") 文本噪聲標簽在預訓練語言模型(PLMs)上的特性
文本噪聲標簽在預訓練語言模型(PLMs)上的特性
數(shù)據(jù)的標簽錯誤隨處可見,如何在噪聲數(shù)據(jù)集上學習到一個好的分類器,是很多研究者探索的話題。在 Learning With Noisy Labels 這個大背景下,很多方法在圖像數(shù)據(jù)集上表現(xiàn)出了非常好的效果。
而文本的標簽錯誤有時很難鑒別。比如對于一段文本,可能專家對于其主旨類別的看法都不盡相同。這些策略是否在語言模型,在文本數(shù)據(jù)集上表現(xiàn)好呢?本文探索了文本噪聲標簽在預訓練語言模型(PLMs)上的特性,提出了一種新的學習策略 SelfMix,并機器視覺上常用的方法應用于預訓練語言模型作為 baseline。
為什么選 PLMs
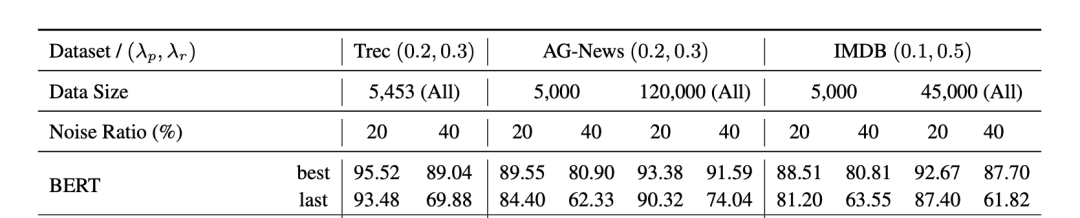
我們對于常見語言分類模型在帶噪文本數(shù)據(jù)集上做了一些前期實驗,結果如下:

首先,毫無疑問,預訓練模型(BERT,RoBERTa)的表現(xiàn)更好。其次,文章提到,預訓練模型已經(jīng)在大規(guī)模的預訓練語料上獲得了一定的類別先驗知識。故而在有限輪次訓練之后,依然具有較高的準確率,如何高效利用預訓練知識處理標簽噪聲,也是一個值得探索的話題。
預訓練模型雖然有一定的抗噪學習能力,但在下游任務的帶噪數(shù)據(jù)上訓練時也會受到噪聲標簽的影響,這種現(xiàn)象在少樣本,高噪聲比例的設置下更加明顯。
方法
