 使用FastAPI構建機器學習微服務
使用FastAPI構建機器學習微服務
使用微服務架構部署應用程序有幾個優點:更容易進行主系統集成、更簡單的測試和可重用的代碼組件。 FastAPI 最近已成為 Python 中用于開發微服務的最流行的 web 框架之一。 FastAPI 比 Flask ( Python 中常用的 web 框架),因為它是基于 異步服務器網關接口( ASGI ) 而不是 Web 服務器網關接口( WSGI ) 。
什么是微服務
微服務定義了構建軟件應用程序的架構和組織方法。微服務的一個關鍵方面是它們是分布式的,并且具有松散耦合。實現更改不太可能破壞整個應用程序。
您還可以將使用微服務架構構建的應用程序視為由幾個通過應用程序編程接口( API )通信的小型獨立服務組成。通常,每個服務都由一個較小的、自包含的團隊擁有,負責在必要時實現更改和更新。
使用微服務的一個主要好處是,它們使團隊能夠快速為其應用程序構建新組件。這對于與不斷變化的業務需求保持一致至關重要。
另一個好處是它們使按需擴展應用程序變得多么簡單。企業可以加快上市時間,以確保不斷滿足客戶需求。
微服務和整體服務的區別
單片是另一種軟件體系結構,它為設計軟件應用程序提供了一種更傳統、統一的結構。這里有一些不同之處。
微服務是解耦的
想想微服務如何將應用程序分解為其核心功能。每個功能都稱為服務,并執行單個任務。
換句話說,服務可以獨立構建和部署。這樣做的好處是,單個服務在不影響其他服務的情況下工作。例如,如果一項服務比其他服務的需求更大,則可以獨立擴展。
巨石是緊密耦合的
另一方面,整體架構是緊密耦合的,并作為單個服務運行。缺點是,當一個進程遇到需求高峰時,必須擴展整個應用程序,以防止該進程成為瓶頸。由于單個進程故障會影響整個應用程序,因此應用程序停機的風險也會增加。
對于單片架構,隨著代碼庫的增長,更新或向應用程序添加新功能要復雜得多。這限制了實驗的空間。
何時使用微服務或巨石?
這些差異并不一定意味著微服務比單一服務更好。在某些情況下,使用單體仍然更有意義,例如構建一個不需要太多業務邏輯、優異的可伸縮性或靈活性的小型應用程序。
然而,機器學習( ML )應用程序通常是具有許多運動部件的復雜系統,必須能夠擴展以滿足業務需求。通常需要為 ML 應用程序使用微服務架構。
包裝機器學習模型
在我深入了解用于此微服務的體系結構的細節之前,有一個重要的步驟需要完成:模型打包。只有當 ML 模型的預測可以提供給最終用戶時,您才能真正實現 ML 模型的價值。在大多數情況下,這意味著從筆記本電腦到腳本,以便將模型投入生產。
在本例中,將用于訓練和預測新實例的腳本轉換為 Python 包。軟件包是編程的重要組成部分。沒有它們,大部分開發時間都浪費在重寫現有代碼上。
為了更好地理解包是什么,從腳本開始,然后介紹模塊要容易得多。
腳本:預期將直接運行的文件。每個腳本執行都執行開發人員定義的特定行為。創建腳本就像保存擴展名為.py 的文件以表示 Python 文件一樣簡單。
