 Java進程所使用的內存情況介紹
Java進程所使用的內存情況介紹
0.引言
我們經常會好奇,我啟動了一個 JVM,他到底會占據多大的內存?他的內存都消耗在哪里?為什么 JVM 使用的內存比我設置的 -Xmx 大這么多?我的內存設置參數是否合理?為什么我的 JVM 內存一直緩慢增長?為什么我的 JVM 會被 OOMKiller 等等,這都涉及到 JAVA 虛擬機對內存的一個使用情況,不如讓我們來一探其中究竟。
1.簡介
除去大家都熟悉的可以使用 -Xms、-Xmx 等參數設置的堆(Java Heap),JVM 還有所謂的非堆內存(Non-Heap Memory)。
可以通過一張圖來簡單看一下 Java 進程所使用的內存情況(簡略情況):
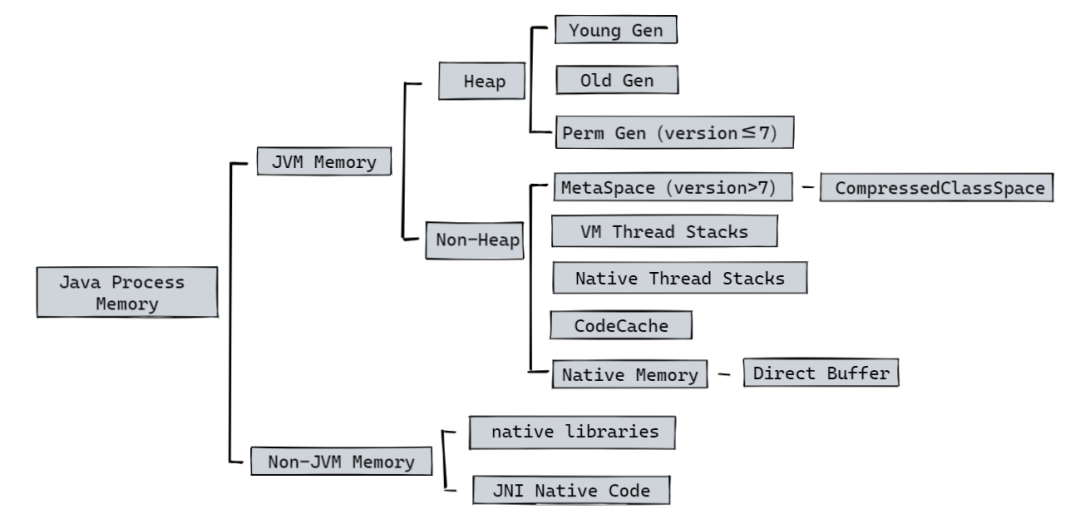
非堆內存包括方法區和Java虛擬機內部做處理或優化所需的內存。
方法區:在所有線程之間共享,存儲每個類的結構,如運行時常量池、字段和方法數據,以及方法和構造函數的代碼。方法區在邏輯上(虛擬機規范)是堆的一部分,但規范并不限定實現方法區的內存位置和編譯代碼的管理策略,所以不同的 Java 虛擬機可能有不同的實現方式,此處我們僅討論 HotSpot。
除了方法區域外,Java 虛擬機實現可能需要內存用于內部的處理或優化。例如,JIT編譯器需要內存來存儲從Java虛擬機代碼轉換的本機代碼(儲存在CodeCache中),以獲得高性能。
從 OpenJDK8 起有了一個很 nice 的虛擬機內部功能:Native Memory Tracking (NMT) 。我們可以使用 NMT 來追蹤了解 JVM 的內存使用詳情(即上圖中的 JVM Memory 部分),幫助我們排查內存增長與內存泄漏相關的問題。
2.如何使用
2.1 開啟 NMT
默認情況下,NMT是處于關閉狀態的,我們可以通過設置 JVM 啟動參數來開啟:-XX:NativeMemoryTracking=[off | summary | detail]。
注意:啟用NMT會導致5% -10%的性能開銷。
NMT 使用選項如下表所示:
| NMT 選項 | 說明 |
|---|---|
| off | 不跟蹤 JVM 本地內存使用情況。如果不指定 -XX:NativeMemoryTracking 選項則默認為off。 |
| summary | 僅跟蹤 JVM 子系統(如:Java heap、class、code、thread等)的內存使用情況。 |
| detail | 除了通過 JVM 子系統跟蹤內存使用情況外,還可以通過單獨的 CallSite、單獨的虛擬內存區域及其提交區域來跟蹤內存使用情況。 |
我們注意到,如果想使用 NMT 觀察 JVM 的內存使用情況,我們必須重啟 JVM 來設置 XX:NativeMemoryTracking 的相關選項,但是重啟會使得我們丟失想要查看的現場,只能等到問題復現時才能繼續觀察。
筆者試圖通過一種不用重啟 JVM 的方式來開啟 NMT ,但是很遺憾目前沒有這樣的功能。
JVM 啟動后只有被標記為 manageable 的參數才可以動態修改或者說賦值,我們可以通過 JDK management interface (com.sun.management.HotSpotDiagnosticMXBean API) 或者 jinfo -flag 命令來進行動態修改的操作,讓我們看下所有可以被修改的參數值(JDK8):
java-XX:+PrintFlagsFinal|grepmanageable
intxCMSAbortablePrecleanWaitMillis=100{manageable}
intxCMSTriggerInterval=-1{manageable}
intxCMSWaitDuration=2000{manageable}
boolHeapDumpAfterFullGC=false{manageable}
boolHeapDumpBeforeFullGC=false{manageable}
boolHeapDumpOnOutOfMemoryError=false{manageable}
ccstrHeapDumpPath={manageable}
uintxMaxHeapFreeRatio=100{manageable}
