") 通過多尺度說話人分解實現(xiàn)動態(tài)尺度加權(quán)
通過多尺度說話人分解實現(xiàn)動態(tài)尺度加權(quán)
說話人日記化是按說話人標簽對錄音進行分段的過程,旨在回答“誰在何時發(fā)言?”。與語音識別相比,它有著明顯的區(qū)別。
在你執(zhí)行說話人日記化之前,你知道“說的是什么”,但你不知道“誰說的”。因此,說話人日記化是語音識別系統(tǒng)的一個基本特征,它可以用說話人標簽豐富轉(zhuǎn)錄內(nèi)容。也就是說,如果沒有說話人日記化過程,會話錄音永遠不能被視為完全轉(zhuǎn)錄,因為沒有說話者標簽的轉(zhuǎn)錄無法通知您是誰在和誰說話。
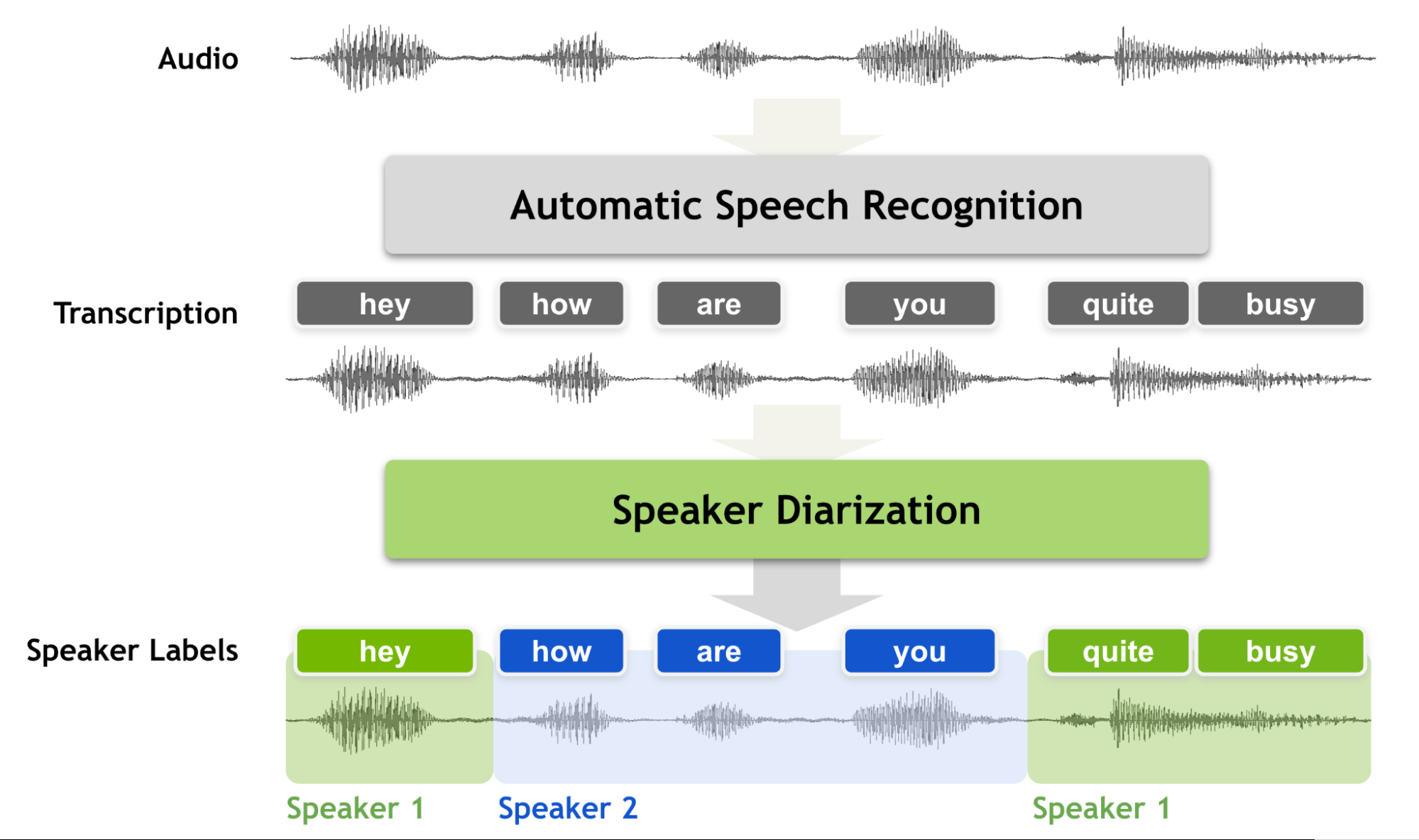
圖 1.說話人區(qū)分是將音頻記錄劃分為說話人同質(zhì)區(qū)域的任務
說話人日記必須產(chǎn)生準確的時間戳,因為在會話設置中,說話人的話輪數(shù)可能非常短。我們經(jīng)常使用短的反向通道詞,如“ yes ”、“ uh huh ”或“ oh ”。這些詞對機器轉(zhuǎn)錄和識別說話人來說很有挑戰(zhàn)性。
雖然根據(jù)說話人身份對音頻記錄進行分段,但說話人日記化需要對相對較短的分段進行細粒度決策,從十分之幾秒到幾秒不等。對如此短的音頻片段做出準確、細粒度的決策是一項挑戰(zhàn),因為它不太可能捕捉到可靠的說話人特征。
在本文中,我們討論了如何通過引入一種稱為多尺度方法和多尺度二值化解碼器( MSDD )的新技術(shù)來處理多尺度輸入來解決這個問題。
