 用NVIDIA DGX cuQuantum設備實現超級計算規模的量子電路仿真
用NVIDIA DGX cuQuantum設備實現超級計算規模的量子電路仿真
量子電路模擬對于開發量子計算機的應用程序和算法至關重要。由于已知量子計算算法和用例的破壞性,政府、企業和學術界的量子算法研究人員正在開發新的量子算法,并在更大的量子系統上進行基準測試。
在沒有大規模糾錯量子計算機的情況下,開發這些算法的最佳方法是通過量子電路模擬。量子電路模擬需要大量計算, GPU 是計算量子態的天然工具。 為了模擬更大的量子系統,有必要將計算分布在多個 GPU 和多個節點上,以充分利用超級計算機的計算能力。
NVIDIA cuQuantum 是一個軟件開發工具包( SDK ),使用戶可以使用 GPU 輕松加速和縮放量子電路模擬,為探索量子優勢提供了新的能力。
此 SDK 包括最近發布的 NVIDIA DGX cuQuantum Appliance ,這是一個支持部署的軟件容器,具有多 GPU 狀態向量模擬支持。通用多 GPU API 現在也可在 cuStateVec 中使用,以便輕松集成到任何模擬器中。對于張量網絡模擬, cuQuantum cuTensorNet library 提供的切片 API 可實現分布在多個 GPU 或多個節點上的加速張量網絡收縮。這使得用戶可以利用 DGX A100 系統的近線性強伸縮性。
NVIDIA cuQuantum SDK 具有狀態向量和張量網絡方法庫。這篇文章主要關注用于多節點狀態向量模擬的 cuStateVec 和 DGX cuQuantum 設備 。如果您有興趣了解更多關于 cuTensorNet 和張量網絡方法的信息,請參見 使用 NVIDIA cuTensorNet 擴大 Quantum Circuit Simulation 。
什么是多節點、多 GPU 狀態矢量仿真
節點是由緊密互連的處理器組成的單個封裝單元,這些處理器經過優化,可以在保持機架就緒外形的同時協同工作。多節點多 GPU 狀態向量模擬利用了一個節點內的多個 GPU 和 GPU 的多個節點,以提供比其他方式更快的解決時間和更大的問題規模。
DGX 使用戶能夠利用高內存、低延遲和高帶寬。 DGX H100 system 由八個 H100 張量芯 GPU 組成,利用了 第四代 NVLink 和第三代 NVSwitch 。該節點是量子電路模擬的發電站。