模塊:為導入其他腳本或模塊而創建的程序。一個模塊通常由幾個類和函數組成,這些類和函數用于其他文件。將模塊視為代碼的另一種方式是反復重用。
包可以被定義為相關模塊的集合。這些模塊以特定的方式相互作用,從而使您能夠完成任務。在 Python 中,包通常通過 PyPi 并且可以使用 pip ,一個 Python 包安裝程序。
圖 1 顯示了該模型的目錄結構。
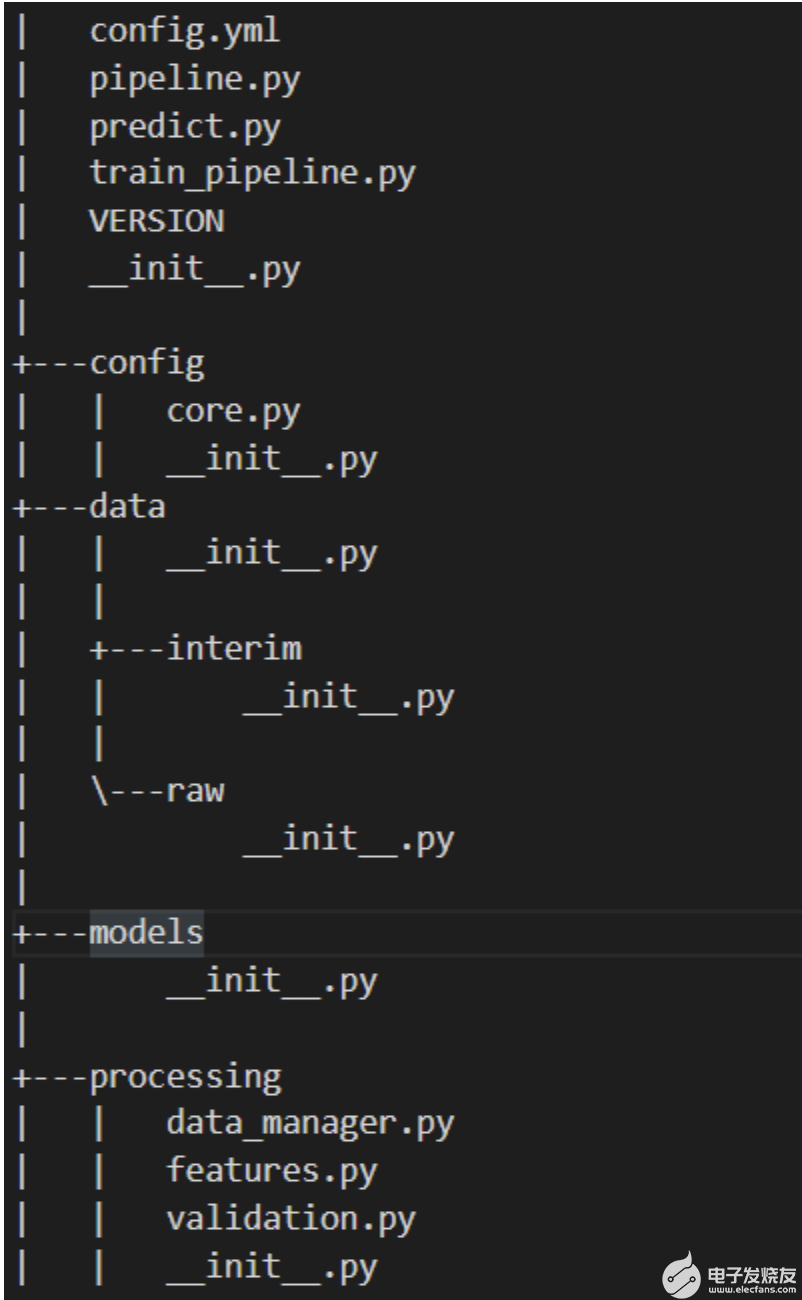
圖 1.模型的目錄結構
包模塊包括以下內容:
config.yml: YAML 文件以定義常量變量。
pipeline.py:執行所有特征轉換和建模的管道。
predict.py:使用訓練模型對新實例進行預測。
train_pipeline.py:進行模型培訓。
版本:當前版本。
config/core.py:用于解析 YAML 文件的模塊,以便可以在 Python 中訪問常量變量。
資料/:用于項目的所有數據。
模型/:經過訓練的序列化模型。
processing/data_manager.py:用于數據管理的實用功能。
processing/features.py:要在管道中使用的特征轉換。
processing/validation.py:數據驗證架構。
該模型沒有針對這個問題進行優化,因為本文的主要重點是展示如何使用微服務架構構建 ML 應用程序。
現在該模型已經準備好分發,但存在一個問題。通過 PyPi 索引分發包意味著它可以在全球范圍內訪問。對于模型中沒有業務價值的場景,這可能是可以的。然而,在真實的業務場景中,這將是一場徹底的災難。
您可以使用第三方工具,如 Gemfury 完成此操作的步驟超出了本文的范圍。有關詳細信息,請參閱 安裝專用 Python 軟件包 。
圖 2 顯示了我的 Gemfury 存儲庫中的私有打包模型。我做了這個 用于演示目的的包公開 。
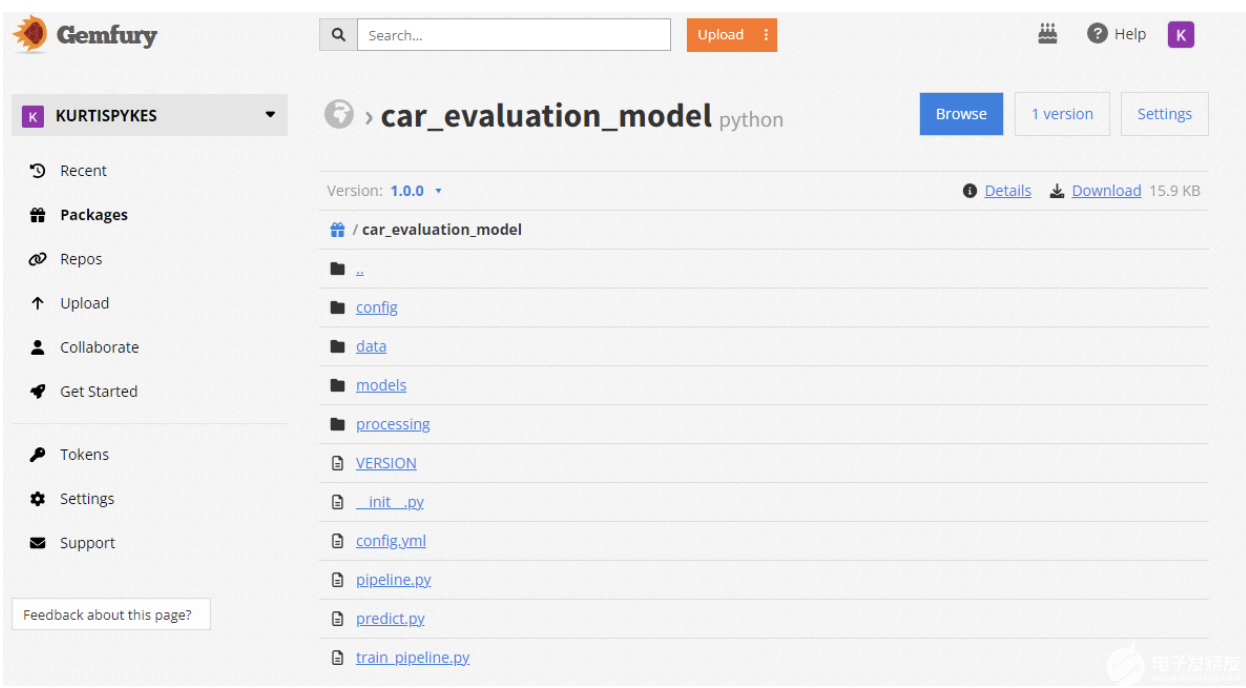
圖 2.Gemfury 存儲庫中的打包模型
微服務系統設計
在訓練并保存模型后,您需要一種向最終用戶提供預測的方法。 RESTAPI 是實現這一目標的好方法。有幾種應用程序架構可用于集成 RESTAPI 。圖 3 顯示了我在本文中使用的嵌入式體系結構。
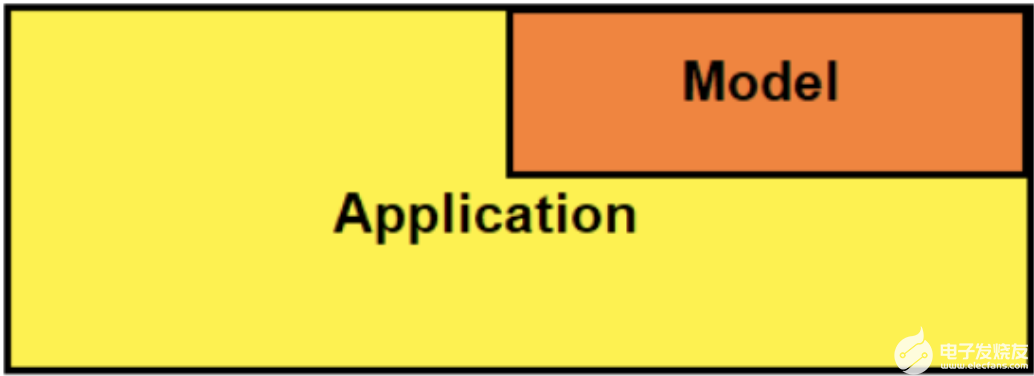
圖 3.嵌入式方法的可視化表示
嵌入式體系結構指的是一個系統,其中訓練的模型嵌入到 API 中并作為依賴項安裝。
在簡單性和靈活性之間有一個自然的權衡。嵌入式方法比其他方法簡單得多,但靈活性較差。例如,每當進行模型更新時,必須重新部署整個應用程序。如果你的服務是在手機上提供的,那么你必須發布新版本的軟件。
使用 FastAPI 構建 API
構建 API 時需要考慮的是依賴關系。您將不會創建虛擬環境,因為您正在使用運行應用程序 tox ,這是一個命令行驅動的自動化測試工具,也用于通用 虛擬人 經營因此,調用tox創建虛擬環境并運行應用程序。
