") 使用第三代NVIDIA NVSwitch升級多GPU互連
使用第三代NVIDIA NVSwitch升級多GPU互連
人工智能和 高性能計算 ( HPC )正在推動對每個 GPU 之間具有高速通信的更快、更可擴展互連的需求。
這個 第三代 NVIDIA NVSwitch 設(shè)計用于滿足這種通信需求。最新的 NVSwitch 和 H100 張量核心 GPU 使用第四代 NVLink ,這是 NVIDIA 最新的高速點對點互連。
第三代 NVIDIA NVSwitch 旨在為 NVLink 交換機系統(tǒng)提供節(jié)點內(nèi)或節(jié)點外部 GPU 的連接。它還將硬件加速與多播和 NVIDIA 可擴展分層聚合和縮減協(xié)議( SHARP ) 在網(wǎng)絡(luò)縮減中。
NVIDIA NVSwitch 也是 NVLink 開關(guān) 網(wǎng)絡(luò)設(shè)備 ,允許創(chuàng)建最多連接 256 個的群集 NVIDIA H100 Tensor Core GPUs 以及 57.6TB / s 的全對全帶寬。與 NVIDIA 安培架構(gòu) GPU 上的 HDR InfiniBand 相比,該設(shè)備可提供 9 倍的二等分帶寬。
高帶寬和 GPU 兼容操作
AI 和 HPC 工作負載的性能需求繼續(xù)快速增長,需要擴展到多節(jié)點、多 – GPU 系統(tǒng)。
大規(guī)模提供卓越性能需要每個 GPU 之間的高帶寬通信, NVIDIA NVLink 規(guī)范旨在與 NVIDIA GPU 協(xié)同工作,以實現(xiàn)所需的性能和可擴展性。
例如, NVIDIA GPU 的線程塊執(zhí)行結(jié)構(gòu)有效地為并行化 NVLink 架構(gòu)提供了支持。 NVLink 端口接口也被設(shè)計為盡可能地匹配 GPU L2 緩存的數(shù)據(jù)交換語義。
比 PCIe 快
NVLink 的一個關(guān)鍵優(yōu)勢是它提供了比 PCIe 大得多的帶寬。第四代 NVLink 每個通道的帶寬為 100 Gbps ,是 PCIe Gen5 的 32 Gbps 帶寬的三倍多。可以組合多個 NVLink 以提供更高的聚合通道數(shù),從而產(chǎn)生更高的吞吐量。
比傳統(tǒng)網(wǎng)絡(luò)更低的開銷
NVLink 被專門設(shè)計為高速點對點鏈路互連 GPU ,產(chǎn)生比傳統(tǒng)網(wǎng)絡(luò)更低的開銷。