在 DGX A100 節點上運行,所有八個 GPU 上都有啟用 NVIDIA 多 GPU 的 DGX cuQuantum Appliance ,對于三種常見的量子計算算法:量子傅里葉變換、肖氏算法和 Sycamore Supremacy 電路,在雙 64 核 AMD EPYC 7742 處理器上的速度提高了 70 到 290 倍。這使得用戶能夠使用單個 DGX A100 節點(八個 GPU ),通過全狀態矢量方法模擬多達 36 個量子比特。圖 1 所示的結果比我們上次宣布此功能的基準測試高出 4.4 倍,這是因為我們的團隊已經實現了只使用軟件的增強。
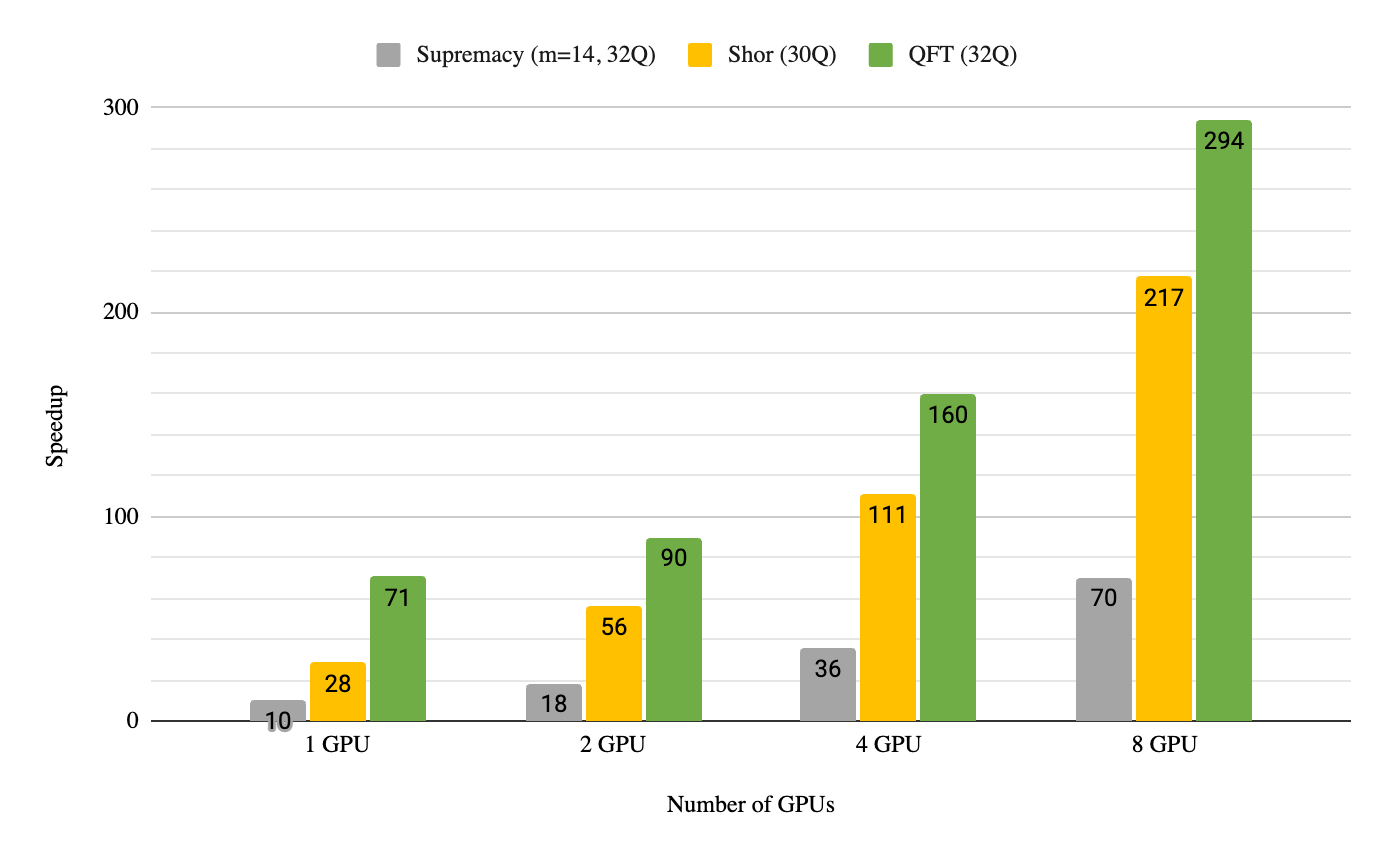
圖 1.DGX cuQuantum Appliance 多 GPU 加速超過最先進的雙插槽 CPU 服務器
NVIDIA cuStateVec 團隊深入研究了除單個節點內的多個 GPU 之外,利用多個節點的性能方法。因為大多數門應用程序都是完全并行的操作,所以節點內和跨節點的 GPU 可以被編排以進行分而治之。
在模擬過程中,狀態向量被分割并分布在 GPU 之間,每個 GPU 可以對其狀態向量的一部分并行應用一個門。在許多情況下,這可以在本地處理;然而,高階量子比特的門應用需要分布式狀態向量之間的通信。
一種典型的方法是首先對量子比特重新排序,然后在每個 GPU 中應用門,而不訪問其他 GPU 或節點。這種重新排序本身需要設備之間的數據傳輸。為了有效地做到這一點,高互連帶寬變得極其重要。在多個節點上有效地利用這種并行性是非常重要的。
介紹多節點 DGX cuQuantum Appliance
這里給出了基于性能和任意尺度狀態矢量的量子電路模擬的答案。 NVIDIA 很高興宣布新 DGX cuQuantum Appliance 提供的多節點、多 GPU 功能。在我們的下一版本中,任何 cuQuantum 容器用戶都將能夠快速、輕松地利用 IBM Qiskit 前端在世界上最大的 NVIDIA 系統上模擬量子電路。
cuQuantum 的任務是使盡可能多的用戶能夠輕松加速和縮放量子電路模擬。為此, cuQuantum 團隊正在努力將 NVIDIA 多節點方法生產成 API ,該 API 將于明年初正式上市。通過這種方法,您將能夠利用更廣泛的基于 NVIDIA GPU 的系統來擴展狀態向量量子電路模擬。
