") groupby功能的大多數(shù)用例
groupby功能的大多數(shù)用例
groupby是Pandas在數(shù)據(jù)分析中最常用的函數(shù)之一。它用于根據(jù)給定列中的不同值對(duì)數(shù)據(jù)點(diǎn)(即行)進(jìn)行分組,分組后的數(shù)據(jù)可以計(jì)算生成組的聚合值。 如果我們有一個(gè)包含汽車品牌和價(jià)格信息的數(shù)據(jù)集,那么可以使用groupby功能來計(jì)算每個(gè)品牌的平均價(jià)格。 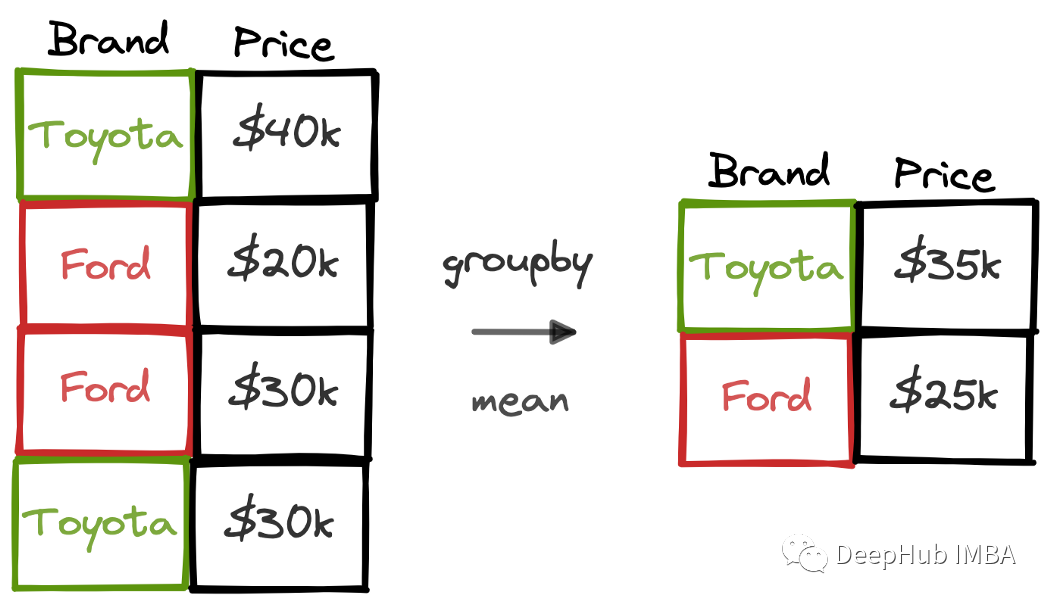 在本文中,我們將使用25個(gè)示例來詳細(xì)介紹groupby函數(shù)的用法。這25個(gè)示例中還包含了一些不太常用但在各種任務(wù)中都能派上用場(chǎng)的操作。 這里使用的數(shù)據(jù)集是隨機(jī)生成的,我們把它當(dāng)作一個(gè)銷售的數(shù)據(jù)集。
在本文中,我們將使用25個(gè)示例來詳細(xì)介紹groupby函數(shù)的用法。這25個(gè)示例中還包含了一些不太常用但在各種任務(wù)中都能派上用場(chǎng)的操作。 這里使用的數(shù)據(jù)集是隨機(jī)生成的,我們把它當(dāng)作一個(gè)銷售的數(shù)據(jù)集。
importpandasaspd sales=pd.read_csv("sales_data.csv") sales.head()
 1、單列聚合 我們可以計(jì)算出每個(gè)店鋪的平均庫存數(shù)量如下:
1、單列聚合 我們可以計(jì)算出每個(gè)店鋪的平均庫存數(shù)量如下:
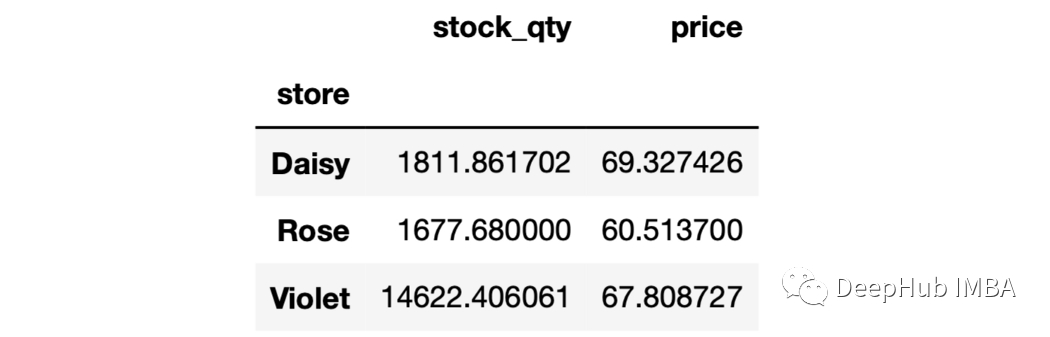
sales.groupby("store")["stock_qty"].mean()
#輸出
store
Daisy1811.861702
Rose1677.680000
Violet14622.406061
Name:stock_qty,dtype:float64
2、多列聚合
在一個(gè)操作中進(jìn)行多個(gè)聚合。以下是我們?nèi)绾斡?jì)算每個(gè)商店的平均庫存數(shù)量和價(jià)格。
sales.groupby("store")[["stock_qty","price"]].mean()sales.groupby("store")[["stock_qty","price"]].mean()