多尺度分割機制
就揚聲器特征的質(zhì)量而言,提取長音頻段是可取的。然而,音頻段的長度也限制了粒度,這導致?lián)P聲器標簽決策的單位長度較粗。如圖 2 所示的曲線所示,說話人區(qū)分系統(tǒng)面臨著時間分辨率和說話人表示保真度之間的權(quán)衡問題。
在說話人區(qū)分流水線中的說話人特征提取過程中,為了獲得高質(zhì)量的說話者表示向量,不可避免地要花費較長的語音段來犧牲時間分辨率。在簡單明了的語言中,如果你試圖準確掌握語音特征,那么你必須考慮更長的時間跨度。
同時,如果你考慮更長的時間跨度,你必須在相當長的時間跨度內(nèi)做出決定。這會導致粗決策(時間分辨率低)。想想這樣一個事實,如果只錄下半秒鐘的講話,即使是人類聽眾也無法準確地說出誰在講話。
在大多數(shù)分音系統(tǒng)中,音頻段長度在 1.5 到 3.0 秒之間,因為這樣的數(shù)字在揚聲器特性的質(zhì)量和時間分辨率之間取得了很好的折衷。這種分割方法稱為 single-scale approach 。
即使使用重疊技術(shù),單尺度分割也將時間分辨率限制在 0.75 ~ 1.5 秒,這在時間精度方面留下了改進的空間。
粗略的時間分辨率不僅會降低二值化的性能,而且會降低說話人計數(shù)的準確性,因為短語音片段無法正確捕獲。 更重要的是,說話人時間戳中的這種粗時間分辨率使得解碼后的 ASR 文本與說話人區(qū)分結(jié)果之間的匹配更容易出錯。
