 可視化操作的告警軟件背景現狀
可視化操作的告警軟件背景現狀
云原生報警背景現狀
在云原生的生態下,kubernetes 已經被越來越多地應用到公司實際生產環境中。在這樣的生態環境下系統監控、業務監控和數據庫監控指標都需要在第一時間獲取到,目前用的最多的也是prometheus、exporter、grafana、alertmanager這幾個軟件組建起來構建自己的監控系統。以上這幾款軟件組建監控系統比較容易。可是在告警這一環節,只能依靠終端vim來編輯規則文件。今天給大家推薦一款可以可視化操作的告警軟件,這個軟件是將prometheus和alertmanager進行了結合可以把數據分散存儲起來,通過可視化的操作添加 prometheus 告警規則,這個軟件就是 grafana 公司開發的mimir。
Mimir 是做什么的
Mimir 為 prometheus 提供水平可擴展、高度可用、多租戶的長期存儲。它的工作架構如下圖展示:
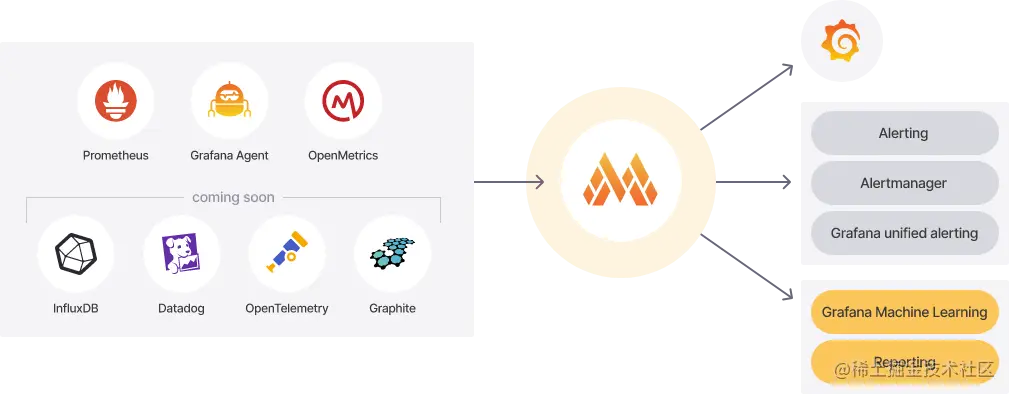 Mimir 架構
Mimir 架構
存儲 Prometheus metrics 使用 Prometheus 從應用程序中提取指標,并將這些指標遠程寫入 Mimir,或者使用 Grafana Agent、PrometheusAgent 或其他 Prometheus 遠程寫入兼容軟件直接發送數據。
擴展性強 Mimir 群集不需要手動進行切分、復制或重新平衡。要增加容量,只需向集群添加新實例。
在 grafana 中可視化 Mimir 允許用戶運行查詢,通過記錄規則創建新數據,并利用租戶聯合在多個租戶之間設置警報規則。所有這一切都可以與 Grafana 儀表盤聯系在一起。
Mimir 組件都有哪些,它們是做什么的?
| 類型 | 組建名稱 |
|---|---|
| 可選 | alertmanager,ruler,overrides-exporter,query-scheduler | |
| 必選 | compactor,distributor,ingester,querier,query-frontend,store-gateway |
以上列舉出了 Mimir 的一些組件,下面介紹一下它們分別是做什么的
Compactor(數據壓縮器,無狀態應用)
compactor 通過組合塊提高查詢性能并減少長期存儲使用。負責以下工作:
將給定租戶的多個數據塊壓縮為單個優化的較大數據塊。這可以消除數據塊并減小索引的大小,從而降低存儲成本。查詢更少的塊更快,因此也提高了查詢速度。
保持每租戶的數據存儲桶索引更新,存儲桶索引被queriers、store-gateway和rulers使用,用來發現數據中新增加的數據塊和刪除數據塊
刪除那些不再在可配置保留期內的數據塊。
按租戶以固定、可配置時間間隔進行數據塊壓縮。垂直壓縮將接收器在同一時間范圍(默認情況下為 2 小時內)上傳的租戶的所有塊合并到單個塊中。它還對最初由于復制而寫入 N 個塊的樣本執行重復數據消除。垂直壓縮減少了單個時間范圍內的塊數。垂直壓縮后觸發水平壓縮。它將幾個具有相鄰范圍周期的塊壓縮為一個較大的塊。水平壓縮后,關聯塊塊的總大小不變。水平壓縮可以顯著減小存儲網關保存在內存中的索引和索引頭的大小。如下圖:
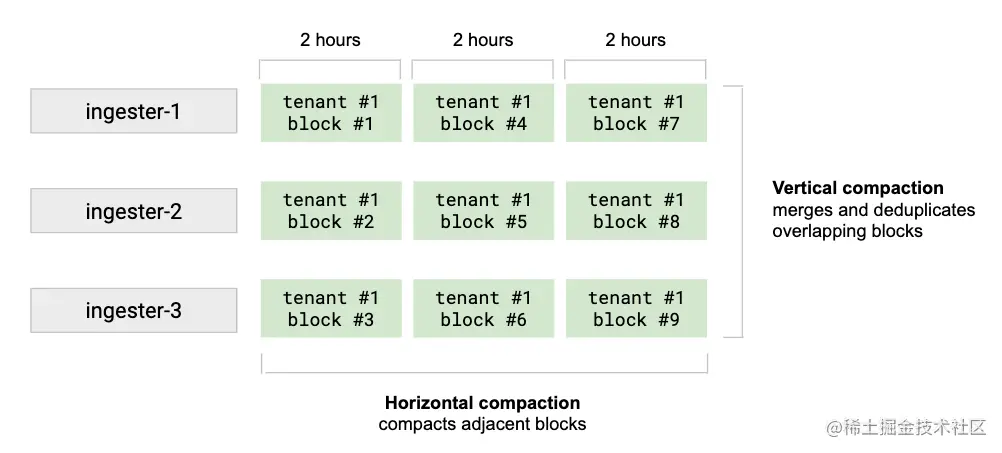 壓縮器
壓縮器
縮放
可以針對具有大型租戶的集群調整壓縮。配置指定了壓縮程序在按租戶壓縮時如何運行的垂直和水平縮放。垂直縮放:-compactor.compaction-concurrency選項配置了單個壓縮實例中運行的最大并發壓縮數。每次壓縮使用一個 CPU 內核。水平縮放:默認情況下,租戶區塊可以使用任何 Mimir 進行數據壓縮。當通過將-compactor.compactor-tenant-shard-size(或其相應的 YAML 配置選項)設置為大于 0 且小于可用 compactors 實例數量的值來啟用壓縮隨機分片時,僅指定 compactor 的數量才有資格為給定的租戶壓縮數據塊。
壓縮算法
Mimir 使用了一種稱為拆分和合并的復雜壓縮算法。通過設計,拆分和合并算法克服了時間序列數據庫(TSDB)索引的局限性,并且它避免了壓縮塊在任何壓縮階段對一個非常大的租戶無限期增長的情況。這種壓縮策略是一個兩階段的過程:拆分和合并,默認配置禁用拆分階段。
拆分階段第一級是壓縮。例如:2 小時內 compactor 將所有源數據庫分割成 N 個組(通過-compactor.split-groups設置)。對待每一個組 compactor 壓縮數據塊而不是生成單個的結果塊,輸出 M 個分割塊(通過-compactor.split-and-merge-shards設置)。每個分割塊只包含了屬于 M 碎片中給定碎片的序列子集。在分割階段結束時,compactor 會參考塊文件(meta.json)中各自碎片信息的引用來產生N*M個數據塊。Compactor 合并每個碎片的分割塊,將壓縮給定碎片的所有 N 個分割塊。合并將塊數從N*M減少到M。對于給定的壓縮時間范圍,每個 M 碎片都將有一個壓縮塊。如下圖所展示的說明
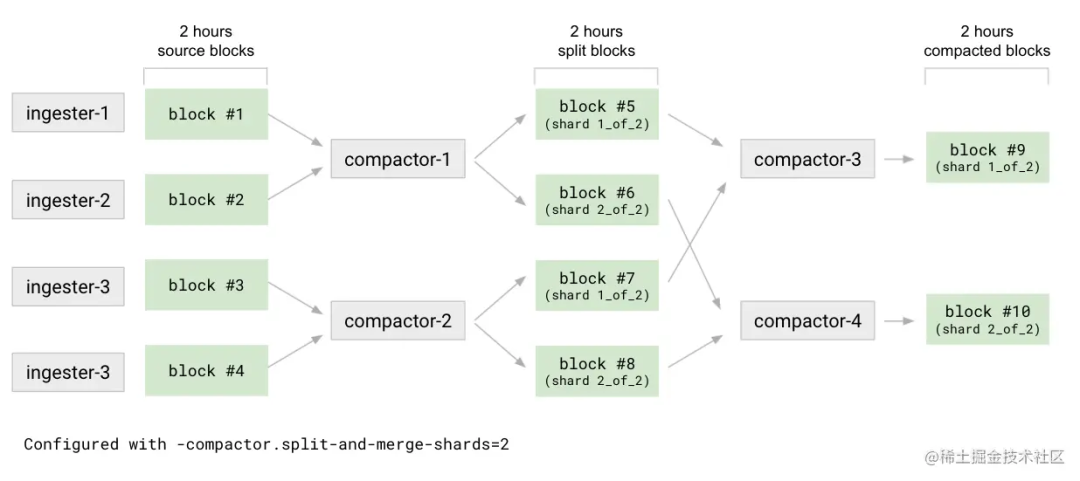
壓縮共享
Compactor 將來自單租戶或者多租戶的壓縮作業進行碎片化處理。單個租戶的壓縮可以由多個壓縮器實例分割和處理。無論壓縮器實例的數量何時增加或減少,租戶和任務崗位都會在可用壓縮器實例中重新分配,而無需任何手動干預。壓縮器使用哈希環進行分片。在啟動時,壓縮器生成隨機令牌并將自身注冊到壓縮器哈希環。在運行時,它每隔一段時間(通過-compactor.compaction-interval-compactor.compaction-interval設置)定期掃描存儲桶,以發現每個租戶的存儲和壓縮塊中的租戶列表,這些租戶的哈希與哈希環中分配給實例本身的令牌范圍相匹配。
阻止刪除
成功壓縮后,將從存儲中刪除原始塊。塊刪除不是立即進行的;它遵循兩步過程:
1.原始塊標記為刪除;這是軟刪除
2.一旦一個塊被標記為刪除的時間超過了可配置壓實機的時間。刪除延遲,從存儲器中刪除塊;這是一個硬刪除。