這使得傳統(tǒng)網(wǎng)絡(luò)中的許多復(fù)雜網(wǎng)絡(luò)功能(如端到端重試、自適應(yīng)路由和數(shù)據(jù)包重新排序)可以在增加端口數(shù)的情況下進行權(quán)衡。
網(wǎng)絡(luò)接口更加簡單,允許將應(yīng)用程序?qū)印⒈硎緦雍蜁拰庸δ苤苯忧度氲?CUDA 本身中,從而進一步減少通信開銷。
NVLink 世代
隨著 NVIDIA P100 GPU 的首次推出, NVLink 繼續(xù)與 NVIDIA GPU 體系結(jié)構(gòu)同步發(fā)展,每一種新體系結(jié)構(gòu)都伴隨著新一代 NVLink 。
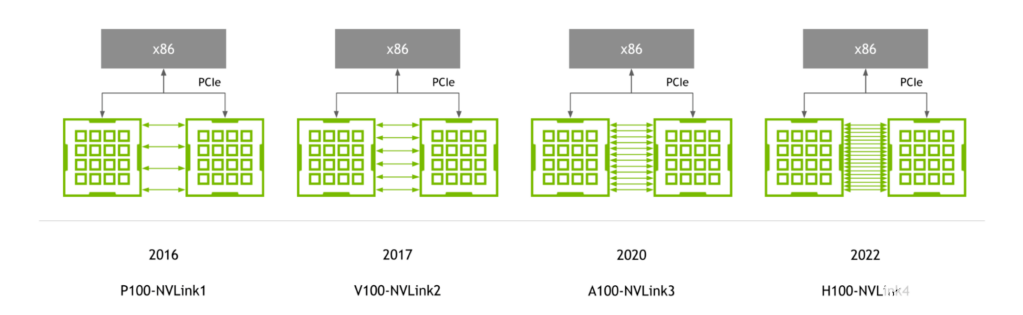
圖 1.與 GPU 同步演進的 NVLink 生成
第四代 NVLink 為每個 GPU 提供 900 GB / s 的雙向帶寬,比上一代高 1.5 倍,比第一代 NVLink 高 5.6 倍。
支持 NVLink 的服務(wù)器代
NVIDIA NVSwitch 首先與 NVIDIA V100 Tensor Core GPU 和第二代 NVLink 一起推出,實現(xiàn)了服務(wù)器中所有 GPU 之間的高帶寬、任意連接。
NVIDIA A100 Tensor Core GPU 引入了第三代 NVLink 和第二代 NVSwitch ,使每 CPU 帶寬和減少帶寬都增加了一倍。
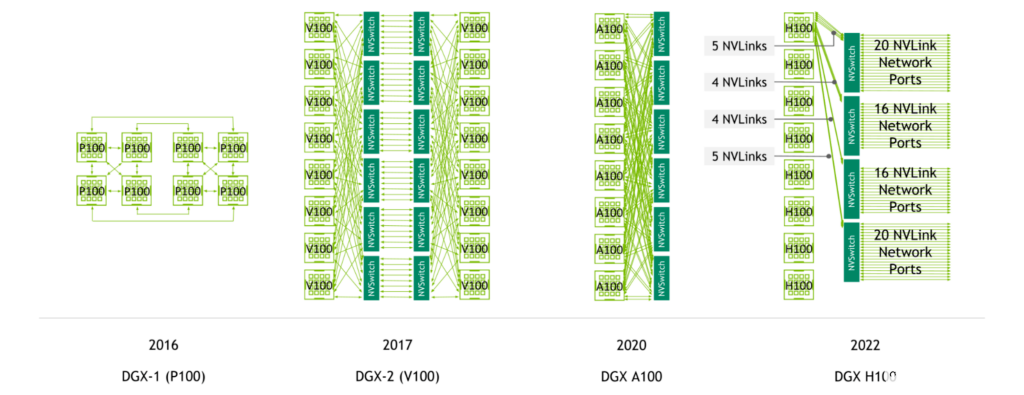
圖 2.NVLink總而言之跨 DGX 服務(wù)器代的連接
使用第四代 NVLink 和第三代 NVSwitch ,具有八個 NVIDIA H100 Tensor Core GPU 的系統(tǒng)具有 3.6 TB / s 的二等分帶寬和 450 GB / s 的縮減操作帶寬。與上一代相比,這兩個數(shù)字分別增加了 1.5 倍和 3 倍。
此外,使用第四代 NVLink 和第三代 NVSwitch 以及外部 NVIDIA NVLink 交換機,現(xiàn)在可以以 NVLink 速度跨多臺服務(wù)器進行多 GPU 通信。
迄今為止最大、最快的交換機芯片
第三代 NVSwitch 是迄今為止最大的 NVSwitch 。它使用為 NVIDIA 定制的 TSMC 4N 工藝構(gòu)建。該芯片包含 251 億個晶體管,比 NVIDIA V100 Tensor Core GPU 的晶體管多,面積為 294 毫米2封裝尺寸為 50 mm x 50 mm ,共有 2645 個焊球。