uintxMinHeapFreeRatio=0{manageable}
boolPrintClassHistogram=false{manageable}
boolPrintClassHistogramAfterFullGC=false{manageable}
boolPrintClassHistogramBeforeFullGC=false{manageable}
boolPrintConcurrentLocks=false{manageable}
boolPrintGC=false{manageable}
boolPrintGCDateStamps=false{manageable}
boolPrintGCDetails=false{manageable}
boolPrintGCID=false{manageable}
boolPrintGCTimeStamps=false{manageable}
很顯然,其中不包含 NativeMemoryTracking 。
2.2 使用 jcmd 訪問 NMT 數據
我們可以通過jcmd命令來很方便的查看 NMT 相關的數據:
jcmdVM.native_memory[summary|detail|baseline|summary.diff|detail.diff|shutdown][scale=KB|MB|GB]
jcmd 操作 NMT 選項如下表所示:
| jcmd NMT 選項 | 說明 |
|---|---|
| summary | 打印按類別匯總的摘要信息 |
| detail |
打印按類別匯總的內存使用情況 打印虛擬內存映射 打印按 call site 匯總的內存使用情況 |
| baseline | 創建一個新的內存使用狀況的快照,用以進行比較 |
| summary.diff | 根據上一個 baseline 基線打印新的 summary 對比報告 |
| detail.diff | 根據上一個 baseline 基線打印新的 detail 對比報告 |
| shutdown | 停止NMT |
NMT 默認打印的報告是 KB 來進行呈現的,為了滿足我們不同的需求,我們可以使用scale=MB | GB來更加直觀的打印數據。
創建 baseline 之后使用 diff 功能可以很直觀地對比出兩次 NMT 數據之間的差距。
看到 shutdown 選項,筆者本能的一激靈,既然我們可以通過 shutdown 來關閉 NMT ,那為什么不能通過逆向 shutdown 功能來動態的開啟 NMT 呢?筆者找到 shutdown 相關源碼(以下都是基于 OpenJDK 8):
#hotspot/src/share/vm/services/nmtDCmd.cpp voidNMTDCmd::execute(DCmdSourcesource,TRAPS){ //CheckNMTstate //nativememorytrackinghastobeon if(MemTracker::tracking_level()==NMT_off){ output()->print_cr("Nativememorytrackingisnotenabled"); return; }elseif(MemTracker::tracking_level()==NMT_minimal){ output()->print_cr("Nativememorytrackinghasbeenshutdown"); return; } ...... //執行shutdown操作 elseif(_shutdown.value()){ MemTracker::shutdown(); output()->print_cr("Nativememorytrackinghasbeenturnedoff"); } ...... } #hotspot/src/share/vm/services/memTracker.cpp //ShutdowncanonlybeissuedviaJCmd,andNMTJCmdisserializedbylock voidMemTracker::shutdown(){ //WecanonlyshutdownNMTtominimaltrackinglevelifitiseveron. if(tracking_level()>NMT_minimal){ transition_to(NMT_minimal); } } #hotspot/src/share/vm/services/nmtCommon.hpp //Nativememorytrackinglevel//NMT的追蹤等級 enumNMT_TrackingLevel{ NMT_unknown=0xFF, NMT_off=0x00, NMT_minimal=0x01, NMT_summary=0x02, NMT_detail=0x03 };
