") NVIDIA Triton推理服務(wù)器的功能與架構(gòu)簡(jiǎn)介
NVIDIA Triton推理服務(wù)器的功能與架構(gòu)簡(jiǎn)介
前面文章介紹微軟 Teams 會(huì)議系統(tǒng)、微信軟件與騰訊 PCG 服務(wù)三個(gè) Triton 推理服務(wù)器的成功案例,讓大家對(duì) Triton 有初步的認(rèn)知,但別誤以為這個(gè)軟件只適合在大型的服務(wù)類(lèi)應(yīng)用中使用,事實(shí)上 Triton 能適用于更廣泛的推理環(huán)節(jié)中,并且在越復(fù)雜的應(yīng)用環(huán)境中就越能展現(xiàn)其執(zhí)行成效。
在說(shuō)明 Triton 推理服務(wù)器的架構(gòu)與功能之前,我們需要先了解一個(gè)推理服務(wù)器所需要面對(duì)并解決的問(wèn)題。
與大部分的服務(wù)器軟件所需要的基本功能類(lèi)似,一個(gè)推理服務(wù)器也得接受來(lái)自不同用戶(hù)端所提出的各種要求(request)然后做出回應(yīng)(response),并且對(duì)系統(tǒng)的處理進(jìn)行性能優(yōu)化與穩(wěn)定性管理。
但是推理計(jì)算需要面對(duì)深度學(xué)習(xí)領(lǐng)域的各式各樣推理模型,包括圖像分類(lèi)、物件檢測(cè)、語(yǔ)義分析、語(yǔ)音識(shí)別等不同應(yīng)用類(lèi)別,每種類(lèi)別還有不同神經(jīng)網(wǎng)絡(luò)算法與不同框架所訓(xùn)練出來(lái)的模型格式等。此外,我們不能對(duì)任務(wù)進(jìn)行單純的串行隊(duì)列(queue)方式處理,這會(huì)使得任務(wù)等待時(shí)間拖得很長(zhǎng),影響使用的體驗(yàn)感,因此必須對(duì)任務(wù)進(jìn)行并行化處理,這里就存在非常復(fù)雜的任務(wù)管理技巧。
下面列出一個(gè)推理服務(wù)器所需要面對(duì)的技術(shù)問(wèn)題:
1.支持多種模型格式:至少需要支持普及度最高的
2.TensorFlow 的 GraphDef 與 SavedMode 中一種以上格式
(1) PyTorch 的 TorchScript 格式
(2) ONNX 開(kāi)放標(biāo)準(zhǔn)格式
(3) 其他:包括自定義模型格式
3.支持多種查詢(xún)類(lèi)型,包括
(1) 在線的實(shí)時(shí)查詢(xún):盡量降低查詢(xún)的延遲(latency)時(shí)間
(2) 離線的批量處理:盡量提高查詢(xún)的通量(throughput)
(3) 流水線傳輸?shù)淖R(shí)別號(hào)管理等工作
4.支持多種部署方式:包括
(1) 企業(yè)的 GPU 或 CPU 計(jì)算設(shè)備
(2) 公共云或數(shù)據(jù)中心
5.對(duì)模型進(jìn)行最佳縮放處理:讓個(gè)別模型提供更好的性能
6.優(yōu)化多個(gè) KPI:包括
(1) 硬件利用率
(2) 模型推理識(shí)別時(shí)間
(3) 總體成本(TCO)
7.提高系統(tǒng)穩(wěn)定性:需監(jiān)控模型狀態(tài)并解決問(wèn)題以防止停機(jī)
在了解推理服務(wù)器所需要解決的關(guān)鍵問(wèn)題之后,接著來(lái)看看下方的 Triton 系統(tǒng)高階架構(gòu)圖,就能更清楚每個(gè)板塊所負(fù)責(zé)的任務(wù)與使用的對(duì)應(yīng)技術(shù)。