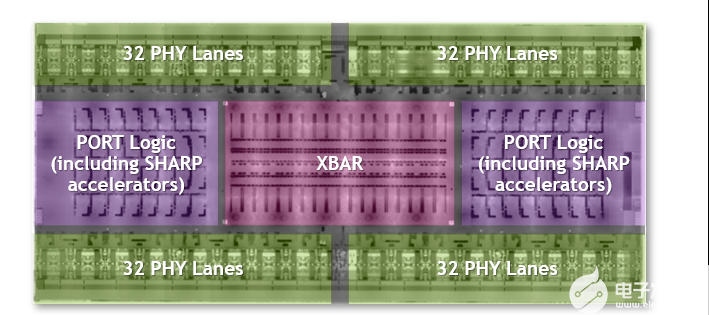
圖 3.第三代 NVSwitch 芯片的特點包括它是最大的 NVSwitch ,具有最高的帶寬和 400 GFlops 的 FP32 夏普
NVLink 網(wǎng)絡(luò)支持
第三代 NVSwitch 是 NVLink 交換機系統(tǒng)的關(guān)鍵使能器,它能夠以 NVLink 速度實現(xiàn) GPU 跨節(jié)點的連接。
它包含與 400 Gbps 以太網(wǎng)和 InfiniBand 連接兼容的物理( PHY )電氣接口。隨附的管理控制器現(xiàn)在支持附加的八進制小尺寸可插拔( OSFP )模塊,每個機架具有四個 NVLINK 。使用自定義固件,可以支持活動電纜。
還添加了其他前向糾錯( FEC )模式,以增強 NVLink 網(wǎng)絡(luò)性能和可靠性。
還添加了安全處理器,以保護數(shù)據(jù)和芯片配置免受攻擊。該芯片提供了分區(qū)功能,可以將端口子集隔離到單獨的 NVLink 網(wǎng)絡(luò)中。擴展的遙測功能還支持 InfiniBand 風(fēng)格的監(jiān)控。
帶寬加倍
第三代 NVSwitch 是我們迄今為止帶寬最高的 NVSwitch 。
使用 50 Gbaud PAM4 信令,每個差分對的帶寬為 100 Gbps ,第三代 NVSwitch 在 64 個 NVLink 端口上提供 3.2 TB / s 的全雙工帶寬(每個 NVLink x2 )。與前一代相比,它在系統(tǒng)中提供了更多帶寬,同時還需要更少的 NVSwitch 芯片。第三代 NVSwitch 上的所有端口都支持 NVLink 網(wǎng)絡(luò)。
SHARP 集合和多播支持
第三代 NVSwitch 包括一系列用于快速加速的新硬件模塊:
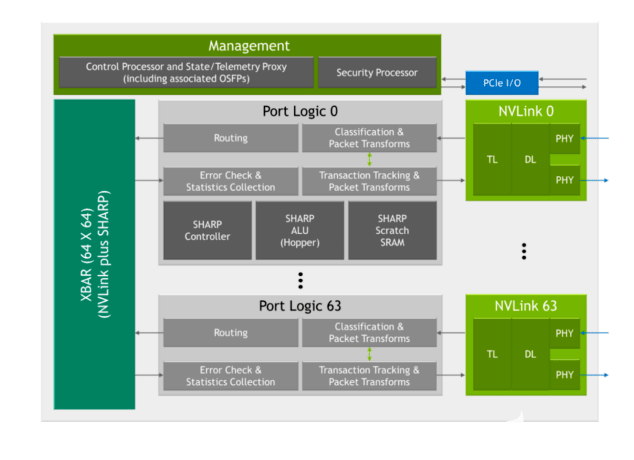
圖 4.第三代 NVSwitch 框圖
敏銳的控制器
夏普算術(shù)邏輯單元( ALU )與 NVIDIA Hopper 架構(gòu)
嵌入式 ALU 提供高達 400 次的 FP32 吞吐量,并被添加為直接在 NVSwitch 中執(zhí)行縮減操作,而不是通過系統(tǒng)中的 GPU 。
這些 ALU 支持多種運算符,如邏輯運算符、最小/最大運算符和加法運算符。它們還支持有符號/無符號整數(shù)、 FP16 、 FP32 、 FP64 和 BF16 等數(shù)據(jù)格式。
