 基于graph-relational domains的自適應問題
基于graph-relational domains的自適應問題
現有深度學習模型都不具有普適性,即在某個數據集上訓練的結果只能在某個領域中有效,而很難遷移到其他的場景中,因此出現了遷移學習這一領域。其目標就是將原數據域(源域,source domain)盡可能好的遷移到目標域(target domain),Domain Adaptation任務中往往源域和目標域屬于同一類任務,即源于為訓練樣本域(有標簽),目標域為測集域,其測試集域無標簽或只有少量標簽,但是分布不同或數據差異大。主要分為兩種情景:
homogeneous 同質:target 與 source domain 特征空間相似,但數據分布存在 distribution shift
heterogeneous 異構:target 與 source domain 特征空間不同
現有的DA方法傾向于強制對不同的domain進行對齊,即平等地對待每個域并完美地對它們的特征進行align。然而,在實踐中,這些領域通常是異質的;當源域接近目標域時,DA可以預期工作良好,但當它們彼此相距太遠時就效果不那么令人滿意。問題就在于,它們把各個domain當成相互獨立的,從而無視了domain之間的關系。
這樣的話,它們在學encoder的時候,就會盲目地把所有不同domain的feature強制完全對齊。這樣做是有問題的,因為有的domain之間其實聯系并不大,強行對齊它們反而會降低預測任務的性能。而其實這種異質性通常可以用圖來捕捉,其中域實現節點,兩個域之間的鄰接可以用邊捕捉。
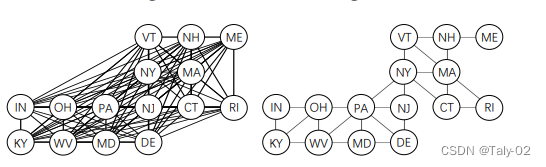
例如,本文舉了一個非常有趣的例子,為了捕捉美國天氣的相似性,我們可以構建一個圖,其中每個州都被視為一個節點,兩個州之間的物理接近性產生一條邊。在那里還有許多其他的場景,在這些場景中,領域之間的關系可以通過圖自然地捕獲。所以如果給定一個域圖,我們可以根據圖調整域的適應性,而不是強制讓來自所有域的數據完美對齊,而忽略這種圖的結構。其實在對domain graph這一比較重要的概念做出定義之后,就可以比較清晰地勾勒出本文提出的方法了。我們只需要對傳統的adversarial DA方法做一下簡單的改動:
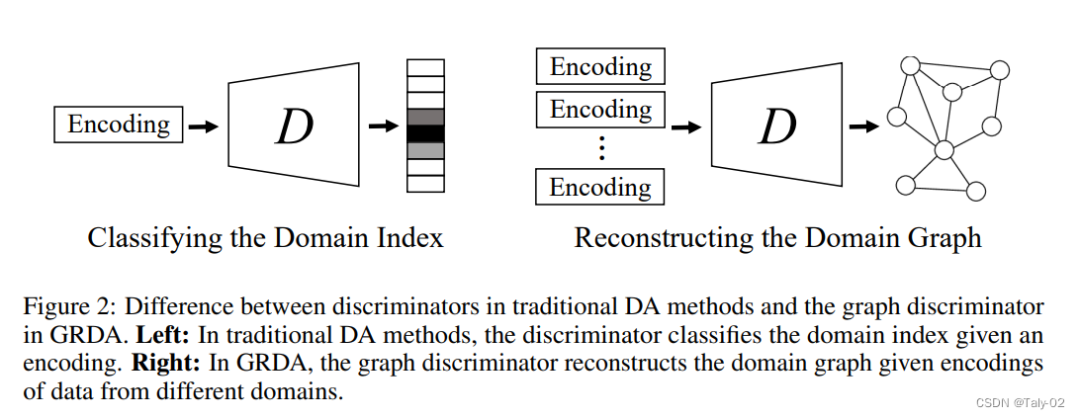
傳統的方法直接把data x作為encoder的輸入,而我們把domain index u以及domain graph作為encoder的輸入。
相比于傳統的方法讓discriminator對domain index進行分類,而我們讓discriminator直接重構(reconstruct)出domain graph。
論文的貢獻在于:
提出使用圖來描述域關系,并開發圖-關系域適應(GRDA)作為第一個在圖上跨域適應的通用對抗性的domain adaption方法。.
