 常見的小樣本學習方法
常見的小樣本學習方法
近年來,基于深度學習的模型在目標檢測和圖像識別等任務中表現出色。像ImageNet這樣具有挑戰性的圖像分類數據集,包含1000種不同的對象分類,現在一些模型已經超過了人類水平上。但是這些模型依賴于監督訓練流程,標記訓練數據的可用性對它們有重大影響,并且模型能夠檢測到的類別也僅限于它們接受訓練的類。
由于在訓練過程中沒有足夠的標記圖像用于所有類,這些模型在現實環境中可能不太有用。并且我們希望的模型能夠識別它在訓練期間沒有見到過的類,因為幾乎不可能在所有潛在對象的圖像上進行訓練。我們將從幾個樣本中學習的問題被稱為“少樣本學習 Few-Shot learning”。
什么是小樣本學習?
少樣本學習是機器學習的一個子領域。它涉及到在只有少數訓練樣本和監督數據的情況下對新數據進行分類。只需少量的訓練樣本,我們創建的模型就可以相當好地執行。
考慮以下場景:在醫療領域,對于一些不常見的疾病,可能沒有足夠的x光圖像用于訓練。對于這樣的場景,構建一個小樣本學習分類器是完美的解決方案。
小樣本的變化
一般來說,研究人員確定了四種類型:
N-Shot Learning (NSL)
Few-Shot Learning ( FSL )
One-Shot Learning (OSL)
Zero-Shot Learning (ZSL)
當我們談論 FSL 時,我們通常指的是 N-way-K-Shot 分類。N 代表類別數,K 代表每個類中要訓練的樣本數。所以N-Shot Learning 被視為比所有其他概念更廣泛的概念。可以說 Few-Shot、One-Shot 和 Zero-Shot是 NSL 的子領域。而零樣本學習旨在在沒有任何訓練示例的情況下對看不見的類進行分類。
在 One-Shot Learning 中,每個類只有一個樣本。Few-Shot 每個類有 2 到 5 個樣本,也就是說 Few-Shot 是更靈活的 One-Shot Learning 版本。
小樣本學習方法
通常,在解決 Few Shot Learning 問題時應考慮兩種方法:
數據級方法 (DLA)
這個策略非常簡單,如果沒有足夠的數據來創建實體模型并防止欠擬合和過擬合,那么就應該添加更多數據。正因為如此,許多 FSL 問題都可以通過利用來更大大的基礎數據集的更多數據來解決。基本數據集的顯著特征是它缺少構成我們對 Few-Shot 挑戰的支持集的類。例如,如果我們想要對某種鳥類進行分類,則基礎數據集可能包含許多其他鳥類的圖片。
參數級方法 (PLA)
從參數級別的角度來看,Few-Shot Learning 樣本相對容易過擬合,因為它們通常具有大的高維空間。限制參數空間、使用正則化和使用適當的損失函數將有助于解決這個問題。少量的訓練樣本將被模型泛化。
通過將模型引導到廣闊的參數空間可以提高性能。由于缺乏訓練數據,正常的優化方法可能無法產生準確的結果。
因為上面的原因,訓練我們的模型以發現通過參數空間的最佳路徑,產生最佳的預測結果。這種方法被稱為元學習。
小樣本學習圖像分類算法
有4種比較常見的小樣本學習的方法:
與模型無關的元學習 Model-Agnostic Meta-Learning
基于梯度的元學習 (GBML) 原則是 MAML 的基礎。在 GBML 中,元學習者通過基礎模型訓練和學習所有任務表示的共享特征來獲得先前的經驗。每次有新任務要學習時,元學習器都會利用其現有經驗和新任務提供的最少量的新訓練數據進行微調訓練。
一般情況下,如果我們隨機初始化參數經過幾次更新算法將不會收斂到良好的性能。MAML 試圖解決這個問題。MAML 只需幾個梯度步驟并且保證沒有過度擬合的前提下,為元參數學習器提供了可靠的初始化,這樣可以對新任務進行最佳快速學習。
步驟如下:
元學習者在每個分集(episode)開始時創建自己的副本C,
C 在這一分集上進行訓練(在 base-model 的幫助下),
C 對查詢集進行預測,
從這些預測中計算出的損失用于更新 C,
這種情況一直持續到完成所有分集的訓練。