壓縮器負責標記塊和硬刪除。軟刪除基于存儲在 bucket 中塊位置中的一個小文件(deletion-mark.json)。成功壓縮后,將從存儲中刪除原始塊。塊刪除不是立即進行的;它遵循兩步過程:1.原始塊標記為刪除;這是軟刪除 2.一旦一個塊被標記為刪除的時間超過了可配置壓實機的時間。刪除延遲,從存儲器中刪除塊;這是一個硬刪除。
壓實機負責標記塊和硬刪除。軟刪除基于存儲在 bucket 中塊位置中的一個小文件。軟刪除機制為queriers,rulers和store-gateways提供了時間,以便在刪除原始塊之前發現新的壓縮塊。如果這些原始塊被立即硬刪除,則涉及壓縮塊的某些查詢可能會暫時失敗或返回部分結果。
distributor(數據分發器)
分發服務器是一個無狀態組件,從 Prometheus 或 Grafana 代理接收時間序列數據。分發服務器驗證數據的正確性,并確保數據在給定租戶的配置限制內。然后,分發服務器將數據分為多個批次,并將其并行發送給多個接收程序,在接收程序之間切分序列,并通過配置的復制因子復制每個序列。默認情況下,配置的復制因子為 3。
工作原理
驗證
分發服務器在將數據寫入 ingester 之前驗證其接收的數據。因為單個請求可以包含有效和無效的度量、樣本、元數據和樣本,所以分發服務器只將有效數據傳遞給 ingester。分發服務器在其對接收程序的請求中不包含無效數據。如果請求包含無效數據,分發服務器將返回 400 HTTP 狀態代碼,詳細信息將顯示在響應正文中。關于第一個無效數據的詳細信息無論是普羅米修斯還是格拉夫納代理通常由發送方記錄。分發器驗證包括以下檢查:
度量元數據和標簽符合普羅米修斯公開格式。
度量元數據(名稱、幫助和單位)的長度不超過通過validation.max-metadata-length定義的長度
每個度量的標簽數不高于-validation.max-label-names-per-series
每個度量標簽名稱不得長于-validation.max-length-label-name
每個公制標簽值不長于-validation.max-length-label-value
每個樣本時間戳都不晚于-validation.create-grace-period
每個示例都有一個時間戳和至少一個非空標簽名稱和值對。
每個樣本不超過 128 個標簽。
速率限制
分發器包括適用于每個租戶的兩種不同類型的費率限制。
請求速率每個租戶每秒可以跨 Grafana Mimir 集群處理的最大請求數。
接受速率每個租戶在 Grafana Mimir 集群中每秒可接收的最大樣本數。如果超過其中任何一個速率,分發服務器將丟棄請求并返回 HTTP 429 響應代碼。
在內部,這些限制是使用每個分發器的本地速率限制器實現的。每個分發服務器的本地速率限制器都配置了limit/N,其中 N 是正常分發服務器副本的數量。如果分發服務器副本的數量發生變化,分發服務器會自動調整請求和接收速率限制。因為這些速率限制是使用每個分發服務器的本地速率限制器實現的,所以它們要求寫入請求在分發服務器池中均勻分布。可以通過下面的這幾個參數進行限制:
-distributor.request-rate-limit