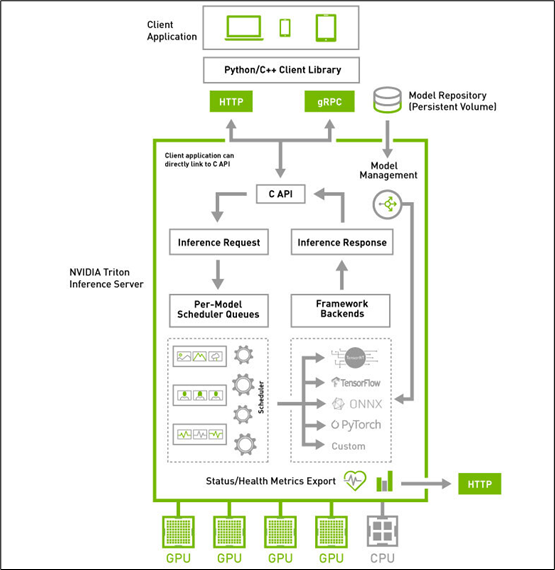
Triton 推理服務(wù)器采用屬于 “主從(client-server)” 架構(gòu)的系統(tǒng),由圖中的四個(gè)板塊所組成:
1.模型倉(cāng)(Model Repostory):存放 Triton 服務(wù)器所要使用的模型文件與配置文件的存儲(chǔ)設(shè)備,可以是本地服務(wù)器的文件系統(tǒng),也可以使用 Google、AWS、Azure 等云存儲(chǔ)空間,只要遵循 Triton 服務(wù)器所要求的規(guī)范就可以;
2.客戶(hù)端應(yīng)用(Client Application):基于 Triton 用戶(hù)端 Python / C++ / Java 庫(kù)所撰寫(xiě),可以在各種操作系統(tǒng)與 CPU 架構(gòu)上操作,對(duì) Triton 服務(wù)器提交任務(wù)請(qǐng)求,并且接受返回的計(jì)算結(jié)果。這是整個(gè) Triton 推理應(yīng)用中代碼量最多的一部分,也是開(kāi)發(fā)人員需要花費(fèi)最多心思的部分,在后面會(huì)有專(zhuān)文講解。
3.HTTP / gPRC 通訊協(xié)議:作為用戶(hù)端與服務(wù)端互動(dòng)的通訊協(xié)議,開(kāi)發(fā)人員可以根據(jù)實(shí)際狀況選擇其中一種通訊協(xié)議進(jìn)行操作,能透過(guò)互聯(lián)網(wǎng)對(duì)服務(wù)器提出推理請(qǐng)求并返回推理結(jié)果,如下圖所示:
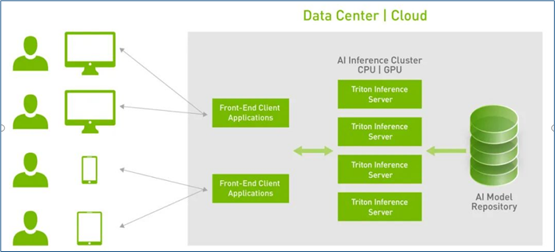
使用這類(lèi)通訊協(xié)議有以下優(yōu)點(diǎn):
(1)支持實(shí)時(shí)、批處理和流式推理查詢(xún),以獲得最佳應(yīng)用程序體驗(yàn)
(2)提供高吞吐量推理,同時(shí)使用動(dòng)態(tài)批處理和并發(fā)模型執(zhí)行來(lái)滿足緊張的延遲預(yù)算
(3)模型可以在現(xiàn)場(chǎng)制作中更新,而不會(huì)中斷應(yīng)用程序
4.推理服務(wù)器(Inference Server):這是整個(gè) Triton 服務(wù)器最核心且最復(fù)雜的部分,特別在 “性能”、“穩(wěn)定”、“擴(kuò)充” 這三大要求之間取得平衡的管理,主要包括以下幾大功能板塊:
(1) C 開(kāi)發(fā)接口:
在服務(wù)器內(nèi)的代碼屬于系統(tǒng)底層機(jī)制,主要由 NVIDIA 系統(tǒng)工程師進(jìn)行維護(hù),因此只提供性能較好的 C 開(kāi)發(fā)接口,一般應(yīng)用工程師可以忽略這部分,除非您有心深入 Triton 系統(tǒng)底層進(jìn)行改寫(xiě)。
(2) 模型管理器(Model Management):
支持多框架的文件格式并提供自定義的擴(kuò)充能力,目前已支持 TensorFlow 的 GraphDef 與 SavedModel 格式、ONNX、PyTorch TorchScript、TensorRT、用于基于樹(shù)的 RAPIDS FIL 模型、OpenVINO 等模型文件格式,還能使用自定義的 Python / C++ 模型格式;