第三代 NVSwitch 還包括一個 SHARP 控制器,可并行管理多達 128 個 SHARP 組。芯片中的縱橫帶寬已經(jīng)增加,以承載額外的夏普相關(guān)交換。
所有這些都降低了操作兼容性
NVIDIA 夏普的一個關(guān)鍵用例是 AI 培訓(xùn)中常見的所有 reduce 操作。當(dāng)使用多個 GPU 訓(xùn)練網(wǎng)絡(luò)時,批次被分成更小的子批次,然后分配給每個單獨的 GPU 。
每個 GPU 通過網(wǎng)絡(luò)參數(shù)處理各自的子批次,產(chǎn)生參數(shù)的可能變化,也稱為局部梯度這些局部梯度被組合并協(xié)調(diào)以產(chǎn)生全局梯度,每個 GPU 應(yīng)用于它們的參數(shù)表。該平均過程也稱為全減操作。
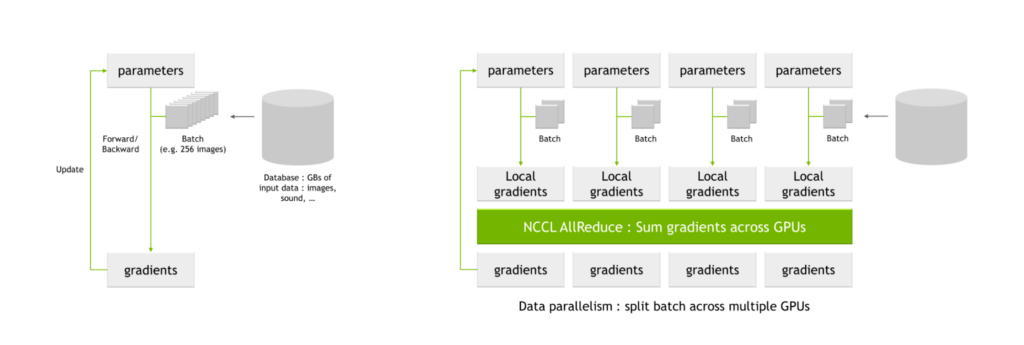
圖 5. NCCL 人工智能培訓(xùn)中的 AllReduce 與關(guān)鍵通信密集型操作
NVIDIA Magnum IO 是數(shù)據(jù)中心 IO 加速多節(jié)點通信的架構(gòu)。它使 HPC 、 AI 和科學(xué)應(yīng)用程序能夠在使用 NVLink 和 NVSwitch 擴展的新的大型 GPU 集群上擴展性能。
Magnum IO 包括 NVIDIA 集體通信庫 ( NCCL ),它實現(xiàn)了豐富的多 – GPU 和多節(jié)點集合基元,包括所有 reduce 。
NCCL AllReduce 將局部梯度作為輸入,將其劃分為子集,收集特定級別的所有子集,并將其分配給單個 GPU 。 GPU 然后對該子集執(zhí)行協(xié)調(diào)過程,例如對所有 GPU 的局部梯度值求和。
在此過程之后,生成一組全局梯度,然后將其分配給所有其他 GPU 。
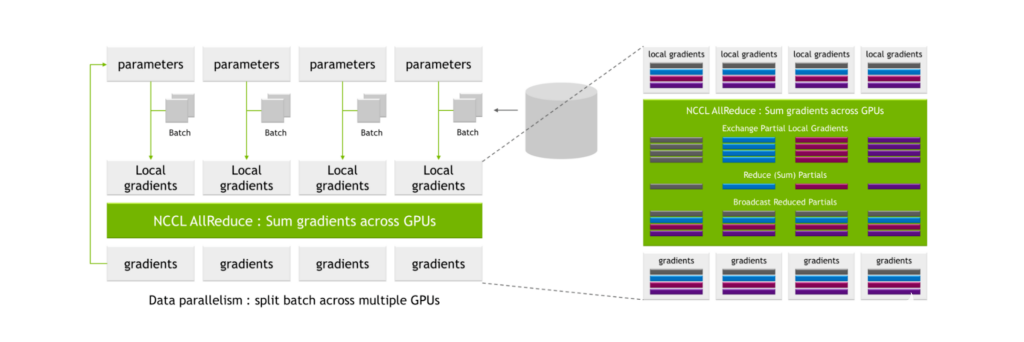
圖 6.具有數(shù)據(jù)交換和并行計算的傳統(tǒng) all-reduce 計算
這些過程是高度通信密集型的,并且相關(guān)聯(lián)的通信開銷可以顯著延長訓(xùn)練的總時間。
使用 NVIDIA A100 Tensor Core GPU 、第三代 NVLink 和第二代 NVSwitch ,發(fā)送和接收部分的過程將產(chǎn)生2N讀到(在哪里N是 GPU 的編號)。廣播結(jié)果的過程產(chǎn)生 2N為 2 寫N閱讀和 2N在每個 GPU 接口處寫入,或 4N總操作數(shù)。