為了解決這個問題,我們提出了一種多尺度方法,這是一種通過從多段長度中提取說話人特征,然后將多尺度的結(jié)果結(jié)合起來來處理這種權(quán)衡的方法。多尺度技術(shù)在最流行的說話人方言化基準數(shù)據(jù)集上實現(xiàn)了最先進的精度。它已經(jīng)是開源會話 AI 工具包 NVIDIA NeMo 的一部分。
圖 2 顯示了多尺度揚聲器分辨率的關(guān)鍵技術(shù)解決方案。
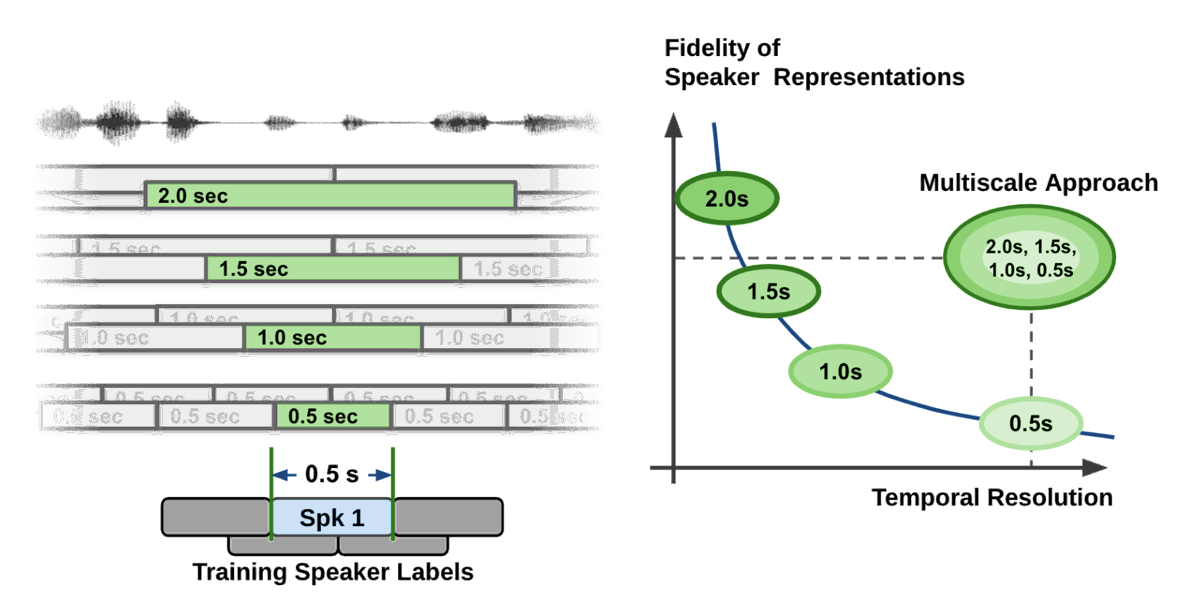
圖 2.說話人表示的時間分辨率和保真度的相應折衷曲線
多尺度方法通過使用多尺度分割和從每個尺度提取說話人嵌入來實現(xiàn)。在圖 2 的左側(cè),在多尺度分割方法中執(zhí)行了四種不同的尺度。
在段關(guān)聯(lián)性計算過程中,將合并從最長刻度到最短刻度的所有信息,但只對最短的段范圍作出決策。當組合每個音階的特征時,每個音階權(quán)重在很大程度上影響說話人的區(qū)分性能。
基于神經(jīng)模型的多尺度分解流水線
由于刻度權(quán)重在很大程度上決定了說話人區(qū)分系統(tǒng)的準確性,因此應設置刻度權(quán)重以使說話人的區(qū)分性能達到最大。
我們提出了一種稱為 multiscale diarization decoder ( MSDD )的新型多尺度二值化系統(tǒng),該系統(tǒng)在每個時間步長動態(tài)確定每個尺度的重要性。
說話人日記系統(tǒng)依賴于被稱為說話人嵌入的音頻特征向量捕獲的說話人特征。通過神經(jīng)模型提取說話人嵌入向量,從給定的音頻信號中生成稠密浮點數(shù)向量。