遺憾的是通過源碼我們發現,shutdown 操作只是將 NMT 的追蹤等級 tracking_level 變成了 NMT_minimal 狀態(而并不是直接變成了 off 狀態),注意注釋:We can only shutdown NMT to minimal tracking level if it is ever on(即我們只能將NMT關閉到最低跟蹤級別,如果它曾經打開)。
這就導致了如果我們沒有開啟過 NMT ,那就沒辦法通過魔改 shutdown 操作逆向打開 NMT ,因為 NMT 追蹤的部分內存只在 JVM 啟動初始化的階段進行記錄(如在初始化堆內存分配的過程中通過 NMT_TrackingLevel level = MemTracker::tracking_level(); 來獲取 NMT 的追蹤等級,視等級來記錄內存使用情況),JVM 啟動之后再開啟 NMT 這部分內存的使用情況就無法記錄,所以目前來看,還是只能在重啟 JVM 后開啟 NMT。
至于提供 shutdown 功能的原因,應該就是讓用戶在開啟 NMT 功能之后如果想要關閉,不用再次重啟 JVM 進程。shutdown 會清理虛擬內存用來追蹤的數據結構,并停止一些追蹤的操作(如記錄 malloc 內存的分配)來降低開啟 NMT 帶來的性能耗損,并且通過源碼可以發現 tracking_level 變成 NMT_minimal 狀態后也不會再執行 jcmd
2.3 虛擬機退出時獲取 NMT 數據
除了在虛擬機運行時獲取 NMT 數據,我們還可以通過兩個參數:-XX:+UnlockDiagnosticVMOptions和-XX:+PrintNMTStatistics,來獲取虛擬機退出時內存使用情況的數據(輸出數據的詳細程度取決于你設定的跟蹤級別,如 summary/detail 等)。
-XX:+UnlockDiagnosticVMOptions:解鎖用于診斷 JVM 的選項,默認關閉。
-XX:+PrintNMTStatistics:當啟用 NMT 時,在虛擬機退出時打印內存使用情況,默認關閉,需要開啟前置參數 -XX:+UnlockDiagnosticVMOptions 才能正常使用。
3.NMT 內存 & OS 內存概念差異性
我們可以做一個簡單的測試,使用如下參數啟動 JVM :
-Xmx1G-Xms1G-XX:+UseG1GC-XX:MaxMetaspaceSize=256m-XX:MaxDirectMemorySize=256m-XX:ReservedCodeCacheSize=256M-XX:NativeMemoryTracking=detail
然后使用 NMT 查看內存使用情況(因各環境資源參數不一樣,部分未明確設置數據可能由虛擬機根據資源自行計算得出,以下數據僅供參考):
jcmdVM.native_memorydetail
NMT 會輸出如下日志:
NativeMemoryTracking: Total:reserved=2813709KB,committed=1497485KB -JavaHeap(reserved=1048576KB,committed=1048576KB) (mmap:reserved=1048576KB,committed=1048576KB) -Class(reserved=1056899KB,committed=4995KB) (classes#442) (malloc=131KB#259) (mmap:reserved=1056768KB,committed=4864KB) -Thread(reserved=258568KB,committed=258568KB) (thread#127) (stack:reserved=258048KB,committed=258048KB) (malloc=390KB#711) (arena=130KB#234) -Code(reserved=266273KB,committed=4001KB) (malloc=33KB#309) (mmap:reserved=266240KB,committed=3968KB) -GC(reserved=164403KB,committed=164403KB) (malloc=92723KB#6540) (mmap:reserved=71680KB,committed=71680KB) -Compiler(reserved=152KB,committed=152KB) (malloc=4KB#36) (arena=148KB#21) -Internal(reserved=14859KB,committed=14859KB) (malloc=14827KB#3632) (mmap:reserved=32KB,committed=32KB) -Symbol(reserved=1423KB,committed=1423KB) (malloc=936KB#111) (arena=488KB#1) -NativeMemoryTracking(reserved=330KB,committed=330KB) (malloc=118KB#1641) (trackingoverhead=211KB) -ArenaChunk(reserved=178KB,committed=178KB) (malloc=178KB) -Unknown(reserved=2048KB,committed=0KB) (mmap:reserved=2048KB,committed=0KB) ......
大家可能會發現 NMT 所追蹤的內存(即 JVM 中的 Reserved、Committed)與操作系統 OS (此處指Linux)的內存概念存在一定的差異性。
首先按我們理解的操作系統的概念:
操作系統對內存的分配管理典型地分為兩個階段:保留(reserve)和提交(commit)。保留階段告知系統從某一地址開始到后面的dwSize大小的連續虛擬內存需要供程序使用,進程其他分配內存的操作不得使用這段內存;提交階段將虛擬地址映射到對應的真實物理內存中,這樣這塊內存就可以正常使用[1]。
如果使用 top 或者 smem 等命令查看剛才啟動的 JVM 進程會發現:
top PIDUSERPRNIVIRTRESSHRS%CPU%MEMTIME+COMMAND 36257dou+20010.8g5420017668S99.70.013:04.15java
此時疑問就產生了,為什么 NMT 中的 committed ,即日志詳情中 Total: reserved=2813709KB, committed=1497485KB 中的 1497485KB 與 top 中 RES 的大小54200KB 存在如此大的差異?
使用 man 查看 top 中 RES 的概念(不同版本 Linux 可能不同):
RES--ResidentMemorySize(KiB) Asubsetofthevirtualaddressspace(VIRT)representingthenon-swappedphysicalmemoryataskiscurrentlyusing.ItisalsothesumoftheRSan, RSfdandRSshfields. Itcanincludeprivateanonymouspages,privatepagesmappedtofiles(includingprogramimagesandsharedlibraries)plussharedanonymouspages. AllsuchmemoryisbackedbytheswapfilerepresentedseparatelyunderSWAP. Lastly,thisfieldmayalsoincludesharedfile-backedpageswhich,whenmodified,actasadedicatedswapfileandthuswillneverimpactSWAP.
RES 表示任務當前使用的非交換物理內存(此時未發生swap),那按對操作系統 commit 提交內存的理解,這兩者貌似應該對上,為何現在差距那么大呢?