 3、多列多個(gè)聚合 我們還可以使用agg函數(shù)來計(jì)算多個(gè)聚合值。
3、多列多個(gè)聚合 我們還可以使用agg函數(shù)來計(jì)算多個(gè)聚合值。
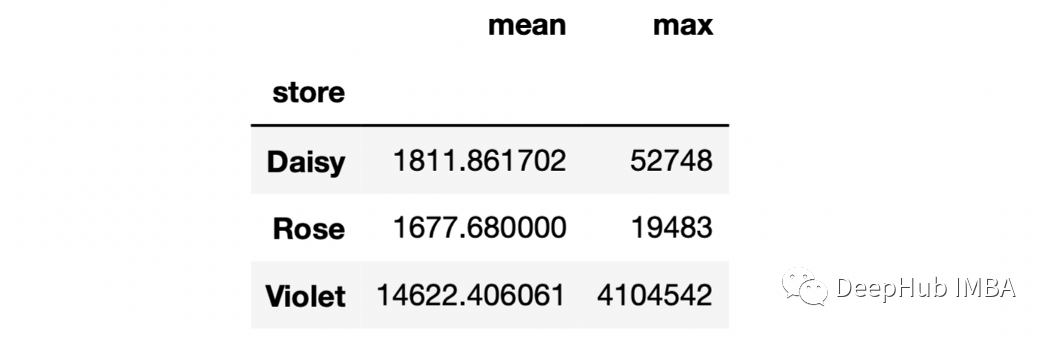
sales.groupby("store")["stock_qty"].agg(["mean","max"])
 4、對(duì)聚合結(jié)果進(jìn)行命名 在前面的兩個(gè)示例中,聚合列表示什么還不清楚。例如,“mean”并沒有告訴我們它是什么的均值。在這種情況下,我們可以對(duì)聚合的結(jié)果進(jìn)行命名。
4、對(duì)聚合結(jié)果進(jìn)行命名 在前面的兩個(gè)示例中,聚合列表示什么還不清楚。例如,“mean”并沒有告訴我們它是什么的均值。在這種情況下,我們可以對(duì)聚合的結(jié)果進(jìn)行命名。
sales.groupby("store").agg(
avg_stock_qty=("stock_qty","mean"),
max_stock_qty=("stock_qty","max")
)
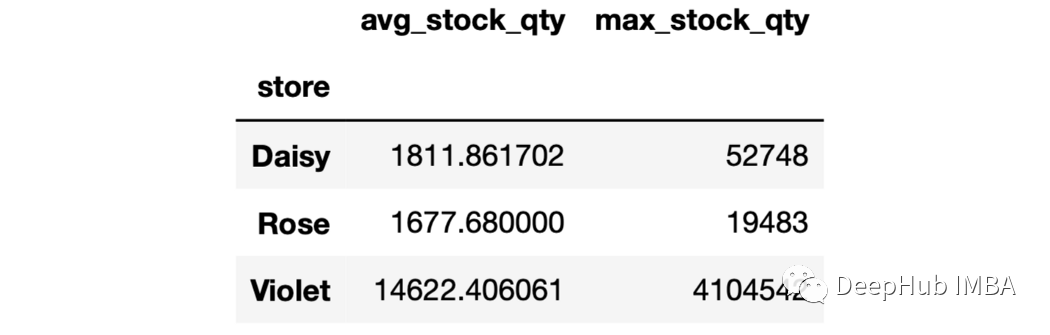 要聚合的列和函數(shù)名需要寫在元組中。 5、多個(gè)聚合和多個(gè)函數(shù)
要聚合的列和函數(shù)名需要寫在元組中。 5、多個(gè)聚合和多個(gè)函數(shù)
sales.groupby("store")[["stock_qty","price"]].agg(["mean","max"])
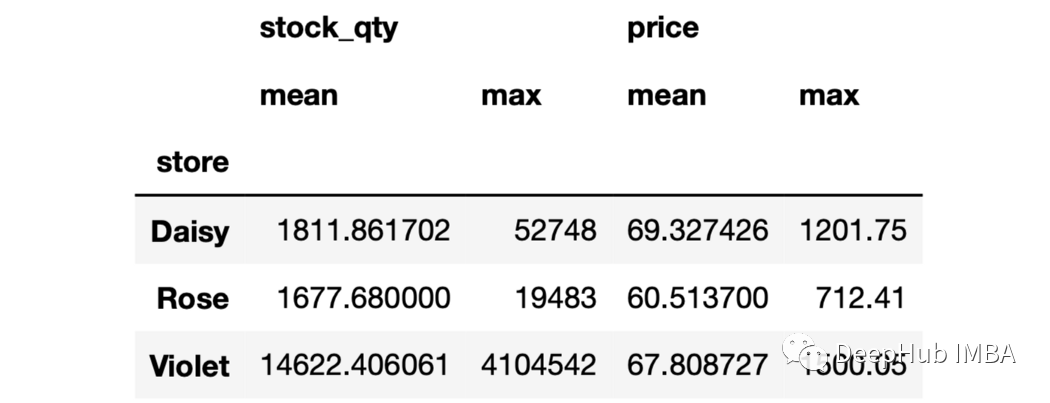
6、對(duì)不同列的聚合進(jìn)行命名
sales.groupby("store").agg(
avg_stock_qty=("stock_qty","mean"),
avg_price=("price","mean")
)
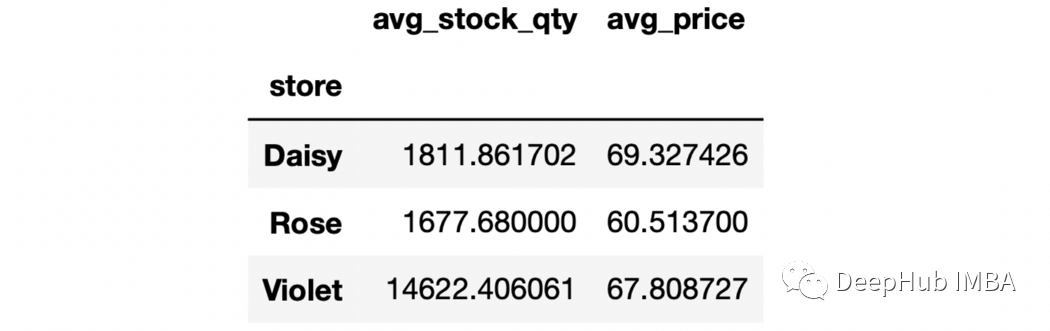 7、as_index參數(shù) 如果groupby操作的輸出是DataFrame,可以使用as_index參數(shù)使它們成為DataFrame中的一列。