盡管如此,以下是依賴項。
--extra-index-url="https://repo.fury.io/kurtispykes/" car-evaluation-model==1.0.0 uvicorn>=0.18.2, <0.19.0 fastapi>=0.79.0, <1.0.0 python-multipart>=0.0.5, <0.1.0 pydantic>=1.9.1, <1.10.0 typing_extensions>=3.10.0, <3.11.0 loguru>=0.6.0, <0.7.0
如果在 PyPI 中找不到包,pip還有一個額外的索引,用于搜索包。這是到托管打包模型的 Gemfury 帳戶的公共鏈接,因此,您可以從 Gemfurry 安裝經過訓練的模型。這將是專業設置中的私有包,這意味著鏈接將被提取并隱藏在環境變量中。
另一件需要注意的事情是uvicorn.Uvicorn 是實現 ASGI 接口的服務器網關接口。換句話說,它是一個專門的 web 服務器,負責處理入站和出站請求。它在Procfile中定義。
web: uvicorn app.main:app --host 0.0.0.0 --port $PORT
既然指定了依賴項,您就可以繼續查看實際的應用程序了。 API 應用程序的主要部分是main.py腳本:
from typing import Any from fastapi import APIRouter, FastAPI, Request from fastapi.middleware.cors import CORSMiddleware from fastapi.responses import HTMLResponse from loguru import logger from app.api import api_router from app.config import settings, setup_app_logging # setup logging as early as possible setup_app_logging(config=settings) app = FastAPI( title=settings.PROJECT_NAME, openapi_url=f"{settings.API_V1_STR}/openapi.json" ) root_router = APIRouter() @root_router.get("/") def index(request: Request) -> Any: """Basic HTML response.""" body = ( "" "" "Welcome to the API
