

導(dǎo)讀 模型部署作為算法模型落地的最后一步,在人工智能產(chǎn)業(yè)化過程中是非常關(guān)鍵的步驟,而目標(biāo)檢測(cè)作為計(jì)算機(jī)視覺三大基礎(chǔ)任務(wù)之一,眾多的業(yè)務(wù)功能都要在檢測(cè)的基礎(chǔ)之上完成,本文提供了YOLOv5算法從0部署的實(shí)戰(zhàn)教程,值得各位讀者收藏學(xué)習(xí)。
前言
TensorRT是英偉達(dá)官方提供的一個(gè)高性能深度學(xué)習(xí)推理優(yōu)化庫,支持C++和Python兩種編程語言API。通常情況下深度學(xué)習(xí)模型部署都會(huì)追求效率,尤其是在嵌入式平臺(tái)上,所以一般會(huì)選擇使用C++來做部署。 本文將以YOLOv5為例詳細(xì)介紹如何使用TensorRT的C++版本API來部署ONNX模型,使用的TensorRT版本為8.4.1.5,如果使用其他版本可能會(huì)存在某些函數(shù)與本文描述的不一致。另外,使用TensorRT 7會(huì)導(dǎo)致YOLOv5的輸出結(jié)果與期望不一致,請(qǐng)注意。
導(dǎo)出ONNX模型
YOLOv5使用PyTorch框架進(jìn)行訓(xùn)練,可以使用官方代碼倉庫中的export.py腳本把PyTorch模型轉(zhuǎn)換為ONNX模型:
pythonexport.py--weightsyolov5x.pt--includeonnx--imgsz640640
準(zhǔn)備模型輸入數(shù)據(jù)
如果想用YOLOv5對(duì)圖像做目標(biāo)檢測(cè),在將圖像輸入給模型之前還需要做一定的預(yù)處理操作,預(yù)處理操作應(yīng)該與模型訓(xùn)練時(shí)所做的操作一致。YOLOv5的輸入是RGB格式的3通道圖像,圖像的每個(gè)像素需要除以255來做歸一化,并且數(shù)據(jù)要按照CHW的順序進(jìn)行排布。所以YOLOv5的預(yù)處理大致可以分為兩個(gè)步驟:
將原始輸入圖像縮放到模型需要的尺寸,比如640x640。這一步需要注意的是,原始圖像是按照等比例進(jìn)行縮放的,如果縮放后的圖像某個(gè)維度上比目標(biāo)值小,那么就需要進(jìn)行填充。舉個(gè)例子:假設(shè)輸入圖像尺寸為768x576,模型輸入尺寸為640x640,按照等比例縮放的原則縮放后的圖像尺寸為640x480,那么在y方向上還需要填充640-480=160(分別在圖像的頂部和底部各填充80)。來看一下實(shí)現(xiàn)代碼:
cv::Matinput_image=cv::imread("dog.jpg"); cv::Matresize_image; constintmodel_width=640; constintmodel_height=640; constfloatratio=std::min(model_width/(input_image.cols*1.0f), model_height/(input_image.rows*1.0f)); //等比例縮放 constintborder_width=input_image.cols*ratio; constintborder_height=input_image.rows*ratio; //計(jì)算偏移值 