MSDD 從多個尺度中提取多個說話人嵌入向量,然后估計所需的尺度權(quán)重。基于估計的音階權(quán)重,生成揚聲器標簽。如果輸入信號被認為在某些尺度上具有更準確的信息,則所提出的系統(tǒng)在大尺度上的權(quán)重更大。
圖 3 顯示了提議的多尺度說話人分離系統(tǒng)的數(shù)據(jù)流。從音頻輸入中提取多尺度分段,并使用揚聲器嵌入提取器( TitaNet )生成用于多尺度音頻輸入的相應揚聲器嵌入向量。
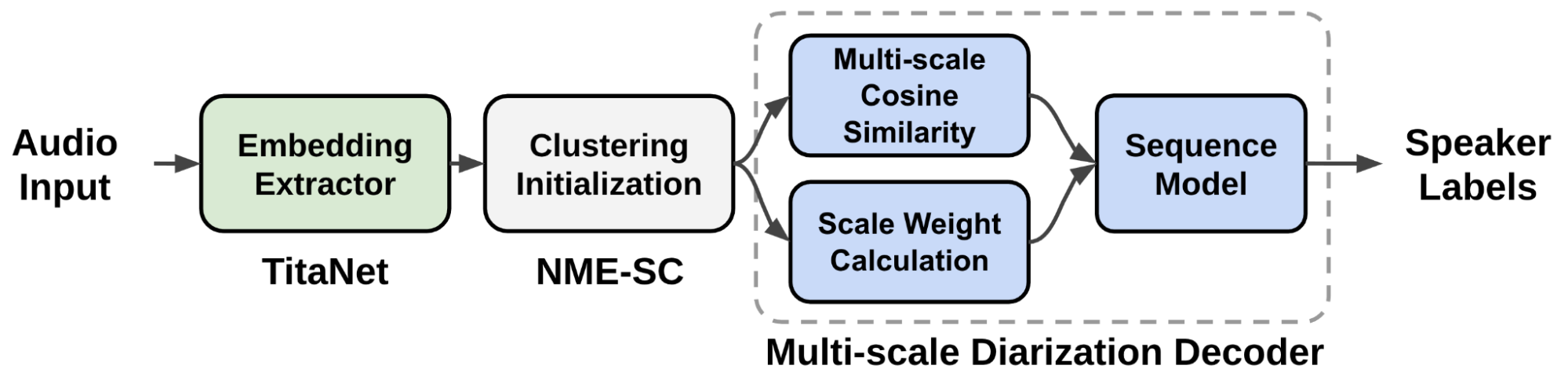
圖 3.擬建 多尺度說話人識別系統(tǒng) 的數(shù)據(jù)流
提取的多尺度嵌入通過聚類算法進行處理,以向 MSDD 模塊提供初始化聚類結(jié)果。 MSDD 模塊使用簇平均說話人嵌入向量與輸入說話人嵌入式序列進行比較。估計每個步驟的磅秤權(quán)重,以衡量每個磅秤的重要性。
最后,訓練序列模型輸出每個說話人的說話人標簽概率。
MSDD 機制
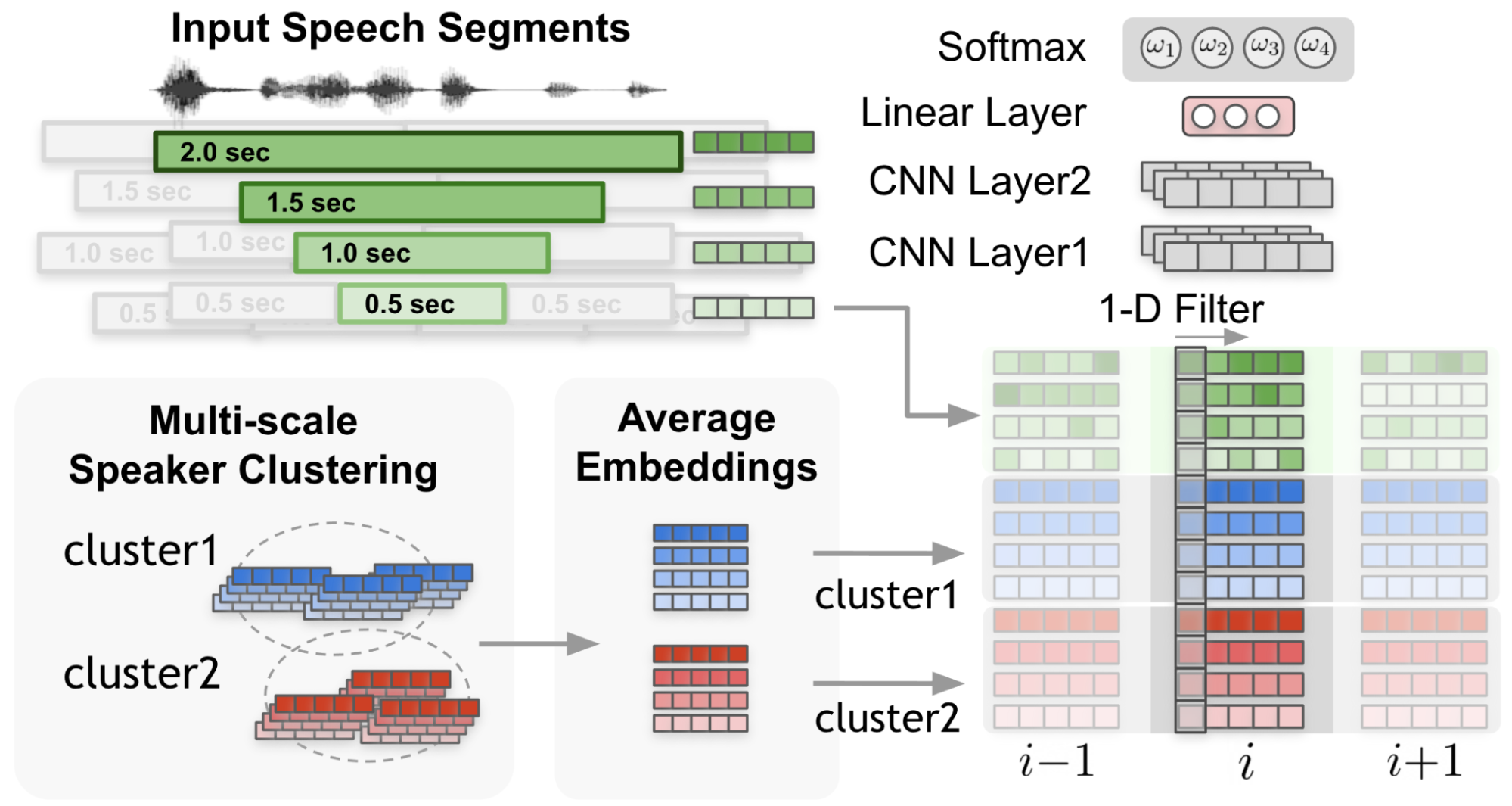
圖 4.根據(jù) MSDD 中的 1-D CNN 計算出的秤重量
在圖 4 中, 1-D 濾波器 從輸入嵌入和集群平均嵌入捕獲上下文。
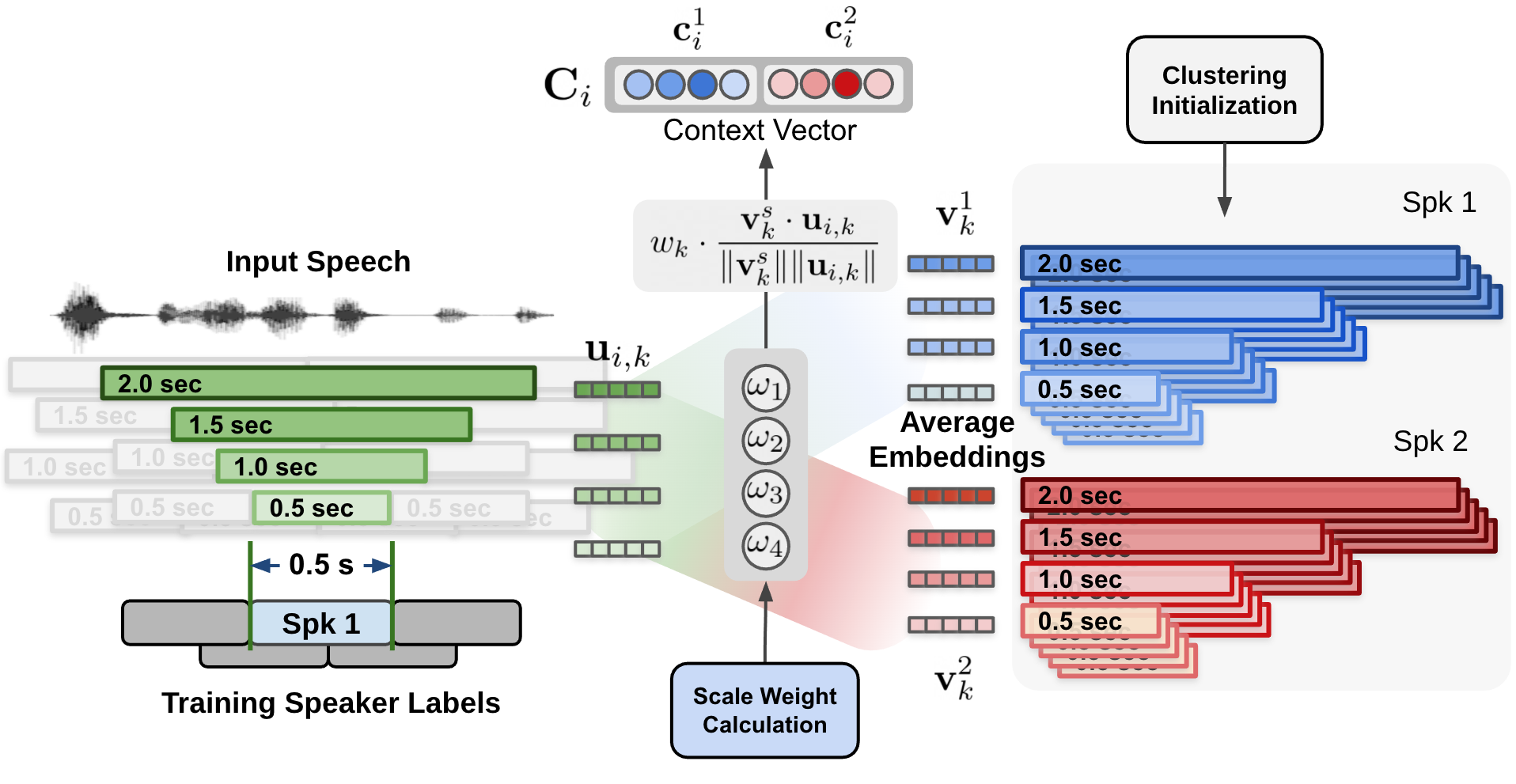
圖 5.MSDD 的上下文向量
在圖 5 中,每個說話人和每個尺度的余弦相似性值由尺度權(quán)重加權(quán),形成加權(quán)余弦相似向量。