(3) 模型的推理隊(duì)列調(diào)度器(Per-Model Scheduler Queues):
將推理模型用管道形式進(jìn)行管理,將一個(gè)或多個(gè)模型的預(yù)處理或后處理進(jìn)行邏輯排列,并管理模型之間的輸入和輸出張量的連接,任何的推理請(qǐng)求都會(huì)觸發(fā)這個(gè)模型管道。這部分還包含以下兩個(gè)重點(diǎn):
并發(fā)模型執(zhí)行(Concurrent Model Execution):允許同一模型的多個(gè)模型和 / 或多個(gè)實(shí)例在同一系統(tǒng)上并行執(zhí)行,系統(tǒng)可能有零個(gè)、一個(gè)或多個(gè) GPU。
模型和調(diào)度程序(Models And Schedulers):支持多種調(diào)度和批量處理算法,可為每個(gè)模型單獨(dú)選擇無(wú)狀態(tài)(stateless)、有狀態(tài)(stateful)或集成(ensemble)模式。對(duì)于給定的模型,調(diào)度器的選擇和配置是通過(guò)模型的配置文件完成的。
(4) 計(jì)算資源的優(yōu)化處理:
這是作為服務(wù)器軟件的最重要工作之一,就是要將設(shè)備的計(jì)算資源充分調(diào)度,并且優(yōu)化總體計(jì)算性能,主要使用以下三種技術(shù)。
支持異構(gòu)計(jì)算模式:可部署在純 x86 與 ARM CPU 的計(jì)算設(shè)備上,也支持裝載 NVIDIA GPU 的計(jì)算設(shè)備。
動(dòng)態(tài)批量處理(Dynamic batching)技術(shù):對(duì)支持批處理的模型提供多個(gè)內(nèi)置的調(diào)度和批處理算法,并結(jié)合各個(gè)推理請(qǐng)求以提高推理吞吐量,這些調(diào)度和批量處理決策對(duì)請(qǐng)求推理的客戶(hù)端是透明的。
批量處理推理請(qǐng)求分為客戶(hù)端批量處理和服務(wù)器批量處理兩種,通過(guò)將單個(gè)推理請(qǐng)求組合在一起來(lái)實(shí)現(xiàn)服務(wù)器批處理,以提高推理吞吐量;
構(gòu)建一個(gè)批量處理緩存區(qū),當(dāng)達(dá)到配置的延遲閾值后便啟動(dòng)處理機(jī)制;
調(diào)度和批處理決策對(duì)請(qǐng)求推斷的客戶(hù)機(jī)是透明的,并且根據(jù)模型進(jìn)行配置。
c.并發(fā)模型(Concurrent model)運(yùn)行:多個(gè)模型或同一模型的多個(gè)實(shí)例,可以同時(shí)在一個(gè) GPU 或多個(gè) GPU 上運(yùn)行,以滿足不同的模型管理需求。
(5) 框架后端管理器(Framework Backends):
Triton 的后端就是執(zhí)行模型的封裝代碼,每種支持的框架都有一個(gè)對(duì)應(yīng)的后端作為支持,例如 tensorrt_backend 就是支持 TensorRT 模型推理所封裝的后端、openvino_backend 就是支持 openvine 模型推理所封裝的后端,目前在 Triton 開(kāi)源項(xiàng)目里已經(jīng)提供大約 15 種后端,技術(shù)人員可以根據(jù)開(kāi)發(fā)無(wú)限擴(kuò)充。