constintx_offset=(model_width-border_width)/2; constinty_offset=(model_height-border_height)/2; cv::resize(input_image,resize_image,cv::Size(border_width,border_height)); cv::copyMakeBorder(resize_image,resize_image,y_offset,y_offset,x_offset, x_offset,cv::BORDER_CONSTANT,cv::Scalar(114,114,114)); //轉(zhuǎn)換為RGB格式 cv::cvtColor(resize_image,resize_image,cv::COLOR_BGR2RGB); 圖像這樣處理后的效果如下圖所示,頂部和底部的灰色部分是填充后的效果。
對(duì)圖像像素做歸一化操作,并按照CHW的順序進(jìn)行排布。這一步的操作比較簡單,直接看代碼吧:
input_blob=newfloat[model_height*model_width*3]; constintchannels=resize_image.channels(); constintwidth=resize_image.cols; constintheight=resize_image.rows; for(intc=0;c(h,w)[c]/255.0f; } } }
ONNX模型部署
1. 模型優(yōu)化與序列化
要使用TensorRT的C++ API來部署模型,首先需要包含頭文件NvInfer.h。
#include"NvInfer.h" TensorRT所有的編程接口都被放在命名空間nvinfer1中,并且都以字母I為前綴,比如ILogger、IBuilder等。使用TensorRT部署模型首先需要?jiǎng)?chuàng)建一個(gè)IBuilder對(duì)象,創(chuàng)建之前還要先實(shí)例化ILogger接口: classMyLogger:publicnvinfer1::ILogger{ public: explicitMyLogger(nvinfer1::Severityseverity= nvinfer1::kWARNING) :severity_(severity){} voidlog(nvinfer1::Severityseverity, constchar*msg)noexceptoverride{ if(severity<=?severity_)?{ ??????std::cerr?< MyLoggerlogger; nvinfer1::IBuilder*builder=nvinfer1::createInferBuilder(logger); 創(chuàng)建IBuilder對(duì)象后,優(yōu)化一個(gè)模型的第一步是要構(gòu)建模型的網(wǎng)絡(luò)結(jié)構(gòu)。 constuint32_texplicit_batch=1U<( nvinfer1::kEXPLICIT_BATCH); nvinfer1::INetworkDefinition*network=builder->createNetworkV2(explicit_batch); 模型的網(wǎng)絡(luò)結(jié)構(gòu)有兩種構(gòu)建方式,一種是使用TensorRT的API一層一層地去搭建,這種方式比較麻煩;另外一種是直接從ONNX模型中解析出模型的網(wǎng)絡(luò)結(jié)構(gòu),這需要ONNX解析器來完成。由于我們已經(jīng)有現(xiàn)成的ONNX模型了,所以選擇第二種方式。TensorRT的ONNX解析器接口被封裝在頭文件NvOnnxParser.h中,命名空間為nvonnxparser。創(chuàng)建ONNX解析器對(duì)象并加載模型的代碼如下: conststd::stringonnx_model="yolov5m.onnx"; nvonnxparser::IParser*parser=nvonnxparser::createParser(*network,logger); parser->parseFromFile(model_path.c_str(), static_cast