通過動態(tài)計算每個尺度的權(quán)重,訓練神經(jīng)網(wǎng)絡模型 MSDD 以利用多尺度方法。 MSDD 獲取初始聚類結(jié)果,并將提取的說話人嵌入與聚類平均說話人表示向量進行比較。
最重要的是,每個時間步長的每個尺度的權(quán)重是通過尺度權(quán)重機制確定的,其中尺度權(quán)重是通過應用于多尺度說話人嵌入輸入和簇平均嵌入的一維卷積神經(jīng)網(wǎng)絡( CNN )計算得出的(圖 3 )。
估計的尺度權(quán)重應用于為每個說話人和每個尺度計算的余弦相似值。圖 5 顯示了通過對集群平均說話人嵌入和輸入說話人嵌入式之間計算出的余弦相似性(圖 4 )應用估計的比例權(quán)重來計算上下文向量的過程。
最后,每個步驟的每個上下文向量都被送入一個多層 LSTM 模型,該模型生成每個說話人的說話人存在概率。圖 6 顯示了 LSTM 模型和上下文向量輸入如何估計說話人標簽序列。
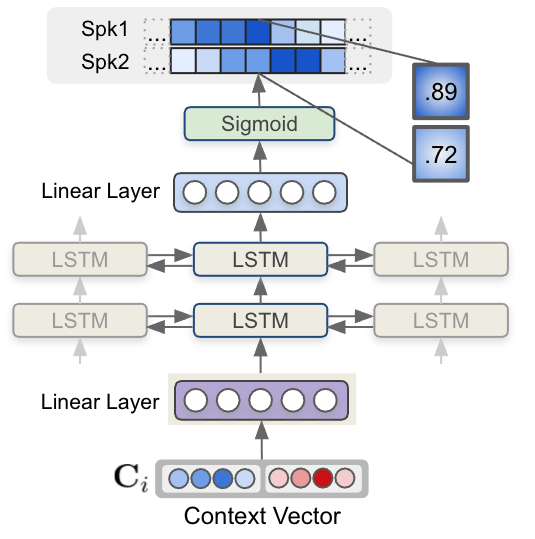
圖 6.使用 LSTM 的序列建模
圖 6 ,使用 LSTM 的序列建模接受上下文向量輸入并生成說話人標簽。 MSDD 的輸出是兩個說話人在每個時間步存在說話人的概率值。
擬議的說話人日記系統(tǒng)旨在支持以下功能:
揚聲器數(shù)量靈活
重疊感知區(qū)分
預訓練說話人嵌入模型
揚聲器數(shù)量靈活
MSDD 使用兩兩推理來記錄與任意數(shù)量說話人的對話。例如,如果有四個說話人,則提取六對,并對 MSDD 的推理結(jié)果進行平均,以獲得四個說話人中每個人的結(jié)果。
重疊感知區(qū)分