要添加一個(gè)新的后臺(tái)是相當(dāng)復(fù)雜的過(guò)程,因此在本系列文章中并不探索,這里主要說(shuō)明以下 Triton 服務(wù)器對(duì)各個(gè)后端的管理機(jī)制,主要是以下重點(diǎn):
采用 KFServing 的新社區(qū)標(biāo)準(zhǔn) gRPC 和 HTTP/REST 數(shù)據(jù)平面(data plane)v2 協(xié)議(如下圖),這是 Kubernetes 上基于各種標(biāo)準(zhǔn)的無(wú)服務(wù)器推理架構(gòu)
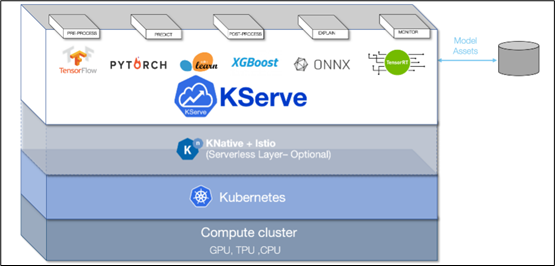
通過(guò)配置自動(dòng)化和自動(dòng)擴(kuò)展簡(jiǎn)化 Kubernetes 中的推理服務(wù)部署
透明地處理負(fù)載峰值,即使請(qǐng)求數(shù)量顯著增加,請(qǐng)求的服務(wù)也將繼續(xù)順利運(yùn)行
可以通過(guò)定義轉(zhuǎn)換器,輕松地將標(biāo)記化和后處理等預(yù)處理步驟包含在部署中
可以用 NGC 的 Helm 命令在 Kubernetes 中部署 Triton,也可以部署為容器微服務(wù),為 GPU 和 CPU 上的預(yù)處理或后處理和深度學(xué)習(xí)模型提供服務(wù),也能輕松部署在數(shù)據(jù)中心或云平臺(tái)上
將推理實(shí)例進(jìn)行微服務(wù)處理,每個(gè)實(shí)例都可以在 Kubernetes 環(huán)境中獨(dú)立擴(kuò)展,以獲得最佳性能
通過(guò)這種新的集成,可以輕松地在 Kubernetes 使用 Triton 部署高性能推理
以上是 Triton 推理服務(wù)器的高級(jí)框架與主要特性的簡(jiǎn)介,如果看完本文后仍感覺(jué)有許多不太理解的部分,這是正常的現(xiàn)象,因?yàn)檎麄€(gè) Triton 系統(tǒng)集成非常多最先進(jìn)的技術(shù)在內(nèi),并非朝夕之間就能掌握的。
后面的內(nèi)容就要進(jìn)入 Triton 推理服務(wù)器的環(huán)境安裝與調(diào)試,以及一些基礎(chǔ)范例的執(zhí)行環(huán)節(jié),透過(guò)這些實(shí)際的操作,逐步體驗(yàn) Triton 系統(tǒng)的強(qiáng)大。
審核編輯:湯梓紅
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4986瀏覽量
103066 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9160瀏覽量
85427 -
Triton
+關(guān)注
關(guān)注
0文章
28瀏覽量
7038
原文標(biāo)題:NVIDIA Triton系列文章(2):功能與架構(gòu)簡(jiǎn)介
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Triton編譯器與GPU編程的結(jié)合應(yīng)用
Triton編譯器的優(yōu)化技巧
Triton編譯器在機(jī)器學(xué)習(xí)中的應(yīng)用
Triton編譯器功能介紹 Triton編譯器使用教程
GPU服務(wù)器AI網(wǎng)絡(luò)架構(gòu)設(shè)計(jì)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論