2. 模型反序列化
通過上一步得到優(yōu)化后的序列化模型后,如果要用模型進(jìn)行推理,那么還需要?jiǎng)?chuàng)建一個(gè)IRuntime接口的實(shí)例,然后通過其模型反序列化接口去創(chuàng)建一個(gè)ICudaEngine對(duì)象:
nvinfer1::IRuntime*runtime=nvinfer1::createInferRuntime(logger); nvinfer1::ICudaEngine*engine=runtime->deserializeCudaEngine( serialized_model->data(),serialized_model->size()); deleteserialized_model; deleteruntime; 如果是直接從磁盤中加載.engine文件也是差不多的步驟,首先從.engine文件中把模型加載到內(nèi)存中,然后再通過IRuntime接口對(duì)模型進(jìn)行反序列化即可。 conststd::stringengine_file_path="yolov5m.engine"; std::stringstreamengine_file_stream; engine_file_stream.seekg(0,engine_file_stream.beg); std::ifstreamifs(engine_file_path); engine_file_stream<(model_mem),model_size); nvinfer1::IRuntime*runtime=nvinfer1::createInferRuntime(logger); nvinfer1::ICudaEngine*engine=runtime->deserializeCudaEngine(model_mem,model_size); deleteruntime; free(model_mem);
3. 模型推理
ICudaEngine對(duì)象中存放著經(jīng)過TensorRT優(yōu)化后的模型,不過如果要用模型進(jìn)行推理則還需要通過createExecutionContext()函數(shù)去創(chuàng)建一個(gè)IExecutionContext對(duì)象來管理推理的過程:
nvinfer1::IExecutionContext*context=engine->createExecutionContext(); 現(xiàn)在讓我們先來看一下使用TensorRT框架進(jìn)行模型推理的完整流程:
對(duì)輸入圖像數(shù)據(jù)做與模型訓(xùn)練時(shí)一樣的預(yù)處理操作。
調(diào)用模型推理接口進(jìn)行推理。
把模型的輸出數(shù)據(jù)從GPU拷貝到CPU中。
對(duì)模型的輸出結(jié)果進(jìn)行解析,進(jìn)行必要的后處理后得到最終的結(jié)果。
由于模型的推理是在GPU上進(jìn)行的,所以會(huì)存在搬運(yùn)輸入、輸出數(shù)據(jù)的操作,因此有必要在GPU上創(chuàng)建內(nèi)存區(qū)域用于存放輸入、輸出數(shù)據(jù)。模型輸入、輸出的尺寸可以通過ICudaEngine對(duì)象的接口來獲取,根據(jù)這些信息我們可以先為模型分配輸入、輸出緩存區(qū)。