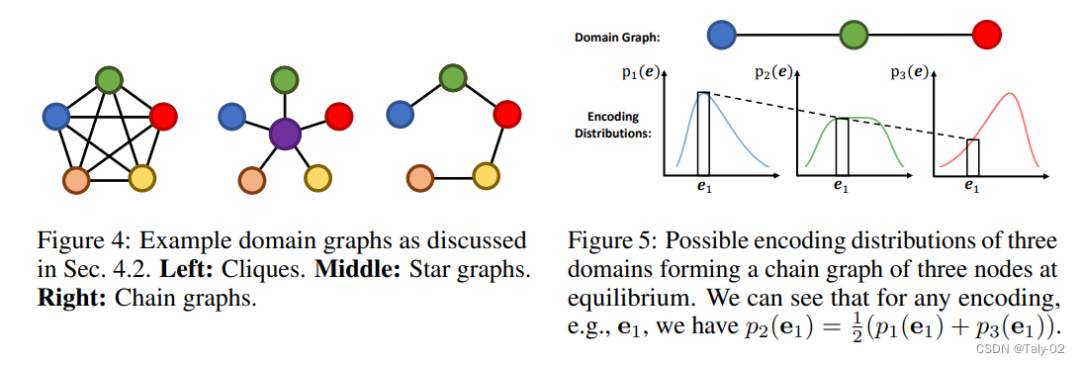
理論分析表明,在balance狀態下,當域圖為clique時,提出的方法能保持均勻對齊的能力,而對其他類型的圖則能實現對齊。
最后通過充分的實驗驗證了方法在合成和真實數據集上提出的方法優于最先進的DA方法。
3. 方法
首先明確下本文的應用場景,他關注的是共N個域的無監督domain adaption setting。每個domain 都有一個離散域索引,屬于源域索引集或目標域索引集。域之間的關系用一個域圖來描述,其鄰接矩陣a = [Aij],其中圖中的i和j個索引節點(域)。
已知來自源域(uf E Us)的標記數據(x, y,u),來自目標域(u, EUt)的未標記數據[, =1],以及由A描述的域圖,我們希望預測來自目標域的數據的標記[yte1]。注意,域圖是在域上定義的,每個域(節點)包含多個數據點。
概述。我們使用對抗學習框架跨圖關系域執行適應。本文提出的方法主要由三個成分組成:
編碼器E,它以數據和相關域索引u和鄰接矩陣a作為輸入,生成編碼。
預測器F,它基于編碼ei進行預測
圖判別器D,它指導編碼適應圖關系域。
3.1 Predictor
定義優化的loss為:
where the expectation is taken over the source-domain data distribution is a predictor loss function for the task (e.g., loss for regression).
3.2 Encoder and Node Embeddings
給定一個輸入元組(x, u, A),用編碼器E首先根據域索引和域的graph計算一個embedding的graph domain,然后將z和x,y輸入到神經網絡中,得到最終的編碼e。理論上,任何節點的索引的embedding都應該同樣有效,只要它們彼此不同,所以為了簡單起見,論文通過一個重構損耗預先訓練embeddings:
where is the sigmoid function.
3.3 Graph Discriminator
whereare the discriminator's reconstructions of node embeddings. The expectation is taken over a pair of i.i.d. samples from the joint data distribution .
更具體的模型實現細節可以參考原文的附錄。
3.5 Theory
論文闡述并證明了兩個觀點:
用的是adversarial training,本質上是在求一個minimax game的均衡點(equilibrium)。在傳統的DA方法上,因為discriminator做的是分類,我們可以很自然地證明,這個minimax game的均衡點就是會完全對齊所有domain。在任何domain graph的情況下,當GRDA訓練到最優時是可以保證不同domain的feature會根據domain graph來對齊,而不是讓所有domain完全對齊。
傳統的DA方法,其實是提出的GRDA的一個特例。這個特例其實非常直觀:傳統的DA方法(完全對齊所有domain)會等價于當GRDA的domain graph是全連接圖(fully-connected graph or clique)時的情況。
4. 實驗
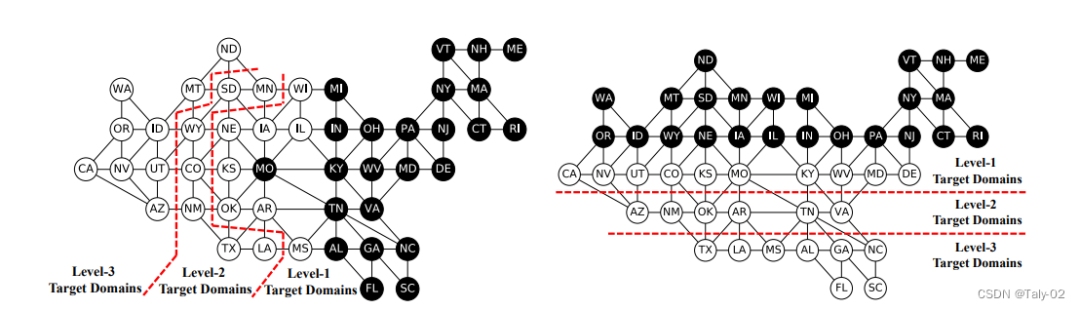
論文構造了一個15個domain的toy dataset及其對應的domain graph(如下圖的左邊)DG-15。可以看到,GRDA的accuracy可以大幅超過其他的方法,特別是其他方法在離source domain比較遠(從domain graph的角度)的target domain的準確率并不是很高,但GRDA卻能夠保持較高的準確率。

5. 結論
在本文中,論文確定了graph-relational domains的自適應問題,并提出了一種通用的DA方法來解決這一問題。我們進一步提供了理論分析,表明我們的方法恢復了經典DA方法的一致對齊,并實現了其他類型圖的非平凡對齊,從而自然地融合了由域圖表示的域信息。實證結果證明該方法非常有效
-
數據
+關注
關注
8文章
7104瀏覽量
89295 -
模型
+關注
關注
1文章
3279瀏覽量
48976 -
深度學習
+關注
關注
73文章
5510瀏覽量
121345
原文標題:【域自適應】Graph-Relational Domain Adaptation
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論