這種技術的最大優勢在于,它被認為與元學習算法的選擇無關。因此MAML 方法被廣泛用于許多需要快速適應的機器學習算法,尤其是深度神經網絡。
為解決 FSL 問題而創建的第一個度量學習方法是匹配網絡 (MN)。
當使用匹配網絡方法解決 Few-Shot Learning 問題時需要一個大的基礎數據集。。
將該數據集分為幾個分集之后,對于每一分集,匹配網絡進行以下操作:
來自支持集和查詢集的每個圖像都被饋送到一個 CNN,該 CNN 為它們輸出特征的嵌入
查詢圖像使用支持集訓練的模型得到嵌入特征的余弦距離,通過 softmax 進行分類
分類結果的交叉熵損失通過 CNN 反向傳播更新特征嵌入模型
匹配網絡可以通過這種方式學習構建圖像嵌入。MN 能夠使用這種方法對照片進行分類,并且無需任何特殊的類別先驗知識。他只要簡單地比較類的幾個實例就可以了。
由于類別因分集而異,因此匹配網絡會計算對類別區分很重要的圖片屬性(特征)。而當使用標準分類時,算法會選擇每個類別獨有的特征。
原型網絡 Prototypical Networks
與匹配網絡類似的是原型網絡(PN)。它通過一些細微的變化來提高算法的性能。PN 比 MN 取得了更好的結果,但它們訓練過程本質上是相同的,只是比較了來自支持集的一些查詢圖片嵌入,但是 原型網絡提供了不同的策略。
我們需要在 PN 中創建類的原型:通過對類中圖像的嵌入進行平均而創建的類的嵌入。然后僅使用這些類原型來比較查詢圖像嵌入。當用于單樣本學習問題時,它可與匹配網絡相媲美。
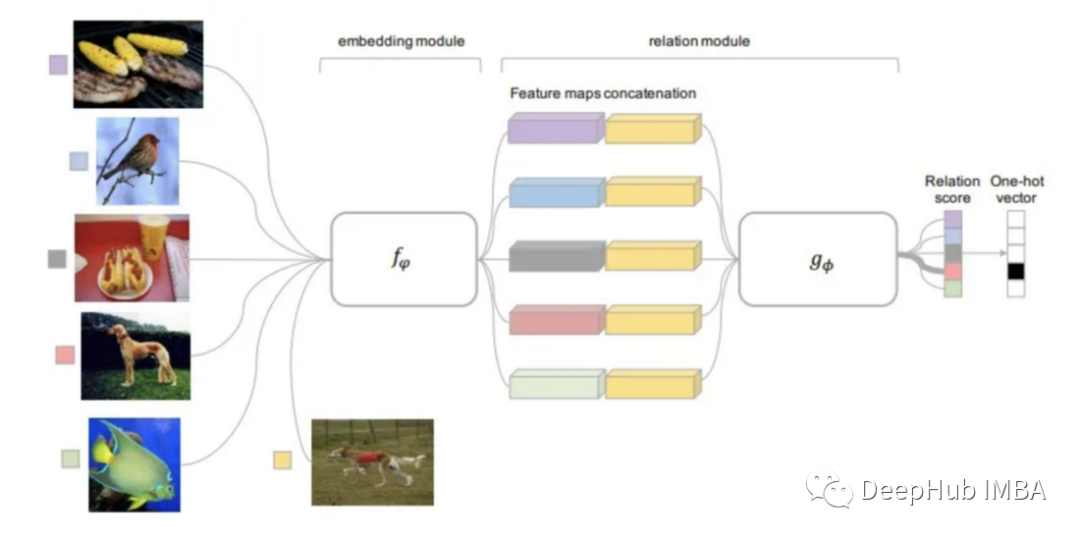
關系網絡 Relation Network
關系網絡可以說繼承了所有上面提到方法的研究的結果。RN是基于PN思想的但包含了顯著的算法改進。
該方法使用的距離函數是可學習的,而不是像以前研究的事先定義它。關系模塊位于嵌入模塊之上,嵌入模塊是從輸入圖像計算嵌入和類原型的部分。
可訓練的關系模塊(距離函數)輸入是查詢圖像的嵌入與每個類的原型,輸出為每個分類匹配的關系分數。關系分數通過 Softmax 得到一個預測。
使用 Open-AI Clip 進行零樣本學習
CLIP(Contrastive Language-Image Pre-Training)是一個在各種(圖像、文本)對上訓練的神經網絡。它無需直接針對任務進行優化,就可以為給定的圖像來預測最相關的文本片段(類似于 GPT-2 和 3 的零樣本的功能)。
CLIP 在 ImageNet“零樣本”上可以達到原始 ResNet50 的性能,而且需要不使用任何標記示例,它克服了計算機視覺中的幾個主要挑戰,下面我們使用Pytorch來實現一個簡單的分類模型。
引入包
! pip install ftfy regex tqdm ! pip install git+https://github.com/openai/CLIP.gitimport numpy as np import torch from pkg_resources import packaging print("Torch version:", torch.__version__)
加載模型
import clipclip.available_models() # it will list the names of available CLIP modelsmodel, preprocess = clip.load("ViT-B/32") model.cuda().eval() input_resolution = model.visual.input_resolution context_length = model.context_length vocab_size = model.vocab_size print("Model parameters:", f"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}") print("Input resolution:", input_resolution) print("Context length:", context_length) print("Vocab size:", vocab_size)
圖像預處理
我們將向模型輸入8個示例圖像及其文本描述,并比較對應特征之間的相似性。
分詞器不區分大小寫,我們可以自由地給出任何合適的文本描述。
import os import skimage import IPython.display import matplotlib.pyplot as plt from PIL import Image import numpy as np from collections import OrderedDict import torch %matplotlib inline %config InlineBackend.figure_format = 'retina' # images in skimage to use and their textual descriptions descriptions = { "page": "a page of text about segmentation", "chelsea": "a facial photo of a tabby cat", "astronaut": "a portrait of an astronaut with the American flag", "rocket": "a rocket standing on a launchpad", "motorcycle_right": "a red motorcycle standing in a garage", "camera": "a person looking at a camera on a tripod", "horse": "a black-and-white silhouette of a horse", "coffee": "a cup of coffee on a saucer" }original_images = [] images = [] texts = [] plt.figure(figsize=(16, 5)) for filename in [filename for filename in os.listdir(skimage.data_dir) if filename.endswith(".png") or filename.endswith(".jpg")]: name = os.path.splitext(filename)[0] if name not in descriptions: continue image = Image.open(os.path.join(skimage.data_dir, filename)).convert("RGB") plt.subplot(2, 4, len(images) + 1) plt.imshow(image) plt.title(f"{filename} {descriptions[name]}") plt.xticks([]) plt.yticks([]) original_images.append(image) images.append(preprocess(image)) texts.append(descriptions[name]) plt.tight_layout()
結果的可視化如下:

我們對圖像進行規范化,對每個文本輸入進行標記,并運行模型的正傳播獲得圖像和文本的特征。
image_input = torch.tensor(np.stack(images)).cuda() text_tokens = clip.tokenize(["This is " + desc for desc in texts]).cuda() with torch.no_grad(): image_features = model.encode_image(image_input).float() text_features = model.encode_text(text_tokens).float()
我們將特征歸一化,并計算每一對的點積,進行余弦相似度計算
image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T count = len(descriptions) plt.figure(figsize=(20, 14)) plt.imshow(similarity, vmin=0.1, vmax=0.3) # plt.colorbar() plt.yticks(range(count), texts, fontsize=18) plt.xticks([]) for i, image in enumerate(original_images): plt.imshow(image, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower") for x in range(similarity.shape[1]): for y in range(similarity.shape[0]): plt.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12) for side in ["left", "top", "right", "bottom"]: plt.gca().spines[side].set_visible(False) plt.xlim([-0.5, count - 0.5]) plt.ylim([count + 0.5, -2]) plt.title("Cosine similarity between text and image features", size=20)

零樣本的圖像分類
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
plt.figure(figsize=(16, 16))
for i, image in enumerate(original_images):
plt.subplot(4, 4, 2 * i + 1)
plt.imshow(image)
plt.axis("off")
plt.subplot(4, 4, 2 * i + 2)
y = np.arange(top_probs.shape[-1])
plt.grid()
plt.barh(y, top_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()])
plt.xlabel("probability")
plt.subplots_adjust(wspace=0.5)
plt.show()
可以看到,分類的效果還是非常好的
-
圖像識別
+關注
關注
9文章
520瀏覽量
38272 -
模型
+關注
關注
1文章
3243瀏覽量
48840 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162
原文標題:使用PyTorch進行小樣本學習的圖像分類
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
高維小樣本分類問題中特征選擇研究綜述
多示例多標記學習方法
答疑解惑探討小樣本學習的最新進展
深度學習:小樣本學習下的多標簽分類問題初探
一種針對小樣本學習的雙路特征聚合網絡

一種為小樣本文本分類設計的結合數據增強的元學習框架

融合零樣本學習和小樣本學習的弱監督學習方法綜述

一種基于偽標簽半監督學習的小樣本調制識別算法
基于深度學習的小樣本墻壁缺陷目標檢測及分類
小樣本學習領域的未來發展方向






 工商網監
工商網監
評論