7、as_index參數(shù) 如果groupby操作的輸出是DataFrame,可以使用as_index參數(shù)使它們成為DataFrame中的一列。
sales.groupby("store",as_index=False).agg(
avg_stock_qty=("stock_qty","mean"),
avg_price=("price","mean")
)
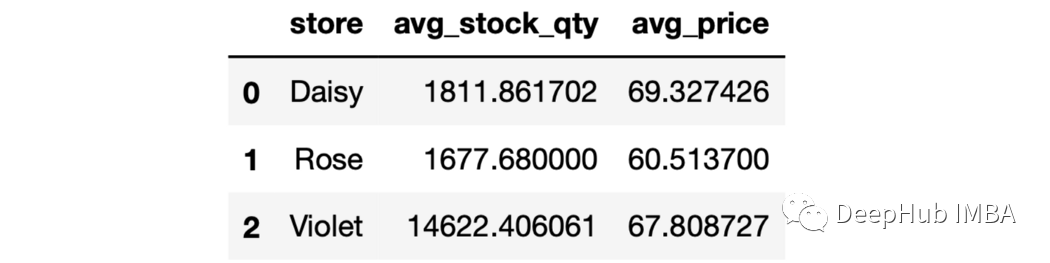 8、用于分組的多列 就像我們可以聚合多個(gè)列一樣,我們也可以使用多個(gè)列進(jìn)行分組。
8、用于分組的多列 就像我們可以聚合多個(gè)列一樣,我們也可以使用多個(gè)列進(jìn)行分組。
sales.groupby(["store","product_group"],as_index=False).agg(
avg_sales=("last_week_sales","mean")
).head()
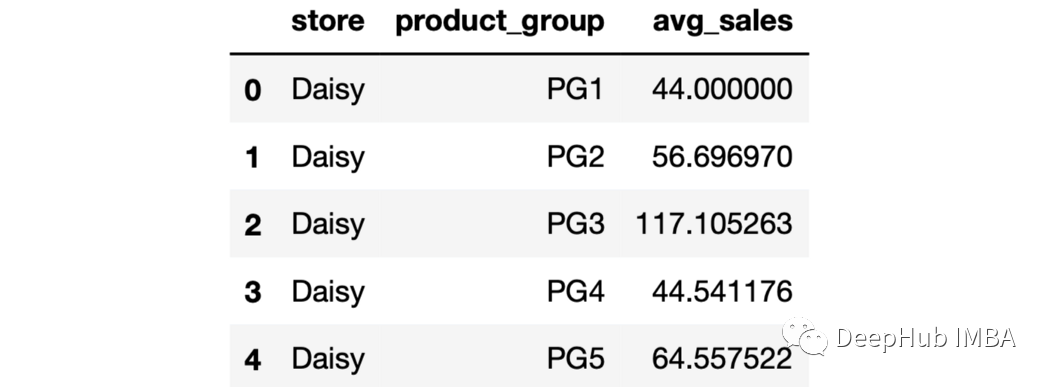 每個(gè)商店和產(chǎn)品的組合都會(huì)生成一個(gè)組。 9、排序輸出 可以使用sort_values函數(shù)根據(jù)聚合列對(duì)輸出進(jìn)行排序。
每個(gè)商店和產(chǎn)品的組合都會(huì)生成一個(gè)組。 9、排序輸出 可以使用sort_values函數(shù)根據(jù)聚合列對(duì)輸出進(jìn)行排序。
sales.groupby(["store","product_group"],as_index=False).agg(avg_sales=("last_week_sales","mean")
).sort_values(by="avg_sales",ascending=False).head()
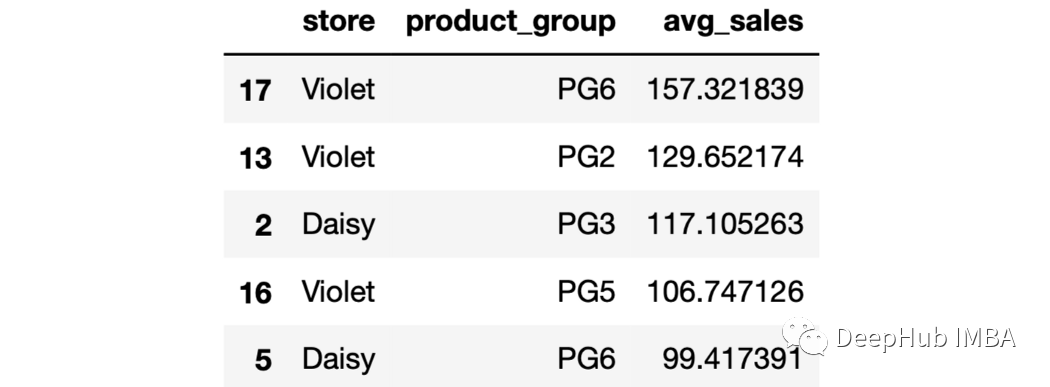 這些行根據(jù)平均銷售值按降序排序。 10、最大的Top N max函數(shù)返回每個(gè)組的最大值。如果我們需要n個(gè)最大的值,可以用下面的方法:
這些行根據(jù)平均銷售值按降序排序。 10、最大的Top N max函數(shù)返回每個(gè)組的最大值。如果我們需要n個(gè)最大的值,可以用下面的方法:
sales.groupby("store")["last_week_sales"].nlargest(2)
store
Daisy4131883
