑解碼器預測實體響應。
通過形式邏輯表示的語義解析是對話系統的另一個方向。
Dialog-to-Action:是一種編碼器-解碼器方法,通過預定義一組基本動作,它從對話中的話語映射可執行的邏輯形式,以在語法引導解碼器的控制下生成動作序列。
六、醫學和生物學 Medicine and Biology
知識驅動的模型及其應用為整合領域知識以在醫學和生物學領域進行精確預測鋪平了道路。醫學應用涉及有眾多醫學概念的特定領域知識圖譜。
Sousa等人:采用知識圖譜相似性進行蛋白質-蛋白質相互作用預測,使用基因本體。
Mohamed等人:將藥物-靶點相互作用預測設定為生物醫學知識圖譜中與藥物及其潛在靶點的鏈接預測。
Lin等人:開發了一個知識圖譜網絡來學習藥物-藥物相互作用預測的結構信息和語義關系。
UMLS:在臨床領域,來自Unified Medical Language Systems(UMLS)本體的生物醫學知識被集成到語言模型預訓練中,用于臨床實體識別和醫學語言推理等下游臨床應用。
Liu等人:設定了醫學圖像報告生成的任務,包括編碼、檢索和釋義三個步驟。
知識圖譜相關信息學習:
一、知識圖譜概論
1.1知識圖譜的起源和歷史
1.2知識圖譜的發展史——從框架、本體論、語義網、鏈接數據到知識圖譜
1.3知識圖譜的本質和價值
1.4知識圖譜VS傳統知識庫VS關系數據庫
1.5經典的知識圖譜
1.5.1經典的CYC, WordNnet, WikiData, DBpedia, YAGO, NELL等知識庫
1.5.2行業知識圖譜:
Google知識圖譜,微軟實體圖,阿里知識圖譜,醫學知識圖譜,基因知識圖譜等知識圖譜項目
二、知識圖譜應用
2.1知識圖譜應用場景
2.2知識圖譜應用簡介
2.2.1知識圖譜在數字圖書館上的應用
2.2.2知識圖譜在國防、情報、公安上的應用
2.2.3知識圖譜在金融上的應用
2.2.4知識圖譜在電子商務中的應用
2.2.5知識圖譜在農業、醫學、法律等領域的應用
2.2.6知識圖譜在制造行業的應用
2.2.7知識圖譜在大數據融合中的應用
2.2.8知識圖譜在人機交互(智能問答)中的應用
三、知識表示與知識建模
3.1知識表示概念
3.2 知識表示方法
a.語義網絡 b.產生式規則 c.框架系統 d.描述邏輯 e.本體 f.RDF和RDFS
g.OWL和OWL2 Fragmentsh.SPARQL查詢語言
i.Json-LD、RDFa、HTML5 MicroData等新型知識表示
3.3典型知識庫項目的知識表示
3.4知識建模方法學
3.5知識表示和知識建模實踐
1.三國演義知識圖譜的表示和建模實踐案例
2.學術知識圖譜等
四、知識抽取與挖掘
4.1知識抽取基本問題
a.實體識別 b.關系抽取 c.事件抽取
4.2數據采集和獲取
4.3面向結構化數據的知識抽取
a.D2RQb.R2RML
4.4面向半結構化數據的知識抽取
a.基于正則表達式的方法b.基于包裝器的方法
4.5.面向非結構化數據的知識抽取
a.實體識別技術(基于規則、機器學習、深度學習、半監督學習、預訓練等方法)
b.關系抽取技術(基于模板、監督、遠程監督、深度學習等方法)
c.事件抽取技術(基于規則、深度學習、強化學習等方法)
4.6.知識挖掘
a.實體消歧b.實體鏈接c.類型推斷 d.知識表示學習
4.7知識抽取上機實踐
A.面向半結構化數據的三國演義知識抽取
B.面向文本的三國演義知識抽取
C.人物關系抽取
五、知識融合
5.1知識融合背景
5.2知識異構原因分析
5.3知識融合解決方案分析
5.4.本體對齊基本流程和常用方法
a.基于文本的匹配 b.基于圖結構的匹配 c.基于外部知識庫的匹配
e.不平衡本體匹配 d.跨語言本體匹配f.弱信息本體匹配
5.5實體匹配基本流程和常用方法
a.基于相似度的實例匹配b.基于規則或推理的實體匹配
c.基于機器學習的實例匹配 d.大規模知識圖譜的實例匹配
(1)基于分塊的實例匹配
(2)無需分塊的實例匹配
(3)大規模實例匹配的分布式處理
5.6 知識融合上機實踐
1.百科知識融合
2.OAEI知識融合任務
六、存儲與檢索
6.1.知識圖譜的存儲與檢索概述
6.2.知識圖譜的存儲
a.基于表結構的存儲b.基于圖結構的存儲
6.3.知識圖譜的檢索
a.關系數據庫查詢:SQL語言b數據庫查詢:SPARQL語言
6.4.上機實踐案例:利用GraphDB完成知識圖譜的存儲與檢索
七、知識推理
7.1.知識圖譜中的推理技術概述
7.2.歸納推理:學習推理規則
a.歸納邏輯程設計?b.關聯規則挖掘c.路徑排序算法
上機實踐案例:利用AMIE+算法完成Freebase數據上的關聯規則挖掘
7.3.演繹推理:推理具體事實
?a.馬爾可夫邏輯網 b.概率軟邏輯
7.4.基于分布式表示的推理
a.TransE模型及其變種b.RESCAL模型及其變種
c.(深度)神經網絡模型介紹d.表示學習模型訓練
7.5.上機實踐案例:利用分布式知識表示技術完成Freebase上的鏈接預測
八、語義搜索
8.1.語義搜索概述
8.2.搜索關鍵技術
a.索引技術:倒排索引
b.排序算法:BM25及其擴展
8.3.知識圖譜搜索
a.實體搜索
b.關聯搜索
8.4.知識可視化a.摘要技術
8.5.上機實踐案例:SPARQL搜索
九、知識問答
9.1.知識問答概述
9.2.知識問答基本流程
9.3.相關測試集:QALD、WebQuestions等
9.4.知識問答關鍵技術
a.基于模板的方法
b.語義解析
c.基于深度學習的方法
9.5.上機實踐案例:DeepQA、TemplateQA
-
AI
+關注
關注
87文章
30896瀏覽量
269088 -
機器學習
+關注
關注
66文章
8418瀏覽量
132635 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7709
發布評論請先 登錄
相關推薦
傳音旗下人工智能項目榮獲2024年“上海產學研合作優秀項目獎”一等獎

傳音旗下小語種AI技術榮獲2024年“上海產學研合作優秀項目獎”一等獎

微軟與豆神教育攜手共同開啟Windows 11 AI+PC教育全新體驗

58大新質生產力產業鏈圖譜

三星自主研發知識圖譜技術,強化Galaxy AI用戶體驗與數據安全
中科曙光入選2024算力服務產業圖譜及算力服務產品名錄
三星電子成功收購英國初創公司,致力開發AI核心技術
三星電子將收購英國知識圖譜技術初創企業
知識圖譜與大模型之間的關系

利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(下)

利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(上)
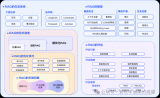
知識圖譜基礎知識應用和學術前沿趨勢





 工商網監
工商網監
評論