MSDD 獨立估計每個步驟中兩個揚聲器的兩個揚聲器標簽的概率(圖 6 )。這可以在兩個揚聲器同時講話的情況下進行重疊檢測。
預訓練說話人嵌入模型
MSDD 基于預處理嵌入提取器( TitaNet )模型。通過使用預處理說話人模型,可以使用從相對大量的單說話人語音數(shù)據(jù)中學習的神經(jīng)網(wǎng)絡權(quán)重。
此外, MSDD 設計為使用經(jīng)過預處理的說話人進行優(yōu)化,以在特定領(lǐng)域的說話者日記數(shù)據(jù)集上微調(diào)整個說話人日記系統(tǒng)。
實驗結(jié)果和定量效益
提出的 MSDD 系統(tǒng)有幾個定量優(yōu)勢:卓越的時間分辨率和提高的準確性。
卓越的時間分辨率
雖然單尺度聚類分解器在 1.5 秒的分段長度上表現(xiàn)出最佳性能,其中單位決策長度為 0.75 秒(半重疊),但提議的多尺度方法的單位決策長度是 0.25 秒。通過使用需要更多步驟和資源的更短移位長度,可以進一步提高時間分辨率。
圖 2 顯示了多尺度方法的概念和 0.5 秒的單位決策長度。由于揚聲器功能的保真度降低,僅將 0.5 秒的片段長度應用于單刻度分劃器會顯著降低分劃性能。
提高準確性
通過比較假設時間戳和地面真值時間戳來計算重化錯誤率( DER )。圖 7 顯示了多尺度二值化方法相對于最先進的單尺度聚類方法的量化性能。
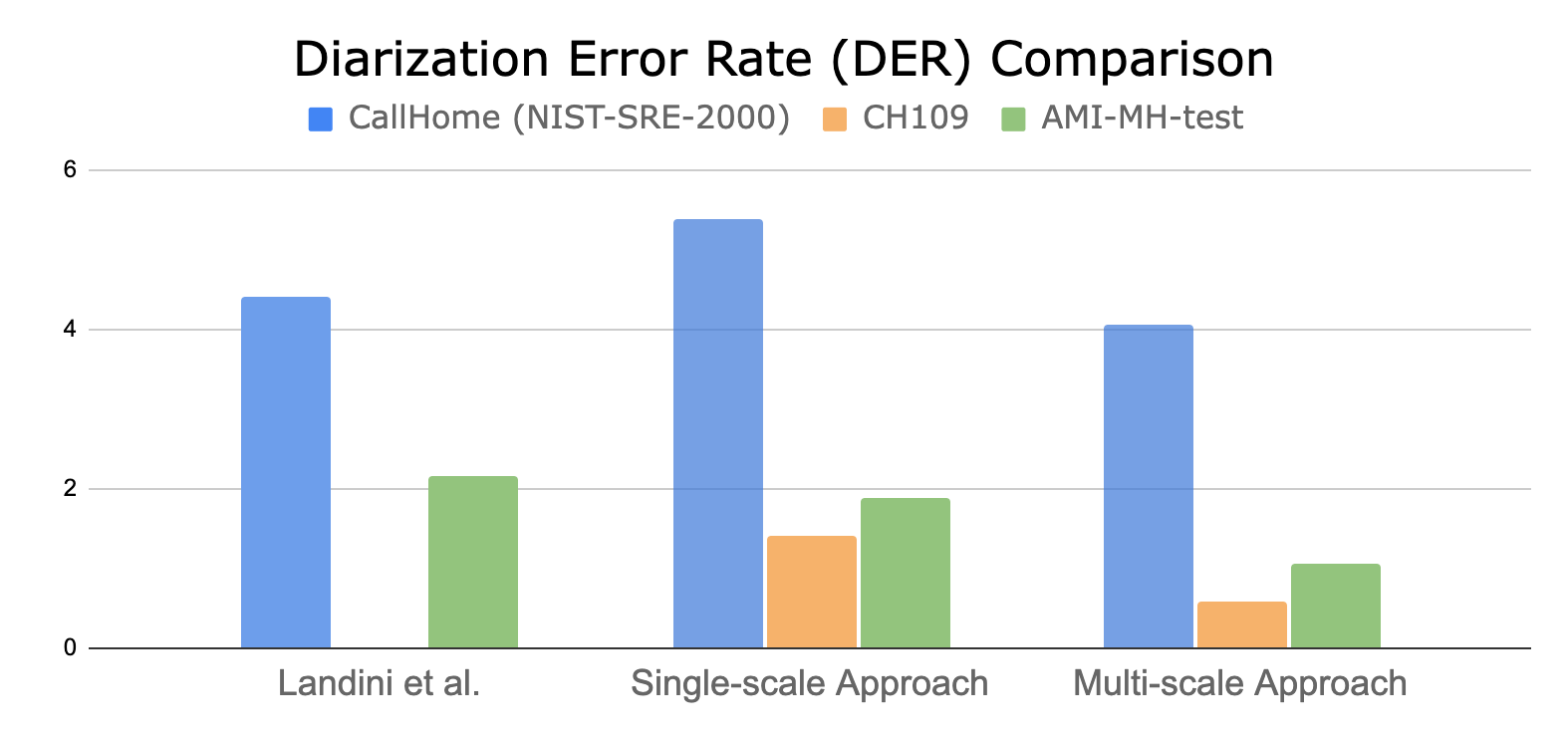