筆者一開始猜測是 JVM 的 uncommit 機制(如 JEP 346[2],支持 G1 在空閑時自動將 Java 堆內存返回給操作系統,BiSheng JDK 對此做了增強與改進[3])造成的,JVM 在 uncommit 將內存返還給 OS 之后,NMT 沒有除去返還的內存導致統計錯誤。
但是在翻閱了源碼之后發現,G1 在 shrink 縮容的時候,通常調用鏈路如下:
G1CollectedHeap::shrink->
G1CollectedHeap::shrink_helper->
HeapRegionManager::shrink_by->
HeapRegionManager::uncommit_regions->
G1PageBasedVirtualSpace::uncommit->
G1PageBasedVirtualSpace::uncommit_internal->
os::uncommit_memory
忽略細節,uncommit 會在最后調用 os::uncommit_memory ,查看 os::uncommit_memory 源碼:
boolos::uncommit_memory(char*addr,size_tbytes){
boolres;
if(MemTracker::tracking_level()>NMT_minimal){
Trackertkr=MemTracker::get_virtual_memory_uncommit_tracker();
res=pd_uncommit_memory(addr,bytes);
if(res){
tkr.record((address)addr,bytes);
}
}else{
res=pd_uncommit_memory(addr,bytes);
}
returnres;
}
可以發現在返還 OS 內存之后,MemTracker 是進行了統計的,所以此處的誤差不是由 uncommit 機制造成的。
既然如此,那又是由什么原因造成的呢?筆者在追蹤 JVM 的內存分配邏輯時發現了一些端倪,此處以Code Cache(存放 JVM 生成的 native code、JIT編譯、JNI 等都會編譯代碼到 native code,其中 JIT 生成的 native code 占用了 Code Cache 的絕大部分空間)的初始化分配為例,其大致調用鏈路為下:
InitializeJVM->
Thread::vreate_vm->
init_globals->
codeCache_init->
CodeCache::initialize->
CodeHeap::reserve->
VirtualSpace::initialize->
VirtualSpace::initialize_with_granularity->
VirtualSpace::expand_by->
os::commit_memory
查看 os::commit_memory 相關源碼:
boolos::commit_memory(char*addr,size_tsize,size_talignment_hint,
boolexecutable){
boolres=os::pd_commit_memory(addr,size,alignment_hint,executable);
if(res){
MemTracker::record_virtual_memory_commit((address)addr,size,CALLER_PC);
}
returnres;
}
我們發現 MemTracker 在此記錄了 commit 的內存供 NMT 用以統計計算,繼續查看 os::pd_commit_memory 源碼,可以發現其調用了 os::commit_memory_impl 函數。
查看 os::commit_memory_impl 源碼:
intos::commit_memory_impl(char*addr,size_tsize,boolexec){
intprot=exec?PROT_READ|PROT_WRITE|PROT_EXEC:PROT_READ|PROT_WRITE;
uintptr_tres=(uintptr_t)::mmap(addr,size,prot,
MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS,-1,0);
if(res!=(uintptr_t)MAP_FAILED){
if(UseNUMAInterleaving){
numa_make_global(addr,size);
}
return0;
}
interr=errno;//saveerrnofrommmap()callabove
if(!recoverable_mmap_error(err)){
warn_fail_commit_memory(addr,size,exec,err);
vm_exit_out_of_memory(size,OOM_MMAP_ERROR,"committingreservedmemory.");
}
returnerr;
}
問題的原因就在 uintptr_t res = (uintptr_t) ::mmap(addr, size, prot, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0); 這段代碼上。
我們發現,此時申請內存執行的是 mmap 函數,并且傳遞的 port 參數是 PROT_READ|PROT_WRITE|PROT_EXEC 或 PROT_READ|PROT_WRITE ,使用 man 查看 mmap ,其中相關描述為:
Theprotargumentdescribesthedesiredmemoryprotectionofthemapping(andmustnotconflictwiththeopenmodeofthefile).ItiseitherPROT_NONE orthebitwiseORofoneormoreofthefollowingflags: PROT_EXECPagesmaybeexecuted. PROT_READPagesmayberead. PROT_WRITEPagesmaybewritten. PROT_NONEPagesmaynotbeaccessed.