" "" "Check the docs: here" "" "" "" ) return HTMLResponse(content=body) app.include_router(api_router, prefix=settings.API_V1_STR) app.include_router(root_router) # Set all CORS enabled origins if settings.BACKEND_CORS_ORIGINS: app.add_middleware( CORSMiddleware, allow_origins=[str(origin) for origin in settings.BACKEND_CORS_ORIGINS], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], ) if __name__ == "__main__": # Use this for debugging purposes only logger.warning("Running in development mode. Do not run like this in production.") import uvicorn # type: ignore uvicorn.run(app, host="localhost", port=8001, log_level="debug")
如果你不能跟上,不要擔心。需要注意的關鍵是,主應用程序中有兩個路由器:
-
root_router:此端點定義返回 HTML 響應的主體。您幾乎可以將其視為稱為索引的主端點。 -
api_router:此端點用于指定允許其他應用程序與 ML 模型交互的更復雜的端點。
深入了解api.py模塊以更好地理解api_router。首先,本模塊中定義了兩個端點:health和predict。
看看代碼示例:
@api_router.get("/health", response_model=schemas.Health, status_code=200)
def health() -> dict:
"""
Root Get
"""
health = schemas.Health(
name=settings.PROJECT_NAME, api_version=__version__, model_version=model_version
)
return health.dict()
@api_router.post("/predict", response_model=schemas.PredictionResults, status_code=200)
async def predict(input_data: schemas.MultipleCarTransactionInputData) -> Any:
"""
Make predictions with the Fraud detection model
"""
input_df = pd.DataFrame(jsonable_encoder(input_data.inputs))
