 芯片架構師需要考慮哪些問題
芯片架構師需要考慮哪些問題
我們認為半導體世界中的許多事情是理所當然的,但如果幾十年前做出的某些決定不再可行或最優了,我們應該怎么辦?我們看到了一個使用 finFET 的小例子,平面晶體管將不再擴展。今天,我們面臨著幾個更大的破壞,這些破壞將產生更大的連鎖反應。
技術通常以線性方式發展。每一步都提供了對以前存在的增量改進,或者克服了一些新的挑戰。這些挑戰來自新節點、新物理效果或限制等。雖然這非常有效,而且許多單獨的步驟都很出色,但它建立在紙牌屋的基礎上,如果基礎上的某些東西從根本上來說變化,整個設計、實現和驗證的連鎖反應可能非常顯著。
單個連續內存
這些更改之一已經進行了一段時間。1945 年首次描述的馮諾依曼處理器架構,具有單一的連續內存空間,是絕對的突破。它提供了一個圖靈完備的解決方案,可以解決任何有限問題。這成為幾乎所有計算機的實際架構。
內存很快成為了大小和性能方面的限制。為了克服這個問題,引入了緩存以使廉價的大容量內存看起來像更昂貴、更快的內存。隨著時間的推移,這些緩存變得多級,跨多個主機連貫,并在越來越大的地址空間上工作。
但這不再是許多現代計算功能的要求。在基于對象的軟件功能和特定領域計算的時代,對內存組織的需求可能是有害的。它基于這樣一個前提,即程序可以隨機訪問它想要的任何東西——安全專家希望這不是真的。
必須充分考慮緩存和一致性的全部成本。“在芯片中實現一致性是復雜且昂貴的,” Imperas Software的創始人兼首席執行官 Simon Davidmann 說。“當您進行多級緩存時,內存層次結構變得越來越復雜,并且越來越充滿錯誤,并且消耗越來越多的功率。”
當任務很好理解時,可以避免這種開銷。“在數據流引擎中,一致性不那么重要,因為您將在邊緣移動的數據直接從一個加速器傳送到另一個加速器,” Arteris IP的研究員兼系統架構師 Michael Frank 說。“如果你對數據集進行分區,一致性就會成為障礙,因為它會花費你額外的周期。您必須使用查找表。您必須提供更新信息。”
面向對象系統的采用,以及限制類型轉換的強類型語言和對程序員的一些限制,可以使執行流程可預測并避免對單個連續內存空間的需求。諸如在圖形和機器學習中發現的任務在有限的內存塊上運行,并且不會從復雜的內存管理或對內存的硬件控制中受益。
特定領域的計算正在導致人們重新考慮這方面的許多方面。“例如,DSP 傾向于提供分布式內存池,通常直接在軟件中管理,” Arm研發團隊的高級首席研究工程師 Matt Horsnell 說。“與傳統的共享內存系統相比,這可能更適合專門應用程序的帶寬要求和訪問模式。這些處理器通常通過提供對特定訪問模式(例如,N 緩沖、FIFO、行緩沖區、壓縮等)的直接支持來提供某種形式的內存專業化。”
新的內存類型
改變內存架構有很大的影響。“挑戰在于,在過去,人們有一個很好的抽象模型來思考計算系統,” Rambus的研究員和杰出發明家 Steven Woo 說。“他們從來沒有真正考慮過存儲。它最初是免費出現的,而編程模型只是讓你在引用內存時,它就發生了。你永遠不必明確說明你在做什么。隨著摩爾定律的放緩和功率縮放的停止,人們開始意識到有很多新的存儲可以進入方程式。但要讓它們真正有用,你必須擺脫我們過去擁有的非常抽象的觀點。”
第二個相關的變化是通過新的內存技術實現的。長期以來,SRAM 和 DRAM 都針對速度、密度和性能進行了優化。但是 DRAM 的擴展已經停滯不前,而且 SRAM 受到最新節點的可變性的影響,因此難以保持密度。基于不同物理特性的新內存類型最終可能會更好,但這可能不是主要好處。
例如,如果采用ReRAM,存儲單元本質上就會變成模擬的,這就開辟了許多可能性。Mythic 負責產品和業務開發的高級副總裁 Tim Vehling 說:“模擬的一個基本理念是,您實際上可以在存儲單元本身中進行計算。” “你實際上消除了整個內存移動問題,因此功率大幅下降。當模擬發揮作用時,您可以進行高效的計算和很少的數據移動。借助模擬內存計算技術,它的能效實際上比數字等效技術高出幾個數量級。”
這與機器學習所需的乘法/累加函數完全一致。“執行這些 MAC 操作所消耗的能量是巨大的,”西門子 EDA產品經理 Sumit Vishwakarma 說。“神經網絡有權重,這些權重存在于內存中。他們必須不斷地訪問內存,這是一項非常耗能的任務。計算能力是傳輸數據所需能力的十分之一。為了解決這個問題,公司和大學正在研究模擬計算,它將權重存儲在內存中。現在我只需要輸入一些輸入并得到一個輸出,這基本上是這些權重與我的輸入的乘積。”