-distributor.request-burst-size
-distributor.ingestion-rate-limit
-distributor.ingestion-burst-size
高可用跟蹤器
遠程寫發送器(如 Prometheus)可以成對配置,這意味著即使其中一個遠程寫發送機停機進行維護或由于故障而不可用,度量也會繼續被擦除并寫入 Grafana Mimir。我們將此配置稱為高可用性(HA)對。分發服務器包括一個 HA 跟蹤器。啟用 HA 跟蹤器后,分發服務器會對來自 Prometheus HA 對的傳入序列進行重復數據消除。這使您能夠擁有同一 Prometheus 服務器的多個 HA 副本,將同一系列寫入 Mimir,然后在 Mimir 分發服務器中對該系列進行重復數據消除。
切分和復制
分發服務器在 ingester 之間切分和復制傳入序列。您可以通過-ingester.ring.replication-factor配置每個系列寫入的攝取器副本的數量。復制因子默認為 3。分發者使用一致哈希和可配置的復制因子來確定哪些接收者接收給定序列。切分和復制使用 ingester 的哈希環。對于每個傳入的序列,分發服務器使用度量名稱、標簽和租戶 ID 計算哈希。計算的哈希稱為令牌。分發服務器在哈希環中查找令牌,以確定向哪個接收程序寫入序列。
仲裁一致性
因為分發服務器共享對同一哈希環的訪問,所以可以向任何分發服務器發送寫請求。您還可以在它前面設置一個無狀態負載平衡器。為了確保一致的查詢結果,Mimir 在讀寫操作上使用了 Dynamo 風格的仲裁一致性。分發服務器等待 n/2+1 接收程序的成功響應,其中 n 是配置的復制因子,然后發送對 Prometheus 寫入請求的成功響應。
分發器之間的負載平衡
在分發服務器實例之間隨機進行負載平衡寫入請求。如果在 Kubernetes 集群中運行 Mimir,可以將 KubernetesService 定義為分發器的入口。
ingester(數據接收器)
接收程序是一個有狀態組件,它將傳入序列寫入長期存儲的寫路徑,并返回讀取路徑上查詢的序列樣本。
工作原理
來自分發服務器的傳入序列不會立即寫入長期存儲,而是保存在接收服務器內存中或卸載到接收服務器磁盤。最終,所有系列都會寫入磁盤,并定期(默認情況下每兩小時)上傳到長期存儲。因此,查詢器可能需要在讀取路徑上執行查詢時,從接收器和長期存儲中獲取樣本。任何調用接收器的 Mimir 組件都首先查找哈希環中注冊的接收器,以確定哪些接收器可用。每個接收器可能處于以下狀態之一:
pending
joining
active
leaving
unhealthy
寫放大
Ingers 將最近收到的樣本存儲在內存中,以便執行寫放大。如果接收器立即將收到的樣本寫入長期存儲,由于長期存儲的高壓,系統將很難縮放。由于這個原因,接收器在內存中對樣本進行批處理和壓縮,并定期將它們上傳到長期存儲。寫反放大是 Mimir 低總體擁有成本(TCO)的主要來源。
接收失敗和數據丟失
如果接收程序進程崩潰或突然退出,則所有尚未上載到長期存儲的內存中序列都可能丟失。有以下方法可以緩解這種故障模式:
Replication
Write-ahead log (WAL)
Write-behind log (WBL), out-of-order 啟用時
區域感知復制
區域感知復制可確保給定時間序列的接收副本跨不同的區域進行劃分。分區可以表示邏輯或物理故障域,例如,不同的數據中心。跨多個區域劃分副本可防止在整個區域發生停機時發生數據丟失和服務中斷。
無序切分
亂序切分可以用來減少多個租戶對彼此的影響。
無序樣本接收
默認情況下會丟棄無序樣本。如果將樣本寫入 Mimir 的系統產生無序樣本,您可以啟用此類樣本的接收。
querier(查詢器)
查詢器是一個無狀態組件,它通過在讀取路徑上獲取時間序列和標簽來評估 PromQL 表達式,使用存儲網關組件查詢長期存儲,使用接收組件查詢最近寫入的數據。
工作原理
為了在查詢時查找正確的塊,查詢器需要一個關于長期存儲中存儲桶的最新視圖。查詢器只需要來自 bucket 的元數據信息的,元數據包括塊內樣本的最小和最大時間戳。查詢器執行以下操作之一,以確保更新 bucket 視圖:
定期下載 bucket 索引(默認)
定期掃描 bucket
Bucket 索引已啟用(默認)
當查詢器收到給定租戶的第一個查詢時,它會對 bucket 索引進行懶下載。查詢器將 bucket 索引緩存在內存中,并定期更新。bucket 索引包含租戶的塊列表和塊刪除標記。查詢器稍后使用塊列表和塊刪除標記來定位給定查詢需要查詢的塊集。當查詢器在啟用 bucket 索引的情況下運行時,查詢器的啟動時間和對對象存儲的 API 調用量都會減少。我們建議您保持啟用 bucket 索引。
Bucket 索引已禁用
當禁用 bucket 索引時,查詢器會迭代存儲 bucket 以發現所有租戶的塊,并下載每個塊的 meta.json 文件。在這個初始 bucket 掃描階段,查詢器無法處理傳入的查詢,其/ready ready 探測端點將不會返回 HTTP 狀態代碼 200。運行時,查詢器定期迭代存儲桶以發現新的租戶和最近上載的塊。
查詢請求解析
連接到存儲網關
連接到接收器
支持元數據緩存
query-frontend
查詢前端是一個無狀態組件,它提供與查詢器相同的 API,并可用于加快讀取路徑。盡管查詢前端不是必需的,但我們建議您部署它。部署查詢前端時,應該向查詢前端而不是查詢器發出查詢請求。集群中需要查詢器來執行查詢,在內部隊列中保存查詢。在這種情況下,查詢器充當從隊列中提取作業、執行作業并將結果返回到查詢前端進行聚合的工作者。要將查詢器與查詢前端連接,通過-querier.frontend-address配置,在使用高可用情況下建議部署至少 2 個查詢前端。
工作原理
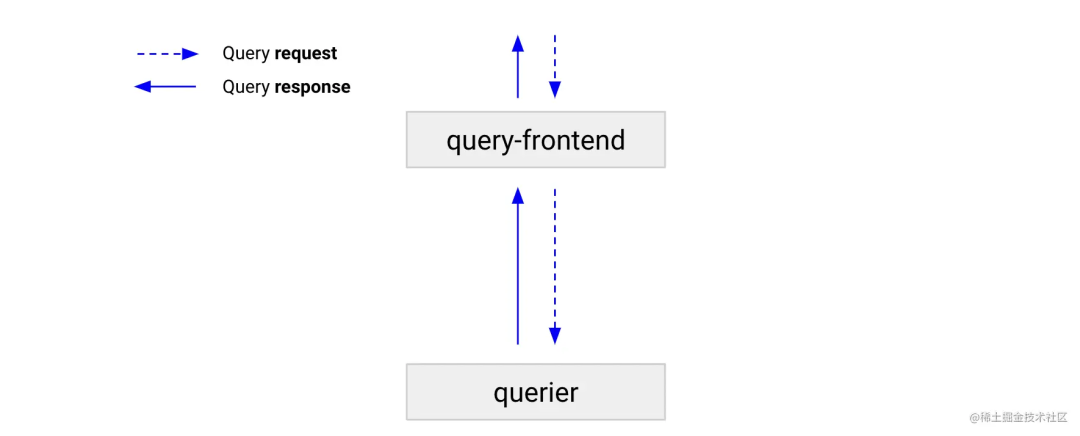
隊列
查詢前端使用排隊機制來:
如果查詢失敗,請確保重試可能導致查詢器內存不足(OOM)錯誤的大型查詢。這使管理員能夠為查詢提供不足的內存,或并行運行更多的小型查詢,這有助于降低總體擁有成本。
通過使用先進先出隊列在所有查詢器之間分發查詢,防止在單個查詢器上保護多個大型請求。