231947
Rose948883
263623
Violet9913222
3392690
Name:last_week_sales,dtype:int64
11、最小的Top N
與最大值相似,也可以求最小值
sales.groupby("store")["last_week_sales"].nsmallest(2)
12、第n個(gè)值
除上面2個(gè)以外,還可以找到一組中的第n個(gè)值。
sales_sorted=sales.sort_values(by=["store","last_month_sales"],ascending=False,ignore_index=True)
找到每個(gè)店鋪上個(gè)月銷售排名第五的產(chǎn)品如下:
sales_sorted.groupby("store").nth(4)
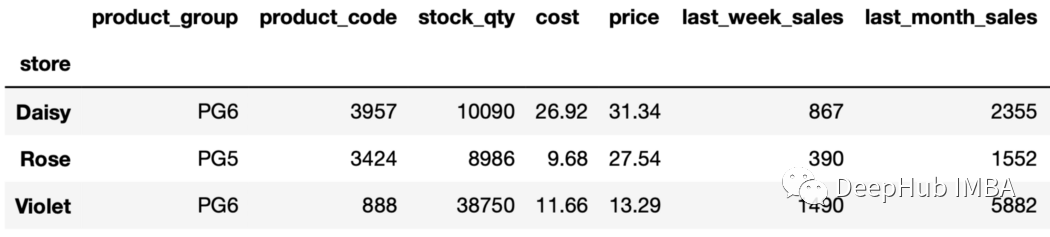 輸出包含每個(gè)組的第5行。由于行是根據(jù)上個(gè)月的銷售值排序的,所以我們將獲得上個(gè)月銷售額排名第五的行。 13、第n個(gè)值,倒排序 也可以用負(fù)的第n項(xiàng)。例如," nth(-2) "返回從末尾開始的第二行。
輸出包含每個(gè)組的第5行。由于行是根據(jù)上個(gè)月的銷售值排序的,所以我們將獲得上個(gè)月銷售額排名第五的行。 13、第n個(gè)值,倒排序 也可以用負(fù)的第n項(xiàng)。例如," nth(-2) "返回從末尾開始的第二行。
sales_sorted.groupby("store").nth(-2)
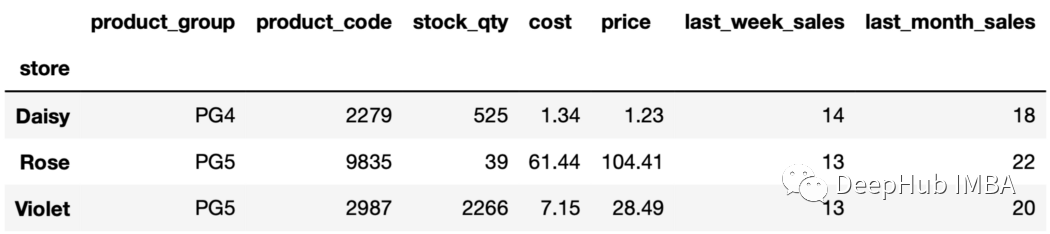 14、唯一值 unique函數(shù)可用于查找每組中唯一的值。例如,可以找到每個(gè)組中唯一的產(chǎn)品代碼如下:
14、唯一值 unique函數(shù)可用于查找每組中唯一的值。例如,可以找到每個(gè)組中唯一的產(chǎn)品代碼如下:
sales.groupby("store",as_index=False).agg(
unique_values=("product_code","unique")
)
 15、唯一值的數(shù)量 還可以使用nunique函數(shù)找到每組中唯一值的數(shù)量。
15、唯一值的數(shù)量 還可以使用nunique函數(shù)找到每組中唯一值的數(shù)量。