void*buffers[2]; //獲取模型輸入尺寸并分配GPU內(nèi)存 nvinfer1::Dimsinput_dim=engine->getBindingDimensions(0); intinput_size=1; for(intj=0;jgetBindingDimensions(1); intoutput_size=1; for(intj=0;j cudaStream_tstream; cudaStreamCreate(&stream); //拷貝輸入數(shù)據(jù) cudaMemcpyAsync(buffers[0],input_blob,input_size*sizeof(float), cudaMemcpyHostToDevice,stream); //執(zhí)行推理 context->enqueueV2(buffers,stream,nullptr); //拷貝輸出數(shù)據(jù) cudaMemcpyAsync(output_buffer,buffers[1],output_size*sizeof(float), cudaMemcpyDeviceToHost,stream); cudaStreamSynchronize(stream); 模型推理成功后,其輸出數(shù)據(jù)被拷貝到output_buffer中,接下來我們只需按照YOLOv5的輸出數(shù)據(jù)排布規(guī)則去解析即可。
4. 小結(jié)
在介紹如何解析YOLOv5輸出數(shù)據(jù)之前,我們先來總結(jié)一下用TensorRT框架部署ONNX模型的基本流程。  如上圖所示,主要步驟如下:
如上圖所示,主要步驟如下:
實(shí)例化Logger;
創(chuàng)建Builder;
創(chuàng)建Network;
使用Parser解析ONNX模型,構(gòu)建Network;
設(shè)置Config參數(shù);
優(yōu)化網(wǎng)絡(luò),序列化模型;
反序列化模型;
拷貝模型輸入數(shù)據(jù)(HostToDevice),執(zhí)行模型推理;
拷貝模型輸出數(shù)據(jù)(DeviceToHost),解析結(jié)果。
解析模型輸出結(jié)果
YOLOv5有3個(gè)檢測(cè)頭,如果模型輸入尺寸為640x640,那么這3個(gè)檢測(cè)頭分別在80x80、40x40和20x20的特征圖上做檢測(cè)。讓我們先用Netron工具來看一下YOLOv5 ONNX模型的結(jié)構(gòu),可以看到,YOLOv5的后處理操作已經(jīng)被包含在模型中了(如下圖紅色框內(nèi)所示),3個(gè)檢測(cè)頭分支的結(jié)果最終被組合成一個(gè)張量作為輸出。 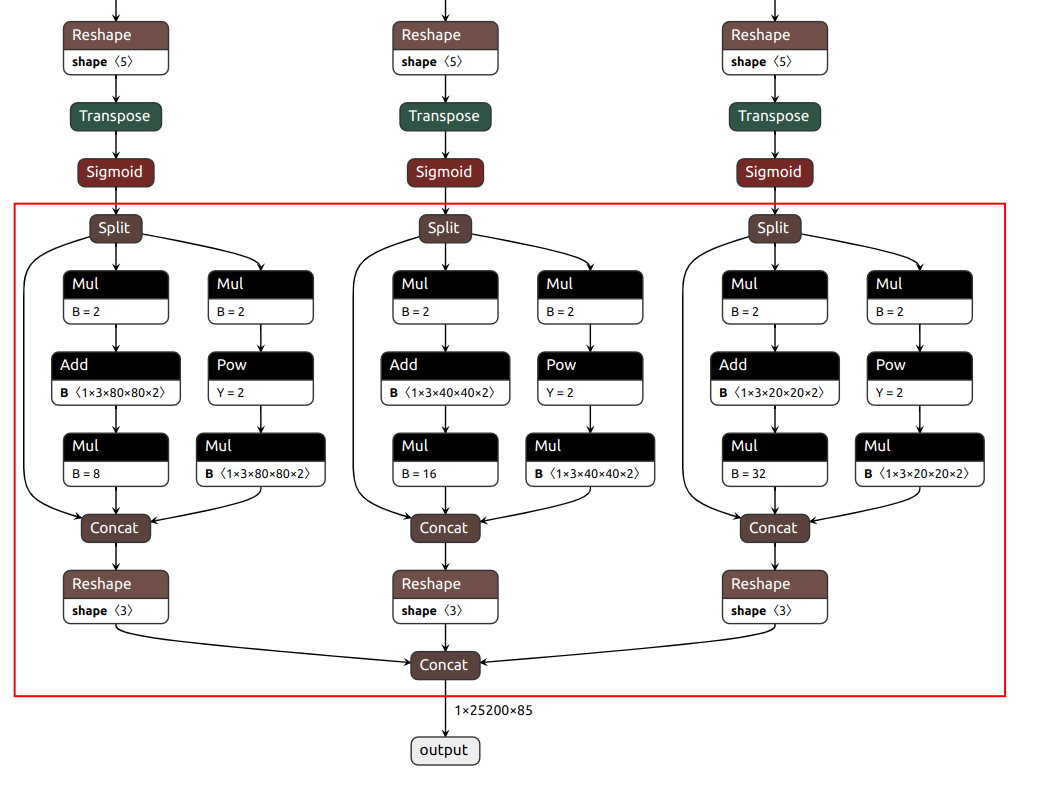 yolov5m YOLOv5的3個(gè)檢測(cè)頭一共有(80x80+40x40+20x20)x3=25200個(gè)輸出單元格,每個(gè)單元格輸出x,y,w,h,objectness這5項(xiàng)再加80個(gè)類別的置信度總共85項(xiàng)內(nèi)容。經(jīng)過后處理操作后,目標(biāo)的坐標(biāo)值已經(jīng)被恢復(fù)到以640x640為參考的尺寸,如果需要恢復(fù)到原始圖像尺寸,只需要除以預(yù)處理時(shí)的縮放因子即可。這里有個(gè)問題需要注意:由于在做預(yù)處理的時(shí)候圖像做了填充,原始圖像并不是被縮放成640x640而是640x480,使得輸入給模型的圖像的頂部被填充了一塊高度為80的區(qū)域,所以在恢復(fù)到原始尺寸之前,需要把目標(biāo)的y坐標(biāo)減去偏移量80。