# Advanced: You can improve performance of your API by rewriting the
# `make prediction` function to be async and using await here.
logger.info(f"Making prediction on inputs: {input_data.inputs}")
results = make_prediction(inputs=input_df.replace({np.nan: None}))
if results["errors"] is not None:
logger.warning(f"Prediction validation error: {results.get('errors')}")
raise HTTPException(status_code=400, detail=json.loads(results["errors"]))
logger.info(f"Prediction results: {results.get('predictions')}")
return results
health端點非常簡單。當您訪問 web 服務器時,它返回模型的健康響應模式(圖 4 )。您在schemas目錄中的health.py模塊中定義了此架構。
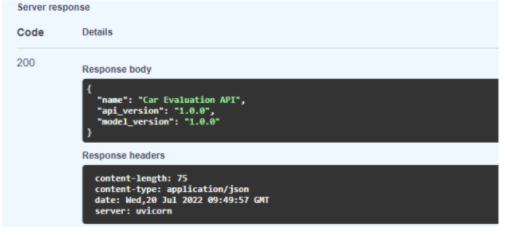
圖 4.來自健康端點的服務器響應
predict端點稍微復雜一些。以下是所涉及的步驟:
獲取輸入并將其轉換為 pandas 數據幀 : jsonable_encoder 返回的 JSON 兼容版本 pydantic model.
記錄輸入數據以進行審計。
使用 ML 模型的make_prediction函數進行預測。
捕獲模型產生的任何錯誤。
如果模型沒有錯誤,則返回結果。
通過從終端窗口使用以下命令啟動服務器,檢查所有功能是否正常:
py -m tox -e run
如果服務器正在運行,這將顯示多個日志,如圖 5 所示。
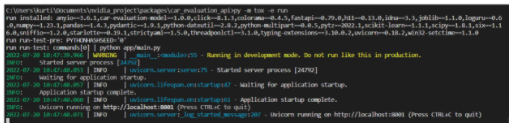
圖 5.顯示服務器正在運行的日志
現在,您可以導航到 http://localhost:8001 查看 API 的交互端點。
測試微服務 API
導航到本地服務器將從main.py腳本轉到root_rooter中定義的索引端點。您可以通過在本地主機服務器 URL 的末尾添加/docs來獲得有關 API 的更多信息。
例如,圖 6 顯示您已經將predict端點創建為 POST 請求,health端點是 GET 請求。
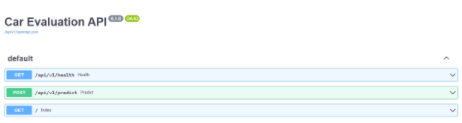
圖 6.API 端點
首先,展開predict標題以接收有關端點的信息。在本標題中,您將看到請求主體中的一個示例。我在其中一個模式中定義了這個示例,以便您可以測試 API 。這超出了本文的范圍,但您可以瀏覽 模式代碼 。
要在請求體示例中嘗試該模型,請選擇試試看。
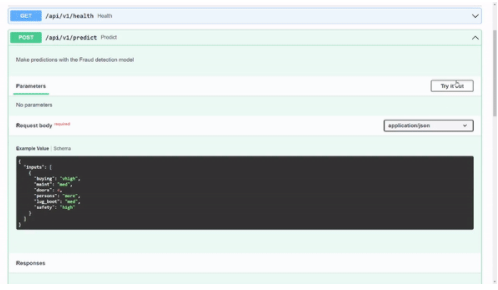
圖 7.使用微服務的示例預測
圖 7 顯示了模型返回的預測輸出類為 1 。在內部,您知道 1 表示acc類值,但您可能希望在用戶界面中顯示時向用戶顯示該值。
下一步是什么?
恭喜您,您現在已經為微服務構建了自己的 ML 模型。接下來的步驟涉及部署它,以便它可以在生產中運行。
總而言之,微服務是一種架構和組織設計方法,用于安排松散耦合的服務。在 ML 應用程序中使用微服務方法的主要好處之一是獨立于主要軟件產品。擁有與主軟件產品分離的功能服務( ML 應用程序)有兩個關鍵好處:
它使跨職能團隊能夠參與分布式開發,從而加快部署速度。
軟件的可擴展性得到了顯著提高。
關于作者
Kurtis Pykes 是一位自學成才的機器學習實踐者,目前是一名自由職業者。
審核編輯:郭婷
-
python
+關注
關注
56文章
4797瀏覽量
84683
發布評論請先 登錄
相關推薦
使用阿里云ACM簡化你的Spring Cloud微服務環境配置管理
微服務架構和CQRS架構基本概念介紹
微服務網關gateway的相關資料推薦
java微服務生態系統模型解讀
什么是微服務_微服務知識點全面總結
java微服務架構有哪些
微服務優勢_微服務架構的好處與不足
什么是微服務和容器?微服務和容器的作用是什么
什么是微服務架構?
springcloud微服務架構
docker微服務架構實戰
設計微服務架構的原則

如何構建彈性、高可用的微服務?





 工商網監
工商網監
評論