 基于COCO的預訓練模型mAP對應關系
基于COCO的預訓練模型mAP對應關系
torchvision對象檢測介紹
Pytorch1.11版本以上支持Torchvision高版本支持以下對象檢測模型的遷移學習:
- Faster-RCNN - Mask-RCNN - FCOS - RetinaNet - SSD - KeyPointsRCNN其中基于COCO的預訓練模型mAP對應關系如下:
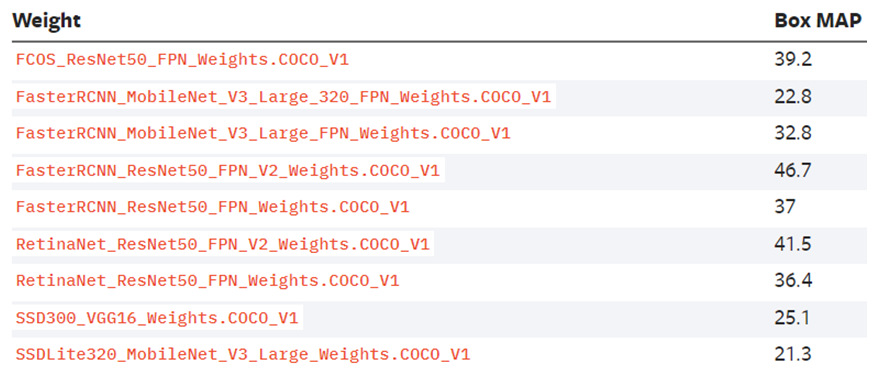


最近一段時間本人已經全部親測,都可以轉換為ONNX格式模型,都可以支持ONNXRUNTIME框架的Python版本與C++版本推理,本文以RetinaNet為例,演示了從模型下載到導出ONNX格式,然后基于ONNXRUNTIME推理的整個流程。
RetinaNet轉ONNX
把模型轉換為ONNX格式,Pytorch是原生支持的,只需要把通過torch.onnx.export接口,填上相關的參數,然后直接運行就可以生成ONNX模型文件。相關的轉換代碼如下:
model=tv.models.detection.retinanet_resnet50_fpn(pretrained=True) dummy_input=torch.randn(1,3,1333,800) model.eval() model(dummy_input) im=torch.zeros(1,3,1333,800).to("cpu") torch.onnx.export(model,im, "retinanet_resnet50_fpn.onnx", verbose=False, opset_version=11, training=torch.onnx.TrainingMode.EVAL, do_constant_folding=True, input_names=['input'], output_names=['output'], dynamic_axes={'input':{0:'batch',2:'height',3:'width'}} )運行時候控制臺會有一系列的警告輸出,但是絕對不影響模型轉換,影響不影響精度我還沒做個仔細的對比。 模型轉換之后,可以直接查看模型的輸入與輸出結構,圖示如下:
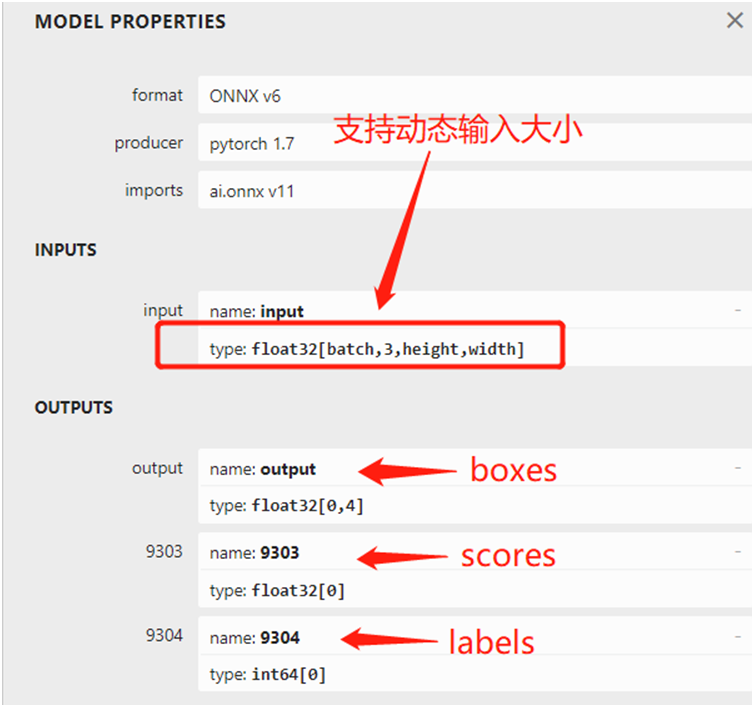
RetinaNet的ONNX格式推理
基于Python版本的ONNXRUNTIME完成推理演示,這個跟我之前寫過一篇文章Faster-RCNN的ONNX推理演示非常相似,大概是去年寫的,鏈接在這里: 代碼很簡單,只有三十幾行,Python就是方便使用,這里最需要注意的是輸入圖像的預處理必須是RGB格式,需要歸一化到0~1之間。對得到的三個輸出層分別解析,就可以獲取到坐標(boxes里面包含的實際坐標,無需轉換),推理部分的代碼如下:
importonnxruntimeasort
importcv2ascv
importnumpyasnp
importtorchvision
coco_names={'0':'background','1':'person','2':'bicycle','3':'car','4':'motorcycle','5':'airplane','6':'bus',
'7':'train','8':'truck','9':'boat','10':'trafficlight','11':'firehydrant','13':'stopsign',
'14':'parkingmeter','15':'bench','16':'bird','17':'cat','18':'dog','19':'horse','20':'sheep',
'21':'cow','22':'elephant','23':'bear','24':'zebra','25':'giraffe','27':'backpack',
'28':'umbrella','31':'handbag','32':'tie','33':'suitcase','34':'frisbee','35':'skis',