NVIDIA 多節點 DGX cuQuantum 設備正處于開發的最后階段,您很快就能利用 NVIDIA DGX SuperPOD 系統 的最佳性能。這將作為 NGC 托管的容器映像提供,您可以在 Docker 和幾行代碼的幫助下快速部署。
NVIDIA DGX H100 擁有所有 DGX 系統中最快的 I / O 架構,是大型 AI 群集(如 NVIDIA -DGX SuperPOD )的基礎構建塊,是可擴展 AI 的企業藍圖,現在是量子電路仿真基礎設施。 DGX H100 中的八臺 NVIDIA H100 GPU 使用新的高性能第四代 NVLink 技術,通過四臺第三代 NVSwitch 進行互連。
第四代 NVLink 技術提供了上一代 1.5 倍的通信帶寬,比 PCIe Gen5 快 7 倍。它提供了高達 7.2 TB / s 的 GPU 總吞吐量至 – GPU ,比上一代 DGX A100 提高了近 1.5 倍。
DGX H100 系統與隨附的八個 NVIDIA ConnectX-7 InfiniBand / Ethernet 適配器(每個適配器都以 400 GB / s 的速度運行)一起,提供了強大的高速結構,可在分布于多個節點的狀態矢量之間的全局通信中節省開銷。多節點、多 GPU cuQuantum 與大規模 GPU 加速計算相結合,利用最先進的網絡硬件和軟件優化,這意味著 DGX H100 系統可以擴展到數百或數千個節點,以應對最大的挑戰,例如將全狀態矢量量子電路模擬擴展到 50 個量子比特以上。
為了對這項工作進行基準測試,多節點 DGX cuQuantum Appliance 運行在 NVIDIA Selene Supercomputer 上,這是 NVIDIA DGX SuperPOD 系統的參考體系結構。截至 2022 年 6 月, Selene 在超級計算系統 TOP500 榜單中排名第八 ,以 63.5 petaflops 的速度執行高性能 Linpack ( HPL )基準測試,并以 24.0 giaflops /瓦特的速度在 Green500 名單上排名第 22 。
NVIDIA 利用多節點 DGX cuQuantum Appliance 運行基準測試: Quantum Volume 、 Quantum 近似優化算法( QAOA )和 Quantum 相位估計。量子體積電路的深度為 10 和 30 。 QAOA 是一種常用算法,用于解決相對而言近期量子計算機上的組合優化問題。我們用兩個參數運行它。
