") 深度學(xué)習(xí)——如何用LSTM進(jìn)行文本分類
深度學(xué)習(xí)——如何用LSTM進(jìn)行文本分類
簡介
主要內(nèi)容包括
如何將文本處理為Tensorflow LSTM的輸入
如何定義LSTM
用訓(xùn)練好的LSTM進(jìn)行文本分類
代碼
導(dǎo)入相關(guān)庫
#coding=utf-8
importtensorflowastf
fromtensorflow.contribimportlearn
importnumpyasnp
fromtensorflow.python.ops.rnnimportstatic_rnn
fromtensorflow.python.ops.rnn_cell_implimportBasicLSTMCell
數(shù)據(jù)
# 數(shù)據(jù)
positive_texts=[
"我 今天 很 高興",
"我 很 開心",
"他 很 高興",
"他 很 開心"
]
negative_texts=[
"我 不 高興",
"我 不 開心",
"他 今天 不 高興",
"他 不 開心"
]
label_name_dict={
0:"正面情感",
1:"負(fù)面情感"
}
配置信息
配置信息
embedding_size=50
num_classes=2
將文本和label數(shù)值化
# 將文本和label數(shù)值化
all_texts=positive_texts+negative_textslabels=[0]*len(positive_texts)+[1]*len(negative_texts)
max_document_length=4
vocab_processor=learn.preprocessing.VocabularyProcessor(max_document_length)
datas=np.array(list(vocab_processor.fit_transform(all_texts)))
vocab_size=len(vocab_processor.vocabulary_)
定義placeholder(容器),存放輸入輸出
# 容器,存放輸入輸出
datas_placeholder=tf.placeholder(tf.int32, [None, max_document_length])
labels_placeholder=tf.placeholder(tf.int32, [None])
詞向量處理
# 詞向量表
embeddings=tf.get_variable("embeddings", [vocab_size, embedding_size],initializer=tf.truncated_normal_initializer)
# 將詞索引號轉(zhuǎn)換為詞向量[None, max_document_length] => [None, max_document_length, embedding_size]
embedded=tf.nn.embedding_lookup(embeddings, datas_placeholder)
將數(shù)據(jù)處理為LSTM的輸入格式
# 轉(zhuǎn)換為LSTM的輸入格式,要求是數(shù)組,數(shù)組的每個元素代表某個時間戳一個Batch的數(shù)據(jù)
rnn_input=tf.unstack(embedded, max_document_length,axis=1)
定義LSTM
# 定義LSTM
lstm_cell=BasicLSTMCell(20,forget_bias=1.0)
rnn_outputs, rnn_states=static_rnn(lstm_cell, rnn_input,dtype=tf.float32)
#利用LSTM最后的輸出進(jìn)行預(yù)測
logits=tf.layers.dense(rnn_outputs[-1], num_classes)
predicted_labels=tf.argmax(logits,axis=1)
定義損失和優(yōu)化器
# 定義損失和優(yōu)化器
losses=tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(labels_placeholder, num_classes),
logits=logits
)
mean_loss=tf.reduce_mean(losses)
optimizer=tf.train.AdamOptimizer(learning_rate=1e-2).minimize(mean_loss)
執(zhí)行
withtf.Session()assess:
# 初始化變量
sess.run(tf.global_variables_initializer())
訓(xùn)練# 定義要填充的數(shù)據(jù)
feed_dict={
datas_placeholder: datas,
labels_placeholder: labels
}
print("開始訓(xùn)練")
forstepinrange(100):
_, mean_loss_val=sess.run([optimizer, mean_loss],feed_dict=feed_dict)
ifstep%10==0:
print("step ={}tmean loss ={}".format(step, mean_loss_val))
預(yù)測
print("訓(xùn)練結(jié)束,進(jìn)行預(yù)測")
predicted_labels_val=sess.run(predicted_labels,feed_dict=feed_dict)
fori, textinenumerate(all_texts):
label=predicted_labels_val[i]
label_name=label_name_dict[label]
print("{}=>{}".format(text, label_name))
審核編輯 黃昊宇
-
LSTM
+關(guān)注
關(guān)注
0文章
59瀏覽量
3767
發(fā)布評論請先 登錄
相關(guān)推薦
pyhanlp文本分類與情感分析
NLPIR平臺在文本分類方面的技術(shù)解析
基于apiori算法改進(jìn)的knn文本分類方法
運(yùn)用多種機(jī)器學(xué)習(xí)方法比較短文本分類處理過程與結(jié)果差別
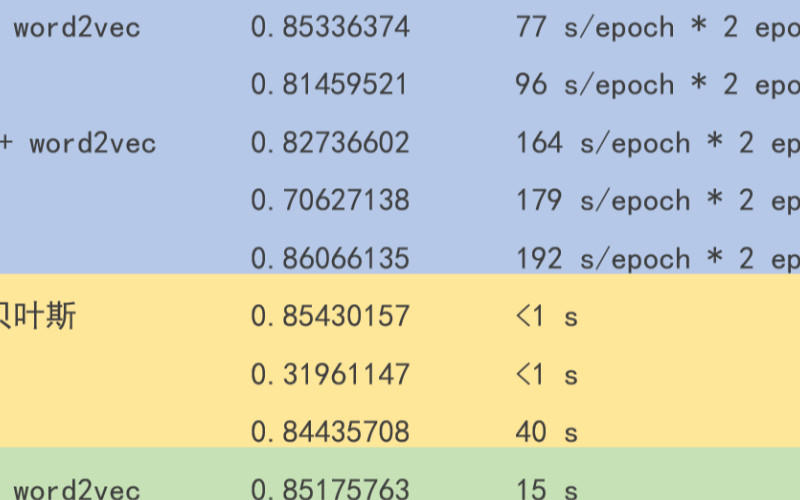
textCNN論文與原理——短文本分類
文本分類的一個大型“真香現(xiàn)場”來了
基于深度神經(jīng)網(wǎng)絡(luò)的文本分類分析

集成WL-CNN和SL-Bi-LSTM的旅游問句文本分類算法

融合文本分類和摘要的多任務(wù)學(xué)習(xí)摘要模型

基于雙通道詞向量的卷積膠囊網(wǎng)絡(luò)文本分類算法
基于LSTM的表示學(xué)習(xí)-文本分類模型
PyTorch文本分類任務(wù)的基本流程
NLP中的遷移學(xué)習(xí):利用預(yù)訓(xùn)練模型進(jìn)行文本分類
卷積神經(jīng)網(wǎng)絡(luò)在文本分類領(lǐng)域的應(yīng)用
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論