sales.groupby("store",as_index=False).agg(
number_of_unique_values=("product_code","nunique")
)
 16、Lambda表達(dá)式 可以在agg函數(shù)中使用lambda表達(dá)式作為自定義聚合操作。
16、Lambda表達(dá)式 可以在agg函數(shù)中使用lambda表達(dá)式作為自定義聚合操作。
sales.groupby("store").agg(
total_sales_in_thousands=(
"last_month_sales",
lambdax:round(x.sum()/1000,1)
)
)
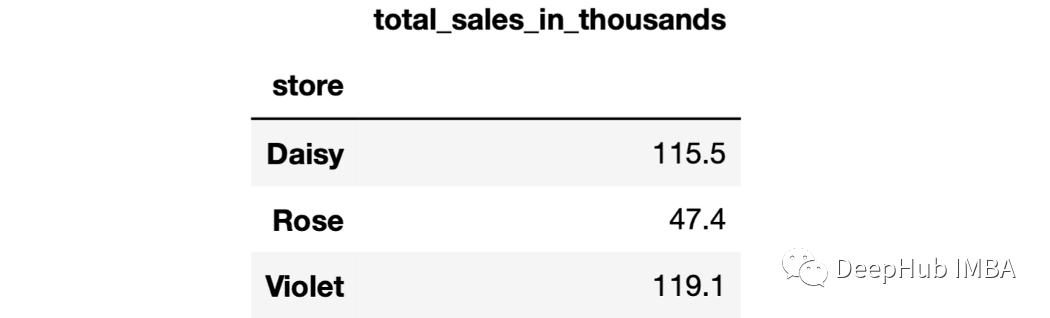 17、apply函數(shù) 使用apply函數(shù)將Lambda表達(dá)式應(yīng)用到每個(gè)組。例如,我們可以計(jì)算每家店上周銷售額與上個(gè)月四分之一銷售額的差值的平均值,如下:
17、apply函數(shù) 使用apply函數(shù)將Lambda表達(dá)式應(yīng)用到每個(gè)組。例如,我們可以計(jì)算每家店上周銷售額與上個(gè)月四分之一銷售額的差值的平均值,如下:
sales.groupby("store").apply(
lambdax:(x.last_week_sales-x.last_month_sales/4).mean()
)
store
Daisy5.094149
Rose5.326250
Violet8.965152
dtype:float64
18、dropna
缺省情況下,groupby函數(shù)忽略缺失值。如果用于分組的列中缺少一個(gè)值,那么它將不包含在任何組中,也不會(huì)單獨(dú)顯示。所以可以使用dropna參數(shù)來改變這個(gè)行為。 讓我們首先添加一個(gè)缺少存儲(chǔ)值的新行。
sales.loc[1000]=[None,"PG2",10000,120,64,96,15,53]
然后計(jì)算帶有dropna參數(shù)和不帶有dropna參數(shù)的每個(gè)商店的平均價(jià)格,以查看差異。
sales.groupby("store")["price"].mean()
store
Daisy69.327426
Rose60.513700
Violet67.808727