由此,我們提出了 SelfMix,一種對抗文本噪聲標簽的學習策略。
基礎模型上,我們采用了 BERT encoder + MLP 這一常用的分類范式。
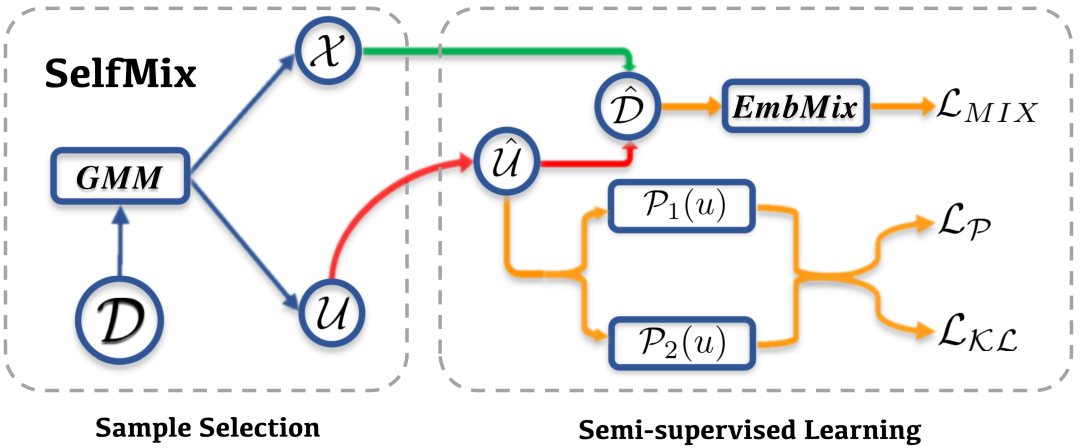
針對帶噪學習策略,主要可以分為兩個部分
Sample Selection
Semi-supervised Learning
Sample Selection
Sample Selection 部分對于原始數(shù)據(jù)集 ,經(jīng)過模型的一次傳播,根據(jù)每個樣本對應的 loss,通過 2 核的 GMM 擬合將數(shù)據(jù)集分為干凈和帶噪聲的兩個部分,分別為 和 。因為其中 被認為是噪聲數(shù)據(jù)集,所以其標簽全部被去除,認為是無標簽數(shù)據(jù)集。
這里的 GMM,簡單的來講其實可以看作是根據(jù)整體的 loss 動態(tài)擬合出一個閾值(而不是規(guī)定一個閾值,因為在訓練過程中這個閾值會變化),將 loss 位于閾值兩邊的分別分為 clean samples 和 noise samples。
Semi-supervised Learning
關于 Semi-supervised Learning 部分,SelfMix 首先利用模型給給無標簽的數(shù)據(jù)集打偽標簽(這里采用了 soft label 的形式),得到 。因為打偽標簽需要模型在這個下游任務上有一定的判別能力,所以模型需要預先 warmup 的少量的步數(shù)。