通過在租戶之間公平地安排查詢,防止單個租戶拒絕為其他租戶提供服務。
拆分
查詢前端可以將遠程查詢拆分為多個查詢。默認情況下,分割間隔為 24 小時。查詢前端在下游查詢器中并行執行這些查詢,并將結果組合在一起。拆分可防止大型多天或多月查詢導致查詢器內存不足錯誤,并加快查詢執行速度。
緩存
查詢前端緩存查詢結果并在后續查詢中重用它們。如果緩存的結果不完整,查詢前端將計算所需的部分查詢,并在下游查詢器上并行執行它們。查詢前端可以選擇將查詢與其步驟參數對齊,以提高查詢結果的可緩存性。結果緩存由 Memcached 支持。
盡管將 step 參數與查詢時間范圍對齊可以提高 Mimir 的性能,但它違反了 Mimir 對 PromQL 的一致性。如果 PromQL 一致性不是優先事項,可以設置-query-frontend.align-queries-with-step=true。
store-gateway(數據存儲網關)
存儲網關組件是有狀態的,它查詢來自長期存儲的塊。在讀取路徑上,querier和ruler在處理查詢時使用存儲網關,無論查詢來自用戶還是來自正在評估的規則。為了在查詢時找到要查找的正確塊,存儲網關需要一個關于長期存儲中存儲桶的最新視圖。存儲網關使用以下選項之一更新存儲段視圖:
定期下載 bucket 索引(默認)
定期掃描 bucket
工作原理
bucket 索引啟用
bucket 索引禁用
數據塊分片和復制
分片策略
自動忘記
區域意識
塊索引頭
索引頭懶加載
索引緩存
inmemory
memcached
元數據緩存
區塊緩存
Alertmanager
Mimir Alertmanager 為 Prometheus Alertmanagers 添加了多租戶支持和水平伸縮性。Mimir Alertmanager 是一個可選組件,它接受來自 Mimir 標尺的警報通知。Alertmanager 對警報通知進行重復數據消除和分組,并將其路由到通知通道,如電子郵件、PagerDuty 或 OpsGenie。
Override-exporter
Mimir 支持按租戶應用覆蓋。許多覆蓋配置了限制,以防止單個租戶使用過多資源。覆蓋導出器組件將限制公開為普羅米修斯度量,以便運營商了解租戶與其限制的接近程度。
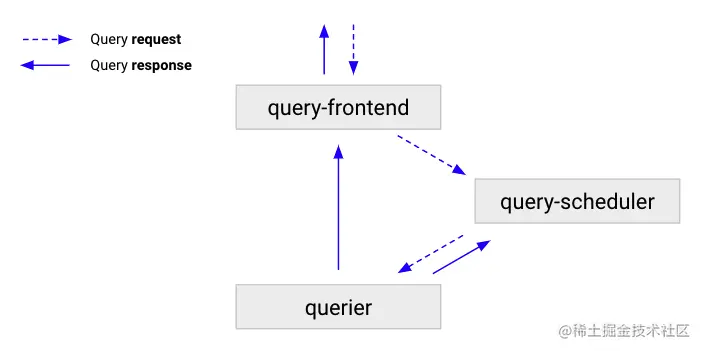
query-scheduler
查詢調度程序是一個可選的無狀態組件,它保留要執行的查詢隊列,并將工作負載分配給可用的查詢器。
工作原理
ruler
規則是一個可選組件,用于評估記錄和警報規則中定義的 PromQL 表達式。每個租戶都有一組記錄和警報規則,可以將這些規則分組到名稱空間中。
安裝
說明:安裝 mimir 需要在官方下載這個二進制程序或者直接在 k8s 集群里面直接部署即可。在這里以未啟用多租戶為介紹。
注意事項:
target 默認為 all,不包含可選組件.要啟用可選組件需要額外添加
replication_factor 默認為 3,如果只有一臺機器或者只需要啟動一個實例,需要改為 1(單需要只要 alertmanager 為 1 的時候只能發送 1 條報警信息,直到 2.3.1 版本官方都沒有解決)