yolov5m YOLOv5的3個(gè)檢測(cè)頭一共有(80x80+40x40+20x20)x3=25200個(gè)輸出單元格,每個(gè)單元格輸出x,y,w,h,objectness這5項(xiàng)再加80個(gè)類別的置信度總共85項(xiàng)內(nèi)容。經(jīng)過后處理操作后,目標(biāo)的坐標(biāo)值已經(jīng)被恢復(fù)到以640x640為參考的尺寸,如果需要恢復(fù)到原始圖像尺寸,只需要除以預(yù)處理時(shí)的縮放因子即可。這里有個(gè)問題需要注意:由于在做預(yù)處理的時(shí)候圖像做了填充,原始圖像并不是被縮放成640x640而是640x480,使得輸入給模型的圖像的頂部被填充了一塊高度為80的區(qū)域,所以在恢復(fù)到原始尺寸之前,需要把目標(biāo)的y坐標(biāo)減去偏移量80。 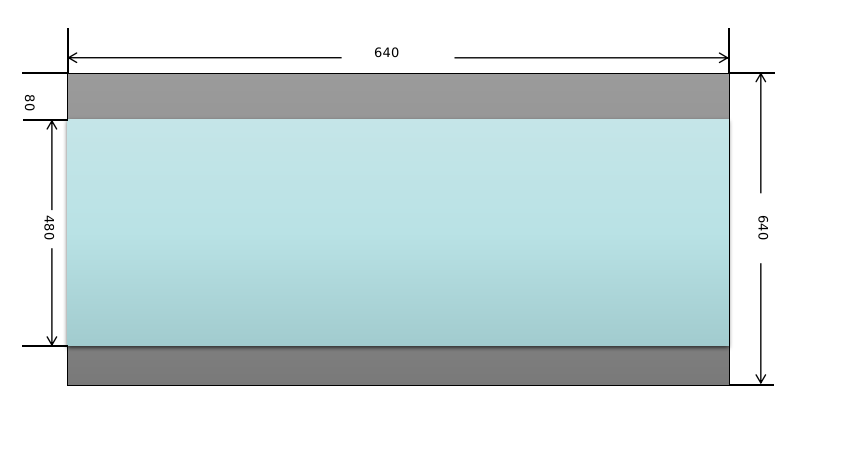 詳細(xì)的解析代碼如下:
詳細(xì)的解析代碼如下:

總結(jié)
本文以YOLOv5為例通過大量的代碼一步步講解如何使用TensorRT框架部署ONNX模型,主要目的是希望讀者能夠通過本文學(xué)習(xí)到TensorRT模型部署的基本流程,比如如何準(zhǔn)備輸入數(shù)據(jù)、如何調(diào)用API用模型做推理、如何解析模型的輸出結(jié)果。如何部署YOLOv5模型并不是本文的重點(diǎn),重點(diǎn)是要掌握使用TensorRT部署ONNX模型的基本方法,這樣才會(huì)有舉一反三的效果。
-
C++
+關(guān)注
關(guān)注
22文章
2116瀏覽量
74531 -
模型
+關(guān)注
關(guān)注
1文章
3460瀏覽量
49772 -
代碼
+關(guān)注
關(guān)注
30文章
4876瀏覽量
69957
原文標(biāo)題:手把手教學(xué),YOLOV5算法TensorRT部署流程
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深度探索ONNX模型部署 精選資料分享
ONNX的相關(guān)資料分享
如何使用Paddle2ONNX模型轉(zhuǎn)換工具將飛槳模型轉(zhuǎn)換為ONNX模型?
EIQ onnx模型轉(zhuǎn)換為tf-lite失敗怎么解決?
Facebook推出ONNX,旨在為不同編程框架的神經(jīng)網(wǎng)絡(luò)創(chuàng)建共享模型
嵌入式Linux平臺(tái)部署AI神經(jīng)網(wǎng)絡(luò)模型Inference的方案

基于TensorRT完成NanoDet模型部署
使用Bottlerocket和Amazon EC2部署AI模型
基于NVIDIA Triton的AI模型高效部署實(shí)踐
Pytorch轉(zhuǎn)化ONNX過程代碼實(shí)操
ONNX格式模型部署兼容性框架介紹
三種主流模型部署框架YOLOv8推理演示
用STM32Cube.AI部署ONNX模型實(shí)操示例:風(fēng)扇堵塞檢測(cè)

Yolo系列模型的部署、精度對(duì)齊與int8量化加速
基于Pytorch訓(xùn)練并部署ONNX模型在TDA4應(yīng)用筆記





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論