Name:price,dtype:float64
看看設(shè)置了缺失值參數(shù)的結(jié)果:
sales.groupby("store",dropna=False)["price"].mean()
store
Daisy69.327426
Rose60.513700
Violet67.808727
NaN96.000000
Name:price,dtype:float64
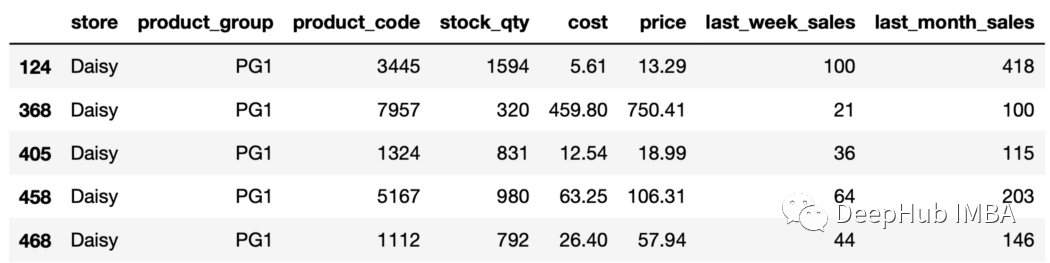
groupby函數(shù)的dropna參數(shù),使用pandas版本1.1.0或更高版本。 19、求組的個(gè)數(shù) 有時(shí)需要知道生成了多少組,這可以使用ngroups。
sales.groupby(["store","product_group"]).ngroups 18在商店和產(chǎn)品組列中有18種不同值的不同組合。 20、獲得一個(gè)特定分組 get_group函數(shù)可獲取特定組并且返回DataFrame。 例如,我們可以獲得屬于存儲(chǔ)“Daisy”和產(chǎn)品組“PG1”的行如下:
aisy_pg1=sales.groupby( ["store","product_group"]).get_group(("Daisy","PG1") ) daisy_pg1.head()
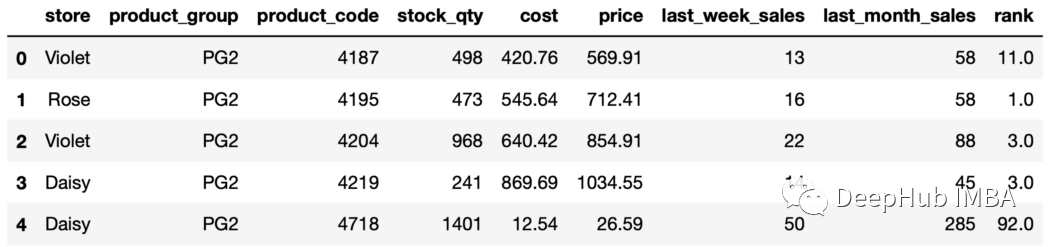
 21、rank函數(shù) rank函數(shù)用于根據(jù)給定列中的值為行分配秩。我們可以使用rank和groupby函數(shù)分別對(duì)每個(gè)組中的行進(jìn)行排序。
21、rank函數(shù) rank函數(shù)用于根據(jù)給定列中的值為行分配秩。我們可以使用rank和groupby函數(shù)分別對(duì)每個(gè)組中的行進(jìn)行排序。
sales["rank"]=sales.groupby("store"["price"].rank(
ascending=False,method="dense"
)
sales.head()
 22、累計(jì)操作 們可以計(jì)算出每組的累計(jì)總和。
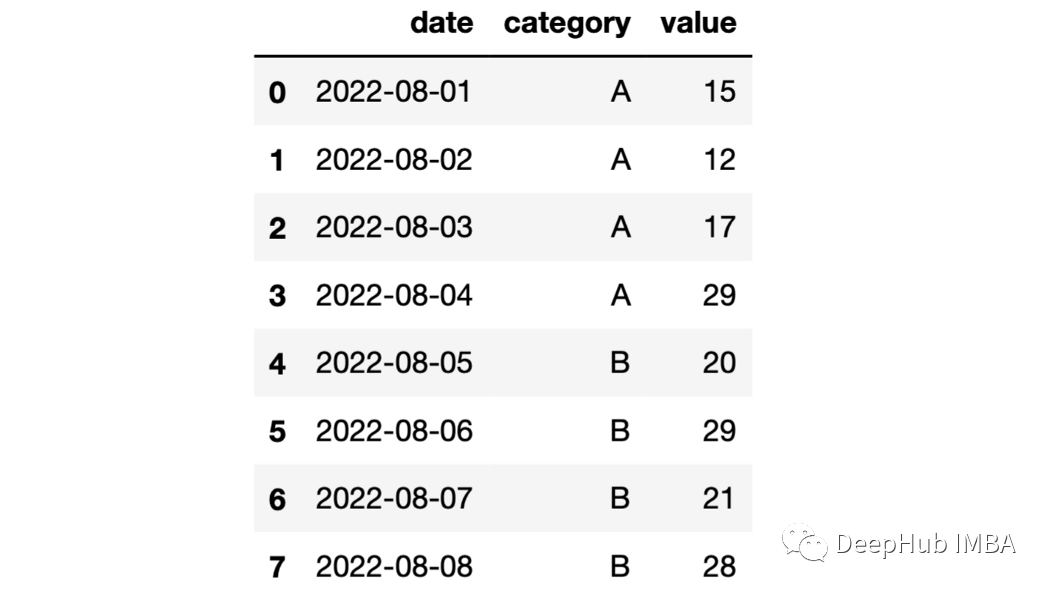
22、累計(jì)操作 們可以計(jì)算出每組的累計(jì)總和。