裸機部署
準備配置文件
alertmanager: external_url:http://127.0.0.1:8080/alertmanager sharding_ring: replication_factor:2 ingester: ring: replication_factor:1 multitenancy_enabled:false ruler: alertmanager_url:http://127.0.0.1:8080/alertmanager external_url:http://127.0.0.1:8080/ruler query_frontend: address:127.0.0.1:9095 query_stats_enabled:true rule_path:./ruler/ ruler_storage: filesystem: dir:./rules-storage store_gateway: sharding_ring: replication_factor:1 target:all,alertmanager,ruler
啟動服務
/usr/local/mimir/mimir-darwin-amd64--config.file/usr/local/mimir/mimir.yaml
查看狀態
服務啟動后可通過瀏覽器打開查看首頁
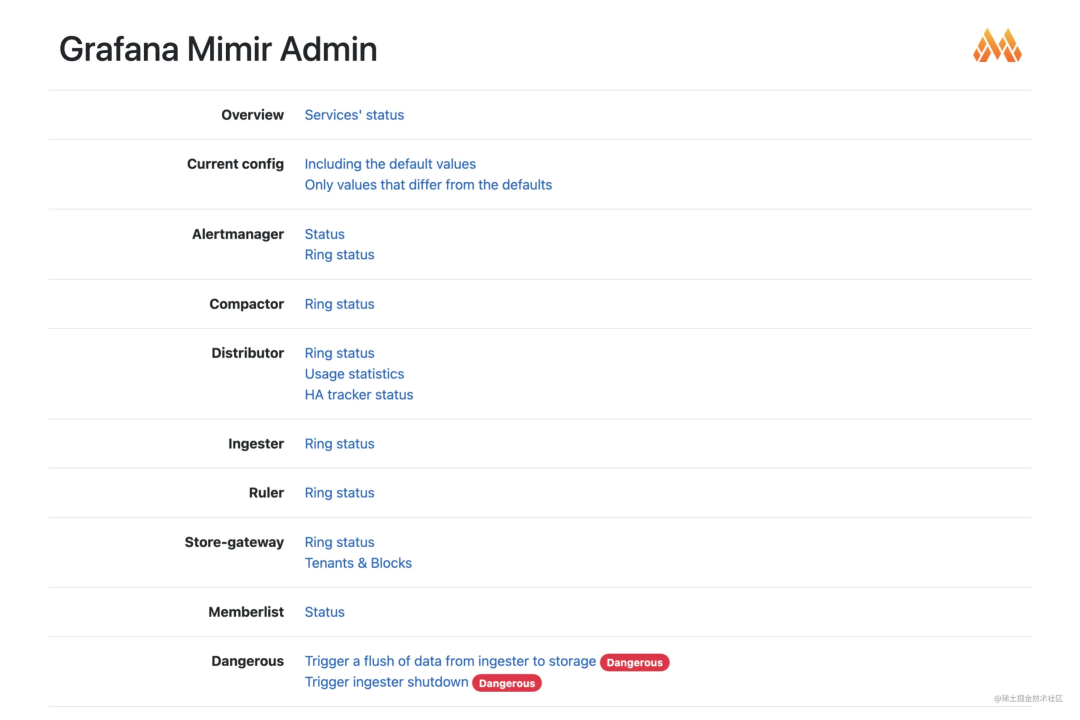 mimir_status
mimir_status
各服務運行狀態
 running_status
running_status
查看服務是否就緒
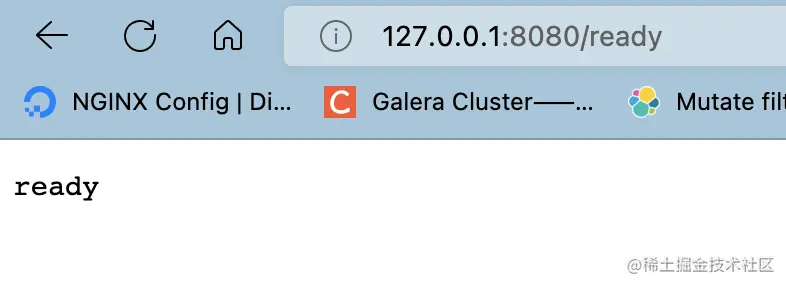
查看當前集群節點
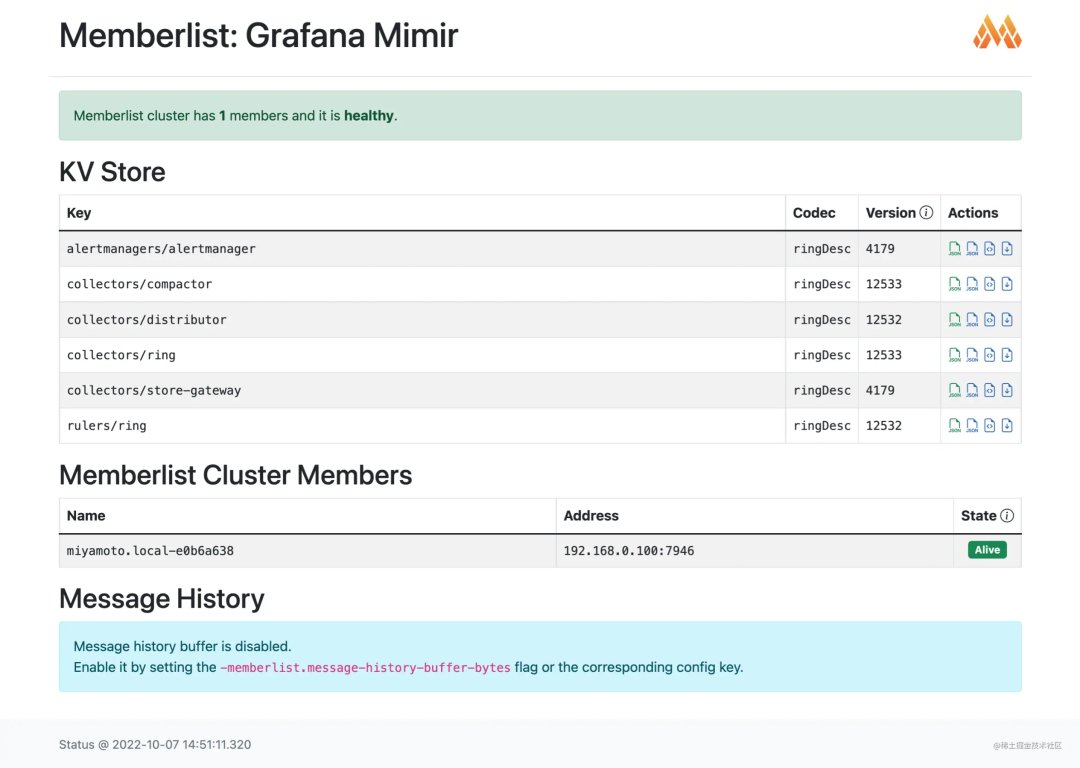
查看多租戶
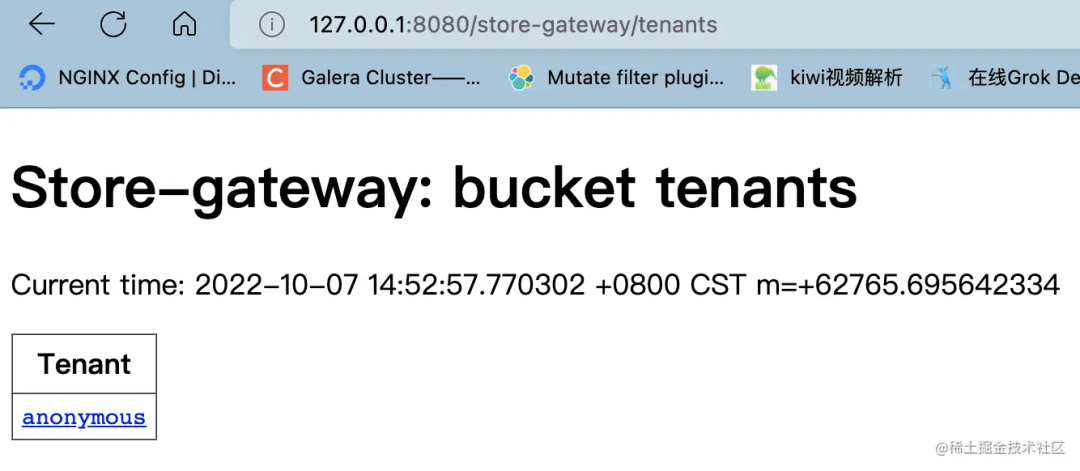
配置 Alertmanager
準備配置文件
cat./alertmanager.yaml global: resolve_timeout:5m http_config: follow_redirects:true enable_http2:true smtp_from:qiyx1@qq.com smtp_hello:mimir smtp_smarthost:smtp.qq.com:587 smtp_auth_username:qiyx1@qq.com smtp_require_tls:true route: receiver:email group_by: -alertname continue:false routes: -receiver:email group_by: -alertname matchers: -severity="info" mute_time_intervals: -夜間 continue:true group_wait:10s group_interval:5s repeat_interval:6h