「Textual Mixup」:文中采用了句子 [CLS] embedding 做 mixup。Mixup 也是半監(jiān)督和魯棒學習中經(jīng)常采用的一個策略。
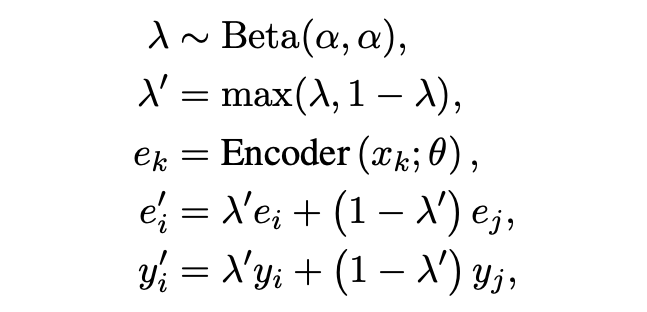
「Pseudo-Loss」:文中的解釋比較拗口,其實本質也是一種在半監(jiān)督訓練過程中常用的對模型輸出墑的約束。
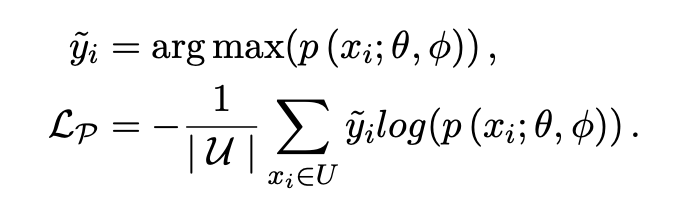
「Self-consistency Regularization」:其他的很多帶噪學習方法大都是多模型集成決策的想法,但我們認為可以利用 dropout 機制來使得單個模型做自集成。噪聲數(shù)據(jù)因為與標簽的真實分布相悖,往往會導致子模型之間產生很大的分歧,我們不希望在高噪聲環(huán)境下子模型的分歧越來越大,故而采用了 R-Drop 來約束子模型。具體的做法是,計算兩次傳播概率分布之間的 KL 散度,作為 loss 的一部分,并且消融實驗證明這個方法是十分有效的。
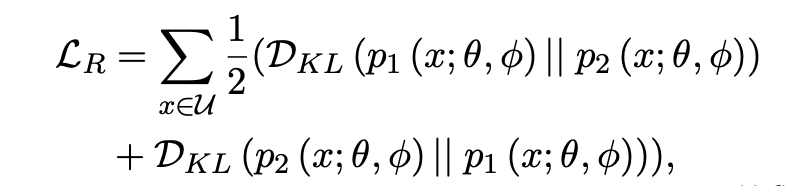
實驗
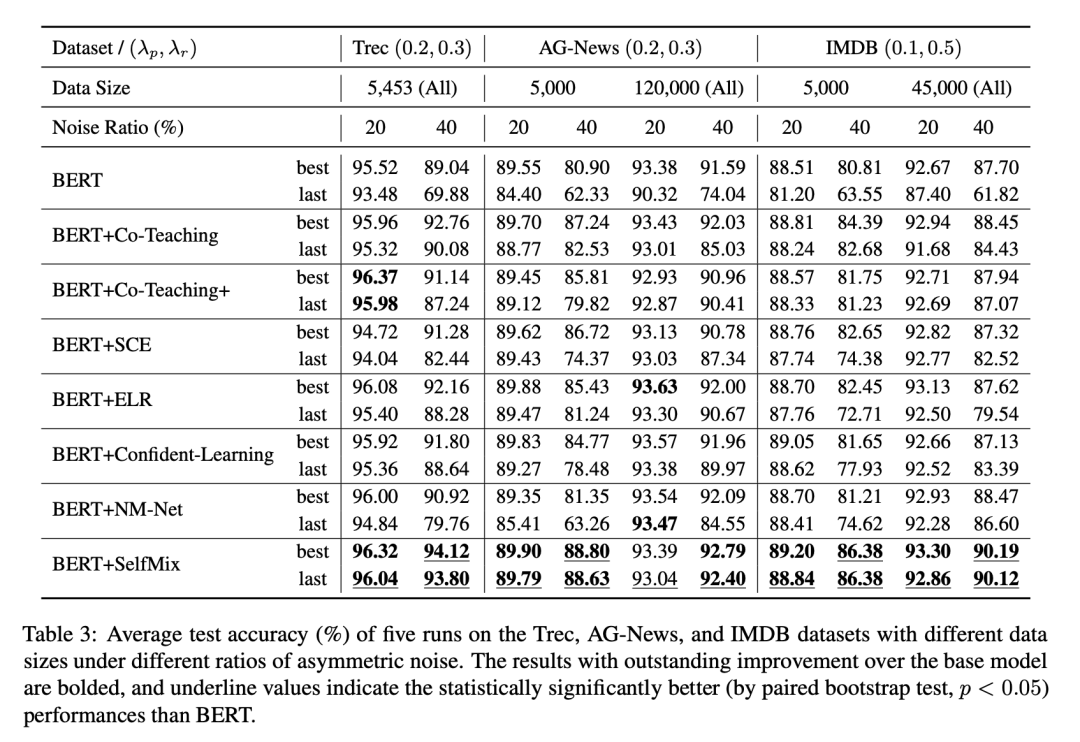
我們在 IDN (Instance-Dependent Noise) 和 Asym (Asymmetric Noise) 做了實驗,并且對數(shù)據(jù)集做了切分來擬合數(shù)據(jù)充分和數(shù)據(jù)補充的情況,并設置了不同比例的標簽噪聲來擬合微量噪聲至極端噪聲下的情況,上圖!