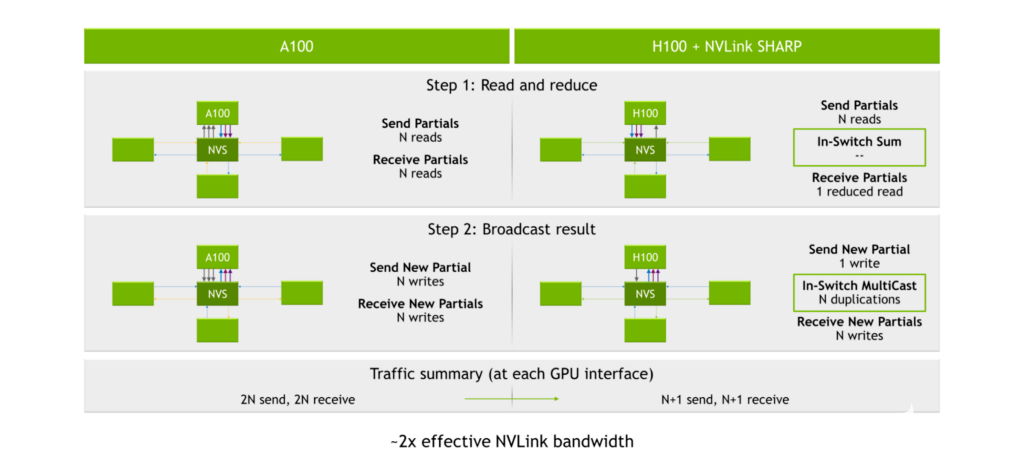
圖 7.NVLink 急劇加速
夏普引擎位于第三代 NVSwitch 內(nèi)部。 GPU 將數(shù)據(jù)發(fā)送到第三代 NVSwitch 芯片,而不是將數(shù)據(jù)分配給每個 GPU 并讓[ZFK55]執(zhí)行計算。芯片然后執(zhí)行計算,然后將結(jié)果發(fā)送回。這導(dǎo)致總共 2N+ 2 個操作,或?qū)?zhí)行全部減少計算所需的讀/寫操作的數(shù)量大約減半。
提高大型模型的性能
隨著 NVLink 交換機系統(tǒng)提供的帶寬是 InfiniBand 的 4.5 倍,大規(guī)模模型培訓(xùn)變得更加實用。
例如,當(dāng)使用 14 TB 嵌入表訓(xùn)練推薦引擎時,與使用 InfiniBand 的 H100 相比,我們預(yù)計使用 NVLink 交換系統(tǒng)的 H100 在性能上會有顯著提升。
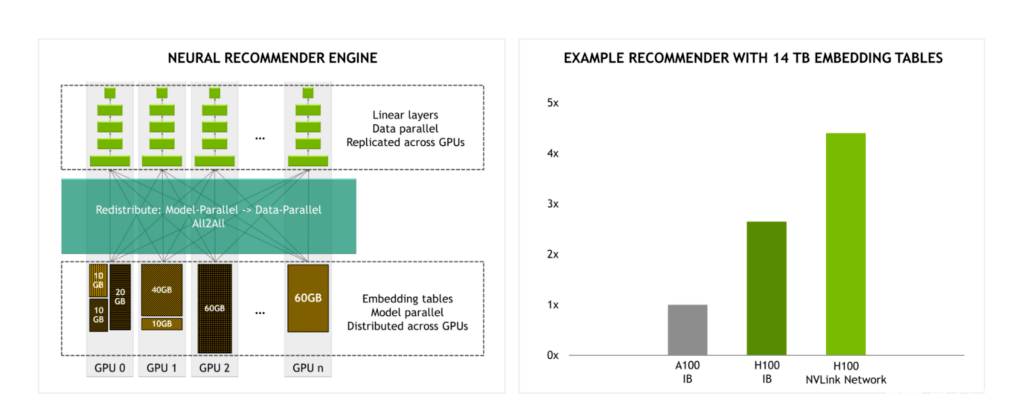
圖 8.NVLink 交換機系統(tǒng)的帶寬是最大 InfiniBand 帶寬的 4.5 倍
NVLink 網(wǎng)絡(luò)
在以前幾代的 NVLink 中,當(dāng)通過 NVLink 相互通信時,每個服務(wù)器都有自己的本地地址空間,由服務(wù)器內(nèi)的 GPU 使用。通過 NVLink 網(wǎng)絡(luò),每臺服務(wù)器都有自己的地址空間,當(dāng) GPU 通過網(wǎng)絡(luò)發(fā)送數(shù)據(jù)時使用該地址空間,從而在共享數(shù)據(jù)時提供隔離并提高安全性。該功能利用了最新 NVIDIA Hopper GPU 架構(gòu)中內(nèi)置的功能。
當(dāng) NVLink 在系統(tǒng)引導(dǎo)過程中執(zhí)行連接設(shè)置時, NVLink 網(wǎng)絡(luò)連接設(shè)置是通過軟件的運行時 API 調(diào)用執(zhí)行的。這使得網(wǎng)絡(luò)能夠在不同服務(wù)器聯(lián)機以及用戶進出時進行動態(tài)重新配置。
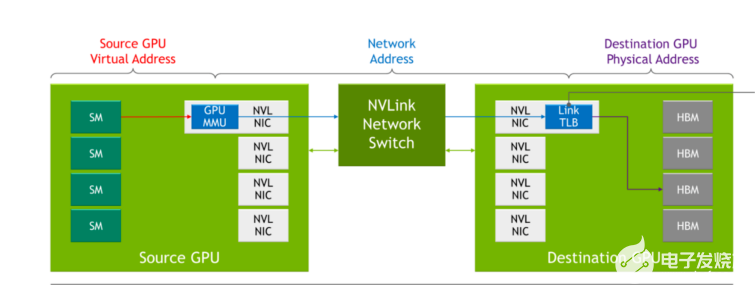
圖 9.與 NVLink 相比, NVLink 交換機系統(tǒng)的變化
表 1 顯示了傳統(tǒng)網(wǎng)絡(luò)概念如何映射到 NVLink 網(wǎng)絡(luò)中的對應(yīng)概念。