inhibit_rules: -source_match: severity:warning target_match: severity:warning equal: -alertname -instance receivers: -name:email email_configs: -send_resolved:true to:xxxx@xxxx.cn from:qiyx1@qq.com hello:mimir smarthost:smtp.qq.com:587 auth_username:qiyx1@qq.com headers: From:qiyx1@qq.com Subject:'{{template"email.default.subject".}}' To:qiyongxiao@elion.com.cn html:'{{template"email.default.html".}}' text:'{{template"email.default.html".}}' require_tls:true templates: -email.default.html mute_time_intervals: -name:夜間 time_intervals: -times: -start_time:"00:00" end_time:"08:45" -start_time:"21:30" end_time:"23:59"
將配置文件上傳到 mimir,默認 mimir 啟動后 alertmanager 的配置信息是空的,報警器無法啟動,需要修改配置后才能啟動
mimirtoolalertmanagerload./alertmanager.yaml--addresshttp://127.0.0.1:8080--idannoymous
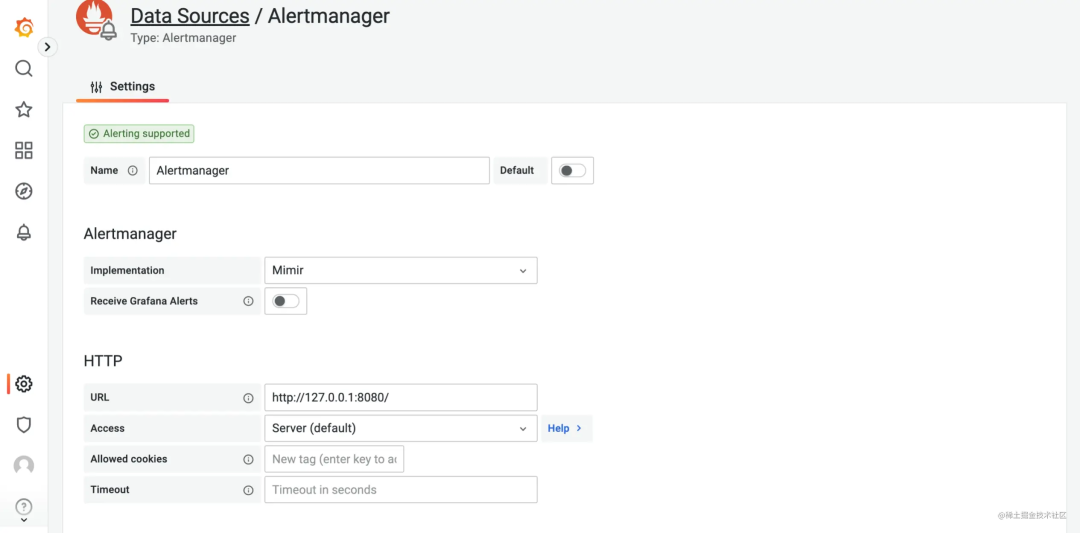
配置 grafana 的 alertmanager
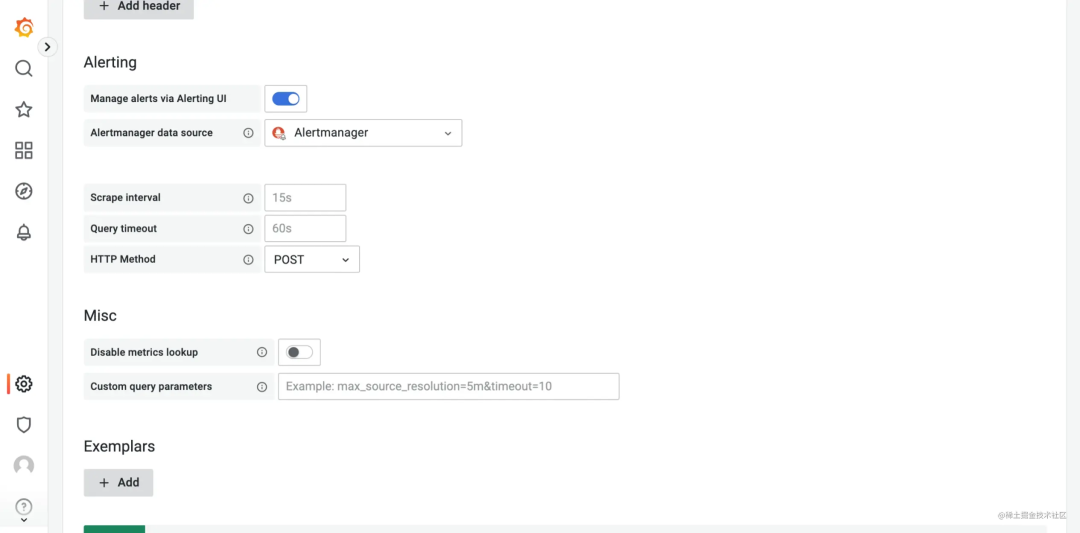
配置 grafana 的 prometheus
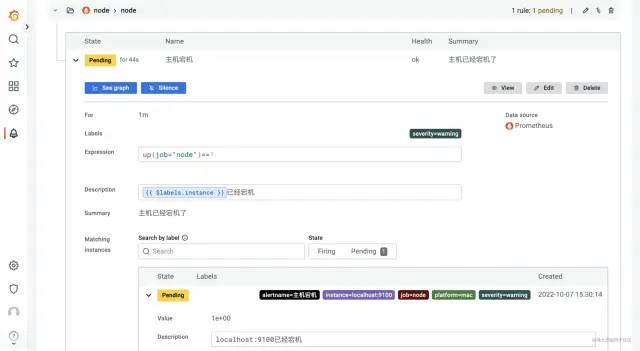
添加報警規則
配置多租戶
更改配置文件中multitenancy_enabled: true
上傳 alertmanager 配置文件(instance_id 一般為配置的 node 名稱,可以自定義)
mimirtool alertmanager load ./alertmanager.yaml --address http://127.0.0.1:8080 --id instance_id
-
監控
+關注
關注
6文章
2219瀏覽量
55282 -
軟件
+關注
關注
69文章
4981瀏覽量
87798 -
數據庫
+關注
關注
7文章
3834瀏覽量
64539 -
可視化
+關注
關注
1文章
1198瀏覽量
20986
原文標題:云原生監控報警可視化
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論