ASYM 噪聲實驗結果
ASYM 噪聲按照一個特定的噪聲轉移矩陣將一個類別樣本的標簽隨機轉換為一個特定類別的標簽,來形成類別之間的混淆。
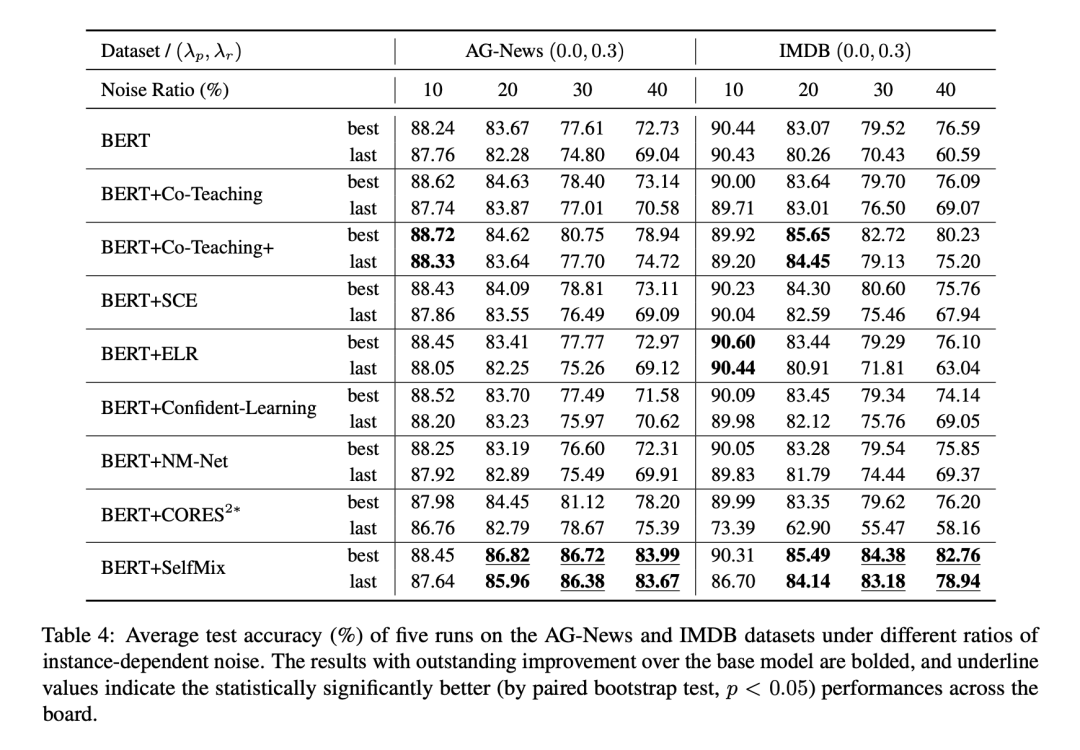
IDN 噪聲實驗結果
為了擬合基于樣本特征的錯標情況,我們訓練了一個LSTM文本分類,對于一個樣本,將LSTM對于其預測結果中更容易錯的類別作為其可能的噪聲標簽。
其他的一些討論
GMM 是否有效:從 a-c, d-f 可看出高斯混合模型能夠比較充分得擬合 clean 和 noise 樣本的 loss 分布。
SelfMix 對防止模型過擬合噪聲的效果是否明顯:d, h 兩張圖中,BERT-base 和 SelfMix 的 warmup 過程是完全一致的,warmup 過后 SelfMix 確實給模型的性能帶來了一定的提升,并且趨于穩(wěn)定,有效避免了過擬合噪聲的現(xiàn)象。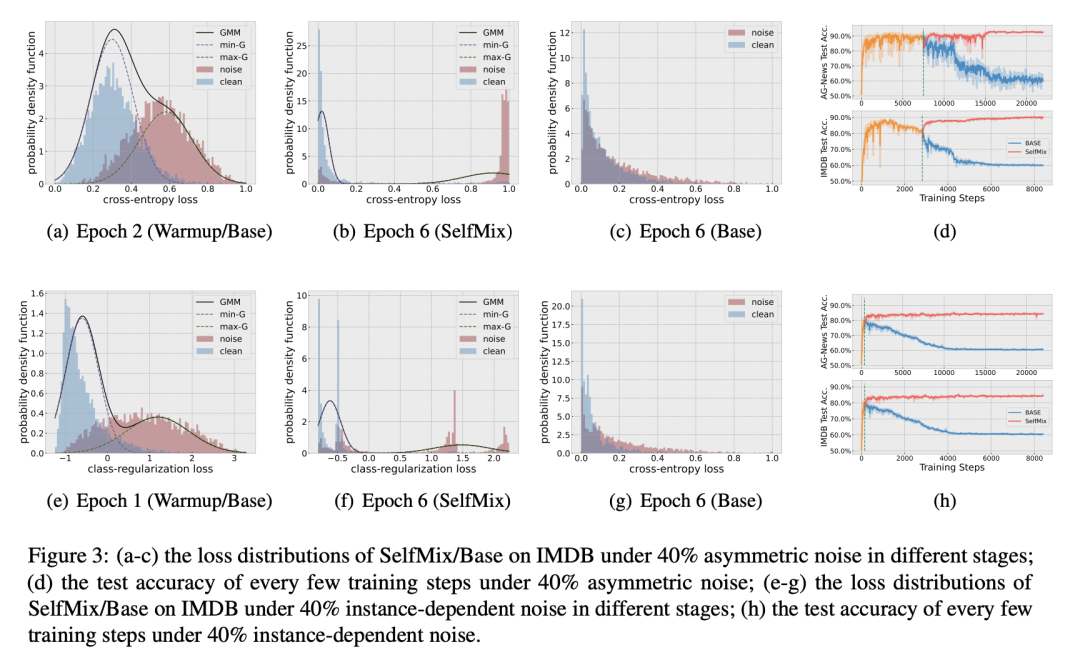
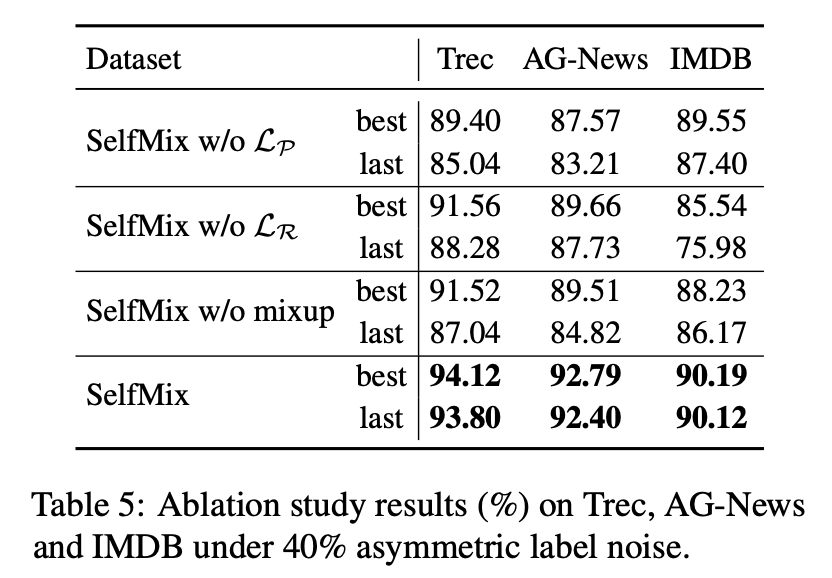
考慮到模型最終的優(yōu)化目標包括三個項,我們做了消融實驗,分別去掉其中一個約束來看看模型表現(xiàn)如何,最終證明每個約束確實對于處理噪聲標簽有幫助。
-
噪聲
+關注
關注
13文章
1122瀏覽量
47420 -
語言模型
+關注
關注
0文章
525瀏覽量
10277 -
數(shù)據(jù)集
+關注
關注
4文章
1208瀏覽量
24710
原文標題:COLING'22 | SelfMix:針對帶噪數(shù)據(jù)集的半監(jiān)督學習方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的預訓練
預訓練語言模型設計的理論化認識
基于BERT的中文科技NLP預訓練模型

Multilingual多語言預訓練語言模型的套路
一種基于亂序語言模型的預訓練模型-PERT
利用視覺語言模型對檢測器進行預訓練
CogBERT:腦認知指導的預訓練語言模型
復旦&微軟提出?OmniVL:首個統(tǒng)一圖像、視頻、文本的基礎預訓練模型
預訓練數(shù)據(jù)大小對于預訓練模型的影響
基于預訓練模型和語言增強的零樣本視覺學習






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論