由此我們可以看出,JVM 中所謂的 commit 內存,只是將內存 mmaped 映射為可讀可寫可執行的狀態!而在 Linux 中,在分配內存時又是 lazy allocation 的機制,只有在進程真正訪問時才分配真實的物理內存。所以 NMT 中所統計的 committed 并不是對應的真實的物理內存,自然與 RES 等統計方式無法對應起來。
所以 JVM 為我們提供了一個參數 -XX:+AlwaysPreTouch,使我們可以在啟動之初就按照內存頁粒度都訪問一遍 Heap,強制為其分配物理內存以減少運行時再分配內存造成的延遲(但是相應的會影響 JVM 進程初始化啟動的時間),查看相關代碼:
voidos::pretouch_memory(char*start,char*end){
for(volatilechar*p=start;p
讓我們來驗證下,開啟 -XX:+AlwaysPreTouch 前后的效果。
NMT 的 heap 地址范圍:
Virtualmemorymap:
[0x00000000c0000000-0x0000000100000000]reserved1048576KBforJavaHeapfrom
[0x0000ffff93ea36d8]ReservedHeapSpace::ReservedHeapSpace(unsignedlong,unsignedlong,bool,char*)+0xb8
[0x0000ffff93e67f68]Universe::reserve_heap(unsignedlong,unsignedlong)+0x2d0
[0x0000ffff93898f28]G1CollectedHeap::initialize()+0x188
[0x0000ffff93e68594]Universe::initialize_heap()+0x15c
[0x00000000c0000000-0x0000000100000000]committed1048576KBfrom
[0x0000ffff938bbe8c]G1PageBasedVirtualSpace::commit_internal(unsignedlong,unsignedlong)+0x14c
[0x0000ffff938bc08c]G1PageBasedVirtualSpace::commit(unsignedlong,unsignedlong)+0x11c
[0x0000ffff938bf774]G1RegionsLargerThanCommitSizeMapper::commit_regions(unsignedint,unsignedlong)+0x5c
[0x0000ffff93943f54]HeapRegionManager::commit_regions(unsignedint,unsignedlong)+0x7c
對應該地址的/proc/{pid}/smaps:
//開啟前//開啟后
c0000000-100080000rw-p0000000000:000c0000000-100080000rw-p0000000000:000
Size:1049088kB Size:1049088kB
KernelPageSize:4kBKernelPageSize: 4kB
MMUPageSize: 4kBMMUPageSize: 4kB
Rss: 792kBRss: 1049088kB
Pss:792kBPss: 1049088kB
Shared_Clean: 0kBShared_Clean: 0kB
Shared_Dirty: 0kBShared_Dirty: 0kB
Private_Clean: 0kBPrivate_Clean: 0kB
Private_Dirty: 792kBPrivate_Dirty: 1049088kB
Referenced: 792kBReferenced: 1048520kB
Anonymous: 792kBAnonymous: 1049088kB
LazyFree: 0kBLazyFree: 0kB
AnonHugePages: 0kBAnonHugePages: 0kB
ShmemPmdMapped: 0kBShmemPmdMapped: 0kB
Shared_Hugetlb:0kBShared_Hugetlb: 0kB
Private_Hugetlb:0kBPrivate_Hugetlb: 0kB
Swap:0kBSwap: 0kB
SwapPss:0kBSwapPss: 0kB
Locked:0kBLocked: 0kB
VmFlags:rdwrmrmwmeacVmFlags:rdwrmrmwmeac
對應的/proc/{pid}/status:
//開啟前//開啟后
......
VmHWM:54136kBVmHWM:1179476kB
VmRSS:54136kBVmRSS:1179476kB
......
VmSwap:0kBVmSwap:0kB
...