DGX H100
NVIDIA DGX H100 是基于最新 NVIDIA H100 張量核心 GPU 的 DGX 系列系統(tǒng)的最新版本,包含:
8x NVIDIA H100 Tensor Core GPU ,具有 640GB 的聚合 GPU 內(nèi)存
4x 第三代 NVIDIA NVSwitch 芯片
18x NVLink 網(wǎng)絡(luò) OSFPs
72 個 NVLink 提供的 3.6 TB / s 全雙工 NVLink 網(wǎng)絡(luò)帶寬
8x NVIDIA ConnectX-7 以太網(wǎng)/ InfiniBand 端口
2x 雙端口 BlueField-3 DPU
雙藍寶石 RAPIDS CPU
支持 PCIe 第 5 代
全帶寬服務(wù)器內(nèi) NVLink
在 DGX H100 中,系統(tǒng)內(nèi)的八個 H100 張量核心 GPU 中的每一個都連接到所有四個第三代 NVSwitch 芯片。業(yè)務(wù)通過四個不同的交換平面發(fā)送,使得鏈路聚合能夠?qū)崿F(xiàn)系統(tǒng)中 GPU 之間的全部到全部帶寬。
半帶寬 NVLink 網(wǎng)絡(luò)
通過 NVLink 網(wǎng)絡(luò),一臺服務(wù)器中的所有八個 NVIDIA H100 Tensor Core GPU 可以向其他服務(wù)器中的 H100 Tessor Core [ZFK55]訂閱 18 個 NVLink 。
或者,一臺服務(wù)器中的四個 H100 Tensor Core GPU 可以向其他服務(wù)器中的 H100 Tensor Core [ZFK55]完全訂閱 18 個 NVLINK 。這種 2 : 1 的錐度是為了平衡帶寬、服務(wù)器復(fù)雜性和該技術(shù)實例的成本而做出的權(quán)衡。
使用夏普,交付的帶寬相當(dāng)于全帶寬 AllReduce 。
多軌以太網(wǎng)
在一個服務(wù)器中,所有八個 GPU 都獨立地支持來自其專用 400 GB NIC 的 RDMA 。對于非 NVLink 網(wǎng)絡(luò)設(shè)備, 800 GB / s 的聚合全雙工帶寬是可能的。
DGX H100 疊加
DGX H100 是 DGX H1100 疊加的構(gòu)建塊。
由八個計算機架構(gòu)建,每個機架具有四臺 DGX H100 服務(wù)器。
共有 32 個 DGX H100 節(jié)點,包含 256 個 NVIDIA H100 張量核心 GPU 。