在前面的算法中演示了弱標度和強標度。很明顯,擴展到像 NVIDIA DGX SuperPOD 這樣的超級計算機對于加快解決時間和擴展相空間研究人員可以利用狀態矢量量子電路模擬技術探索的相空間都很有價值。
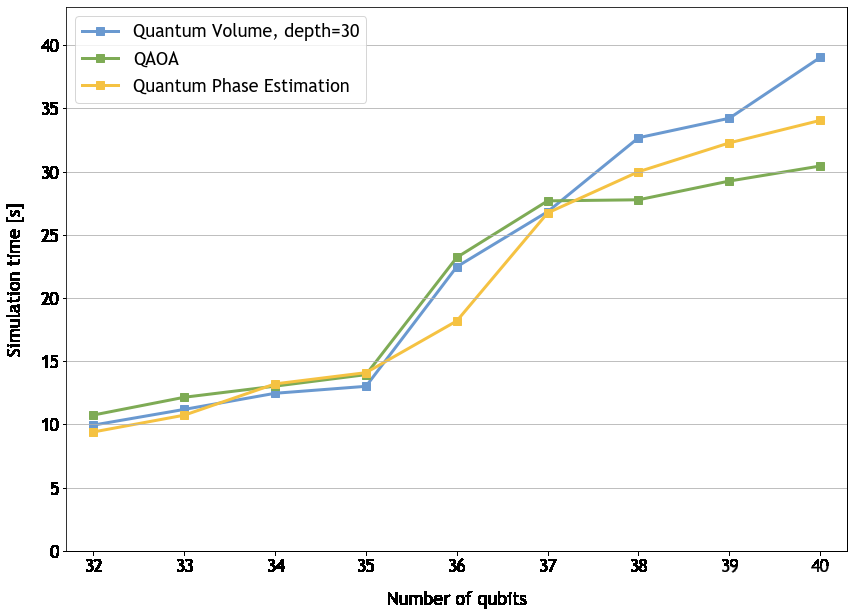
圖 2.DGX cuQuantum Appliance 多節點弱擴展性能,從 32 到 40 量子比特
我們正在通過更新的 DGX cuQuantum Appliance 進一步幫助用戶實現規模化。通過引入多節點功能,我們允許用戶在一個 GPU 上移動 32 個量子比特,在一個 NVIDIA 安培架構節點上移動 36 個量子比特。我們用 32 個 DGX A100 節點模擬了總共 40 個量子比特。用戶現在可以根據系統配置進一步擴展,軟件限制為 56 量子位或數百萬 DGX A100 節點。我們在 NVIDIA Hopper GPU 上的其他初步測試表明,這些數字在我們的下一代架構上會更好。
我們還衡量了我們多節點能力的強大擴展性。為了簡單起見,我們專注于 Quantum Volume 。圖 3 描述了當我們多次改變 GPU 的數量來解決同一問題時的性能。與最先進的雙插槽服務器 CPU 相比,在利用 16 個 DGX A100 節點時,我們獲得了 320 到 340 倍的加速。這也比以前最先進的量子體積實現快 3.5 倍(對于只有兩個 DGX A100 節點的 36 個量子比特,深度= 10 )。當添加更多節點時,這種加速會變得更加顯著。
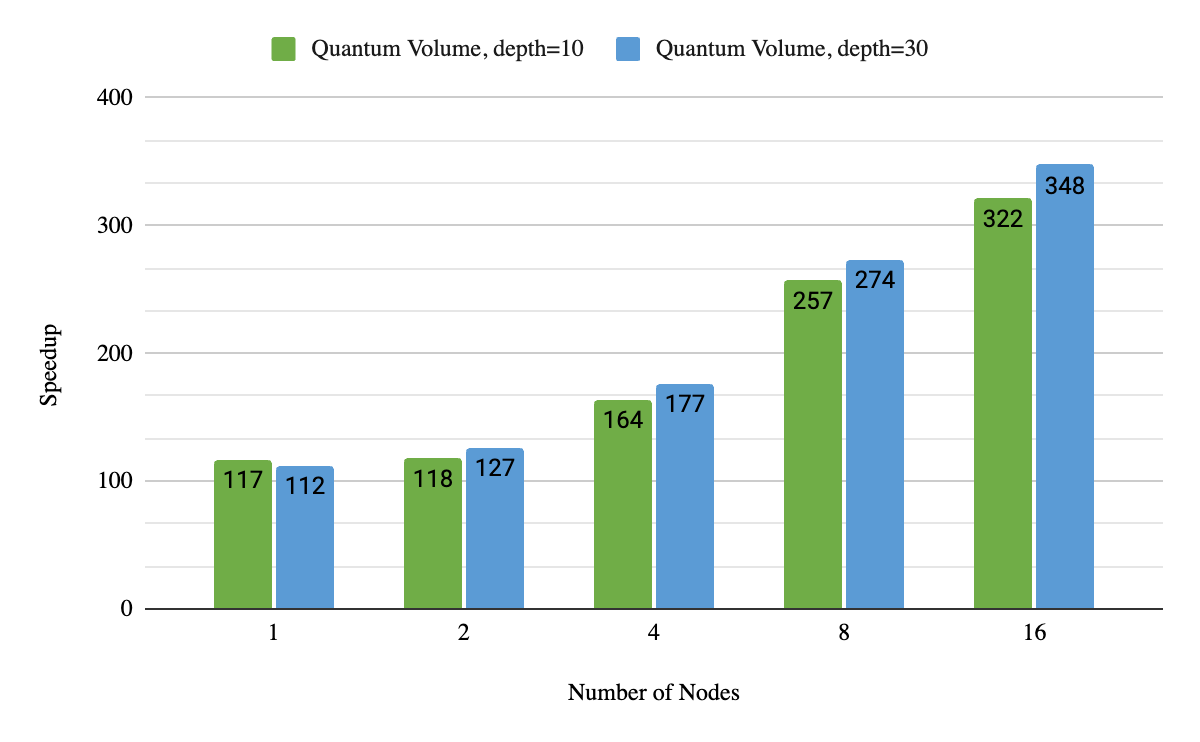
圖 3.與最先進的 CPU 服務器相比, DGX cuQuantum Appliance 多節點加速 32 qubit Quantum Volume
在最大的 NVIDIA 系統上模擬和縮放量子電路
NVIDIA 的 cuQuantum 團隊正在將狀態向量模擬擴展到多節點、多 GPU 。這使得終端用戶能夠對比以往任何時候都大的全狀態矢量進行量子電路模擬。 cuQuantum 不僅支持擴展,還支持性能,顯示節點之間的擴展能力較弱,擴展能力較強。