開啟參數后的 top:
PIDUSERPRNIVIRTRESSHRS%CPU%MEMTIME+COMMAND
85376dou+20010.8g1.1g17784S99.70.414:56.31java
觀察對比我們可以發現,開啟 AlwaysPreTouch 參數后,NMT 統計的 commited 已經與 top 中的 RES 差不多了,之所以不完全相同是因為該參數只能 Pre-touch 分配 Java heap 的物理內存,至于其他的非 heap 的內存,還是受到 lazy allocation 機制的影響。
同理我們可以簡單看下 JVM 的 reserve 機制:
#hotspot/src/share/vm/runtime/os.cpp
char*os::reserve_memory(size_tbytes,char*addr,size_talignment_hint,
MEMFLAGSflags){
char*result=pd_reserve_memory(bytes,addr,alignment_hint);
if(result!=NULL){
MemTracker::record_virtual_memory_reserve((address)result,bytes,CALLER_PC);
MemTracker::record_virtual_memory_type((address)result,flags);
}
returnresult;
}
#hotspot/src/os/linux/vm/os_linux.cpp
char*os::pd_reserve_memory(size_tbytes,char*requested_addr,
size_talignment_hint){
returnanon_mmap(requested_addr,bytes,(requested_addr!=NULL));
}
staticchar*anon_mmap(char*requested_addr,size_tbytes,boolfixed){
......
addr=(char*)::mmap(requested_addr,bytes,PROT_NONE,
flags,-1,0);
......
}
reserve 通過mmap(requested_addr, bytes, PROT_NONE, flags, -1, 0);來將內存映射為 PROT_NONE,這樣其他的 mmap/malloc 等就不能調用使用,從而達到了 guard memory 或者說 guard pages 的目的。
OpenJDK 社區其實也注意到了 NMT 內存與 OS 內存差異性的問題,所以社區也提出了相應的 Enhancement 來增強功能:
JDK-8249666[4]:
目前 NMT 將分配的內存顯示為 Reserved 或 Committed。而在 top 或 pmap 的輸出中,首次使用(即 touch)之前 Reserved 和 Committed 的內存都將顯示為 Virtual memory。只有在內存頁(通常是4k)首次寫入后,它才會消耗物理內存,并出現在 top/pmap 輸出的 “常駐內存”(即 RSS)中。
當前NMT輸出的主要問題是,它無法區分已 touch 和未 touch 的 Committed 內存。
該 Enhancement 提出可以使用 mincore()[5]來查找 NMT 的 Committed 中 RSS 的部分,mincore() 系統調用讓一個進程能夠確定一塊虛擬內存區域中的分頁是否駐留在物理內存中。mincore()已在JDK-8191369 NMT:增強線程堆棧跟蹤中實現,需要將其擴展到所有其他類型的內存中(如 Java 堆)。
遺憾的是該 Enhancement 至今仍是 Unresolved 狀態。
JDK-8191369[6]:
1 中提到的 NMT:增強線程堆棧跟蹤。使用 mincore() 來追蹤駐留在物理內存中的線程堆棧的大小,用以解決線程堆棧追蹤時有時會夸大內存使用情況的痛點。
該 Enhancement 已經在 JDK11 中實現。
由于內容較多,關于NMT追蹤區域分析的內容將在下篇文章進行分享,敬請期待!
審核編輯:彭靜
-
內存
+關注
關注
8文章
3045瀏覽量
74204 -
JAVA
+關注
關注
19文章
2973瀏覽量
104939 -
函數
+關注
關注
3文章
4344瀏覽量
62853 -
虛擬機
+關注
關注
1文章
919瀏覽量
28341
原文標題:Native Memory Tracking 詳解(1):基礎介紹
文章出處:【微信號:openEulercommunity,微信公眾號:openEuler】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Java多線程的用法
Linux 查看進程和刪除進程
Linux上對進程進行內存分析和內存泄漏定位
linux內存的進程查看
Java程序內存低效使用問題的分析
java線程內存模型
Java內存模型及原理分析
Linux下進程的內存結構





 工商網監
工商網監
評論