提供高達峰值 AI 計算的一個 exaflop 的峰值。
NVLink 網(wǎng)絡(luò)在整個 256 GPU 范圍內(nèi)提供 57.6 TB / s 的二等分帶寬。此外,跨所有 32 個 DGX 和相關(guān) InfiniBand 交換機的 ConnectX-7 提供了 25.6 TB / s 的全雙工帶寬,可在 pod 內(nèi)使用或擴展多個疊加。
NVLink 開關(guān)
DGX H100 SuperPOD 的一個關(guān)鍵使能器是基于第三代 NVSwitch 芯片的新型 NVLink 交換機。 DGX H100 SuperPOD 包括 18 個 NVLink 交換機。
NVLink 交換機采用標(biāo)準(zhǔn)的 1U 19 英寸外形,極大地利用了 InfiniBand 交換機設(shè)計,并包括 32 個 OSFP 機架。每個交換機包含兩個第三代 NVSwitch 芯片,提供 128 個第四代 NVLink 端口,總帶寬為 6.4 TB / s 。
NVLink 交換機支持帶外管理通信和一系列布線選項,如無源銅纜。通過自定義固件,還支持有源銅纜和光纖 OSFP 電纜。
使用 NVLink 網(wǎng)絡(luò)進行擴展
與具有 256 DGX A100 的 DGX A10 SuperPOD 相比,具有 NVLink 網(wǎng)絡(luò)的 H100 SuperPOD 能夠顯著增加二等分并減少操作帶寬
GPU 。
單個 DGX H100 可提供 1.5 倍于單個 DGX A100 的二等分和 3 倍于其縮減操作的帶寬。在 32 種 DGX 系統(tǒng)配置中,這些加速比分別增長到 9 倍和 4.5 倍,每種配置總共 256 GPU 。
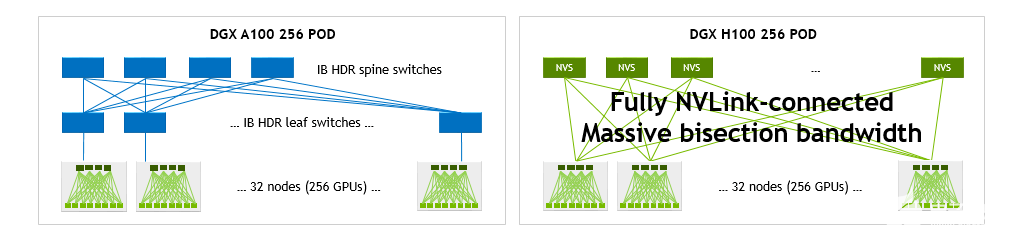
圖 10.DGX A100 POD 和 DGX H100 POD 網(wǎng)絡(luò)拓撲
通信密集型工作負載的性能優(yōu)勢
對于具有高通信強度的工作負載, NVLink 網(wǎng)絡(luò)的性能優(yōu)勢非常顯著。在 HPC 中,由于 HPC SDK 和 Magnum IO 中的通信庫中已設(shè)計了多節(jié)點縮放,因此 Lattice QCD 和 8K 3D FFT 等工作負載可以帶來巨大的好處。
當(dāng)訓(xùn)練大型語言模型或具有大型嵌入表的推薦者時, NVLink 網(wǎng)絡(luò)也可以提供顯著的提升。
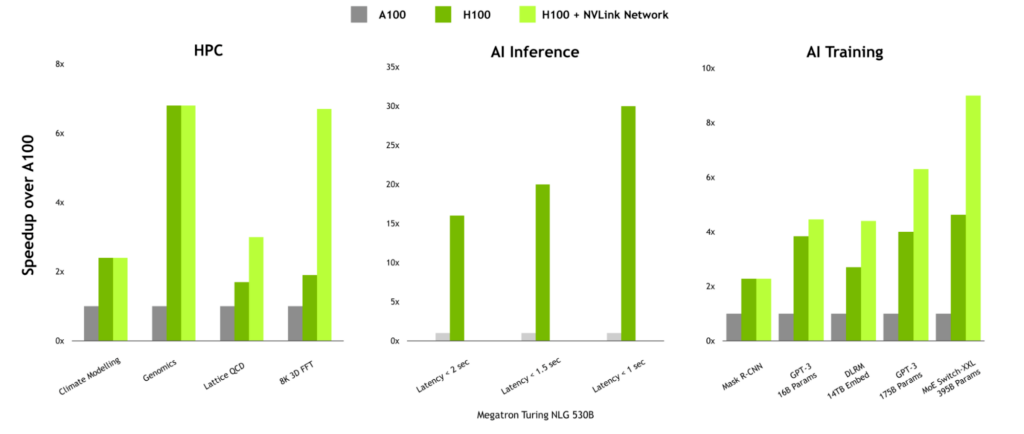