此外, cuQuantum 推出了第一個由 cuQuantom 支持的 IBM Qiskit 映像。在我們的下一個版本中,您將能夠拉動這個容器,從而使用這個流行的框架更容易、更快地擴展量子電路模擬。
關于作者
Tom Lubowe 是 NVIDIA 的量子計算產品經理。 Tom 擅長理解用戶需求,并將其與技術能力相協調。在加入之前,他曾在 Xanadu 、 Rigetti 等量子計算硬件初創公司和其他量子機器學習軟件初創公司擔任業務開發和產品管理職務。在致力于將量子計算帶給用戶之前,他曾在 SEI Investments 從事 FinTech 產品方面的工作。
Takuma Yamaguchi 是 NVIDIA 的 CUDA 數學庫小組的高級軟件工程師,在那里他致力于 cuStateVec 中量子算法的優化。他擁有東京大學土木工程博士學位。
Shinya Morino 是NVIDIA 高級解決方案架構師,隸屬于NVIDIA 人工智能技術中心( NVAITC )。他已經在 NVAITC 中原型化了一個 GPU 加速狀態向量模擬器,并正在利用他的知識推動 cuStateVec 的開發。新亞擁有日本東京大學的工程學博士學位。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5038瀏覽量
103306 -
gpu
+關注
關注
28文章
4754瀏覽量
129099 -
服務器
+關注
關注
12文章
9240瀏覽量
85702
發布評論請先 登錄
相關推薦
NVIDIA助力丹麥發布首臺AI超級計算機
借助NVIDIA超級計算機加速量子計算發展
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
電路仿真模擬器怎么用
電路仿真軟件如何使用 電路仿真軟件有哪些好用
電路仿真軟件如何使用 電路仿真軟件操作流程
電路仿真是什么意思 電路仿真怎么連線
電路仿真圖用什么軟件好
什么是電路仿真 數字電路仿真軟件哪個好用
電路仿真分析的方法步驟
NVIDIA Blackwell DGX SuperPOD助力萬億級生成式AI計算
NVIDIA推出搭載GB200 Grace Blackwell超級芯片的NVIDIA DGX SuperPOD?
NVIDIA 推出 Blackwell 架構 DGX SuperPOD,適用于萬億參數級的生成式 AI 超級計算






 工商網監
工商網監
評論