") NVIDIA GPU加速潞晨科技Colossal-AI大模型開發(fā)進程
NVIDIA GPU加速潞晨科技Colossal-AI大模型開發(fā)進程
通過 NVIDIA GPU 加速平臺,Colossal-AI 實現(xiàn)了通過高效多維并行、異構(gòu)內(nèi)存管理、大規(guī)模優(yōu)化庫、自適應(yīng)任務(wù)調(diào)度等方式,更高效快速部署 AI 大模型訓(xùn)練與推理。
AI 大模型的高門檻成為研發(fā)一大難題
近年來,AI 模型已從 AlexNet、ResNet、AlphaGo 發(fā)展到 BERT、GPT、MoE…隨著深度學(xué)習(xí)的興起及大模型橫掃各大性能榜單,AI 能力不斷提升的一個顯著特征是模型參數(shù)的爆發(fā)式增長,這也使得訓(xùn)練模型的成本急劇上升。目前最大的 AI 模型智源悟道 2.0 參數(shù)量達到 1.75 萬億,前沿 AI 模型的大小在短短幾年內(nèi)便已增大萬倍,遠(yuǎn)超硬件數(shù)倍的緩慢增長,模型大小也遠(yuǎn)超單個 GPU 的容納能力。
由于單臺機器的能力已遠(yuǎn)遠(yuǎn)無法滿足日益增長的 AI 訓(xùn)練需求,即便是超級計算機,也面臨著當(dāng)硬件堆砌到達一定數(shù)量后,效率無法進一步提升的瓶頸,浪費了大量計算資源。而分布式并行也與單機情況差異巨大,通常需要計算機系統(tǒng)和體系結(jié)構(gòu)相關(guān)的專業(yè)人員,這進一步提高了訓(xùn)練和部署成本。
此外,PyTorch、TensorFlow 等現(xiàn)有深度學(xué)習(xí)框架也難以有效處理超大模型,通常需要專業(yè)的 AI 系統(tǒng)工程師針對具體模型做適配和優(yōu)化。更重要的是,不是每一個研發(fā)團隊都具備 “鈔” 能力,能夠隨時調(diào)用大規(guī)模 GPU 集群來使用大模型,更不用提僅有一張顯卡的個人開發(fā)者。因此,盡管大模型已經(jīng)吸引了大量關(guān)注,高昂的上手門檻卻令大眾 “望塵莫及”。
NVIDIA GPU 加速
潞晨科技 Colossal-AI 大模型開發(fā)進程
Colossal-AI 基于 NVIDIA GPU A30,為 AI 大模型的普適化做出了一系列貢獻:
1、提升 AI 大規(guī)模并行效率
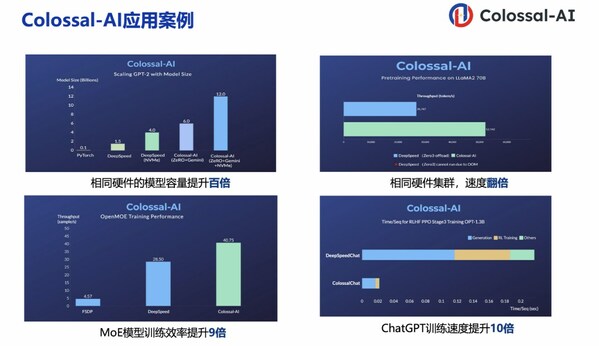
對于 GPT-3 等超大 AI 模型,僅需一半資源啟動訓(xùn)練,或通過高效并行加速,降低訓(xùn)練成本超百萬美元。在訓(xùn)練 ViT 模型時,可以擴大 14 倍的 batch size,加快 5 倍的訓(xùn)練速度;對于 GPT-2 模型,我們可以降低 11 倍的內(nèi)存消耗和超線性擴展,訓(xùn)練加速 3 倍,模型大小可擴展至 24 倍;對于 BERT 模型,可訓(xùn)練加速可達兩倍以上。
2、擴大硬件 AI 模型容量
在單個 GPU 上對于訓(xùn)練任務(wù),可提升模型容量十余倍,將 GPU 訓(xùn)練 GPT-2 和 PaLM 等前沿模型的參數(shù)容量提升數(shù)十倍。
3、豐富 AI 大模型行業(yè)落地
在產(chǎn)品發(fā)布的數(shù)個月內(nèi),潞晨科技已與數(shù)十家行業(yè)標(biāo)桿企業(yè)建立深度合作,客戶涵蓋中、美、英、新等全球市場,涉及云計算、芯片設(shè)計、生物醫(yī)藥、自動駕駛、智能零售等領(lǐng)域。例如,潞晨方案將 GPU 優(yōu)化和大規(guī)模并行技術(shù)引入 AlphaFold 的訓(xùn)練和推理,成功將 AlphaFold 總體訓(xùn)練時間從 11 天減少到 67 小時,且總成本更低,在長序列推理中也實現(xiàn) 9.3 ~ 11.6 倍提升。Colossal-AI 團隊還助力百圖生科開源全球最快的復(fù)合物結(jié)構(gòu)預(yù)測模型,可同時支持蛋白質(zhì)單體與復(fù)合物結(jié)構(gòu)預(yù)測,將原有推理速度提升約 11 倍。
目前,在 NVIDIA GPU 出色的 AI 加速性能加持下,Colossal-AI 已成功應(yīng)用在諸多領(lǐng)域,顯著縮短 AI 大模型開發(fā)和部署流程,降低 AI 大模型落地成本。
NVIDIA GPU 產(chǎn)品助力
潞晨科技 Colossal-AI 大模型落地與推廣
NVIDIA GPU 產(chǎn)品與 Colossal-AI 的合作,極大地提升了 AI 大模型的訓(xùn)練與推理流程,顯著提升了用戶體驗,為 AI 大模型的落地與推廣做出了重要貢獻。