importnumpyasnpdf=pd.DataFrame(
{
"date":pd.date_range(start="2022-08-01",periods=8,freq="D"),
"category":list("AAAABBBB"),
"value":np.random.randint(10,30,size=8)
}
)
 我們可以單獨(dú)創(chuàng)建一個(gè)列,包含值列的累計(jì)總和,如下所示:
我們可以單獨(dú)創(chuàng)建一個(gè)列,包含值列的累計(jì)總和,如下所示:
df["cum_sum"]=df.groupby("category")["value"].cumsum()
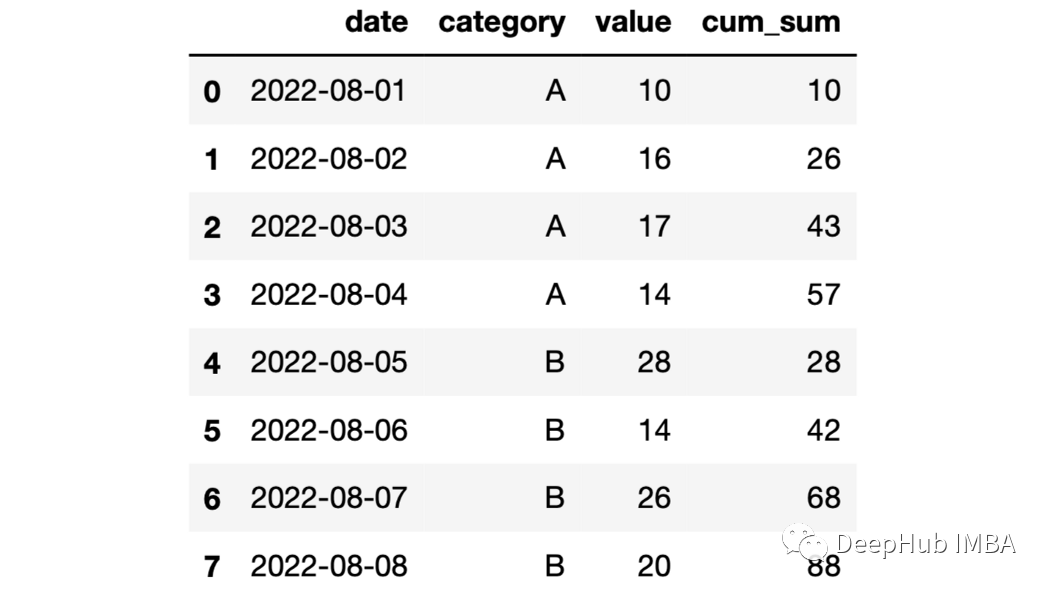 23、expanding函數(shù) expanding函數(shù)提供展開轉(zhuǎn)換。但是對(duì)于展開以后的操作還是需要一個(gè)累計(jì)函數(shù)來堆區(qū)操作。例如它與cumsum 函數(shù)一起使用,結(jié)果將與與sum函數(shù)相同。
23、expanding函數(shù) expanding函數(shù)提供展開轉(zhuǎn)換。但是對(duì)于展開以后的操作還是需要一個(gè)累計(jì)函數(shù)來堆區(qū)操作。例如它與cumsum 函數(shù)一起使用,結(jié)果將與與sum函數(shù)相同。
df["cum_sum_2"]=df.groupby( "category" )["value"].expanding().sum().values
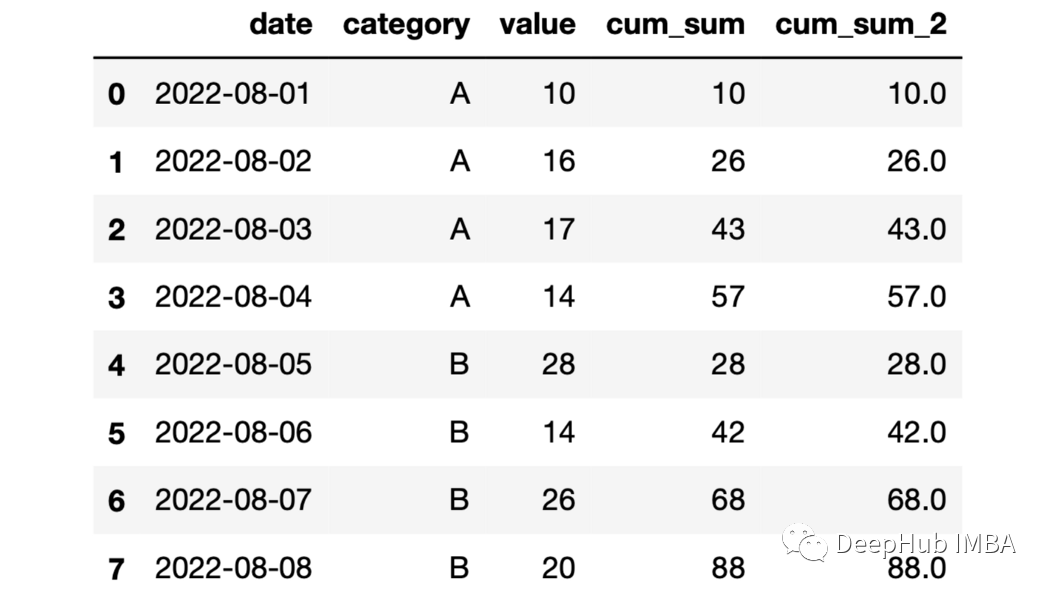 24、累積平均 利用展開函數(shù)和均值函數(shù)計(jì)算累積平均。
24、累積平均 利用展開函數(shù)和均值函數(shù)計(jì)算累積平均。
df["cum_mean"]=df.groupby( "category" )["value"].expanding().mean().values
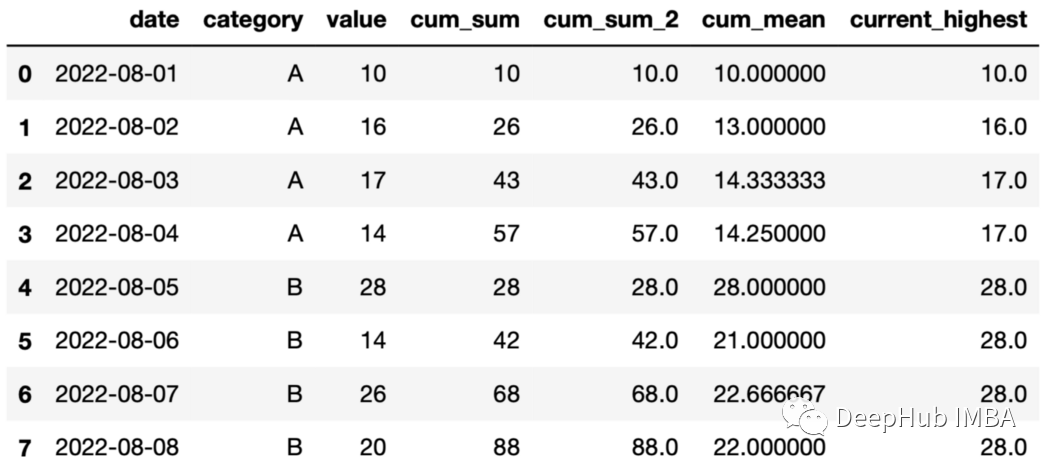
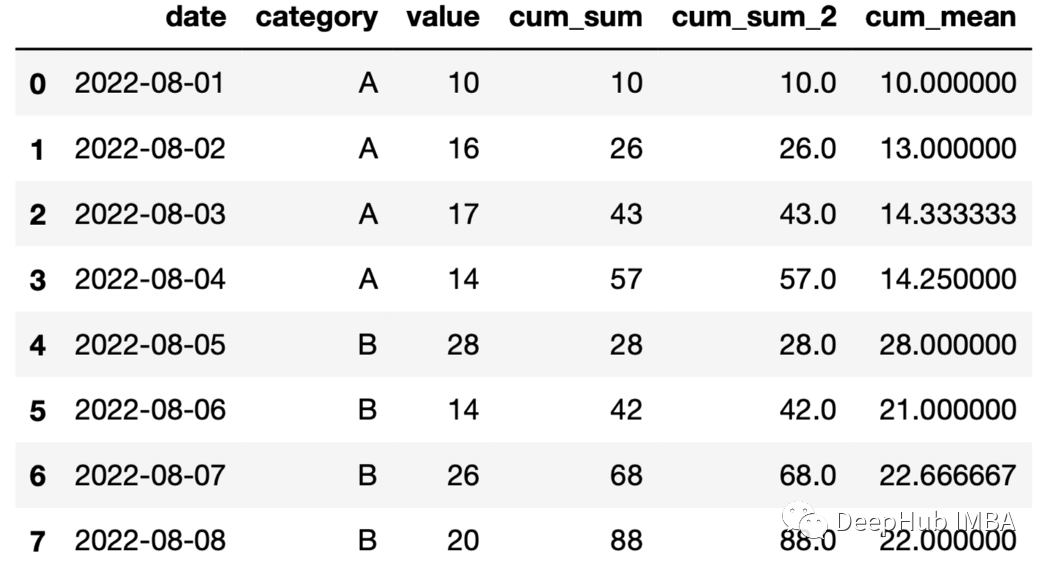 25、展開后的最大值 可以使用expand和max函數(shù)記錄組當(dāng)前最大值。
25、展開后的最大值 可以使用expand和max函數(shù)記錄組當(dāng)前最大值。