圖 7.先前最先進結(jié)果的定量評估 ( Landini et al. 2022 ) ,單尺度聚類法 ( prior work ) 和多尺度方法 ( proposed ) 關(guān)于三個不同的數(shù)據(jù)集
與單尺度聚類日記器相比,所提出的 MSDD 方法可以在兩個說話人數(shù)據(jù)集上減少多達 60% 的 DER 。
結(jié)論
擬議系統(tǒng)具有以下優(yōu)點:
這是第一個應用多尺度加權(quán)概念和基于序列模型( LSTM )的說話人標簽估計的神經(jīng)網(wǎng)絡架構(gòu)。
加權(quán)方案集成在單個推理會話中,不需要像其他說話人日記化系統(tǒng)那樣融合多個日記化結(jié)果。
提出的多尺度分解系統(tǒng)能夠?qū)崿F(xiàn)重疊感知的分解,這是傳統(tǒng)基于聚類的分解系統(tǒng)無法實現(xiàn)的。
因為解碼器基于基于聚類的初始化,所以分音系統(tǒng)可以處理靈活數(shù)量的說話人。這表明您可以在兩個說話人數(shù)據(jù)集上訓練建議的模型,然后使用它對兩個或更多說話人進行分類。
雖然具有前面提到的所有優(yōu)點,但與之前公布的結(jié)果相比,所提出的方法顯示了優(yōu)越的區(qū)分性能。
關(guān)于擬議系統(tǒng),未來有兩個研究領(lǐng)域:
我們計劃通過實現(xiàn)基于短期窗口聚類的二值化解碼器來實現(xiàn)該系統(tǒng)的流媒體版本。
可以研究從說話人嵌入提取器到二值化解碼器的端到端優(yōu)化,以提高說話人二值化性能。
關(guān)于作者
