 NVIDIA 、 Arm和Intel發布FP8標準化規范作為AI的交換格式
NVIDIA 、 Arm和Intel發布FP8標準化規范作為AI的交換格式
人工智能處理需要跨硬件和軟件平臺的全棧創新,以滿足神經網絡日益增長的計算需求。提高效率的一個關鍵領域是使用較低精度的數字格式來提高計算效率,減少內存使用,并優化互連帶寬。
為了實現這些好處,業界已經從 32 位精度轉換為 16 位,現在甚至是 8 位精度格式。 transformer 網絡是人工智能中最重要的創新之一,尤其受益于 8 位浮點精度。我們相信,擁有一種通用的交換格式將使硬件和軟件平臺的快速發展和互操作性得以提高,從而推動計算。
NVIDIA 、 Arm 和 Intel 聯合撰寫了一份白皮書 FP8 Formats for Deep Learning ,描述了 8 位浮點( FP8 )規范。它提供了一種通用的格式,通過優化內存使用來加速人工智能的開發,并適用于人工智能訓練和推理。此 FP8 規格有兩種變體, E5M2 和 E4M3 。
該格式在 NVIDIA 料斗體系結構中本地實現,并在初始測試中顯示出出色的結果。它將立即受益于更廣泛的生態系統所做的工作,包括 AI 框架,為開發者實現它。
兼容性和靈活性
FP8 通過硬件和軟件之間的良好平衡,最大限度地減少了與現有 IEEE 754 浮點格式的偏差,以利用現有實現,加快采用速度,并提高開發人員的生產力。
E5M2 使用五位表示指數,兩位表示尾數,是一種截斷的 IEEE FP16 格式。在需要更高精度而犧牲某些數值范圍的情況下, E4M3 格式進行了一些調整,以擴展用四位指數和三位尾數表示的范圍。
新格式節省了額外的計算周期,因為它只使用 8 位。它可以用于人工智能訓練和推理,而不需要在精度之間進行任何重鑄。此外,通過最小化與現有浮點格式的偏差,它為未來 AI 創新提供了最大的自由度,同時仍堅持當前的慣例。
高精度訓練和推理
測試提議的 FP8 格式顯示,在廣泛的用例、架構和網絡中,其精度相當于 16 位精度。變壓器、計算機視覺和 GAN 網絡的結果都表明, FP8 訓練精度與 16 位精度相似,但可以顯著提高速度。有關精度研究的更多信息,請參閱 FP8 Formats for Deep Learning 白皮書。
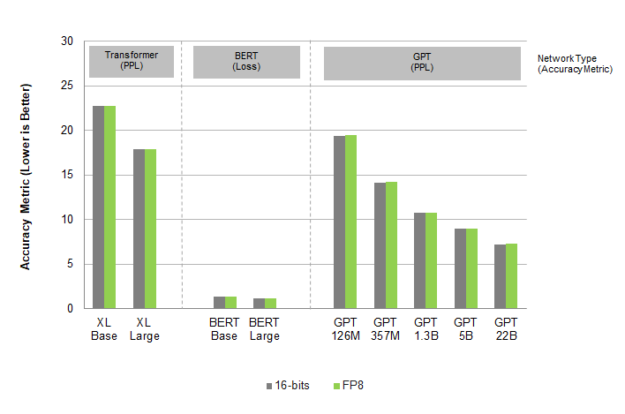
圖 1.語言模型人工智能培訓
在圖 1 中,不同的網絡使用不同的精度度量( PPL 和 Loss ),如圖所示。
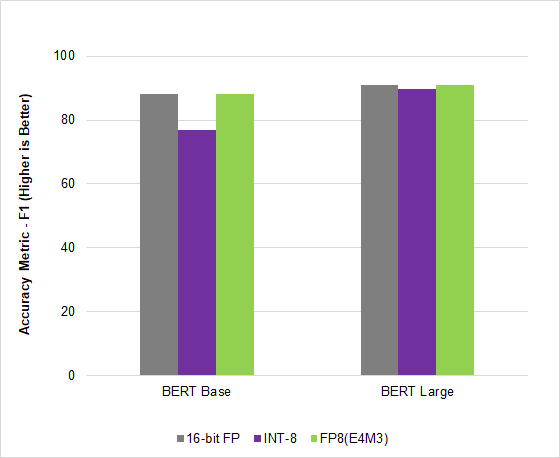
圖 2.語言模型 AI 推理
在人工智能行業領先的基準 MLPerf Inference v2.1 中, NVIDIA Hopper 利用這種新的 FP8 格式在 BERT 高精度模型上實現了 4.5 倍的加速,在不影響精度的情況下獲得了吞吐量。
走向標準化
NVIDIA 、 Arm 和 Intel 以開放、無許可證的格式發布了此規范,以鼓勵行業廣泛采用。他們還將向 IEEE 提交該提案。
通過采用一種保持準確性的可互換格式,人工智能模型將在所有硬件平臺上持續高效地運行,并有助于推動人工智能的發展。
鼓勵標準機構和整個行業
關于作者
Shar Narasimhan 是 AI 的高級產品營銷經理,專門從事 NVIDIA 的 Tesla 數據中心團隊的深度學習培訓和 OEM 業務。
審核編輯:郭婷
-
ARM
+關注
關注
134文章
9111瀏覽量
368103 -
NVIDIA
+關注
關注
14文章
5026瀏覽量
103288 -
人工智能
+關注
關注
1792文章
47445瀏覽量
239053
發布評論請先 登錄
相關推薦
思必馳參與的智能家居團體標準發布
解鎖NVIDIA TensorRT-LLM的卓越性能
南方智能參編《城市信息模型 數據交換標準格式》
如何使用FP8新技術加速大模型訓練
三星與SK海力士攜手推進LPDDR6-PIM產品標準化
FP8數據格式在大型模型訓練中的應用

TensorRT-LLM低精度推理優化

CAN技術的標準化之旅
FP8模型訓練中Debug優化思路
三星或將加入UALink聯盟,推動AI芯片互聯標準化
NVIDIA Omniverse 將為全新 OpenPBR 材質模型提供原生支持
態勢數據有哪些格式和內容呢
易華錄參編《數據要素流通標準化白皮書(2024)》正式發布


NVIDIA 發布全新交換機,全面優化萬億參數級 GPU 計算和 AI 基礎設施






 工商網監
工商網監
評論