df["current_highest"]=df.groupby( "category" )["value"].expanding().max().values
 在Pandas中g(shù)roupby函數(shù)與aggregate函數(shù)共同構(gòu)成了高效的數(shù)據(jù)分析工具。在本文中所做的示例涵蓋了groupby功能的大多數(shù)用例,希望對(duì)你有所幫助。
在Pandas中g(shù)roupby函數(shù)與aggregate函數(shù)共同構(gòu)成了高效的數(shù)據(jù)分析工具。在本文中所做的示例涵蓋了groupby功能的大多數(shù)用例,希望對(duì)你有所幫助。-
函數(shù)
+關(guān)注
關(guān)注
3文章
4332瀏覽量
62677 -
數(shù)據(jù)分析
+關(guān)注
關(guān)注
2文章
1451瀏覽量
34066 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24716
原文標(biāo)題:25 個(gè)例子學(xué)會(huì) Pandas Groupby 操作!
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
為什么圖騰柱電路大多數(shù)用三極管來實(shí)現(xiàn)的呢
為什么現(xiàn)在大多數(shù)四軸飛行器都采用的是X型布局
技術(shù)支持工程師面試試題大多數(shù)是什么
如何解決大多數(shù)電源完整性問題
大多數(shù)為單指令周期
大多數(shù)用戶并不習(xí)慣在智能音箱上收聽新聞
為什么大多數(shù)加密貨幣沒有存在的必要
大多數(shù)加密數(shù)字貨幣都存在什么問題
大多數(shù)企業(yè)擔(dān)憂5G技術(shù)帶來的網(wǎng)絡(luò)安全風(fēng)險(xiǎn)
ADISUSB驅(qū)動(dòng)程序文件(大多數(shù)情況下不需要)

滿足大多數(shù)倒計(jì)時(shí)控件的視圖教程
為何大多數(shù)PLC采用ARM架構(gòu)CPU
大多數(shù)人5G隨身WiFi用戶被商家引導(dǎo),如何避免“劣質(zhì)”隨身WiFi?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論