'36':'snowboard','37':'sportsball','38':'kite','39':'baseballbat','40':'baseballglove',
'41':'skateboard','42':'surfboard','43':'tennisracket','44':'bottle','46':'wineglass',
'47':'cup','48':'fork','49':'knife','50':'spoon','51':'bowl','52':'banana','53':'apple',
'54':'sandwich','55':'orange','56':'broccoli','57':'carrot','58':'hotdog','59':'pizza',
'60':'donut','61':'cake','62':'chair','63':'couch','64':'pottedplant','65':'bed',
'67':'diningtable','70':'toilet','72':'tv','73':'laptop','74':'mouse','75':'remote',
'76':'keyboard','77':'cellphone','78':'microwave','79':'oven','80':'toaster','81':'sink',
'82':'refrigerator','84':'book','85':'clock','86':'vase','87':'scissors','88':'teddybear',
'89':'hairdrier','90':'toothbrush'}
transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
sess_options=ort.SessionOptions()
src=cv.imread("D:/images/mmc.png")
cv.namedWindow("Retina-NetDetectionDemo",cv.WINDOW_AUTOSIZE)
image=cv.cvtColor(src,cv.COLOR_BGR2RGB)
blob=transform(image)
c,h,w=blob.shape
input_x=blob.view(1,c,h,w)
defto_numpy(tensor):
returntensor.detach().cpu().numpy()iftensor.requires_gradelsetensor.cpu().numpy()
#computeONNXRuntimeoutputprediction
ort_inputs={ort_session.get_inputs()[0].name:to_numpy(input_x)}
ort_outs=ort_session.run(None,ort_inputs)
#(N,4)dimensionalarraycontainingtheabsolutebounding-box
boxes=ort_outs[0]
scores=ort_outs[1]
labels=ort_outs[2]
print(boxes.shape,boxes.dtype,labels.shape,labels.dtype,scores.shape,scores.dtype)
index=0
forx1,y1,x2,y2inboxes:
ifscores[index]>0.65:
cv.rectangle(src,(np.int32(x1),np.int32(y1)),
(np.int32(x2),np.int32(y2)),(140,199,0),2,8,0)
label_id=labels[index]
label_txt=coco_names[str(label_id)]
cv.putText(src,label_txt,(np.int32(x1),np.int32(y1)),cv.FONT_HERSHEY_SIMPLEX,0.75,(0,0,255),1)