當模擬和數字解耦時,模擬電路不再受阻。Semtech 信號完整性解決方案集團營銷和應用副總裁 Tim Vang 說:“我們可以設計模擬電路,在某些情況下提供與數字等效甚至更好的功能,而且我們可以在較舊的節點上做到這一點。” “成本可以更低,因為我們不需要所有的數字功能,因此芯片尺寸可以更小。我們可以降低功耗,因為我們沒有那么多功能。”
當內存發生變化時,軟件堆棧中的所有內容都會受到影響。Synopsys產品營銷總監 Prasad Saggurti 說:“通常會發生一種算法,我們看到了一種優化它的方法,優化內存,以便更好地實現算法。” “另一方面,我們擁有這些不同類型的內存。你能改變你的算法來利用這些新的記憶嗎?過去,使用 TCAM 主要是一種網絡域結構來查找 IP 地址。最近,ML 訓練引擎開始使用 TCAM。這需要根據可用存儲器的類型來改變軟件或固件。”
CMOS 的終結
但到目前為止,最大的潛在變化是 CMOS 的終結。隨著器件變得更小,摻雜的控制變得具有挑戰性,這會導致器件閾值電壓的顯著變化。摻雜定義了器件的極性,例如器件是 PMOS 還是 NMOS,正是這些器件的配對創建了 CMOS 結構,這是創建的所有數字功能的基礎。隨著行業向全柵 finFET 結構遷移,出現了一種新的可能性。
“使用水平堆疊的納米線,您實際上可以構建具有兩個柵極的晶體管,”洛桑聯邦理工學院電氣工程和計算機科學教授 Giovanni De Micheli 在 DAC 2022 主題演講中說。“你使用第二個柵極來極化晶體管并使晶體管成為 P 或 N 晶體管(見圖 1)。你會得到一個更強大的晶體管,因為它創建了一個比較器而不是一個開關。現在,有了這些類型的設備,您就可以擁有全新的拓撲結構。”
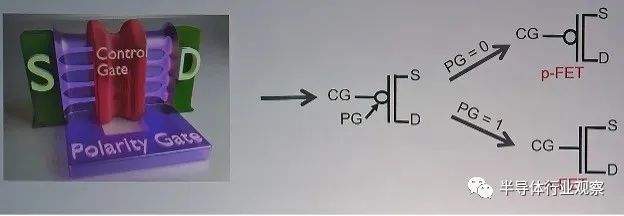
圖 1. GAA 極性門的 3-D 概念圖。
資料來源:Michele De Marchi 論文,EPFL,2015
理論上,這可以通過將極性門一分為二來進一步實現。除了是 p 型或 n 型之外,這將增加每個晶體管也成為高或低閾值電壓器件的能力。因此,每個晶體管在運行期間都可以具有不同的功率/性能特性。
讓我們回到邏輯抽象。“幾十年來,我們一直在用 NAND 和 NOR 設計數字電路,”De Micheli 說。“為什么?因為我們一開始就被洗腦了,因為在CMOS中那是最方便的實現。但是,如果您從多數邏輯的角度思考(見圖 2),您就會意識到這是進行加法和乘法運算的關鍵運算符。今天,我們為機器學習實現的所有電路,其中的主要部分就是進行加法或乘法運算。這就是為什么多數是極其重要的。此外,多數邏輯是超導體、光學技術、內存中的非易失性邏輯等許多技術的自然模型。”
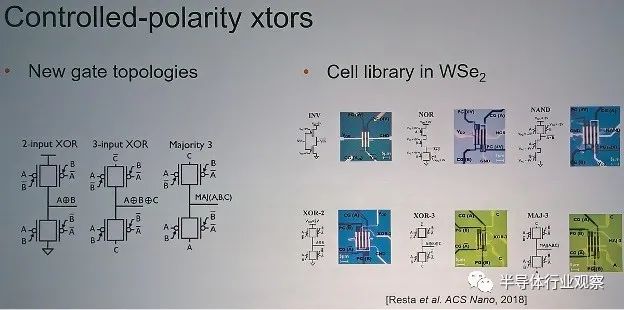
圖 2. 基于極性門器件的新邏輯元件。
資料來源:De Micheli/EPFL
De Micheli 的研究表明,采用多數邏輯設計的電路可以使用今天略微修改的 EDA 工具將延遲減少 15% 到 20%。
但這些類型的變化確實需要對綜合和其他步驟進行重大重新思考。Synopsys 的技術策略師 Rob Aitken 說:“如果這被證明是一個很有前途的載體,你真的需要徹底重新考慮合成引擎。” “許多新設備不會有效地采用 NAND/NOR 電路并從中構建東西,而是將本機調整為 XOR、多數門或其他一些邏輯功能。會發生什么?綜合關注您正在構建的基本事物,雖然它過于簡單化,但邏輯綜合需要一個 PLA,然后將其折疊成一個多層次的對象。以不同的邏輯風格重新思考很重要。”
改變基本的晶體管功能對流程的許多方面都有重大影響。例如,設備現在有四個或五個終端,而不是三個,這會對布局和布線產生什么影響?它將如何影響扇入扇出和擁塞?
結論
改變是困難的。一項有前途的技術必須克服現有技術數十年的優化,這會帶來巨大的慣性挑戰。它還可能需要同時更改解決方案的許多部分,例如硬件和軟件,或整個實現鏈中的工具。但隨著該行業接近半導體的一些基本物理極限,它需要變得更加靈活并愿意改變。
編輯:黃飛
-
CMOS
+關注
關注
58文章
5729瀏覽量
235798 -
晶體管
+關注
關注
77文章
9723瀏覽量
138620 -
機器學習
+關注
關注
66文章
8429瀏覽量
132854 -
reram
+關注
關注
1文章
51瀏覽量
25463
原文標題:學習分享 | 芯片架構師需要思考的一些問題
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
kintex產品架構設計文檔(成為架構師也是電子人不錯的選...
好的架構師為什么是出色的程序員
女性會更適合做架構師?
怎樣成為軟件架構師
開發工程師和架構師的區別
如何成為一個優秀的區塊鏈架構師
什么是 SoC 設計中的系統架構師?





 工商網監
工商網監
評論