借助 Colossal-AI 與 NVIDIA GPU 產(chǎn)品,對于企業(yè)用戶,可將現(xiàn)有項目便捷擴展到大規(guī)模計算集群,使用高效并行技術(shù),以低成本快速完成 AI 大模型的開發(fā)部署。對于計算資源有限的普通用戶,也能訓(xùn)練百億參數(shù)的大模型,相比現(xiàn)有主流方案,可提升參數(shù)容量十余倍,降低了 AI 大模型微調(diào)和推理等下游任務(wù)和應(yīng)用部署的門檻。
潞晨科技致力于將軟件系統(tǒng)設(shè)計與硬件架構(gòu)深度融合,實現(xiàn)一體化、智能化、自動化的人工智能計算服務(wù)。NVIDIA 初創(chuàng)加速計劃為我們提供了技術(shù)支持、市場宣傳、業(yè)務(wù)對接等一列的支持。潞晨科技也參加了 2022 NVIDIA 初創(chuàng)企業(yè)展示活動,并進入了最終展示,借此獲得了更多生態(tài)關(guān)注。
NVIDIA GPU 產(chǎn)品作為 Colossal-AI 算力基礎(chǔ),本次雙方的深化合作將促進潞晨科技與 NVIDIA 共同探索 GPU 如何更有效地應(yīng)用在訓(xùn)練和推理 AI 大模型中,為 GPU 硬件與 Colossal-AI 軟件系統(tǒng)的共同進步打下良好基礎(chǔ)。雙方將共同努力推動 AI 大模型的普世化進程,不斷解放和發(fā)展 AI 生產(chǎn)力。
——潞晨科技創(chuàng)始人尤洋博士
關(guān)于潞晨科技
潞晨科技主營業(yè)務(wù)包括分布式軟件系統(tǒng),大規(guī)模人工智能平臺和企業(yè)級云計算解決方案。公司旨在幫助企業(yè)最大化人工智能部署效率的同時最小化部署成本。其核心產(chǎn)品面向大模型時代的通用深度學(xué)習(xí)系統(tǒng) Colossal-AI,涵蓋高效多維自動并行、異構(gòu)內(nèi)存管理、大規(guī)模優(yōu)化庫、自適應(yīng)任務(wù)調(diào)度等自研技術(shù),可高效快速部署 AI 大模型訓(xùn)練和推理,兼容低端設(shè)備,顯著縮短 AI 大模型訓(xùn)練和推理時間、降低訓(xùn)練和推理成本,減少學(xué)習(xí)和部署的人力成本。
審核編輯:湯梓紅
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4989瀏覽量
103093 -
gpu
+關(guān)注
關(guān)注
28文章
4741瀏覽量
128963 -
AI
+關(guān)注
關(guān)注
87文章
30919瀏覽量
269170 -
大模型
+關(guān)注
關(guān)注
2文章
2459瀏覽量
2734
原文標(biāo)題:NVIDIA GPU加速AI落地,潞晨科技Colossal-AI助力大模型普適化
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
GPU是如何訓(xùn)練AI大模型的
《CST Studio Suite 2024 GPU加速計算指南》
NVIDIA推出全新生成式AI模型Fugatto
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
PyTorch GPU 加速訓(xùn)練模型方法
NVIDIA CorrDiff生成式AI模型能夠精準(zhǔn)預(yù)測臺風(fēng)
NVIDIA RTX AI套件簡化AI驅(qū)動的應(yīng)用開發(fā)
揭秘NVIDIA AI Workbench 如何助力應(yīng)用開發(fā)
HPE 攜手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 變革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 變革
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
軟銀追加1500億日元,加速AI大模型開發(fā)進程
NVIDIA在加速識因智能AI大模型落地應(yīng)用方面的重要作用介紹
潞晨科技Colossal-AI與浪潮信息AIStation完成兼容性互認(rèn)證
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型開發(fā)效率提升10倍





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論