 華為再出新品:GaussDB(for Influx)數據庫的魅力了解一下
華為再出新品:GaussDB(for Influx)數據庫的魅力了解一下
華為再出新品:GaussDB(for Influx)數據庫的魅力了解一下
華為自用的GaussDB(for Influx)數據庫逐漸深入大眾視野,到底值不值得期待?
``
時序數據庫想必大家都有所耳聞,現在在很多行業內都有所應用,它的優點就是可以根據時間段,每一分每一秒都精準地記錄和整理數據。最大的缺點也就顯而易見,因為產生數據的頻率過快,導致數據量過大,一天可以產生幾十GB,甚至達到TB級,久而久之形成了海量的時序數據,數據的存儲就成了最大的問題。如何在長久地保存這些數據的同時壓縮數據?傳統的數據庫肯定做不到,那么有沒有企業能突破這個瓶頸?
目前而言,華為推出的GaussDB(for Influx)時序數據庫是最能達到業內標準的。
GaussDB(for Influx)時序數據庫是華為在數據存儲領域摸爬滾打多年后,整合華為云多方面能力,大膽推出的技術創新。這一次也是華為內部經過多次反復調試達到了預期的效果后才決定將GaussDB(for Influx)時序數據庫對外開放,幫助上云企業解決相關業務問題。像華為這種大企業能認可的數據庫,肯定有兩把刷子在身上,敢推向市面也肯定有足夠的把握。
從框架上來看,時序數據庫分為三大部分。第一,Shard節點,主要負責數據的寫入和查詢,在這個節點內,除了分片和時間線管理外,還能預處理數據——聚合、降解預數據。第二,Config集群,可以儲存和管理元數據,采用三節點的復制模式,保證元數據的可靠性。第三,分布式存儲系統,能集中并且持久地存儲數據和日志,采用三副本方式存放,能用性和可靠性都毋庸置疑。
相比于InfluxDB等開源時序數據庫,GaussDB(for Influx)接口不僅完全兼容InfluxDB,寫入接口兼容OpenTSDB、Prometheus和Graphite,完全屬于上級和下級關系。GaussDB(for Influx)容錯率更高,可以容忍N-1節點故障;存儲與計算也是相互分離的,在保持高性能寫入的同時還可以進行查詢業務,也不用擔心系統故障導致業務中斷或者數據丟失,GaussDB(for Influx)可以實時保存。
擁有分鐘級計算節點擴容,秒級存儲擴容,GaussDB(for Influx)擴縮容比其他的數據庫更加快速。由于避免了遷移過程中大量數據的物理綁定約束,所以可以做到原來以天為單位的數據傳輸縮短為分鐘級別。精簡副本也是關鍵,消除冗雜的副本模式,降低儲存成本,提升用戶體驗感。
以上是GaussDB(for Influx)的優化內容,那么它的核心能力,又有哪些?
``
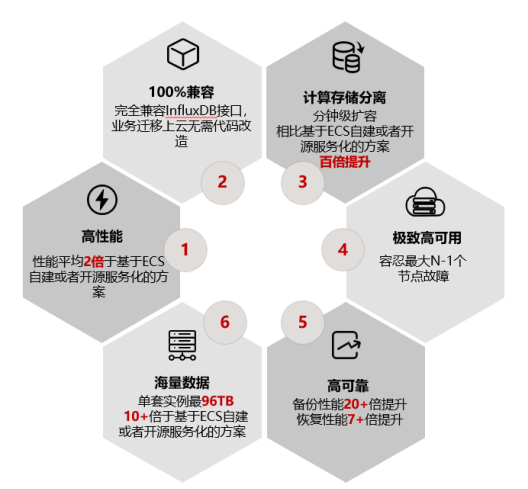
首先,支持億級時間線。在分配上,大量使用內存池復用技術,降低內存碎片;在回收上實現算法根據內存負載,能動態調整GC頻率,加快內存回收;在緩存上,根據不同的時間節點,調整不同的配置。通過這樣的改進,可以達到每天萬億條的數據寫入。 其次,極致寫入性能。GaussDB(for Influx)可以支持每天萬億條數據寫入,實現了集群處理,確保日志持久化,數據庫多副本復制卸載到分布式存儲,降低計算節點到存儲節點的網絡流量。在大規模寫入場景下,GaussDB(for Influx)的寫入性能線性擴展度大于80%。
再就是低成本的數據壓縮。為什么同樣的工作量卻只需1/20的存儲成本?原因就是采用不同的壓縮方式,將Gorilla壓縮算法進行了優化,先把數值轉為整數,再根據數據特點,選擇最合適的數據壓縮算法。選擇完合適的壓縮方式就是壓縮過程,采用了壓縮效率更好的ZSTD壓縮算法,并根據待壓縮數據的Length使用不同Level的編碼方法。最終采用差量壓縮方法,進一步降低時序數據存儲成本。而壓縮數據也只是節約成本的方式之一,GaussDB(for Influx)還特意提供了時序數據的分級存儲,可以自定義冷熱數據。選擇合適的儲存模式就能達到節約存儲成本的目的。
最后是高性能多維聚合查詢。多維聚合是時序數據庫中較為常見、且會定期重復執行的一種查詢。而基于滑動窗口的聚合查詢,大部分從聚合結果緩存中直接命中,僅需要聚合增量數據部分即可,加快查詢數據中的無關信息過濾。
GaussDB(for Influx)的應用場景非常廣泛,在能源、制造、IOT、互聯網等行業的監控統計及分析業務場景中都可以應用上,甚至可以說是必不可少的。當然GaussDB(for Influx)數據庫還將不斷提升數據的存儲模式,帶來更好的用戶體驗。
審核編輯 黃昊宇
-
華為
+關注
關注
216文章
34509瀏覽量
252378 -
數據庫
+關注
關注
7文章
3841瀏覽量
64545 -
人工智能
+關注
關注
1792文章
47514瀏覽量
239247
發布評論請先 登錄
相關推薦
MySQL數據庫的安裝
云數據庫是哪種數據庫類型?
數據庫數據恢復—Mysql數據庫表記錄丟失的數據恢復流程

數據庫事件觸發的設置和應用
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

Oracle數據恢復—Oracle數據庫delete刪除的數據恢復方法
Oracle數據恢復—Oracle刪除數據不用怕!這些數據恢復方法了解一下
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例

華為云GaussDB數據庫基礎版發布:旗艦性能、價格下降超60%
華為云多模數據庫 GeminiDB 架構與應用實踐直播問答實錄
選擇 KV 數據庫最重要的是什么?
傳感器之外—兩個數據庫之間的“連接”查詢
【數據庫數據恢復】Oracle數據庫ASM實例無法掛載的數據恢復案例





 工商網監
工商網監
評論