") 為大家介紹促進存算一體芯片快速發(fā)展的各類原因
為大家介紹促進存算一體芯片快速發(fā)展的各類原因
作為后摩爾時代突破芯片性能瓶頸的主流技術方向之一,存算一體正在被更多人關注和認可。
存算一體直接將數據存儲單元和計算單元融合為一體,能夠大幅減少數據搬運帶來的功耗損失,同時,也減少了等待數據讀取時的算力浪費,極大提高了計算并行度和能效。這一架構設計直接打破“存儲墻”和“功耗墻”,可以從根本上解決馮·諾伊曼的架構瓶頸。
存算一體的概念并不難理解,這一設計思路的出現甚至可以追溯到20 世紀 60 年代。但直至最近幾年,存算一體才真正從概念走向產品。此前,為什么存算一體沒有被業(yè)內廣泛應用?
Q?
存算一體為什么之前沒有被廣泛應用?
實際上,“存算一體”并非橫空出世的新鮮事物,設計人員很早就有了存算一體的設計思路,從上世紀70年代就一直持續(xù)有相關的研究工作在發(fā)表。
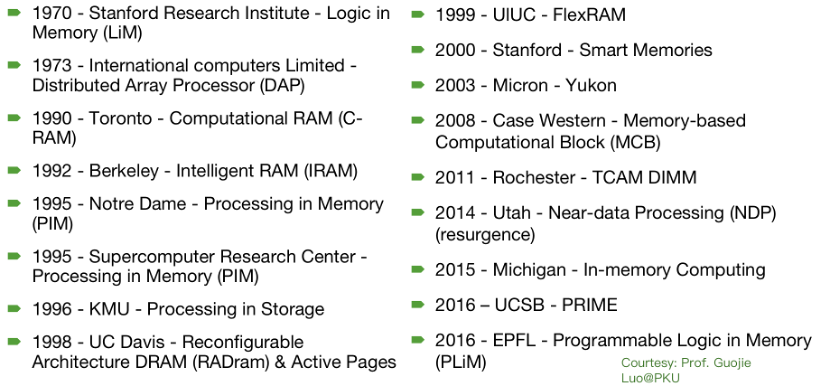
圖1. 相關文獻整理
但是,這方面工作一直不溫不火,直到2012年后又逐漸受到學術界和工業(yè)界的重視,主要原因可以概括為幾個方面:
1)處理器計算吞吐和內存帶寬差距增大。早期處理器的計算吞吐和內存帶寬的差距并不明顯,但是隨著 CMOS 工藝的快速發(fā)展、以及多核/眾核處理器架構成為主流,處理器的計算吞吐能力增長的速度遠超內存帶寬的增長速度。因此,存儲墻的問題愈發(fā)嚴重;
2)應用訪存數據量增大、數據局部性變差。傳統(tǒng)的處理器設計通過增加多級的片上緩存(cache)來緩解內存帶寬不足的問題,但是由于深度學習、圖計算、推薦系統(tǒng)等大數據應用的訪存數據量愈來愈大、數據局部性變差,導致處理器的緩存架構難以發(fā)揮作用;
3)新興應用包含大量、可并行的、乘累加計算。以深度學習應用為例,主流模型80%以上的計算都是可并行的乘累加(MAC)操作,面向這類“簡單”的操作,使得計算單元和存儲單元的深度融合(即CIM),無論以數字還是模擬方式都變得可行;
4)STT-MRAM、RRAM 等新型存儲器的發(fā)展。一方面,新型存儲器有潛力提升片上存儲的密度,從而緩解存儲墻的問題。另一方面,這類新型存儲器為 MAC 計算單元和存儲單元的融合提供了新的機遇;
5)領域定制計算架構的興起。最后值得一提的是,隨著摩爾定律的放緩,領域定制計算架構的優(yōu)勢愈發(fā)明顯,而存算一體正是一種適合AI、圖計算、推薦系統(tǒng)等領域的定制計算架構。
未來將是存算一體應用的爆發(fā)期,將會被廣泛應用。但是我們也認為存算一體架構并不會全面取代現有架構的 AI 芯片(如GPU等),而是會長期共存,不同的架構有各自更加擅長的場景,多樣化架構的并存,甚至異構結合、優(yōu)勢互補,才是更加更合理的情形。選擇架構需要綜合考慮應用場景、模型數量/功能/大小、存儲工藝、集成方式、計算精度等多方面因素,具體分析可以參考前述幾問的闡述。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19387瀏覽量
230544 -
CMOS
+關注
關注
58文章
5729瀏覽量
235798 -
存儲器
+關注
關注
38文章
7522瀏覽量
164102 -
CIM
+關注
關注
1文章
87瀏覽量
14920
原文標題:存算十問|(六)存算一體為什么之前沒有被廣泛應用?
文章出處:【微信號:后摩智能,微信公眾號:后摩智能】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
存算于芯 · 智啟未來 — 2024蘋芯科技產品發(fā)布會盛大召開

開源芯片系列講座第24期:基于SRAM存算的高效計算架構

直播預約 |開源芯片系列講座第24期:SRAM存算一體:賦能高能效RISC-V計算
存算一體化與邊緣計算:重新定義智能計算的未來

存算一體架構創(chuàng)新助力國產大算力AI芯片騰飛
科技新突破:首款支持多模態(tài)存算一體AI芯片成功問世

后摩智能首款存算一體智駕芯片獲評突出創(chuàng)新產品獎
蘋芯科技引領存算一體技術革新 PIMCHIP系列芯片重塑AI計算新格局

存算一體AI芯片企業(yè)后摩智能完成數億元戰(zhàn)略融資
后摩智能推出邊端大模型AI芯片M30,展現出存算一體架構優(yōu)勢
一體成型合金電感在電路中燒壞的原因分析
知存科技助力AI應用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究

知存科技攜手北大共建存算一體化技術實驗室,推動AI創(chuàng)新
北京大學-知存科技存算一體聯(lián)合實驗室揭牌,開啟知存科技產學研融合戰(zhàn)略新升級






 工商網監(jiān)
工商網監(jiān)
評論