圖 11.取決于通信強度的 NVLink 交換機系統(tǒng)優(yōu)勢
大規(guī)模交付性能
為 AI 和 HPC 提供最高性能需要全棧、數(shù)據(jù)中心規(guī)模的創(chuàng)新。高帶寬、低延遲互連技術(shù)是實現(xiàn)大規(guī)模性能的關(guān)鍵因素。
第三代 NVSwitch 為服務(wù)器內(nèi) GPU 之間的高帶寬、低延遲通信以及服務(wù)器節(jié)點之間的全 NVLink 速度的全對全 GPU 通信帶來了下一次飛躍。
Magnum IO 與 CUDA 、 HPC SDK 和幾乎所有深度學(xué)習(xí)框架集成工作。它使大型語言模型、推薦系統(tǒng)等人工智能軟件和 3D FFT 等科學(xué)應(yīng)用程序能夠使用 NVLink 開關(guān)系統(tǒng)在多個 GPU 節(jié)點上進行擴展。
關(guān)于作者
Ashraf Eassa 是NVIDIA 加速計算集團內(nèi)部的高級產(chǎn)品營銷經(jīng)理。
Alex Ishii 是 NVIDIA 的杰出架構(gòu)師,在過去的 8 年中,他從 NVIDIA Research 獲得了 NVSwitch 和 NVLink 網(wǎng)絡(luò)概念,并將其引導(dǎo)到一些最先進的 NVIDIA 計算平臺的基石中。
Ryan Wells 于 2018 年加入 NVIDIA ,目前是數(shù)據(jù)中心系統(tǒng)工程團隊的架構(gòu)總監(jiān)。他和他的團隊幫助為 AI 和 HPC 定義高端 NVIDIA 數(shù)據(jù)中心產(chǎn)品,包括 HGX 和 DGX 。在加入 NVIDIA 之前,他曾在前沿 CPU 和 SOC 領(lǐng)域擔(dān)任過多種角色,包括電源/熱管理、 FW 開發(fā)和軟件架構(gòu)。 Ryan 獲得普林斯頓大學(xué)電氣工程學(xué)士學(xué)位,并擁有 22 項專利。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4986瀏覽量
103047 -
gpu
+關(guān)注
關(guān)注
28文章
4739瀏覽量
128941 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9160瀏覽量
85416
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論