Taejin Park 在韓國首爾國立大學獲得電氣工程學士學位和電氣工程與計算機科學碩士學位。 2010 年和 2012 年。 2012 年,他加入韓國大田市電氣和電信研究所( ETRI ),擔任研究員。他畢業(yè)于南加州大學( USC ),獲得電氣工程博士學位和計算機科學碩士學位。 Taejin Park 目前在 NVIDIA 擔任應用科學家。他的研究興趣包括機器學習和專注于說話人日記化的語音信號處理。
審核編輯:郭婷
-
解碼器
+關(guān)注
關(guān)注
9文章
1143瀏覽量
40742 -
NVIDIA
+關(guān)注
關(guān)注
14文章
4986瀏覽量
103066
發(fā)布評論請先 登錄
相關(guān)推薦
關(guān)于labview中使用連續(xù)小波變換后接強度圖得到時間-尺度圖,如何將尺度轉(zhuǎn)換為頻率
基于尺度相乘的Canny改進算法
基于Kalman濾波的多尺度融合估計新算法
單傳感器單模型動態(tài)系統(tǒng)多尺度分解與估計新算法
模糊多尺度邊緣檢測算法的研究
基于小波分解的圖像融合方法及性能評價
基于多尺度小波分解和時間序列解決風電場預測精度等問題

基于引導濾波的Retinex多尺度分解色調(diào)映射算法
基于多尺度HOG的草圖檢索
如何使用多尺度和多任務卷積神經(jīng)網(wǎng)絡實現(xiàn)人群計數(shù)
如何使用跨尺度代價聚合實現(xiàn)改進立體匹配算法
結(jié)合多尺度邊緣保持分解與PCNN的圖像融合方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論