index+=1
cv.imshow("Retina-NetDetectionDemo",src)
cv.imwrite("D:/mmc_result.png",src)
cv.waitKey(0)
cv.destroyAllWindows()
審核編輯:彭靜
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
C++
+關注
關注
22文章
2108瀏覽量
73651 -
pytorch
+關注
關注
2文章
808瀏覽量
13226 -
訓練模型
+關注
關注
1文章
36瀏覽量
3821
原文標題:TorchVision對象檢測RetinaNet推理演示
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于不同量級預訓練數據的RoBERTa模型分析
NLP領域的研究目前由像RoBERTa等經過數十億個字符的語料經過預訓練的模型匯主導。那么對于一個預訓練
發表于 03-03 11:21
?1838次閱讀
【大語言模型:原理與工程實踐】大語言模型的預訓練
大語言模型的核心特點在于其龐大的參數量,這賦予了模型強大的學習容量,使其無需依賴微調即可適應各種下游任務,而更傾向于培養通用的處理能力。然而,隨著學習容量的增加,對預訓練數據的需求也相
發表于 05-07 17:10
在不使用任何額外數據的情況下,COCO數據集上物體檢測結果為50.9 AP的方法
實驗中,我們發現當只使用 COCO 數據集時,從頭開始訓練的模型性能是能夠匹配預訓練模型的性能。

小米在預訓練模型的探索與優化
導讀:預訓練模型在NLP大放異彩,并開啟了預訓練-微調的NLP范式時代。由于工業領域相關業務的復雜性,以及工業應用對推理性能的要求,大規模

基于預訓練模型和長短期記憶網絡的深度學習模型
作為模型的初始化詞向量。但是,隨機詞向量存在不具備語乂和語法信息的缺點;預訓練詞向量存在¨一詞-乂”的缺點,無法為模型提供具備上下文依賴的詞向量。針對該問題,提岀了一種基于
發表于 04-20 14:29
?19次下載
2021 OPPO開發者大會:NLP預訓練大模型
2021 OPPO開發者大會:NLP預訓練大模型 2021 OPPO開發者大會上介紹了融合知識的NLP預訓練大
如何實現更綠色、經濟的NLP預訓練模型遷移
NLP中,預訓練大模型Finetune是一種非常常見的解決問題的范式。利用在海量文本上預訓練得到的Bert、GPT等
Multilingual多語言預訓練語言模型的套路
Facebook在Crosslingual language model pretraining(NIPS 2019)一文中提出XLM預訓練多語言模型,整體思路基于BERT,并提出了針對多語言
一種基于亂序語言模型的預訓練模型-PERT
由于亂序語言模型不使用[MASK]標記,減輕了預訓練任務與微調任務之間的gap,并由于預測空間大小為輸入序列長度,使得計算效率高于掩碼語言模型。PERT
利用視覺語言模型對檢測器進行預訓練
預訓練通常被用于自然語言處理以及計算機視覺領域,以增強主干網絡的特征提取能力,達到加速訓練和提高模型泛化性能的目的。該方法亦可以用于場景文本檢測當中,如最早的使用ImageNet
使用 NVIDIA TAO 工具套件和預訓練模型加快 AI 開發
NVIDIA 發布了 TAO 工具套件 4.0 。該工具套件通過全新的 AutoML 功能、與第三方 MLOPs 服務的集成以及新的預訓練視覺 AI 模型提高開發者的生產力。該工具套件的企業版現在
預訓練模型的基本原理和應用
預訓練模型(Pre-trained Model)是深度學習和機器學習領域中的一個重要概念,尤其是在自然語言處理(NLP)和計算機視覺(CV)等領域中得到了廣泛應用。預
大語言模型的預訓練
能力,逐漸成為NLP領域的研究熱點。大語言模型的預訓練是這一技術發展的關鍵步驟,它通過在海量無標簽數據上進行訓練,使模型學習到語言的通用知識





 工商網監
工商網監
評論